
집 >데이터 베이스 >MySQL 튜토리얼 >MySQL 인터뷰 Q&A 모음 (요약 공유)
MySQL 인터뷰 Q&A 모음 (요약 공유)

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWB앞으로
- 2022-03-22 17:44:432358검색
이 기사는 mysql에 대한 관련 지식을 제공합니다. 데이터베이스 아키텍처, 인덱싱 및 SQL 최적화 등 인터뷰에서 자주 묻는 몇 가지 질문을 주로 정리했습니다. 모든 사람에게 도움이 되기를 바랍니다.

추천 학습: mysql 튜토리얼
1. 데이터베이스 아키텍처
1.1 MySQL의 인프라 다이어그램에 대해 이야기해 보세요.
면접관에게 화이트보드가 있으면 그림을 그릴 수 있습니다. 다음 사진은 인터넷에서 가져온 것입니다.
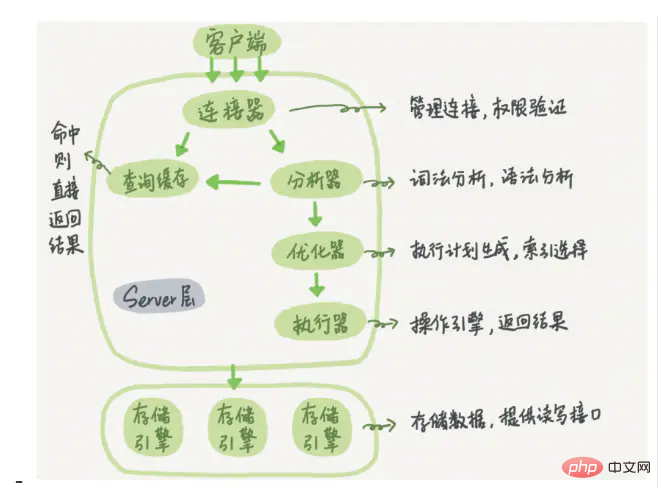
Mysql 논리 아키텍처 다이어그램은 크게 세 가지 레이어로 나뉩니다.
(1) 첫 번째 레이어는 연결 처리, 인증 인증, 보안 등을 담당합니다.
(2) 두 번째 레이어는 컴파일 및 SQL 최적화
(3) 세 번째 계층은 스토리지 엔진입니다.
1.2. MySQL에서 SQL 쿼리문은 어떻게 실행되나요?
먼저
권한이 있는지 확인하세요. 권한이 없으면 바로 오류 메시지가 반환됩니다. (MySQL8.0 버전 이전에는) 캐시를 먼저 쿼리합니다. ).是否有权限,如果没有权限,直接返回错误信息,如果有权限会先查询缓存(MySQL8.0 版本以前)。如果没有缓存,分析器进行
词法分析,提取 sql 语句中 select 等关键元素,然后判断 sql 语句是否有语法错误,比如关键词是否正确等等。最后优化器确定执行方案进行权限校验,如果没有权限就直接返回错误信息,如果有权限就会
调用数据库引擎接口
어휘분석을 수행하여 sql 문에서 select 등의 핵심 요소를 추출한 후 sql 문에 키워드가 있는지 등 문법 오류가 있는지 확인합니다. 등등이 맞습니다.
마지막으로 옵티마이저는 실행 계획을 결정하고 권한 확인을 수행합니다. 권한이 없으면 바로 오류 메시지를 반환합니다. 데이터베이스 엔진 인터페이스를 호출합니다. 그리고 실행 결과를 반환합니다.
2. SQL 최적화
2.1 일상 업무에서 SQL을 어떻게 최적화하나요? 다음 차원에서 이 질문에 답할 수 있습니다. 2.1.1,테이블 구조 최적화
(1) 숫자 필드를 사용해 보세요숫자 정보만 포함하는 필드인 경우 문자 유형으로 디자인하지 마세요. 이는 쿼리 및 조인 성능을 감소시키고 스토리지 오버헤드를 증가시킵니다. 엔진은 쿼리 및 연결 처리 시 문자열의 각 문자를 하나씩 비교하는데, 숫자 유형의 경우 한 번의 비교만으로 충분하기 때문입니다. (2) char 대신 varchar를 최대한 사용하세요가변 길이 필드는 저장 공간이 작아 저장 공간을 절약할 수 있습니다.
