
Python 멀티스레딩을 해석하는 방법을 안내합니다.

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWB앞으로
- 2022-03-02 17:35:482620검색
이 글에서는 멀티스레딩에 대한 관련 지식을 주로 소개하는 python 관련 지식을 소개합니다. 멀티스레딩은 여러 다른 프로그램을 동시에 실행하는 것과 유사하며 아래에서 이에 대해 살펴보겠습니다. . 모두에게 도움이 되기를 바랍니다.

추천 학습: python 튜토리얼
스레딩 설명
멀티스레딩은 여러 다른 프로그램을 동시에 실행하는 것과 유사하며 다음과 같은 장점이 있습니다.
- 스레드를 사용하면 스레드 수를 줄일 수 있습니다. 오랜 시간을 차지하는 프로그램 작업은 처리를 위해 백그라운드에 배치됩니다.
- 사용자 인터페이스가 더 매력적일 수 있으므로 사용자가 버튼을 클릭하여 특정 이벤트 처리를 트리거하면 진행률 표시줄이 팝업되어 처리 진행 상황을 표시할 수 있습니다.
- 프로그램이 더 빠르게 실행될 수 있습니다.
- 스레드는 사용자 입력, 파일 읽기 및 쓰기, 네트워크 데이터 전송 및 수신과 같은 일부 대기 작업을 구현하는 데 더 유용합니다. 이 경우 메모리 사용량 등과 같은 일부 귀중한 리소스를 해제할 수 있습니다.
실행 중에 스레드와 프로세스에는 차이가 있습니다. 각각의 독립 스레드에는 프로그램 실행을 위한 진입점, 순차적 실행 시퀀스 및 프로그램 종료점이 있습니다. 그러나 스레드는 독립적으로 실행될 수 없으며 응용 프로그램 내에 존재해야 하며 응용 프로그램은 다중 스레드 실행 제어를 제공합니다.
각 스레드에는 스레드 컨텍스트라고 하는 고유한 CPU 레지스터 세트가 있으며, 이는 스레드가 마지막으로 실행한 CPU 레지스터의 상태를 반영합니다.
명령 포인터와 스택 포인터 레지스터는 스레드 컨텍스트에서 가장 중요한 두 가지 레지스터입니다. 스레드는 항상 프로세스 컨텍스트에서 실행됩니다. 이 주소는 프로세스의 주소 공간에 메모리를 표시하는 데 사용됩니다. 그것은 스레드를 소유하고 있습니다.
스레드는 선점(중단)될 수 있습니다.
다른 스레드가 실행 중인 동안 스레드는 보류(휴면이라고도 함)될 수 있습니다. 이를 스레드 백오프라고 합니다.
스레드는 다음과 같이 나눌 수 있습니다.
- 커널 스레드: 운영 체제 커널에 의해 생성되고 취소됩니다.
- 사용자 스레드: 커널 지원 없이 사용자 프로그램에 구현된 스레드입니다.
Python3 스레드에서 일반적으로 사용되는 두 가지 모듈은 다음과 같습니다.
- _thread
- threading(권장)
thread 모듈이 중단되었습니다. 사용자는 대신 스레딩 모듈을 사용할 수 있습니다. 따라서 "thread" 모듈은 Python3에서 더 이상 사용할 수 없습니다. 호환성을 위해 Python3에서는 스레드 이름을 "_thread"로 변경했습니다.
Python 스레드 학습 시작
Python에서 스레드를 사용하는 방법에는 두 가지가 있습니다. 스레드 개체를 래핑하는 함수 또는 클래스입니다.
기능: _thread 모듈에서 start_new_thread() 함수를 호출하여 새 스레드를 생성합니다. 구문은 다음과 같습니다:
_thread.start_new_thread ( function, args[, kwargs] )
매개변수 설명:
- function - 스레드 함수.
- args - 스레드 함수에 전달되는 매개변수는 튜플 유형이어야 합니다.
- kwargs - 선택적 매개변수.
예:
#!/usr/bin/python3 import _thread import time # 为线程定义一个函数 def print_time( threadName, delay): count = 0 while count <p> 위 프로그램을 실행한 결과는 다음과 같습니다. <br><img src="/static/imghwm/default1.png" data-src="https://img.php.cn/upload/article/000/000/067/9e54370fdafb34f8739135c680e1aa53-0.png" class="lazy" alt="Python 멀티스레딩을 해석하는 방법을 안내합니다."></p><h2>Thread 모듈</h2><p> Python3은 두 가지 표준 라이브러리인 스레드와 스레딩을 통해 스레드를 지원합니다. </p>
- _thread는 낮은 수준의 기본 스레드와 간단한 잠금을 제공합니다. 해당 기능은 스레딩 모듈에 비해 여전히 상대적으로 제한됩니다. _thread 모듈의 모든 메서드 외에도
- threading 모듈은 다른 메서드도 제공합니다.
