
사진과 글로 자세한 설명! Java 메모리 모델이란 무엇입니까?

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWB앞으로
- 2022-03-22 18:00:411878검색
이 기사는 메모리 모델이 존재하는 이유, 동시 프로그래밍, 메모리 영역과 하드웨어 메모리 간의 관계 등 메모리 모델과 관련된 문제를 주로 소개하는 java 관련 지식을 제공합니다. 다들 도움이 됐어요.

추천 학습: "java 튜토리얼"
면접 중에 면접관은 종종 "JMM(Java Memory Model)이 무엇인가요?"라고 묻기를 좋아합니다. 』
면접관은 방금 이 질문을 외운 상태였습니다. "Java 메모리는 크게 5가지 부분으로 나뉩니다: 힙, 메소드 영역, 가상 머신 스택, 로컬 메소드 스택, PC 레지스터, 발라발라..."
The 면접관은 고의로 웃으며 빛을 드러냈습니다. "좋아, 오늘 면접은 여기까지야. 돌아가서 알림을 기다려"
일반적으로 "알림을 기다리세요"라는 말을 들으면 이 인터뷰는 아마도 멋있을 것입니다. 왜? 면접관이 개념을 잘못 이해하고 있어서 JMM을 시험해 보고 싶었으나 Java Memory라는 키워드를 듣자마자 팔다리 에세이를 낭독하기 시작했습니다. JMM(Java Memory Model)과 Java 런타임 메모리 영역 사이에는 큰 차이가 있습니다. 계속 읽어보시기 바랍니다. Java内存这几个关键字就开始背诵八股文了。Java内存模型(JMM)和Java运行时内存区域区别可大了呢,不要走开接着往下看,答应我要看完。
1. 为什么要有内存模型?
要想回答这个问题,我们需要先弄懂传统计算机硬件内存架构。好了,我要开始画图了。
1.1. 硬件内存架构

(1)CPU
去过机房的同学都知道,一般在大型服务器上会配置多个CPU,每个CPU还会有多个核,这就意味着多个CPU或者多个核可以同时(并发)工作。如果使用Java 起了一个多线程的任务,很有可能每个 CPU 都会跑一个线程,那么你的任务在某一刻就是真正并发执行了。
(2)CPU Register
CPU Register也就是 CPU 寄存器。CPU 寄存器是 CPU 内部集成的,在寄存器上执行操作的效率要比在主存上高出几个数量级。
(3)CPU Cache Memory
CPU Cache Memory也就是 CPU 高速缓存,相对于寄存器来说,通常也可以成为 L2 二级缓存。相对于硬盘读取速度来说内存读取的效率非常高,但是与 CPU 还是相差数量级,所以在 CPU 和主存间引入了多级缓存,目的是为了做一下缓冲。
(4)Main Memory
Main Memory 就是主存,主存比 L1、L2 缓存要大很多。
注意:部分高端机器还有 L3 三级缓存。
1.2. 缓存一致性问题
由于主存与 CPU 处理器的运算能力之间有数量级的差距,所以在传统计算机内存架构中会引入高速缓存来作为主存和处理器之间的缓冲,CPU 将常用的数据放在高速缓存中,运算结束后 CPU 再讲运算结果同步到主存中。
使用高速缓存解决了 CPU 和主存速率不匹配的问题,但同时又引入另外一个新问题:缓存一致性问题。
在多CPU的系统中(或者单CPU多核的系统),每个CPU内核都有自己的高速缓存,它们共享同一主内存(Main Memory)。当多个CPU的运算任务都涉及同一块主内存区域时,CPU 会将数据读取到缓存中进行运算,这可能会导致各自的缓存数据不一致。
因此需要每个 CPU 访问缓存时遵循一定的协议,在读写数据时根据协议进行操作,共同来维护缓存的一致性。这类协议有 MSI、MESI、MOSI、和 Dragon Protocol 等。
1.3. 处理器优化和指令重排序
为了提升性能在 CPU 和主内存之间增加了高速缓存,但在多线程并发场景可能会遇到缓存一致性问题
1. 메모리 모델은 왜 필요한가요?