(3) 인덱스 열에 중복 데이터가 많은 경우 인덱스가 삭제될 수 있습니다. 예를 들어, 성별에 대한 열이 거의 남성, 여성, 알 수 없는 경우 해당 인덱스는 유효하지 않습니다.- 2.1.2,
쿼리 최적화
- where 절에 != 또는 연산자를 사용하지 마세요
- 조건을 연결하는 where 절을 사용하지 마세요
- 모든 쿼리에서 select *를 사용하지 마세요. 필드 인덱싱
너무 많은 인덱스를 생성하지 말고 결합 인덱스를 사용하세요
- 2.2. (설명) 그리고 각 분야의 의미를 어떻게 이해하나요? 실행 계획 정보를 반환하려면 select 문 앞에 explain 키워드를 추가하세요.
- (1) id 컬럼: select 문의 일련번호입니다. MySQL은 select 쿼리를 단순 쿼리와 복합 쿼리로 구분합니다.
(2) select_type 열: 해당 행이 단순 쿼리인지, 복잡한 쿼리인지를 나타냅니다.
(3) 테이블 열: explain 행이 액세스하는 테이블을 나타냅니다.
(4) 유형 컬럼: 가장 중요한 컬럼 중 하나입니다. MySQL이 테이블에서 행을 찾는 방법을 결정하는 연결 유형 또는 액세스 유형을 나타냅니다. 최고부터 최악까지: system > const > eq_ref > index_merge > index_subquery > index > 쿼리를 사용하여 찾을 수 있습니다. 
2.3. 비즈니스 시스템에서 시간이 많이 걸리는 SQL에 대해 걱정해 본 적이 있나요? 쿼리 통계가 너무 느린가요? 느린 쿼리를 어떻게 최적화했나요?
우리가 보통 SQL을 작성할 때, 분석 설명을 사용하는 습관을 길러야 합니다. 느린 쿼리, 운영 및 유지 관리에 대한 통계는 정기적으로 통계를 제공합니다
느린 쿼리 아이디어 최적화:
문 분석, 불필요한 필드/데이터 로드 여부
-
SQL 실행 문장이 인덱스에 도달하는지 분석 , etc.
SQL이 매우 복잡하다면 SQL 구조를 최적화하세요
테이블 데이터의 양이 너무 많으면 하위 테이블을 고려하세요
3. 클러스터형 인덱스와 비클러스터형 인덱스
여러 차원에서 다음 네 가지 답을 누를 수 있습니다.
(1) 테이블은 클러스터형 인덱스를 하나만 가질 수 있지만 테이블은 여러 개의 비클러스터형 인덱스를 가질 수 있습니다.
(2) 클러스터형 인덱스, 인덱스에 있는 키 값의 논리적 순서는 테이블에서 해당 행의 물리적 순서를 결정합니다. 비클러스터형 인덱스는 인덱스의 논리적 순서와 다릅니다. 디스크에 있는 행의 물리적 저장 순서입니다.
(3) 인덱스는 이진 트리의 데이터 구조를 통해 설명됩니다. 클러스터형 인덱스는 다음과 같이 이해할 수 있습니다. 인덱스의 리프 노드는 데이터 노드입니다. 비클러스터형 인덱스의 리프 노드는 여전히 인덱스 노드이지만 해당 데이터 블록을 가리키는 포인터가 있습니다.
(4) 클러스터형 인덱스: 물리적 저장소는 인덱스에 따라 정렬됩니다. 비클러스터형 인덱스: 물리적 저장소는 인덱스에 따라 정렬되지 않습니다.
