
Redis의 실무 진입 및 지속성에 대한 심층 분석(요약 공유)

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWB앞으로
- 2022-02-21 18:09:112383검색
이 기사에서는 redis6.0 시작, Redis 지속성, Redis 복제 원칙, Redis 고가용성 센티널 모니터링 및 클러스터 구성 관련 지식을 포함하여 입문부터 실습까지 Redis에 대한 질문을 제공합니다. 모두를 돕습니다.

redis6.0 시작, Redis 지속성, Redis 복제 원칙, Redis 고가용성 센티널 모니터링 및 클러스터 구성에 대한 자세한 튜토리얼입니다.
Interviewer: 여러분, Redis에 대한 귀하의 견해에 대해 이야기해 보겠습니다.
Me: 아 어때요, 앉아서 보거나 누워서 보거나. Redis는 작습니까? 곧? 하지만 오래가나요?
Interviewer: 진지하게 말씀드리자면, 운전뿐만 아니라 컬러링도 하고 계시는 것 같아요.
나:. . .
Interviewer: 가, 가, 가, 내 시간은 제한되어 있으니 말도 안 되는 소리 하지 마세요. 주제로 돌아가서, Redis에 대해 얼마나 알고 계시나요?
Me: 가볍고 작은 크기, 메모리 기반 매우 빠른 RDB 및 AOF 지속성 덕분에 똑같이 강력하고 내구성이 뛰어납니다.
Interviewer: 구체적으로 말해주세요.
Me: 본문 꼭 읽어주세요.

Text
소개
Redis는 캐싱 및 스토리지 요구 사항에 맞게 다양한 키-값 데이터 유형을 제공하는 고성능 오픈 소스 키-값 쌍 기반 캐싱 및 스토리지 시스템입니다. 다른 시나리오. 동시에 Redis의 많은 고급 기능을 통해 메시지 큐 및 작업 큐와 같은 다양한 역할을 수행할 수 있습니다. 또한 Redis는 외부 모듈 확장도 지원하며 특정 특정 시나리오에서 기본 데이터베이스로 사용할 수 있습니다.
메모리의 읽기 및 쓰기 속도는 하드 디스크보다 훨씬 빠르기 때문에 현재의 SSD에 대한 생각도 아마도 메모리의 사고 모드로 발전하고 있는 것 같습니다. 아마도 저는 장기 저장을 위한 것입니다. , 저는 아직도 기계식 디스크를 사용하고 있습니다. 따라서 Redis 데이터베이스의 모든 데이터는 매우 빠른 메모리에 저장됩니다. 데이터 손실로 이어질 특정 위험도 있지만 RDB 및 AOF 지속성을 사용하면 위험이 줄어듭니다.
1. Redis 첫 소개
1. Linux(Redhat7 시리즈)에서의 설치
1.1. 설치
여기서 준비한 소스코드 패키지는 최신 버전은 아니지만 안정적이고 적용 가능합니다.
나머지 버전은 공식 홈페이지나 호스팅 플랫폼인 github에서 보실 수 있습니다. 다음은 Redis 공식 홈페이지 다운로드 주소입니다.
https://redis.io/download
redis-6.0.8.tar.gz#安装tar -zxvf redis-6.0.8.tar.gz#编译make && make install
1.2, 오류 문제 해결
make[1]: *** [server.o] 错误 1

1.3, 솔루션
1.3.1, 종속 환경 설치
yum -y install centos-release-scl yum -y install devtoolset-9-gcc devtoolset-9-gcc-c++ devtoolset-9-binutils
1.3.2, 환경 변수 추가 및 적용
scl enable devtoolset-9 bashecho "/opt/rh/devtoolset-9/enable" >> /etc/profile
환경 변수 구성 파일을 다시 읽어보세요
source /etc/profile
다시 컴파일하여 문제 해결
#切换到Redis的安装目录,一般源码包安装会放在/usr/local/下面,看个人使用习惯cd /opt/redis-6.0.8/ #编译make && make install
일반적인 기본 명령 연습은 초보자 튜토리얼을 참조하세요
https://www.runoob.com/ redis/redis-commands.html
1.4. 시작 및 로그인
redis-server 서버 시작
#启动redis服务nohup /opt/redis-6.0.8/src/redis-server &
redis-cli 클라이언트에 로그인
#登录redis-cli/opt/redis-6.0.8/src/redis-cli
이제 Linux에서 Redis가 공식적으로 시작되었습니다. 다음은 기본적인 사용법을 소개합니다.
pingpong