이 질문에 대답하려면 먼저 전통적인 컴퓨터 하드웨어 메모리 아키텍처를 이해해야 합니다. 좋아요, 이제 그림 그리기를 시작하겠습니다.1.1. 하드웨어 메모리 아키텍처
(1) CPU
전산실을 가본 학생들은 일반적으로 대형 서버에 여러 개의 CPU가 구성되어 있다는 것을 알고 있으며, 각 CPU에도 여러 개의 코어가 있다는 것을 의미합니다. 여러 CPU 또는 여러 코어가 동시에(동시에) 작동할 수 있습니다. Java를 사용하여 다중 스레드 작업을 시작하는 경우 각 CPU가 스레드를 실행한 다음 특정 순간에 작업이 실제로 동시에 실행될 가능성이 높습니다.  (2) CPU 레지스터
(2) CPU 레지스터
CPU 레지스터는 CPU 레지스터입니다. CPU 레지스터는 CPU 내부에 통합되어 있으며 레지스터에서 작업을 수행하는 효율성은 주 메모리보다 몇 배 더 높습니다. (3) CPU 캐시 메모리🎜🎜CPU 캐시 메모리는 레지스터에 비해 일반적으로 L2 레벨 2 캐시가 될 수도 있습니다. 하드 디스크 읽기 속도에 비해 메모리 읽기 효율은 매우 높지만 여전히 CPU와는 크기가 다릅니다. 따라서 이를 위해 CPU와 메인 메모리 사이에 다중 레벨 캐시가 도입됩니다. 버퍼링의. 🎜🎜(4) 메인 메모리🎜🎜메인 메모리는 L1, L2 캐시보다 훨씬 큰 메인 메모리입니다. 🎜🎜참고: 일부 고급 컴퓨터에는 L3 레벨 3 캐시도 있습니다. 🎜1.2. 캐시 일관성 문제
🎜메인 메모리와 CPU 프로세서의 컴퓨팅 성능 차이로 인해 기존 컴퓨터 메모리 아키텍처에 캐시가 도입되어 메인 메모리 역할을 합니다. CPU는 자주 사용하는 데이터를 캐시에 저장하고, 작업이 완료된 후 작업 결과를 메인 메모리에 동기화합니다. 🎜🎜캐시를 사용하면 CPU와 메인 메모리 속도 불일치 문제가 해결되지만 동시에 캐시 일관성 문제라는 또 다른 새로운 문제가 발생합니다. 🎜🎜 다중 CPU 시스템에서( 또는 단일 CPU 멀티 코어 시스템), 각 CPU 코어에는 자체 캐시가 있으며 동일한 메인 메모리(메인 메모리)를 공유합니다. 여러 CPU의 컴퓨팅 작업이 동일한 주 메모리 영역을 포함하는 경우 CPU는 컴퓨팅을 위해 데이터를 캐시로 읽어 들이며 이로 인해 각 캐시 데이터가 일치하지 않을 수 있습니다. 🎜🎜 따라서 각 CPU는 캐시에 액세스할 때 특정 프로토콜을 따르고, 데이터를 읽고 쓸 때 프로토콜에 따라 작동하며 공동으로 캐시의 일관성을 유지해야 합니다. 이러한 프로토콜에는 MSI, MESI, MOSI 및 Dragon 프로토콜이 포함됩니다. 🎜
1.3. 프로세서 최적화 및 명령어 재정렬
🎜성능 향상을 위해 CPU와 메인 메모리 사이에 캐시를 추가하지만 멀티 스레드 동시 시나리오에서는캐시 일관성 문제가 발생할 수 있습니다.. CPU의 실행 효율성을 더욱 향상시킬 수 있는 방법이 있습니까? 대답은 프로세서 최적화입니다. 🎜🎜🎜프로세서 내부의 컴퓨팅 장치를 최대한 활용하기 위해 프로세서는 입력 코드를 순서대로 실행합니다. 이것이 프로세서 최적화입니다. 🎜🎜🎜코드를 최적화하는 프로세서 외에도 많은 최신 프로그래밍 언어 컴파일러도 유사한 최적화를 수행합니다. 예를 들어 Java의 JIT(Just-In-Time 컴파일러)는 명령 재정렬을 수행합니다. 🎜🎜🎜🎜🎜프로세서 최적화는 실제로 재정렬의 한 유형입니다. 요약하면 재정렬은 세 가지 유형으로 나눌 수 있습니다. 🎜
- 컴파일러 최적화 재정렬. 컴파일러는 단일 스레드 프로그램의 의미를 변경하지 않고도 문의 실행 순서를 다시 정렬할 수 있습니다.
- 명령 수준 병렬 재정렬. 최신 프로세서는 명령어 수준 병렬성을 사용하여 여러 명령어의 실행을 중첩합니다. 데이터 종속성이 없으면 프로세서는 명령문이 기계 명령에 해당하는 순서를 변경할 수 있습니다.
