
Python 데이터 분석: Pandas가 Excel 테이블을 처리합니다.

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWB앞으로
- 2022-05-13 13:39:224216검색
이 글은 python에 대한 관련 지식을 제공합니다. 주로 다른 파일 읽기, 피벗 테이블 및 기타 관련 콘텐츠를 포함하여 데이터 분석의 기본 사항에 대해 소개합니다. 모두에게 도움이 되기를 바랍니다.

권장 학습: python 비디오 튜토리얼
(1) 다른 파일 읽기
다음으로 세 가지 유형의 파일 csvtsvtxt 파일을 읽습니다. 이 세 가지 유형의 파일, 즉 pd.read_csv(file)에 메서드를 사용합니다. 엑셀 테이블을 읽을 때 구분 기호에 주의하고 sep='' 매개 변수를 사용하여 구분해야 합니다. 다음으로 엑셀과 팬더에서 어떻게 조작하는지 살펴보겠습니다!
1. Excel은 다른 파일을 읽습니다
Excel에서 외부 데이터 가져오기

1.1 csv 파일 가져오기
csv 파일을 가져올 때 구분 기호로 쉼표를 선택하면 됩니다.
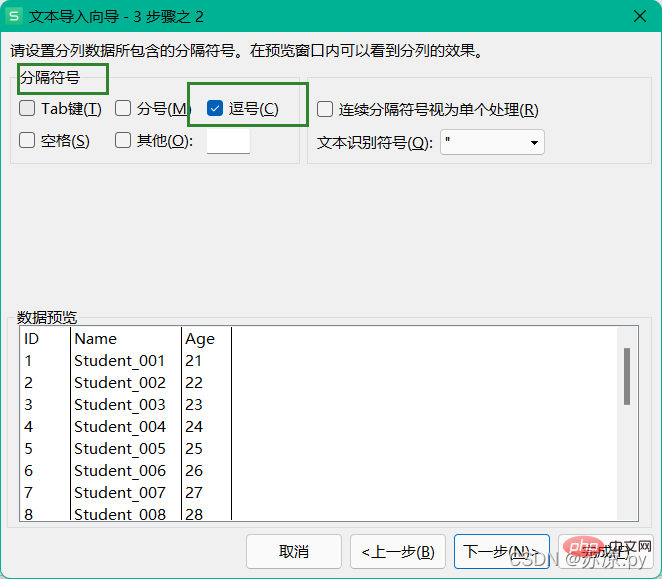
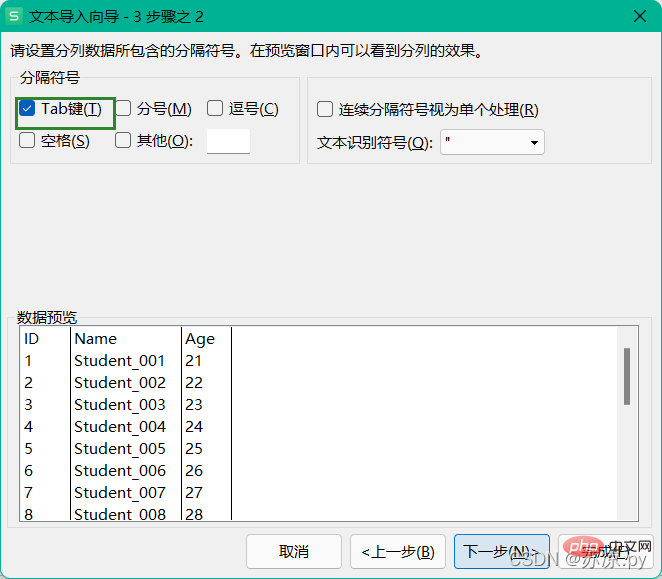
1.2 tsv 파일 가져오기
tsv 파일 가져오기, 구분 기호로 탭 키 선택
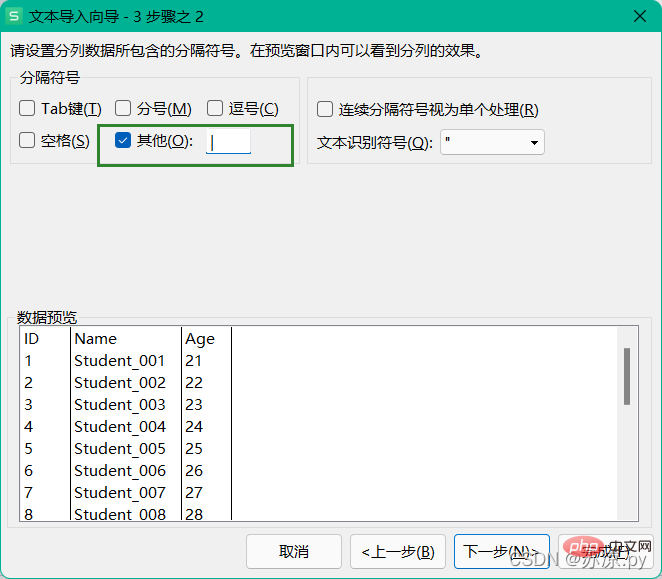
1.3 txt 텍스트 파일 가져오기
txt 파일을 가져올 때 어떤 기호가 사용되는지 주의하세요. 텍스트, 사용자 정의 구분 기호를 분리하십시오.
