
집 >데이터 베이스 >MySQL 튜토리얼 >mysql의 인덱스 심층 분석(원리 상세 설명)
mysql의 인덱스 심층 분석(원리 상세 설명)

- 青灯夜游앞으로
- 2022-07-01 10:07:232942검색
이 기사는 mysql의 인덱스에 대한 심층적인 분석을 제공하고 mysql 인덱스의 원리를 이해하는 데 도움이 되기를 바랍니다.

1. 인덱스란
인덱스는 MySQL이 데이터를 효율적으로 얻을 수 있도록 도와주는 정렬된 데이터 구조입니다.
선지식: 트리 높이가 낮을수록 쿼리 효율성이 높아집니다
2. 인덱스 데이터 구조
데이터 구조 시뮬레이션 웹사이트: https://www.cs.usfca.edu/~galles/visualization/Algorithms.html
(1) 이진 트리
문제: 자체 균형을 이루지 못하고 극단적인 경우 기울기가 발생하며, 쿼리 효율성은 연결된 목록과 유사합니다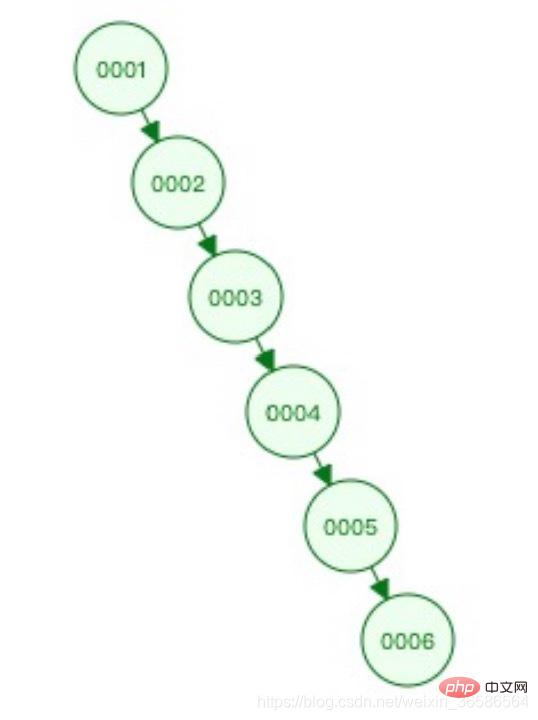
(2) 레드-블랙 트리
레드-블랙 트리는 데이터의 균형을 맞추고 일방적 성장 문제를 해결합니다.
문제: 대량의 데이터에는 적합하지 않습니다. 데이터의 양이 많으면 트리의 높이를 제어할 수 없으며 루트 노드에서 리프 노드까지 여러 번 탐색해야 하므로 비효율적입니다. 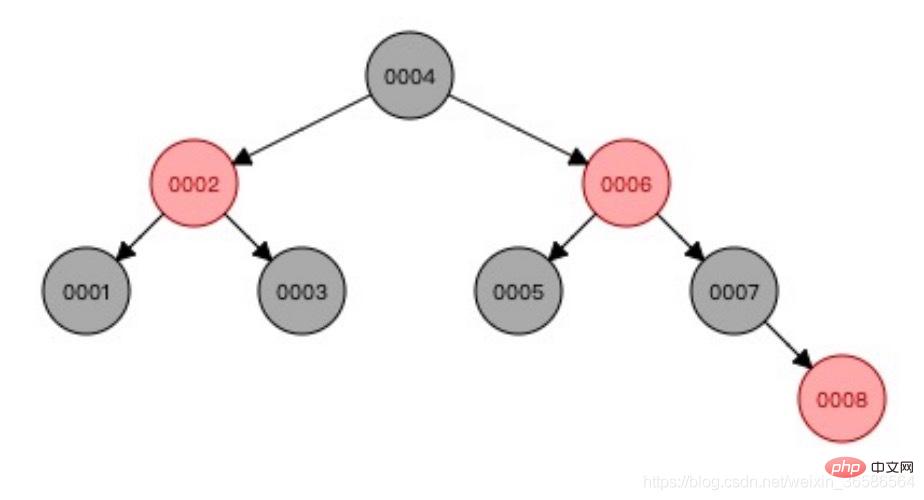