3.2. B+ 트리를 사용하는 이유는 무엇입니까?
이 문제는 쿼리가 충분히 빠른지, 효율성이 안정적인지, 데이터가 얼마나 저장되는지, 디스크 검색 횟수가 왜 일반적인 이진 트리가 아닌지, 왜 그런 것인지 등 여러 차원에서 살펴볼 수 있습니다. 균형 잡힌 이진 트리가 아닌데 왜 B-트리가 아니고 B+ 트리인가요?
3.2.1. 왜 일반 이진 트리가 아닌가?
이진 트리를 연결 리스트로 특화하면 전체 테이블 스캔과 동일합니다. 이진 검색 트리와 비교하여 균형 이진 트리는 검색 효율성이 더 안정적이고 전체 검색 속도가 더 빠릅니다.
3.2.2. 왜 균형 잡힌 이진 트리가 아닌가?
우리는 메모리에 있는 데이터를 쿼리하는 것이 디스크에 있는 것보다 훨씬 빠르다는 것을 알고 있습니다. 트리와 같은 데이터 구조를 인덱스로 사용하면 데이터를 검색할 때마다 디스크에서 노드를 읽어야 하는데, 이를 디스크 블록이라고 부르는데, 균형 이진 트리는 하나의 키 값만 저장합니다. B-트리라면 더 많은 노드 데이터를 저장할 수 있고, 트리 높이도 줄어들기 때문에 디스크 읽기 횟수가 줄어들고 쿼리 효율이 빨라진다.
3.2.3. 왜 B 트리가 아니고 B+ 트리인가요?
B+ 트리는 리프가 아닌 노드에 데이터를 저장하지 않고 키 값만 저장하는 반면, B-트리 노드는 키 값뿐만 아니라 데이터도 저장합니다. innodb의 페이지 기본 크기는 16KB입니다. 데이터가 저장되지 않으면 더 많은 키 값이 저장되고 해당 트리(노드의 하위 노드 트리)의 순서가 더 커지며 트리는 더 커집니다. 이러한 방식으로 데이터를 검색하는 데 필요한 디스크 IO 시간이 다시 줄어들고 데이터 쿼리의 효율성이 더 빨라집니다.
B+ 트리 인덱스의 모든 데이터는 리프 노드에 저장되며, 데이터는 순서대로 정렬되어 연결리스트로 연결됩니다. 그러면 B+ 트리는 범위 검색, 정렬 검색, 그룹 검색 및 중복 제거 검색을 매우 간단하게 만듭니다.
3.3. 해시 인덱스와 B+ 트리 인덱스의 차이점은 무엇인가요? 인덱스 디자인을 어떻게 선택하셨나요?
- B+ 트리는 범위 쿼리를 수행할 수 있지만 해시 인덱스는 수행할 수 없습니다.
- B+ 트리는 가장 왼쪽의 조인트 인덱스 원칙을 지원하고, 해시 인덱스는 지원하지 않습니다.
- B+ 트리는 정렬별 순서를 지원하지만 해시 인덱스는 지원하지 않습니다.
- 해시 인덱스는 동등한 쿼리에서 B+ 트리보다 효율적입니다.
- B+ 트리가 퍼지 쿼리에 like를 사용하는 경우 like 뒤의 단어(예: %로 시작)가 최적화 역할을 할 수 있으며 해시 인덱스는 퍼지 쿼리를 전혀 수행할 수 없습니다.
- 3.4.가장 왼쪽 접두사 원칙은 무엇인가요? 가장 왼쪽의 일치 원리는 무엇입니까?
가장 왼쪽 접두사 원칙은 다중 열 인덱스를 생성할 때 비즈니스 요구에 따라 where 절에서 가장 자주 사용되는 열을 가장 왼쪽에 배치해야 함을 의미합니다.
(a1, a2, a3)과 같은 결합 인덱스를 생성하는 것은 (a1), (a1, a2) 및 (a1, a2, a3) 세 개의 인덱스를 생성하는 것과 같습니다. 원칙.
3.5. 인덱싱에 적합하지 않은 시나리오는 무엇인가요?