2.pandas는 다른 파일을 읽습니다
pandas에서는 csv 파일, tsv 파일 또는 txt 파일을 읽는지 여부에 관계없이 read_csv() 메서드와 sep( ) 매개 변수를 사용하여 읽습니다.
2.1 csv 파일 읽기
import pandas as pd
# 导入csv文件
test1 = pd.read_csv('./excel/test12.csv',index_col="ID")
df1 = pd.DataFrame(test1)
print(df1)
2.2 tsv 파일 읽기
탭 키는 t
import pandas as pd
# 导入tsv文件
test3 = pd.read_csv("./excel/test11.tsv",sep='\t')
df3 = pd.DataFrame(test3)
print(df3)
2.3 txt 파일 읽기
import pandas as pd
# 导入txt文件
test2 = pd.read_csv("./excel/test13.txt",sep='|')
df2 = pd.DataFrame(test2)
print(df2)
로 표시됩니다. 결과: 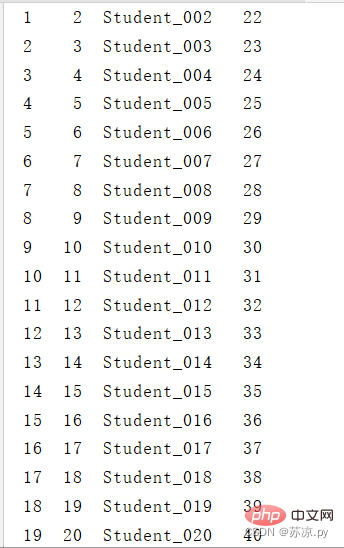
( 2) 데이터 관점 테이블
엑셀에는 많은 종류의 데이터가 있는데, 그 종류가 여러 가지로 나누어져 있습니다. 이때 피벗 테이블을 이용하면 우리가 원하는 다양한 데이터를 분석하는데 매우 편리하고 직관적이 될 것입니다.
예: 다음 데이터를 피벗 테이블에 플롯하고 일반 카테고리별 연간 매출을 플롯합니다!
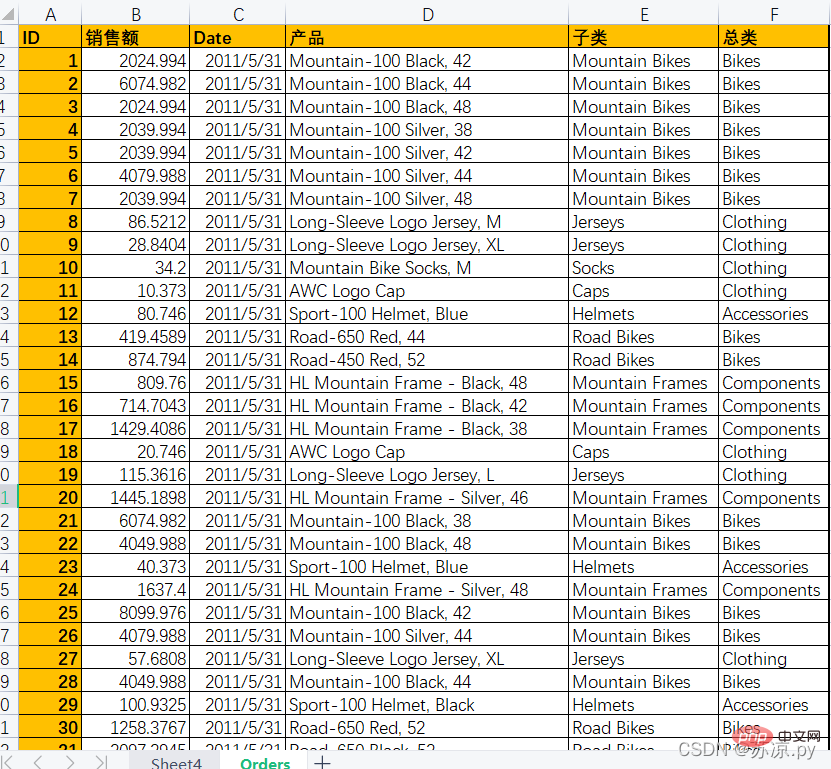
1. Excel에서 피벗 테이블 만들기
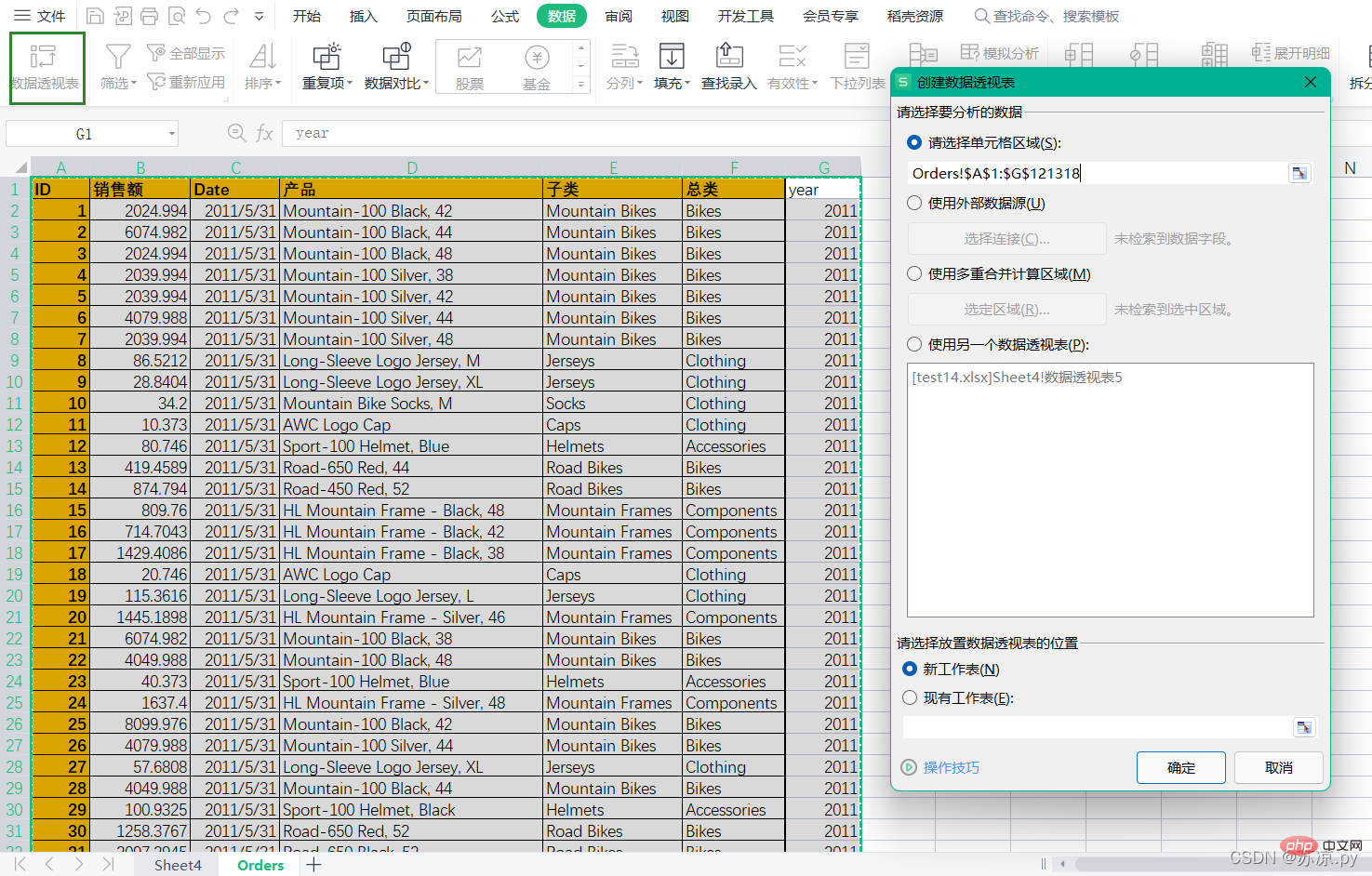
연도별로 나눈 다음 날짜 열을 분할하고 연도를 분할해야 합니다. 그런 다음 데이터 열 아래의 피벗 테이블을 선택하고 영역을 선택합니다.