(3) Hash
1. 인덱스 키에 대한 해시 계산을 통해 데이터 저장 위치를 찾을 수 있습니다
2. 많은 경우 B+ 트리 인덱스보다 해시 인덱스가 더 효율적입니다
3. "="만 가능합니다. 만족, "IN", 범위 쿼리는 지원되지 않습니다
4. 해시 충돌 문제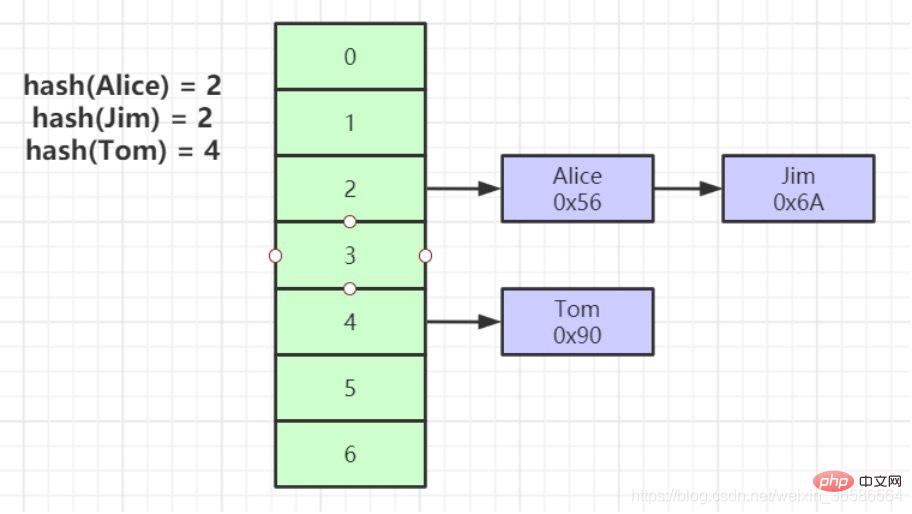
(4) B-Tree
1. 리프 노드의 깊이가 동일하고 리프 노드의 포인터가 비어 있습니다.
2. 모두; 인덱스 요소는 반복되지 않습니다.
3. 노드의 데이터 인덱스는 왼쪽에서 오른쪽으로 오름차순으로 정렬됩니다. 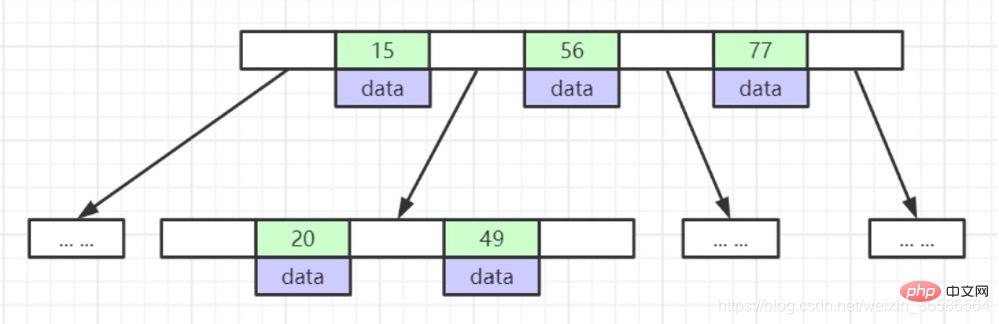
(5) B+Tree(B-Tree 변형)
1. 리프가 아닌 노드는 반복되지 않습니다. 데이터 저장, 인덱스만(중복), 더 많은 인덱스 배치 가능
2. 리프 노드에는 모든 인덱스 필드가 포함됨
3. 리프 노드는 포인터로 연결되어 간격 액세스 성능 향상
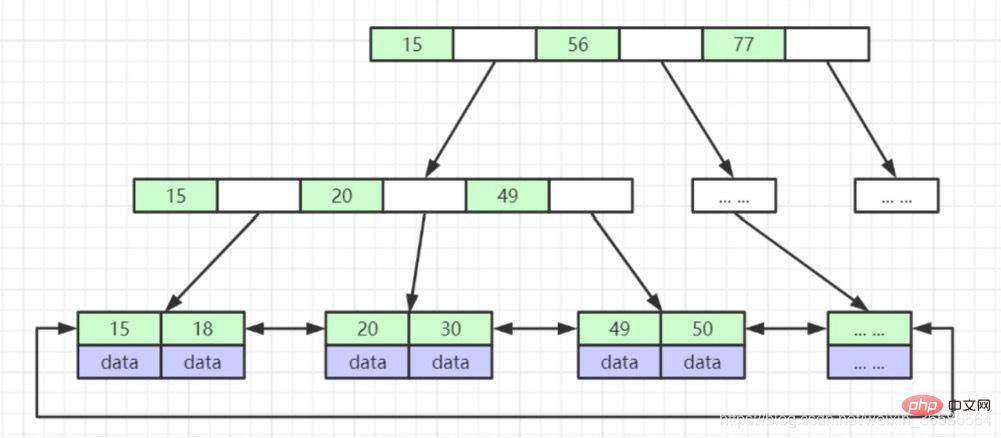
3. 리프 노드의 행 수 데이터는 InnoDB 저장소에 B+ 트리를 저장할 수 있습니까?
