
집 >데이터 베이스 >MySQL 튜토리얼 >MySQL 설명을 완전히 마스터하세요
MySQL 설명을 완전히 마스터하세요

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWB앞으로
- 2022-04-01 13:21:212297검색
이 기사는 mysql에 대한 관련 지식을 제공하며, Mysql의 explain은 mysql의 성능 최적화 분석 도구라고 할 수 있습니다. 구현된 내용입니다. 그것은 모두에게 도움이 됩니다.

추천 학습: mysql 동영상 튜토리얼
데이터베이스 성능 최적화는 모든 백엔드 프로그래머가 갖추어야 할 기본 기술 중 하나이며, Mysql에서의 설명은 Mysql의 성능 최적화 분석 아티팩트라고 할 수 있습니다. use MySQL의 하단에서 해당 SQL 문의 실행 계획이 어떻게 실행되는지 분석하는 것은 SQL의 실행 효율성을 평가하고 Mysql의 성능 최적화 방향을 결정하는 데 큰 의미가 있습니다. 하지만, 여전히 많은 학생들이 explain을 기반으로 기존 SQL의 심층적인 실행 분석을 어떻게 해야 하는지에 대해 혼란스러워하고 있습니다. 따라서 본 글에서는 explain 분석을 통해 데이터베이스 성능 문제를 찾아내는 방법을 자세히 설명합니다.
Explain Basics
각 SQL에 대해 클라이언트가 MySQL 서버로 전송하면 Mysql 최적화 구성 요소에 의해 분석됩니다. 여기에는 주로 최적의 실행 효율성을 보장하기 위해 몇 가지 특별한 처리 및 실행 순서 변경이 포함됩니다. 마지막으로 해당 실행 계획을 생성합니다. 소위 실행 계획은 실제로 스토리지 엔진 수준에서 데이터를 얻는 방법을 의미합니다. 인덱스를 통해 데이터를 얻을 것인지, 전체 테이블 스캔을 통해 데이터를 얻을 것인지, 데이터를 얻은 후 테이블을 반환해야 하는지 등을 간단히 이해합니다. MySQL에서 데이터를 얻는 과정입니다.
다음으로, 이 설명이 무엇인지, 왜 성능 최적화에 지침이 될 수 있는지 자세히 살펴보겠습니다. 다음 명령문을 실행하면
explain SELECT * FROM user_info where NAME='mufeng'
Explain 명령문을 실행한 후 다음과 같은 실행 결과를 얻게 됩니다. 데이터베이스 테이블과 유사한 이 12개 필드는 실제로 Mysql에서 실행되는 실행 계획에 대한 자세한 설명입니다. 이 12개의 필드가 무엇을 의미하는지 자세히 살펴보겠습니다. 해당 의미를 이해해야만 MySQL이 데이터 쿼리를 수행하는 방법을 이해할 수 있습니다.

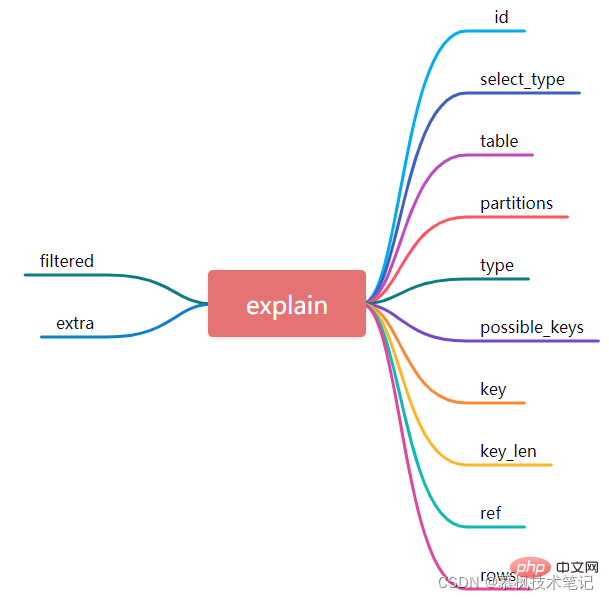
1.id
실제로 각 선택 쿼리는 SQL 실행 순서를 나타내는 ID에 해당합니다. ID 값이 클수록 해당 SQL 문의 우선 순위가 높아집니다. 실행력이 높다. 일부 복잡한 쿼리 SQL 문에는 일부 하위 쿼리가 포함되는 경우가 많으며, 중첩 쿼리가 있는 경우 가장 안쪽 쿼리가 가장 큰 ID에 해당하므로 먼저 실행됩니다.