그런 다음 데이터의 각 부분을 각 영역으로 드래그하세요.
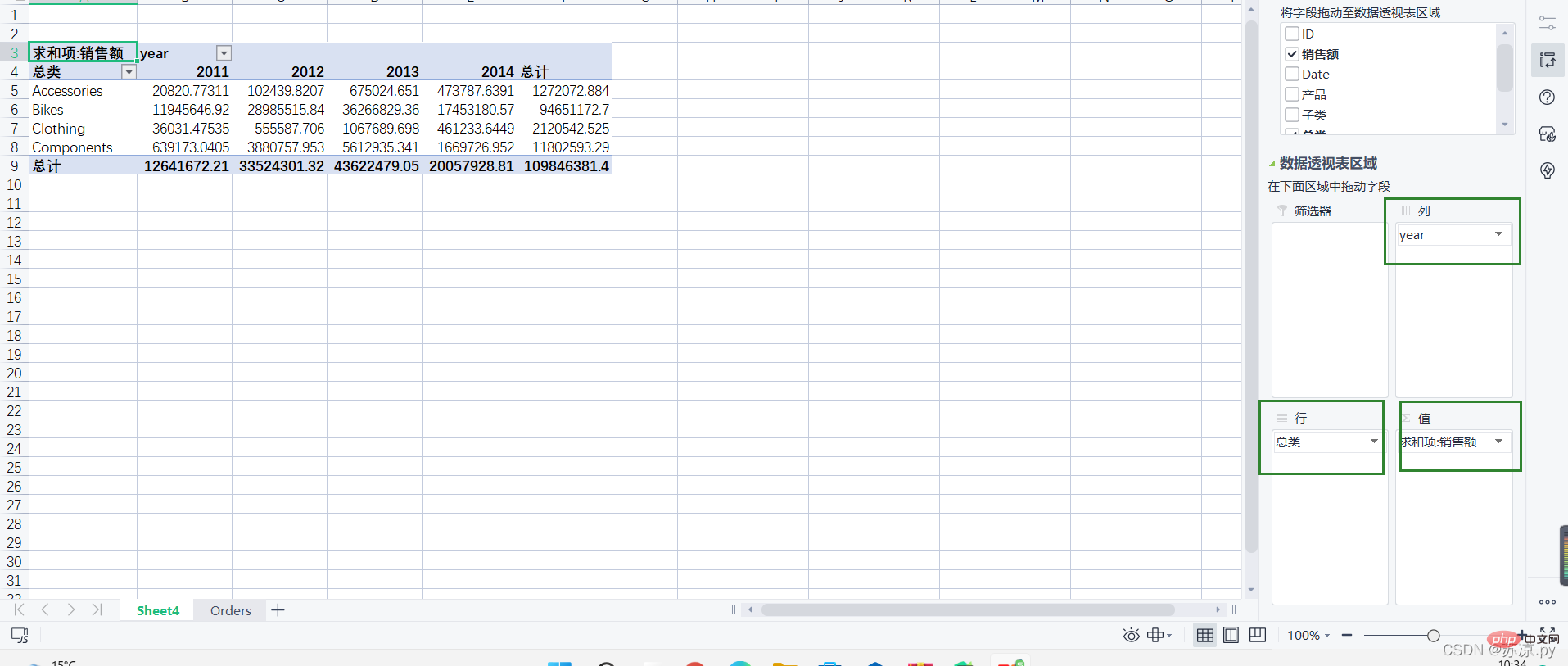
결과: 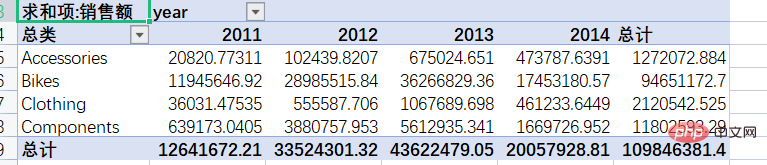
이렇게 엑셀 피벗 테이블 생성이 완료되었습니다.