- 메모리 시스템 재정렬. 프로세서는 캐시와 읽기 및 쓰기 버퍼를 사용하기 때문에 로드 및 저장 작업이 순서 없이 실행되는 것처럼 보일 수 있습니다.
2. 동시 프로그래밍 문제
위에서 하드웨어와 관련된 내용이 많이 언급되었습니다. 이렇게 큰 순환을 거친 후에는 이러한 내용이 Java 메모리 모델과 관련이 있습니까? 걱정하지 말고 천천히 아래를 내려다보자.
Java 동시성에 익숙한 학생은 "가시성 문제", "원자성 문제", "순서 문제"라는 세 가지 문제를 잘 알고 있어야 합니다. 이 세 가지 문제를 보다 심층적으로 살펴보면 실제로는 위에서 언급한 "캐시 일관성", "프로세서 최적화" 및 "명령어 재정렬"로 인해 발생합니다.
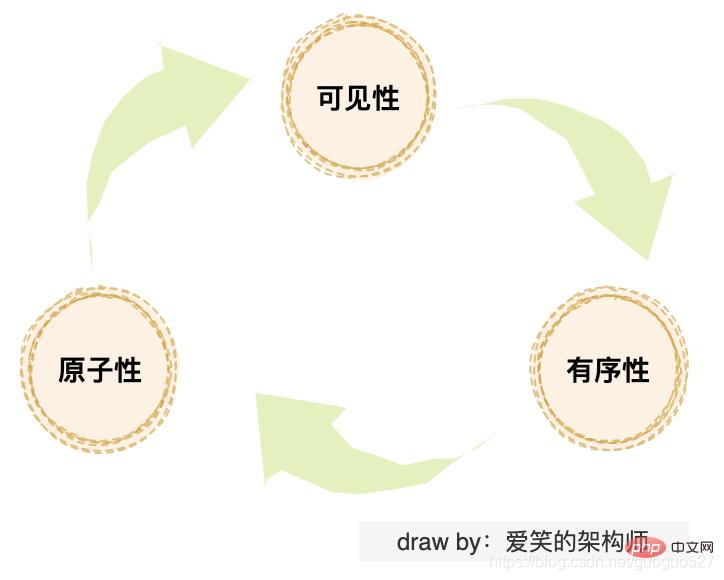
캐시 일관성 문제는 실제로 가시성 문제입니다. 프로세서 최적화로 인해 원자성 문제가 발생할 수 있으며 명령 순서 변경으로 인해 모두 연결되어 있는지 확인하세요.
문제는 항상 해결되어야 하는데, 해결책은 무엇일까요? 우선 간단하고 조잡한 방법을 생각했습니다. 캐시를 종료하고 CPU가 메인 메모리와 직접 상호 작용하도록 하면 프로세서 최적화 및 명령 재정렬을 비활성화하면 원자성과 순서 문제가 해결되지만 이는 이전으로 돌아갑니다. 하룻밤 사이에 해방되는 것은 분명히 바람직하지 않습니다.
그래서 기술 선배들은 메모리 읽기 및 쓰기 작업을 표준화하기 위해 물리적 시스템에 일련의 메모리 모델을 정의하는 것을 생각했습니다. 메모리 모델은 동시성 문제를 해결하기 위해 주로 두 가지 방법을 사용합니다. 限制处理器优化和使用内存屏障.
3. Java 메모리 모델
동일한 메모리 모델 사양으로 언어마다 구현에 약간의 차이가 있을 수 있습니다. 다음으로 Java 메모리 모델의 구현 원리에 대해 중점적으로 살펴보겠습니다.
3.1 Java 런타임 메모리 영역과 하드웨어 메모리의 관계
JVM을 아는 학생들은 JVM 런타임 메모리 영역이 조각화되어 스택, 힙 등으로 나누어져 있다는 것을 알고 있습니다. 실제로 이는 JVM에서 정의한 논리적 개념입니다. . 전통적인 하드웨어 메모리 아키텍처에는 스택과 힙이라는 개념이 없습니다. 
그림에서 알 수 있듯이 스택과 힙은 캐시와 메인 메모리 모두에 존재하므로 둘 사이에는 직접적인 관계가 없습니다.
3.2. Java 스레드와 메인 메모리의 관계
Java 메모리 모델은 많은 것을 정의하는 사양입니다.
- 모든 변수는 메인 메모리(메인 메모리)에 저장됩니다.