- 데이터 양이 적은 것은 인덱싱에 적합하지 않습니다
- 업데이트가 잦은 필드는 인덱싱에 적합하지 않습니다 = 차별화가 낮은 필드는 인덱싱에 적합하지 않습니다. (성별 등)
- 3.6.지수의 장점과 단점은 무엇인가요?
(1) 장점:
- 고유 인덱스는 데이터베이스 테이블에 있는 데이터의 각 행의 고유성을 보장할 수 있습니다.
- 인덱스는 데이터 쿼리 속도를 높이고 쿼리 시간을 줄일 수 있습니다.
- (2) 단점:
- 인덱스를 생성하고 유지하는 데 시간이 걸립니다.
- 인덱스는 데이터 테이블이 차지하는 데이터 공간 외에 각 인덱스도 일정량의 물리적 공간을 차지합니다.
- 테이블의 데이터를 삭제하거나 수정하는 경우 인덱스도 동적으로 유지되어야 합니다.
- 4. Locks
4.1. MySQL에서 교착 상태 문제를 해결한 적이 있나요?
그것을 만났습니다. 교착 상태 문제를 해결하는 일반적인 단계는 다음과 같습니다.
(1) 교착 상태 로그에서 엔진 innodb 상태를 확인합니다.
(2) 교착 상태 Sql
(3) SQL 잠금 상황 분석
(4) 교착 상태 시뮬레이션
(5) 교착 상태 분석 잠금 로그
(6) 교착 상태 결과 분석
4.2. 데이터베이스의 낙관적 잠금과 비관적 잠금은 무엇이며 그 차이점은 무엇입니까?
(1) 비관적 잠금:
비관적 잠금은 한마음이고 안전하지 않습니다. 그녀의 마음은 현재 거래에만 속하며, 그녀는 자신이 사랑하는 데이터가 다른 거래에 의해 수정될 수 있다는 것을 항상 걱정하므로 거래를 소유한 후( 비관적 잠금을 획득하는 경우 다른 트랜잭션은 데이터를 수정할 수 없으며 실행하기 전에 잠금이 해제될 때까지만 기다릴 수 있습니다.
(2) 낙관적 잠금:
낙관적 잠금의 "낙관주의"는 데이터가 너무 자주 변경되지 않을 것이라고 믿는다는 사실에 반영됩니다. 따라서 여러 트랜잭션이 동시에 데이터를 변경할 수 있습니다.
구현 방법: 낙관적 잠금은 일반적으로 버전 번호 메커니즘이나 CAS 알고리즘을 사용하여 구현됩니다.
4.3. MVCC에 대해 잘 알고 있고 기본 원리를 알고 있나요?
MVCC(Multiversion Concurrency Control), 즉 다중 버전 동시성 제어 기술입니다.
MySQL InnoDB에서 MVCC 구현은 주로 데이터베이스 동시성 성능을 향상시키고 읽기-쓰기 충돌을 처리하는 더 나은 방법을 사용하므로 읽기-쓰기 충돌이 있는 경우에도 잠금 및 비차단 동시 읽기가 달성될 수 없습니다. .
5. 트랜잭션
5.1. MySQL 트랜잭션의 네 가지 주요 특징 및 구현 원칙
원자성: 트랜잭션은 전체적으로 실행되며, 여기에 포함된 데이터베이스의 모든 작업은 실행되거나 전혀 실행되지 않습니다.
일관성: 거래 시작 전과 거래 종료 후에도 데이터가 파기되지 않음을 의미합니다. A 계좌가 B 계좌로 10위안을 이체하는 경우 A와 B의 총액은 성공 여부에 관계없이 변경되지 않습니다.
격리: 여러 트랜잭션이 동시에 액세스할 때 트랜잭션은 서로 격리됩니다. 즉, 하나의 트랜잭션이 다른 트랜잭션의 실행 효과에 영향을 주지 않습니다. 한마디로 말하면, 일들 사이에 갈등이 없다는 뜻이다.