그럼 팬더에서 이 효과를 얻는 방법은 무엇일까요?
2. 팬더에서 피벗 테이블 그리기
피벗 테이블을 그리는 함수는 df.pivot_lable(index, columns, value)이며 마지막으로 데이터를 합산합니다.
import pandas as pd
import numpy as np
pd.options.display.max_columns =999
test = pd.read_excel('./excel/test14.xlsx')
df = pd.DataFrame(test)
# 将年份取出并新建一个列名为年份的列
df['year'] = pd.DatetimeIndex(df['Date']).year
# 绘制透视表
table = df.pivot_table(index='总类',columns='year',values='销售额',aggfunc=np.sum)
df1 = pd.DataFrame(table)
df1['总计'] = df1[[2011,2012,2013,2014]].sum(axis=1)
print(df1)
결과: 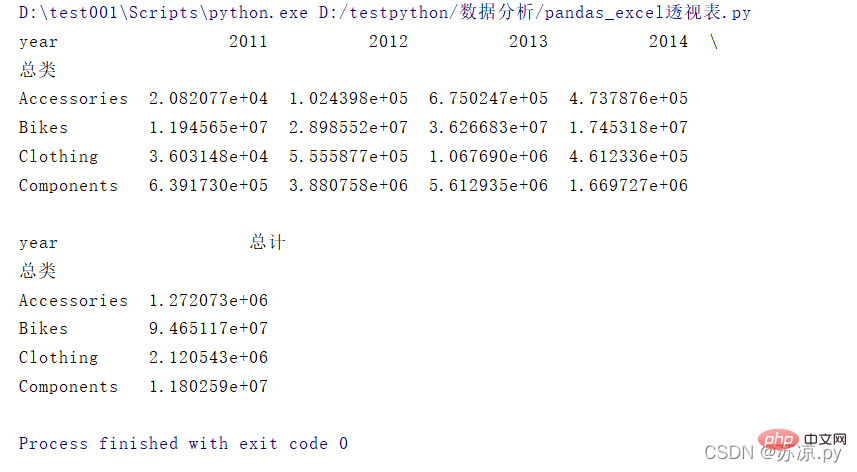
또한 groupby 기능을 사용하여 데이터 테이블을 그릴 수도 있습니다. 여기서는 총 카테고리와 연도를 그룹화하여 총 판매량과 판매량을 계산합니다.
import pandas as pd
import numpy as np
pd.options.display.max_columns =999
test = pd.read_excel('./excel/test14.xlsx')
df = pd.DataFrame(test)
# 将年份取出并新建一个列名为年份的列
df['year'] = pd.DatetimeIndex(df['Date']).year
# groupby方法
group = df.groupby(['总类','year'])
s= group['销售额'].sum()
c = group['ID'].count()
table = pd.DataFrame({'sum':s,'total':c})
print(table)
결과: 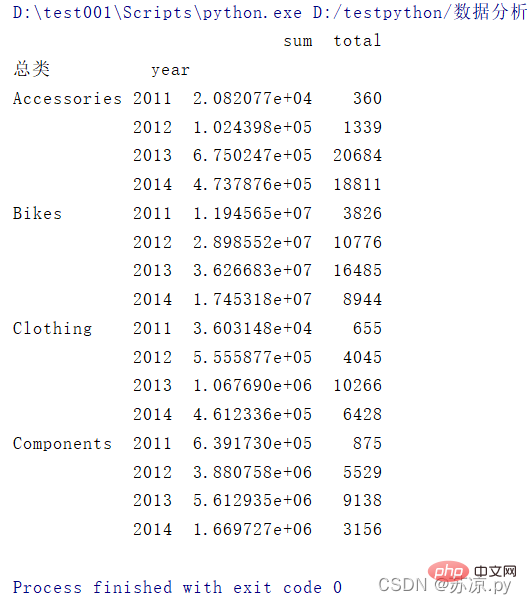
추천 학습: python 비디오 튜토리얼
위 내용은 Python 데이터 분석: Pandas가 Excel 테이블을 처리합니다.의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!