- 각 스레드에는 전용 로컬 메모리(로컬 메모리)가 있으며, 로컬 메모리에는 스레드가 읽고 쓸 수 있는 공유 변수의 복사본이 저장됩니다.
- 스레드에 의한 변수에 대한 모든 작업은 로컬 메모리에서 수행되어야 하며 메인 메모리에서 직접 읽거나 쓸 수 없습니다.
- 서로 다른 스레드는 서로의 로컬 메모리에 있는 변수에 직접 액세스할 수 없습니다.
텍스트 읽는 것이 너무 지루해서 다른 그림을 그렸습니다. 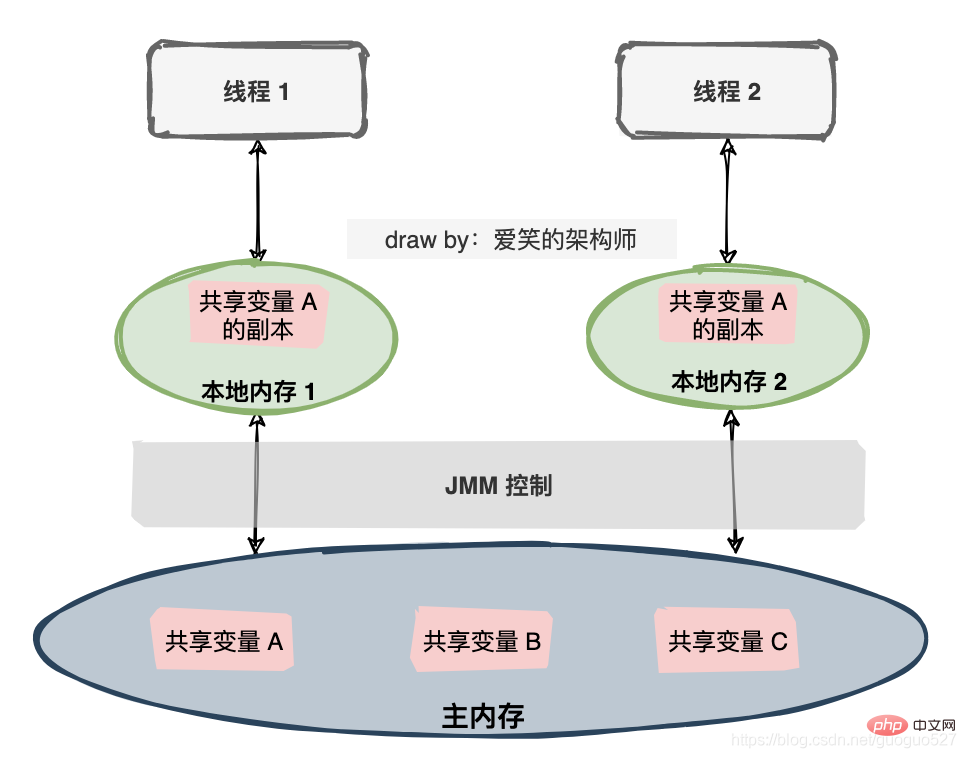
3.3. 스레드 간 통신
두 스레드가 공유 변수에 대해 작동하는 경우 공유 변수의 초기 값은 1이고 각 스레드는 두 변수입니다. 는 1씩 증가하고 공유변수의 기대값은 3입니다. JMM 사양에는 일련의 작업이 있습니다. 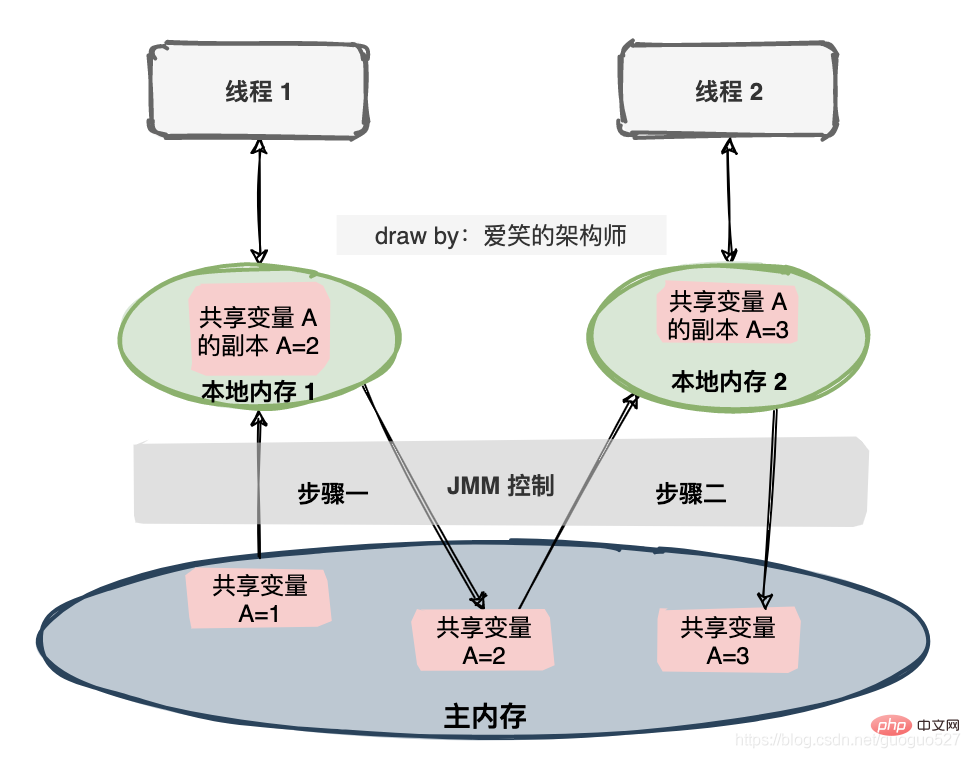
메인 메모리와 로컬 메모리 간의 상호 작용을 더 잘 제어하기 위해 Java 메모리 모델은 다음과 같은 8가지 작업을 정의합니다.
- 잠금: 잠급니다. 주 메모리의 변수에 작용하여 변수를 스레드 전용으로 표시합니다.
- unlock: 잠금을 해제합니다. 해제된 변수가 다른 스레드에 의해 잠길 수 있도록 주 메모리 변수에 작용하여 잠긴 변수를 해제합니다.
- 읽다: 읽다. 메인 메모리 변수에 작용하고 로드 작업
- load: 로드의 후속 사용을 위해 메인 메모리에서 스레드의 작업 메모리로 변수 값을 전송합니다. 읽기 작업을 통해 주 메모리에서 얻은 변수 값을 작업 메모리의 변수 복사본에 저장하는 작업 메모리의 변수에 작용합니다.
- 사용: 사용합니다. 작업 메모리에 작용하는 변수는 작업 메모리의 변수 값을 실행 엔진에 전달합니다. 이 작업은 가상 머신이 변수 값을 요구하는 바이트코드 명령을 만날 때마다 수행됩니다.