지속성: 트랜잭션이 완료된 후 트랜잭션으로 인해 데이터베이스에 대한 작업 변경 사항이 데이터베이스에 영구적으로 저장됨을 나타냅니다.
5.2. 트랜잭션의 격리 수준은 무엇입니까? MySQL의 기본 격리 수준은 무엇입니까?
읽기 커밋됨
읽기 커밋됨
반복 읽기
직렬화 가능
Mysql 기본 트랜잭션 격리 수준은 반복 읽기
5.3입니다. 팬텀 읽기, 더티 읽기 및 비 -반복 가능한 읽기?
트랜잭션 A와 B가 교대로 실행됩니다. 트랜잭션 A가 트랜잭션 B의 커밋되지 않은 데이터를 읽기 때문에 트랜잭션 A가 트랜잭션 B의 방해를 받습니다. 이는 더티 읽기입니다.
트랜잭션 범위 내에서 두 개의 동일한 쿼리가 동일한 레코드를 읽었지만 다른 데이터를 반환합니다. 이는 반복 불가능한 읽기입니다.
트랜잭션 A는 범위의 결과 집합을 쿼리하고 다른 동시 트랜잭션 B는 이 범위에 데이터를 삽입/삭제하고 자동으로 커밋합니다. 그런 다음 트랜잭션 A가 동일한 범위를 다시 쿼리하고 두 번의 읽기로 얻은 결과 집합이 다릅니다. 마찬가지로, 이것은 환상의 독서입니다.
6.실전적인 전투
6.1.MySQL 데이터베이스 CPU가 급증하면 어떻게 대처하나요?
문제 해결 프로세스:
(1) top 명령을 사용하여 mysqld에 의한 것인지 또는 다른 이유로 인해 발생하는지 관찰하고 확인합니다.
(2) mysqld로 인해 발생한 경우 processlist를 표시하고 세션 상태를 확인하여 리소스를 소모하는 SQL이 실행되고 있는지 확인합니다.
(3) 소모량이 많은 SQL을 찾아 실행 계획이 정확한지, 인덱스가 누락되었는지, 데이터량이 너무 많은지 살펴보세요.
처리 중:
(1) 이 스레드를 종료하고(CPU 사용량이 감소하는지 관찰)
(2) 해당 조정 수행(예: 인덱스 추가, SQL 변경, 메모리 매개변수 변경)
(3) 다시 시작 다음을 실행합니다. SQL.
기타 상황:
각 SQL 문이 많은 리소스를 소비하지 않지만 갑자기 많은 수의 세션 연결이 들어와 CPU가 급증하는 경우도 가능합니다. 이 경우 애플리케이션으로 분석해야 합니다. 연결 수가 급증하는 이유는 무엇입니까? 그런 다음 연결 수 제한 등 해당 조정을 수행하십시오.
6.2 MYSQL의 마스터-슬레이브 지연을 어떻게 해결합니까?
마스터-슬레이브 복제는 5단계로 수행됩니다: (인터넷의 사진)
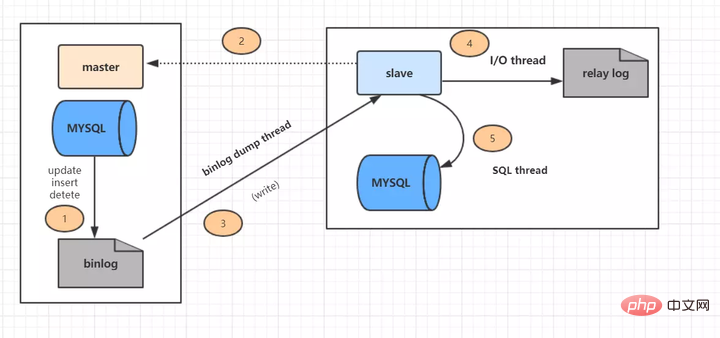
1단계: 메인 라이브러리의 업데이트 이벤트(업데이트, 삽입, 삭제)가 binlog에 기록됩니다.
2단계: 슬레이브 라이브러리에서 기본 라이브러리로의 연결을 시작합니다.