이 질문에 대한 간단한 대답은 약 2천만입니다.
MySQL에서 InnoDB 페이지의 기본 크기는 16k입니다. 물론 매개변수를 통해 설정할 수도 있습니다.
SHOW GLOBAL STATUS LIKE "Innodb_page_size"
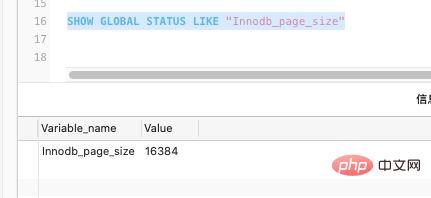
데이터 테이블의 데이터 페이지에 저장되므로 한 페이지에 몇 개의 데이터 행을 저장할 수 있습니까? 데이터 행의 크기를 1k라고 가정하면 페이지는 해당 데이터 행을 16개 저장할 수 있습니다.
이런 식으로 데이터베이스만 저장하면 데이터를 어떻게 찾는지가 문제가 됩니다
찾고자 하는 데이터가 어느 페이지에 있는지도 모르고, 모든 페이지를 순회하는 것도 불가능하기 때문입니다. 너무 느림.
그래서 사람들은 B+ 트리를 이용하여 이 데이터를 정리하는 방법을 생각해냈습니다. 그림과 같이: 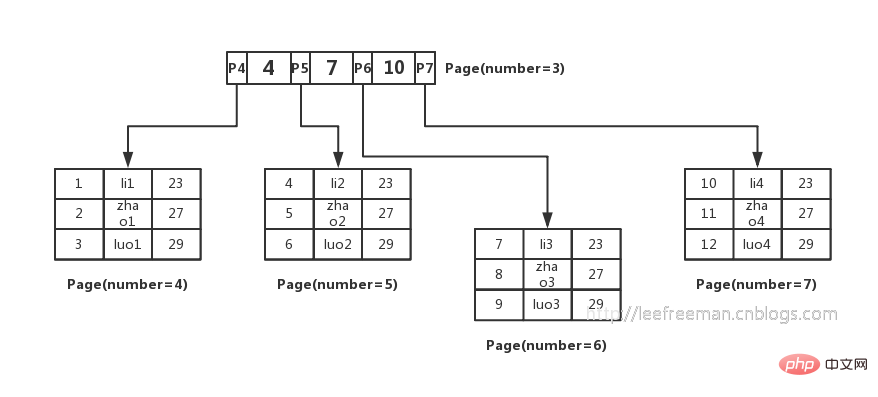
InnoDB의 기본 키 인덱스 B+ 트리가 데이터를 구성하고 데이터를 쿼리하는 방법을 요약해 보겠습니다.
1. InnoDB 스토리지 엔진의 가장 작은 저장 단위는 페이지를 사용하여 저장할 수 있습니다. 데이터 또는 사용 키 값 + 포인터를 저장하기 위해 B+ 트리의 리프 노드는 데이터를 저장하고 리프가 아닌 노드는 키 값 + 포인터를 저장합니다.
2. 인덱스 구성 테이블은 리프가 아닌 노드와 포인터의 이진 검색 방법을 통해 데이터가 어느 페이지에 있는지 확인한 다음 데이터 페이지에서 필요한 데이터를 찾습니다.