위 그림과 같이 SQL 쿼리문에서 첫 번째 실행 계획의 ID는 1, 두 번째 실행 계획의 ID는 2, ID가 1인 실행 계획에 해당하는 테이블은 order입니다. , id는 2입니다. 실행 계획에 해당하는 테이블은 user_info입니다. SQL 문과 결합하면 user_info의 하위 쿼리 select id가 먼저 실행된 다음 테이블 순서에 대한 데이터 쿼리가 실행되는 것을 알 수 있습니다.
2. select_type
select_type은 실행 계획에 해당하는 쿼리 유형을 나타냅니다. 일반적인 쿼리 유형에는 주로 일반 쿼리, 결합 쿼리, 하위 쿼리가 있습니다. SIMPLE(쿼리문은 단순 쿼리이고 하위 쿼리를 포함하지 않음), PRIMARY(쿼리문에 하위 쿼리가 포함된 경우 가장 바깥쪽 쿼리 유형에 해당), UNION(Union 뒤에 나타나는 Select 문에 해당하는 쿼리 유형이 표시됨) 이 유형), SUBQUERY(서브 쿼리가 이 유형으로 표시됨), DEPENDENT SUBQUERY(외부 쿼리에 따라 다름)

3, table
table은 테이블 이름을 나타내며 쿼리할 테이블을 나타냅니다. 물론 반드시 실제 테이블의 이름은 아니며, 테이블의 별칭일 수도 있고 임시 테이블일 수도 있습니다.
4, partitions
partitions는 파티션의 개념을 나타냅니다. 즉, 쿼리할 때 해당 테이블이 데드 파티션 테이블인 경우 특정 파티션 정보가 여기에 표시됩니다.
5.type
type은 마스터해야 할 매우 핵심 속성입니다. 데이터베이스 테이블에 액세스하는 현재 방법을 나타냅니다.
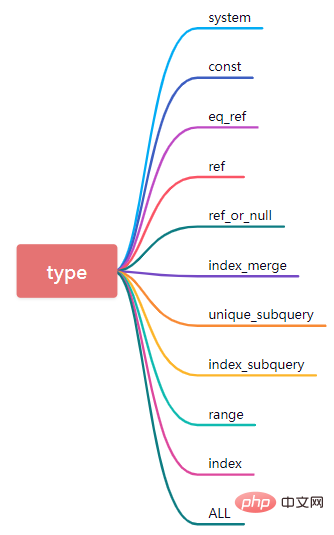
(1)시스템
테이블에는 행이 하나만 있고(시스템 테이블과 동일) 데이터 양이 적고 쿼리 속도가 매우 빠릅니다. 시스템은 const 유형의 특수한 경우입니다.
(2) const
유형이 const인 경우 데이터 쿼리를 수행할 때 기본 키 또는 고유 인덱스가 적중된다는 의미입니다. 이러한 유형의 데이터 쿼리는 매우 빠릅니다.

(3) eq_ref
데이터 쿼리 과정에서 테이블 연결 시 데이터를 기억하기 위해 SQL 문이 클러스터형 인덱스나 null이 아닌 값의 고유 인덱스를 기반으로 할 수 있다면, 이 시간에 해당하는 유형의 값이 eq_ref로 표시됩니다.
(4) ref
데이터 쿼리 시 히트 인덱스가 고유 인덱스가 아닌 보조 인덱스인 경우 테스트 쿼리 속도는 매우 빠르지만 유형은 ref입니다. 또한 다중 필드 조인트 인덱스인 경우 가장 왼쪽 일치 원칙에 따라 조인트 인덱스의 가장 왼쪽부터 시작하여 여러 연속 열의 필드에 대한 동일성 비교도 ref 유형입니다.

(5) ref_or_null
이 조인 유형은 ref와 유사하지만 차이점은 MySQL이 NULL 값이 포함된 행을 추가로 검색한다는 것입니다.
(7) Unique_subquery
where 조건
(8) index_subquery
의 in에 대한 하위 쿼리 조건 집합은 고유하지 않은 인덱스에 사용되는 Unique_subquery와 다르며 중복 값을 반환할 수 있습니다.
(9)range
행 데이터를 검색하려면 인덱스를 사용하고, 지정된 범위 내의 행 데이터만 검색합니다. 즉, 인덱스된 필드에 대해 지정된 범위의 데이터를 검색하는 것입니다. where 문에서 bettween...and, <, >, <=, in 및 기타 조건부 쿼리 유형을 사용하는 경우 유형은 범위입니다.