- threading.currentThread(): 현재 스레드 변수를 반환합니다.
- threading.enumerate():
실행 중인 스레드가 포함된 목록을 반환합니다. 실행이란 스레드가 시작된 후 종료되기 전을 의미하며, 시작 전과 종료 후의 스레드는 제외됩니다. - threading.activeCount():
실행 중인 스레드 수를 반환하며, 이는 len(threading.enumerate())와 동일한 결과를 갖습니다.
스레드 모듈은 스레드를 처리하기 위한 Thread 클래스도 제공합니다.
- run(): 스레드 활동을 나타내는 데 사용되는 메서드입니다.
- start(): 스레드 활동을 시작합니다.
- join([time]): 스레드가 종료될 때까지 기다립니다. 이는 스레드의 Join()
메서드가 중단되거나(정상적으로 종료되거나 처리되지 않은 예외가 발생하거나) 선택적 시간 초과가 발생할 때까지 호출 스레드를 차단합니다. - isAlive(): 스레드가 활성 상태인지 여부를 반환합니다.
- getName(): 스레드 이름을 반환합니다.
- setName(): 스레드 이름을 설정합니다.
threading 모듈을 사용하여 스레드 생성
threading.Thread를 직접 상속하여 새로운 하위 클래스를 생성할 수 있으며, 인스턴스화 후 start() 메서드를 호출하여 새 스레드를 시작합니다. 즉, 스레드의 run( ) 메소드:
#!/usr/bin/python3
import threading
import time
exitFlag = 0
class myThread (threading.Thread):
def __init__(self, threadID, name, counter):
threading.Thread.__init__(self)
self.threadID = threadID
self.name = name
self.counter = counter
def run(self):
print ("开始线程:" + self.name)
print_time(self.name, self.counter, 5)
print ("退出线程:" + self.name)
def print_time(threadName, delay, counter):
while counter:
if exitFlag:
threadName.exit()
time.sleep(delay)
print ("%s: %s" % (threadName, time.ctime(time.time())))
counter -= 1
# 创建新线程
thread1 = myThread(1, "Thread-1", 1)
thread2 = myThread(2, "Thread-2", 2)
# 开启新线程
thread1.start()
thread2.start()
thread1.join()
thread2.join()
print ("退出主线程")
위 프로그램의 실행 결과는 다음과 같습니다. 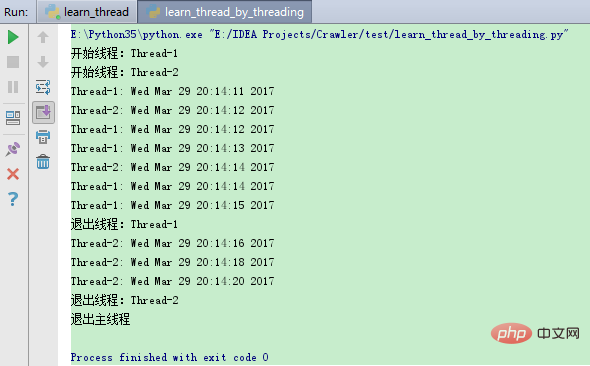
线程同步
如果多个线程共同对某个数据修改,则可能出现不可预料的结果,为了保证数据的正确性,需要对多个线程进行同步。
使用 Thread 对象的 Lock 和 Rlock 可以实现简单的线程同步,这两个对象都有 acquire 方法和 release 方法,对于那些需要每次只允许一个线程操作的数据,可以将其操作放到 acquire 和 release 方法之间。如下:
多线程的优势在于可以同时运行多个任务(至少感觉起来是这样)。但是当线程需要共享数据时,可能存在数据不同步的问题。
考虑这样一种情况:一个列表里所有元素都是0,线程"set"从后向前把所有元素改成1,而线程"print"负责从前往后读取列表并打印。
那么,可能线程"set"开始改的时候,线程"print"便来打印列表了,输出就成了一半0一半1,这就是数据的不同步。为了避免这种情况,引入了锁的概念。
锁有两种状态——锁定和未锁定。每当一个线程比如"set"要访问共享数据时,必须先获得锁定;如果已经有别的线程比如"print"获得锁定了,那么就让线程"set"暂停,也就是同步阻塞;等到线程"print"访问完毕,释放锁以后,再让线程"set"继续。
经过这样的处理,打印列表时要么全部输出0,要么全部输出1,不会再出现一半0一半1的尴尬场面。
实例:
#!/usr/bin/python3
import threading
import time
class myThread (threading.Thread):
def __init__(self, threadID, name, counter):
threading.Thread.__init__(self)
self.threadID = threadID
self.name = name
self.counter = counter
def run(self):
print ("开启线程: " + self.name)
# 获取锁,用于线程同步
threadLock.acquire()
print_time(self.name, self.counter, 3)