그래서 우리가 시작한 문제로 돌아갑니다. , 일반적으로 B+ 트리에는 몇 개의 데이터 행이 포함될 수 있습니까?
여기서 먼저 B+ 트리의 높이가 2라고 가정합니다. 즉, 하나의 루트 노드와 여러 개의 리프 노드가 있다고 가정합니다. 그러면 이 B+ 트리에 저장된 총 레코드 수는 루트 노드 포인터 수 * 단일 리프 노드의 레코드 행 수입니다.
위에서 단일 리프 노드(페이지)의 레코드 수 = 16K/1K=16이라고 설명했습니다. (여기에서는 레코드 한 행의 데이터 크기를 1K로 가정합니다. 실제로 많은 인터넷 비즈니스 데이터의 레코드 크기는 일반적으로 1K 정도입니다.)
이제 리프가 아닌 노드에 얼마나 많은 포인터를 저장할 수 있는지 계산해야 합니까?
사실 이는 계산하기 쉽습니다. 기본 키 ID가 bigint 유형이고 길이가 8바이트라고 가정합니다. InnoDB 소스 코드에서는 포인터 크기가 6바이트로 설정되어 있으므로 총 14바이트입니다.
한 페이지에 얼마나 저장할 수 있나요? 이러한 단위는 실제로 포인터의 수, 즉 16384/14=1170을 나타냅니다. 그러면 높이 2의 B+ 트리가 1170*16=18720개의 데이터 레코드를 저장할 수 있다는 것을 계산할 수 있습니다. 같은 원리를 바탕으로 높이가 3인 B+ 트리는 1170*1170*16=21902400개의 레코드를 저장할 수 있다고 계산할 수 있습니다. 그래서 InnoDB에서는 B+ 트리 높이가 일반적으로 1~3레이어로 수천만 개의 데이터 저장 공간을 만족할 수 있습니다.데이터 검색 시 한 페이지 검색은 하나의 IO를 나타내므로 기본 키 인덱스를 통한 쿼리에는 일반적으로 데이터를 찾는 데 1~3개의 IO 작업만 필요합니다.
4. MySQL의 인덱스는 왜 B 트리와 같은 다른 트리 구조 대신 B+ 트리를 사용합니까?
B-tree
리프 노드의 깊이는 동일하고, 리프 노드의 포인터는 비어 있습니다.
모든 인덱스 요소는 반복되지 않습니다.
노드의 데이터 인덱스는 왼쪽에서 오른쪽으로 증분적으로 배열됩니다.
B+ 트리 인덱스
리프가 아닌 노드는 데이터를 저장하지 않으며 인덱스만(중복), 더 많은 인덱스를 배치할 수 있습니다.
리프 노드에는 모든 인덱스 필드가 포함됩니다.
리프 노드는 포인터로 연결되어 간격 액세스 성능이 향상됩니다.
데이터 노드가 이동되는 이유 리프 노드에 대해 하나의 노드는 더 많은 인덱스
16^n=2천만을 저장할 수 있습니다. n은 트리의 높이이며 동일한 데이터를 저장하며 B+ 트리의 높이는 B 트리
보다 훨씬 작습니다. 리프 노드나 비리프 노드에 관계없이 데이터를 저장하게 되며, 이로 인해 비리프 노드에 저장할 수 있는 포인터 수가 줄어듭니다(일부 데이터는 포인터가 적을 때 팬아웃이라고도 함). 많은 양의 데이터를 저장해야 하므로 트리 높이만 증가할 수 있으며 결과적으로 IO 작업이 늘어나고 쿼리 성능이 저하됩니다. ;
5. 스토리지 엔진 인덱스 구현
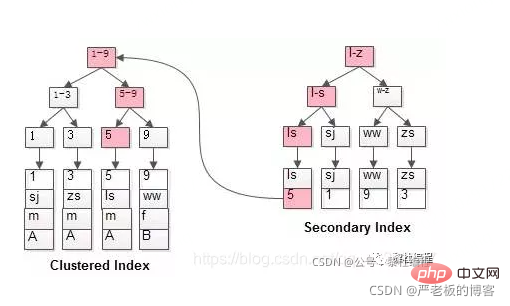
클러스터형 인덱스의 의미: 리프 노드 저장소 인덱스와 데이터, 클러스터형 인덱스라고도 합니다.