(10) index
Index와 ALL은 실제로 테이블 전체를 읽는 반면, ALL은 하드 디스크에서 읽는 반면, 인덱스는 인덱스 트리를 순회하여 읽습니다.
(11)all
데이터 매칭을 위해 전체 테이블을 순회합니다. 이때의 데이터 쿼리 성능은 최악입니다.
6.possible_keys
는 Mysql 최적화 프로그램이 선택할 수 있는 인덱스, 즉 어떤 인덱스 후보가 있는지 나타냅니다.
7, key
possible_keys
8, key_len
에서 실제로 선택된 인덱스는 인덱스의 길이를 나타내며 실제 필드 속성 및 null 여부와 관련됩니다.
9, ref
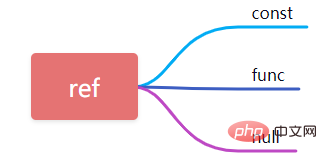
상수 동등 쿼리에 필드를 사용할 경우 여기서 ref는 const입니다. 쿼리 조건에 표현식이나 함수를 사용하면 ref는 func로 표시되고 나머지는 null로 표시됩니다.
10,rows
행 열은 MySQL이 쿼리를 실행할 때 확인해야 한다고 생각하는 행 수를 표시합니다. 행 수가 적을수록 더 효율적입니다!
11.filtered
filtered 테이블의 조건을 충족하는 레코드 수의 백분율인 백분율 값입니다. 간단히 말하면, 이 필드는 스토리지 엔진에서 반환된 데이터를 필터링한 후 조건을 충족하는 나머지 레코드의 비율을 나타냅니다.
12.extra
추가 정보는 다른 열에는 표시되지 않지만 이 열에는 표시됩니다.
(1) 인덱스 사용
데이터 쿼리를 수행할 때 데이터베이스는 커버링 인덱스를 사용합니다. 즉, 쿼리된 열이 인덱스에 의해 커버됩니다. 쿼리 속도는 매우 빠릅니다. select *를 사용하는 대신 커버링 인덱스를 사용하는 selectphone_number를 사용하세요.

(2) where 사용
쿼리 중에 사용 가능한 인덱스가 없으며 where 조건 필터링을 통해 필요한 데이터를 얻습니다. 그러나 where 문이 있는 모든 쿼리에 Using where가 표시되는 것은 아닙니다.

(3) temporary
를 사용한다는 것은 쿼리 결과를 임시 테이블에 저장해야 한다는 의미인데, 일반적으로 쿼리를 정렬하거나 그룹화할 때 사용됩니다.
(4) filesort 사용
이 유형은 지정된 정렬 작업을 완료하는 데 인덱스를 사용할 수 없음을 의미합니다. 즉, ORDER BY 필드에는 실제로 인덱스가 없으므로 이러한 유형의 SQL을 최적화해야 합니다.
exlpain分析实战
上文中我们阐述了explain在分析SQL语句时,可以通过12个属性来分析SQL的大致执行过程,并以此来判断SQL存在的性能问题。那么接下来我们通过一个实际的例子,来具体看下如何结合explain来实现SQL的性能分析。
其实所谓的Mysql性能问题,大部分都指的是平台出现了慢查询问题。慢查询实际上是可以通过配置进行记录的,把执行时间超过某个设定的阈值的sql都记录下来,当出现问题的时候可以通过记录的慢查询日志进行问题的定位。但是有的时候,出现大量慢查询会导致数据库连接给占满,导致整个平台的出现异常。
实际上我们在产品评价表product_evaluation中是建立了索引的,正常来说应该是可以使用到对应的索引字段进行查询的。但是实际上查询耗时有几十秒的时间,远远超过我们的预期。那我们猜测是不是由于某种原因导致Mysql优化器没有选择对应的索引进行数据检索,最后造成慢查询的发生。到底执行计划是怎样的,还是得借助于explain来看下。