3단계: 이때 메인 라이브러리는 binlog 덤프 스레드를 생성하고 binlog의 내용을 슬레이브 라이브러리로 보냅니다.
4단계: 라이브러리에서 시작한 후 I/O 스레드를 생성하고, 메인 라이브러리에서 전달된 binlog 내용을 읽고 이를 릴레이 로그에 씁니다.
5단계: SQL 스레드도 생성됩니다. 릴레이에서 로그 내용을 읽어서 Exec_Master_Log_Pos 위치부터 읽기 업데이트 이벤트를 실행하고 업데이트된 내용을 슬레이브 db에 씁니다
마스터-슬레이브 동기화 지연 이유
서버는 클라이언트가 연결할 수 있도록 N개의 링크를 열어두기 때문에 동시에 업데이트 작업이 많이 발생하지만 서버에서 binlog를 읽는 스레드는 하나뿐이므로 슬레이브 서버에서 특정 SQL을 실행하는 데 시간이 조금 더 걸립니다. 시간이 오래 걸리거나 특정 SQL이 테이블을 잠가야 하므로 마스터 서버에 SQL 백로그가 많아지고 슬레이브 서버에 동기화되지 않을 수 있습니다. 이로 인해 마스터-슬레이브 불일치, 즉 마스터-슬레이브 지연이 발생합니다.
마스터-슬레이브 동기화 지연에 대한 솔루션
마스터 서버는 업데이트 작업을 담당하고 슬레이브 서버보다 보안 요구 사항이 높기 때문에 일부 설정 매개변수를 수정할 수 있습니다. sync_binlog=1, innodb_flush_log_at_trx_commit = 1 등 설정 등
더 나은 하드웨어 장치를 슬레이브로 선택하세요.
쿼리를 제공하지 않고 슬레이브 서버를 백업으로 사용하면 해당 측의 부하가 줄어들고 릴레이 로그에서 SQL을 실행하는 효율성이 자연스럽게 높아집니다.
슬레이브 서버를 추가하는 목적은 독서 부담을 분산시켜 서버 부하를 줄이는 것입니다.
6.3. 서브 데이터베이스와 서브 테이블 디자인을 요청받았다면 어떻게 하시겠습니까?
하위 데이터베이스 및 테이블 구성표:
수평 하위 데이터베이스: 하나의 데이터베이스에 있는 데이터를 필드 및 특정 전략(해시, 범위 등)에 따라 여러 데이터베이스로 분할합니다.
수평 테이블 분할: 필드 및 특정 전략(해시, 범위 등)에 따라 한 테이블의 데이터를 여러 테이블로 분할합니다.
수직 하위 데이터베이스: 테이블을 기반으로 다양한 테이블이 다양한 비즈니스 소유권에 따라 다양한 데이터베이스로 분할됩니다.
수직 테이블 분할: 필드 기반 및 필드 활동에 따라 테이블의 필드가 여러 테이블(메인 테이블과 확장 테이블)로 분할됩니다.
일반적으로 사용되는 sharding-jdbc 미들웨어:
sharding-jdbc
Mycat
샤딩과 관련하여 발생할 수 있는 문제
-
거래 질문: 필수 분산 거래 사용
교차 노드 조인 문제: 이 문제는 두 개의 쿼리로 해결될 수 있습니다
교차 노드 수, 순서 기준, 그룹 기준 및 집계 함수 문제: 각 노드에 각각 가져오고 결과는 애플리케이션 측에서 병합됩니다.
데이터 마이그레이션, 용량 계획, 확장 및 기타 문제
ID 문제: 데이터베이스가 분할된 후에는 더 이상 데이터베이스 자체의 기본 키 생성 메커니즘에 의존할 수 없습니다. 가장 쉬운 방법은 UUID를 고려하는 것입니다.
교차 샤딩 정렬 페이징 문제
추천 학습: mysql 학습 튜토리얼
위 내용은 MySQL 인터뷰 Q&A 모음 (요약 공유)의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!