비클러스터형 인덱스는 희소 인덱스라고도 합니다. 기본 키 인덱스는 클러스터형 인덱스입니다!
(1) MyISAM 인덱스 파일과 데이터 파일은 분리(비집합)
인덱스 파일은 인덱스와 데이터를 저장합니다. files store 데이터, 인덱스, 데이터는 함께 저장되지 않습니다
쿼리: 먼저 B+ 트리에서 인덱스를 쿼리한 다음 쿼리된 위치를 사용하여 데이터 파일을 쿼리합니다. 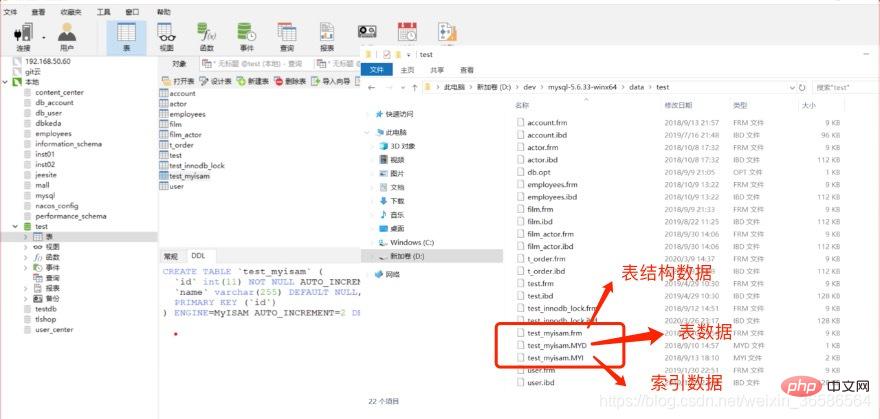
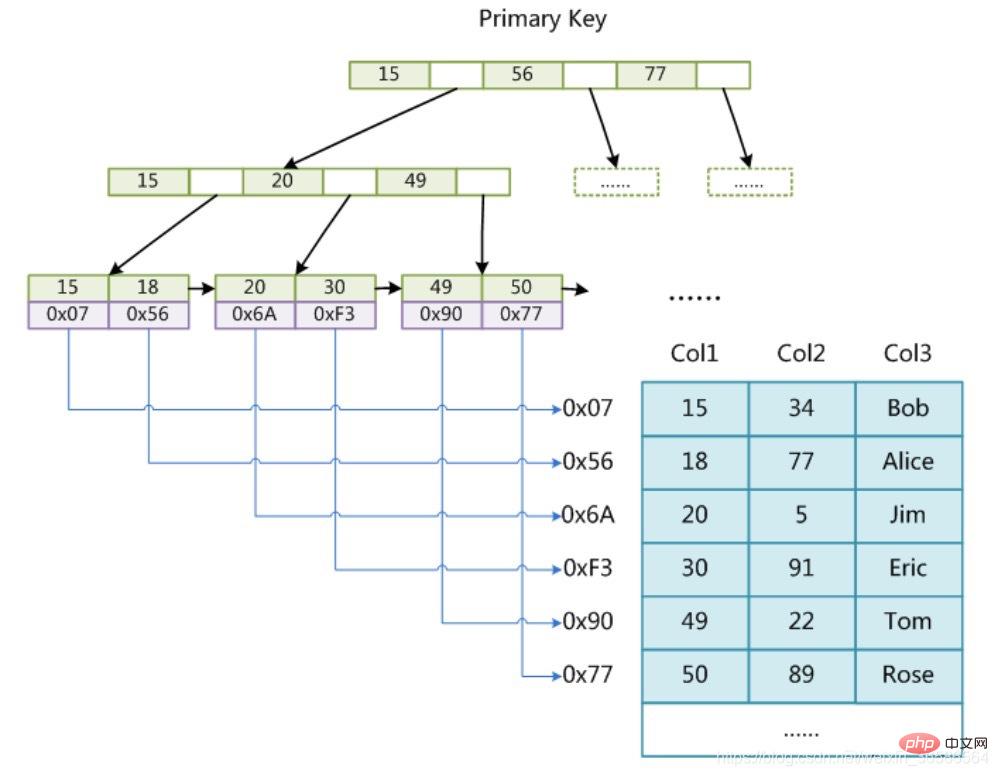 (1) InnoDB 인덱스 구현
(1) InnoDB 인덱스 구현
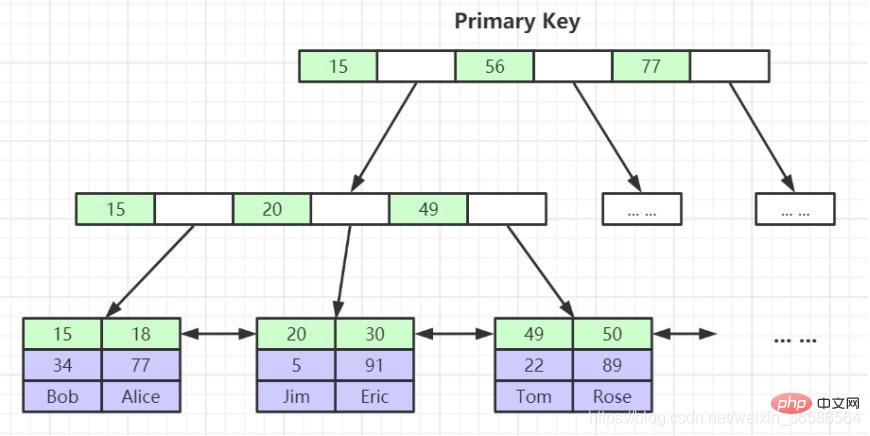
 1. 테이블 데이터 파일 자체는 B+Tree