如上文所说,虽然explain有12个字段属性帮助我们进行执行计划的分析,但是实际上常用的核心字段也就几个。我们可以看的出来在possible_key中实际上包含了我们设置的索引的,但是实际上Mysql却选择了PRIMARY作为其实际使用的。那么问题来了,为什么明明设置了索引,但是实际并没有用上,呗Mysql吃了吗?另外为什么之前的业务中没有出现这个问题,而现在出现了?我们需要进行进一步的分析。
我们所建立的idx_evaluation_type实际上是一个二级索引(叶子节点是主键id),对于数千万一张的大表来说,实际上这个二级索引也是非常大的,而且这个字段本身的值就三个,变化不大。因此Mysql的优化器在分析这个SQL的时候发现,如果按照SQL中的索引来获取数据后再根据where条件进行筛选,筛选后的数据还需要回表到聚簇索引中获取实际的数据。
假如通过二级索引筛选出来的数据有几万条,而后还需要进行排序,这些操作都是基于临时磁盘我恩建进行的,Mysql判断这种方式的性能可能会很差,因此优化器放弃了原有的数据查询方式,直接通过主键id对应的聚簇索引来进行数据的获取,因为id本身就是有序的。
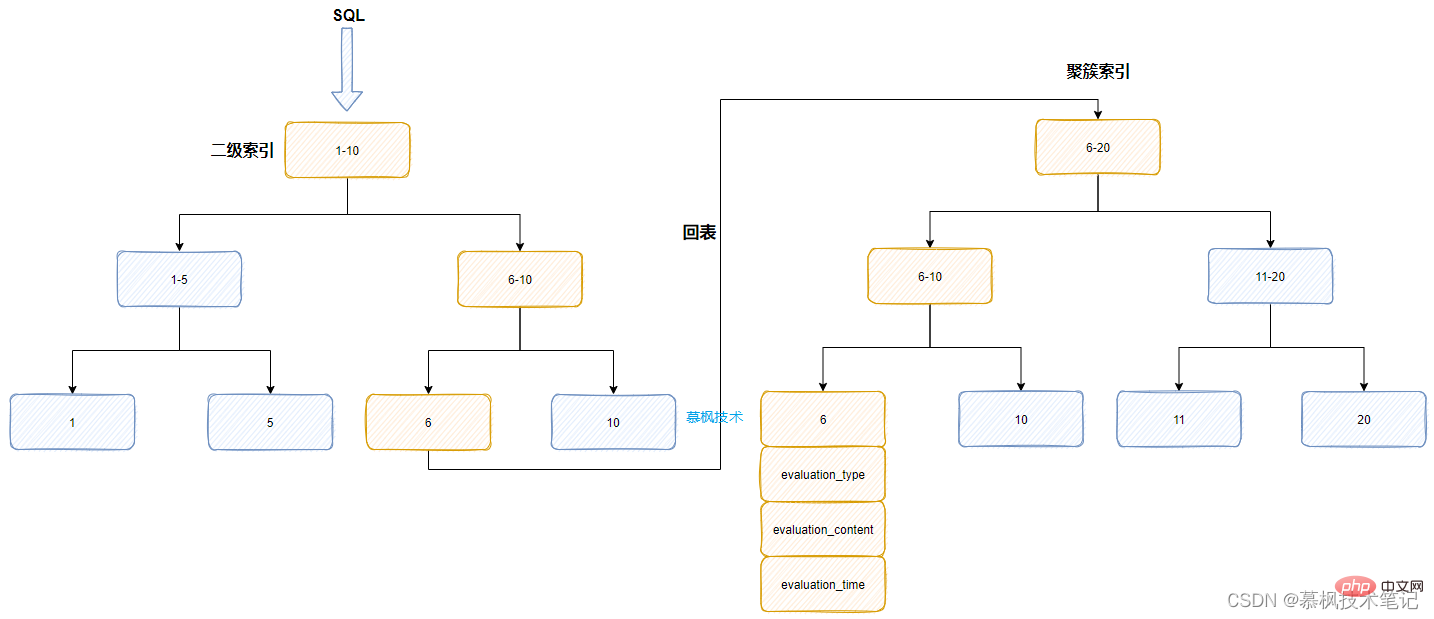
那么知道了查询慢的原因,我们应该怎么进行优化呢?实际上可以在SQL语句中增加force idnex,强制Mysql使用我们设置的二级索引。
SELECT * FROM product_evaluation force index(idx_product_id)WHERE product_id =1 and evaluation_type='GOOD' ORDER BY id desc LIMIT 200
总结
通过上文对于explain使用的介绍,大家在遇到慢SQL问题的时候,可以先通过explain来进行初步的分析,主要明确SQL在Mysql中实际的执行过程是怎样的,如果查询字段没有索引则增加索引,如果有索引就要分析为什么没有用到索引。只要明确具体的执行过程,我们才能确定具体的查询优化方案。
推荐学习:mysql视频教程
위 내용은 MySQL 설명을 완전히 마스터하세요의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!