- 할당: 할당. 실행 엔진에서 받은 값을 작업 메모리의 변수에 할당하는 작업 메모리의 변수에 작용합니다. 이 작업은 가상 머신이 변수에 값을 할당하는 바이트코드 명령을 만날 때마다 수행됩니다.
- 스토어: 창고. 작업 메모리의 변수에 작용하고 후속 쓰기 작업을 위해 작업 메모리의 변수 값을 주 메모리로 전송합니다.
- 쓰다: 쓰다. 작업 메모리의 변수 값에서 메인 메모리의 변수로 저장 작업을 전송하는 메인 메모리의 변수에 작용합니다.
참고: 작업 메모리는 로컬 메모리를 의미하기도 합니다.
4. 태도 요약
CPU와 메인 메모리의 속도 차이로 인해 문제를 해결하기 위해 다중 레벨 캐시의 전통적인 하드웨어 메모리 아키텍처를 도입하려고 생각했습니다. 버퍼링은 CPU와 메인 메모리 사이의 간격 역할을 하여 전반적인 성능을 향상시킵니다. 속도 저하 문제를 해결하지만 캐시 일관성 문제도 발생합니다.
데이터는 캐시와 메인 메모리 모두에 존재합니다. 표준화되지 않으면 필연적으로 재앙이 발생하므로 메모리 모델은 기존 시스템에서 추상화됩니다.
JMM 사양은 다중 스레드가 공유 메모리를 통해 통신할 때 발생하는 로컬 메모리 데이터 불일치, 컴파일러 재정렬 코드 지침 및 프로세서 재정렬 문제를 해결하는 것이 목적입니다. 비순차적 실행 등에 의해
작업 메모리와 주 메모리 간의 상호 작용을 보다 정확하게 제어하기 위해 JMM에서는 8가지 작업도 정의합니다. lock, unlock, read, load,use,assign, store, write.
추천 학습: "java 학습 튜토리얼"
위 내용은 사진과 글로 자세한 설명! Java 메모리 모델이란 무엇입니까?의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!