1. 테이블 데이터 파일 자체는 B+Tree
(1) 기본 키 인덱스:
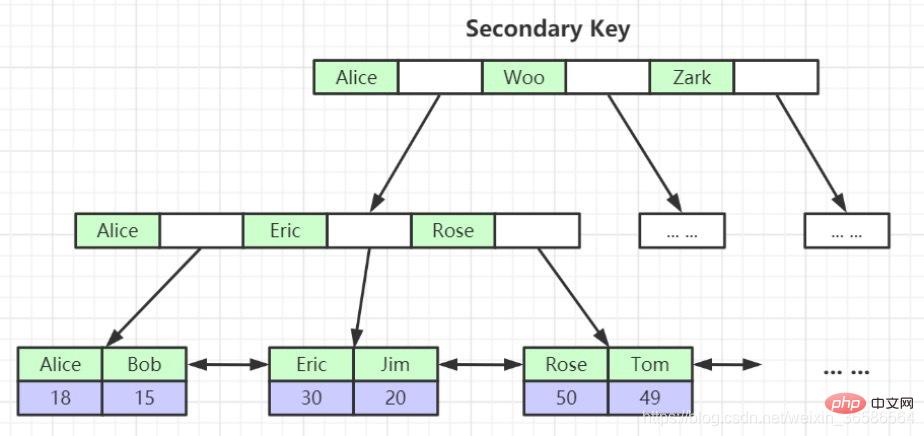
 (2) 보조 인덱스(보조 인덱스)
(2) 보조 인덱스(보조 인덱스)
보조 인덱스는 여러 면에서 클러스터형 인덱스와 다릅니다.
- 리프 노드는 전체 사용자 레코드를 저장하지 않고 인덱스 열 + 기본 키
- 만 저장합니다. . 디렉토리 항목 레코드는 기본 키 + 페이지 번호가 아닌 색인 열 + 페이지 번호
- 입니다. 보조 인덱스에서 데이터를 검색할 때는 기본 키 값을 기준으로 클러스터형 인덱스에서 전체 사용자 레코드를 검색해야 합니다. 이 프로세스를 테이블로 돌아가기
 (3)이라고 합니다. 조인트 인덱스:
(3)이라고 합니다. 조인트 인덱스:
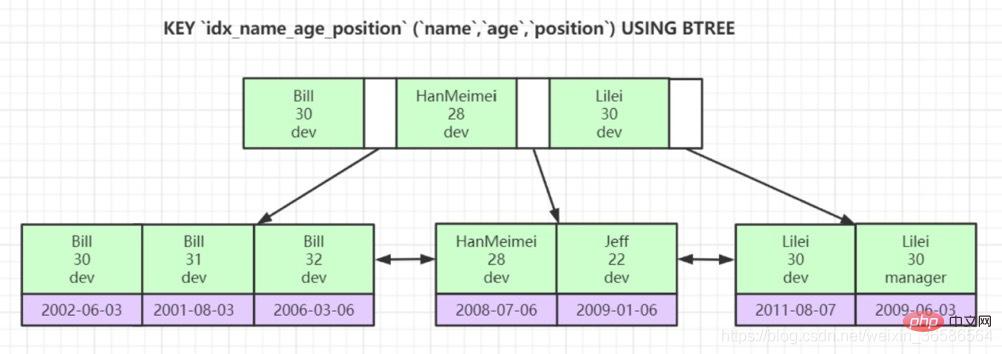
 3. InnoDB 테이블에 기본 키가 있어야 하는 이유는 무엇이며 정수 자동 증가 기본 키를 사용하는 것이 권장되는 이유는 무엇입니까?
3. InnoDB 테이블에 기본 키가 있어야 하는 이유는 무엇이며 정수 자동 증가 기본 키를 사용하는 것이 권장되는 이유는 무엇입니까?
(2) 정수 자동 증가 기본 키를 사용하지 않고 UUID를 기본 키로 사용하면 어떻게 되나요?
UUID는 문자열 유형입니다. 정수 비교 작업은 UUID보다 공간을 절약합니다.
(3) HASH 인덱스: 값이 해시되고 계산됩니다. value는 sum 저장 위치가 하나씩 매핑됩니다.
Hash를 사용하면 어떨까요?
해시는 범위 쿼리를 잘 지원하지 않습니다. 특정 열의 데이터는 순서가 없으며 B+ 트리는 구축 시 데이터를 순서대로 만들 수 있습니다.
4. 기본 키가 아닌 인덱스 구조의 리프 노드는 왜 기본 키 값을 저장하나요? (일관성 및 저장공간 절약)
6. B+ 트리 인덱스 요약
1. 각 인덱스는 B+ 트리에 해당합니다. 사용자 레코드는 B+ 트리의 리프 노드에 저장되고 모든 디렉터리 레코드는 리프가 아닌 노드에 저장됩니다.
2. InnoDB 스토리지 엔진은 자동으로 클러스터형 인덱스를 기본 키로 생성합니다(클러스터형 인덱스가 없으면 자동으로 추가합니다). 클러스터형 인덱스의 리프 노드에는 전체 사용자 레코드가 포함됩니다.
3. 지정된 컬럼에 대한 보조 인덱스를 생성할 수 있습니다. 보조 인덱스의 리프 노드에 포함된 사용자 레코드는 인덱스 컬럼 + 기본 키로 구성됩니다. 따라서 보조 인덱스를 통해 완전한 사용자 레코드를 찾고 싶다면. index, 테이블을 반환해야 합니다. 작업 은 보조 인덱스를 통해 기본 키 값을 찾은 후 클러스터형 인덱스에서 전체 사용자 레코드를 찾는 것입니다.
4. B+ 트리의 각 레벨에 있는 노드는 인덱스 열 값에 따라 작은 것부터 큰 것 순으로 정렬되어 이중 연결 리스트를 형성하며, 각 페이지의 레코드(사용자 레코드인지 디렉토리 항목인지 여부) 레코드)은 인덱스에 따라 정렬되며 열 값은 오름차순으로 단일 연결 목록을 형성합니다. 결합 색인인 경우에는 결합 색인 앞의 열을 기준으로 페이지와 레코드를 먼저 정렬합니다. 열 값이 동일하면 결합 색인 뒤의 열을 기준으로 정렬됩니다.
색인을 통한 레코드 검색은 B+ 트리의 루트 노드부터 시작하여 아래로 한 층씩 검색합니다. 각 페이지에는 인덱스 열의 값을 기반으로 하는 페이지 디렉터리가 있으므로 이러한 페이지의 검색 속도는 매우 빠릅니다.
일곱. Mysql 인덱스가 실패하는 여러 상황 요약
블로그 보기: Mysql 인덱스가 실패하는 여러 상황 요약
https://blog.csdn.net/weixin_36586564/article/details/79641748
[관련 추천: mysql 동영상 튜토리얼]
위 내용은 mysql의 인덱스 심층 분석(원리 상세 설명)의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!