# 释放锁,开启下一个线程
threadLock.release()
def print_time(threadName, delay, counter):
while counter:
time.sleep(delay)
print ("%s: %s" % (threadName, time.ctime(time.time())))
counter -= 1
threadLock = threading.Lock()
threads = []
# 创建新线程
thread1 = myThread(1, "Thread-1", 1)
thread2 = myThread(2, "Thread-2", 2)
# 开启新线程
thread1.start()
thread2.start()
# 添加线程到线程列表
threads.append(thread1)
threads.append(thread2)
# 等待所有线程完成
for t in threads:
t.join()
print ("退出主线程")
执行以上程序,输出结果为: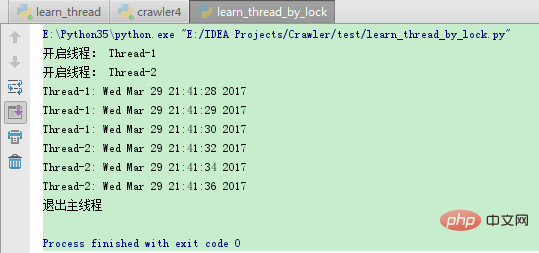
线程优先级队列(Queue)
Python 的 Queue 模块中提供了同步的、线程安全的队列类,包括FIFO(先入先出)队列Queue,LIFO(后入先出)队列LifoQueue,和优先级队列 PriorityQueue。
这些队列都实现了锁原语,能够在多线程中直接使用,可以使用队列来实现线程间的同步。
Queue 模块中的常用方法:
- Queue.qsize() 返回队列的大小
- Queue.empty() 如果队列为空,返回True,反之False
- Queue.full() 如果队列满了,返回True,反之False
- Queue.full 与 maxsize 大小对应
- Queue.get([block[, timeout]])获取队列,timeout等待时间
- Queue.get_nowait() 相当Queue.get(False)
- Queue.put(item) 写入队列,timeout等待时间
- Queue.put_nowait(item) 相当Queue.put(item, False)
- Queue.task_done() 在完成一项工作之后,Queue.task_done()函数向任务已经完成的队列发送一个信号
- Queue.join() 实际上意味着等到队列为空,再执行别的操作
实例:
#!/usr/bin/python3
import queue
import threading
import time
exitFlag = 0
class myThread (threading.Thread):
def __init__(self, threadID, name, q):
threading.Thread.__init__(self)
self.threadID = threadID
self.name = name
self.q = q
def run(self):
print ("开启线程:" + self.name)
process_data(self.name, self.q)
print ("退出线程:" + self.name)
def process_data(threadName, q):
while not exitFlag:
queueLock.acquire()
if not workQueue.empty():
data = q.get()
queueLock.release()
print ("%s processing %s" % (threadName, data))
else:
queueLock.release()
time.sleep(1)
threadList = ["Thread-1", "Thread-2", "Thread-3"]
nameList = ["One", "Two", "Three", "Four", "Five"]
queueLock = threading.Lock()
workQueue = queue.Queue(10)
threads = []
threadID = 1
# 创建新线程
for tName in threadList:
thread = myThread(threadID, tName, workQueue)
thread.start()
threads.append(thread)
threadID += 1
# 填充队列
queueLock.acquire()
for word in nameList:
workQueue.put(word)
queueLock.release()
# 等待队列清空
while not workQueue.empty():
pass
# 通知线程是时候退出
exitFlag = 1
# 等待所有线程完成
for t in threads:
t.join()
print ("退出主线程")
以上程序执行结果: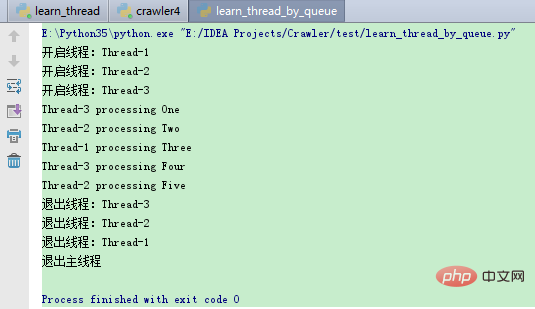
推荐学习:python学习教程
위 내용은 Python 멀티스레딩을 해석하는 방법을 안내합니다.의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!