1.5. 비밀번호 설정
기본적으로 공개 비밀번호 설정은 없으며, 주석 처리된 매개변수 구성을 수동으로 활성화해야 합니다.
#编辑配置文件vim /opt/redis-6.0.8/redis.conf #原本的被注释掉,复制一行改成你设置的密码即可 #requirepass foobaredrequirepass 123456
2. Windows에
2.1을 설치합니다. Windows에
Redis-x64-3.2.100.zip
2.1.1을 설치하거나 msi를 통해 직접 설치합니다.
2.1.2 서비스 명령 설정(서비스 양식으로 등록, 자체 시작)
서비스 설치
redis-server --service-install redis.windows-service.conf --loglevel verbose
서비스 제거
redis-server --service-uninstall
2.2.시작 및 종료
redis-server redis.windows.conf
2.2.1.
redis-server --service-start2.2.2. 서비스 중지
redis-server --service-stop2.3. redis 서비스 시작
#同样在redis解压的或者安装的目录以管理员身份运行cmdredis-server --service-start
2.4. Windows의 관리 도구 rdm은 https://redisdesktop입니다. com/download2. 기본 지식
1. 자주 묻는 면접 질문
: Redis에는 어떤 데이터 유형이 있나요?
I: string(문자열 유형), hash(해시 유형), list(목록 유형), set(세트 유형), zset(순서 있는 세트 유형),
stream(스트림 유형) stream은 새로운 기능 지원 redis5.0에서. Interviewer
: 아, 이 청년은 방송 장르까지 아는 게 많아요.
Me: 혼란스러워요...
3. 고급 1. Persistence
Interviewer: Redis의 고급 기능을 아시나요?
Me: 조금 알아요.
Interviewer: 자세히 얘기해주실 수 있나요?
Me: 뇌수색자들 앞에서 빠르게 읽고 요약했습니다. 캐싱과 지속성이 다가오고 있습니다.
将Redis作为缓存服务器,但缓存被穿透后会对性能照成较大影响,所有缓存同时失效缓存雪崩,从而使服务无法响应。
我们希望Redis能将数据从内存中以某种形式同步到磁盘中,使之重启以后根据磁盘中的记录恢复数据。这一过程就是持久化。
面试官:知道Redis有哪几种常见的持久化方式吗?
我:Redis默认开启的RDB持久化,AOF持久化方式需要手动开启。
Redis支持两种持久化。一种是RDB方式,一种是AOF方式。前者会根据指定的规则“定时”将内存中的数据存储到硬盘上,而后者在每次执行命令后将命令本书记录下来。对于这两种持久化方式,你可以单独使用其中一种,但大多数情况下是将二者紧密结合起来。
此时的面试官一脸期待,炯炯有神的看向了我,请继续。
2、RDB方式
继续介绍,RDB采取的是快照方式,默认设置自定义快照【自动同步】,默认配置如下。

同样可以手动同步
#不推荐在生产环境中使用SAVE
#异步形式BGSAVE
#基于自定义快照FLASHALL
3、AOF方式
当使用Redis存储非临时数据时,一般需要打开AOF持久化来降低进程终止导致数据的丢失。AOF可以将Redis执行的每一条命令追加到硬盘文件中,着这个过程中显然会让Redis的性能打折扣,但大部分情况下这种情况可以接受。这里强调一点,使用读写较快的硬盘可以提高AOF的性能。
默认没有开启,需要手动开启AOF,当你查看redis.conf文件时也会发现appendonly配置的是no
appendonly yes
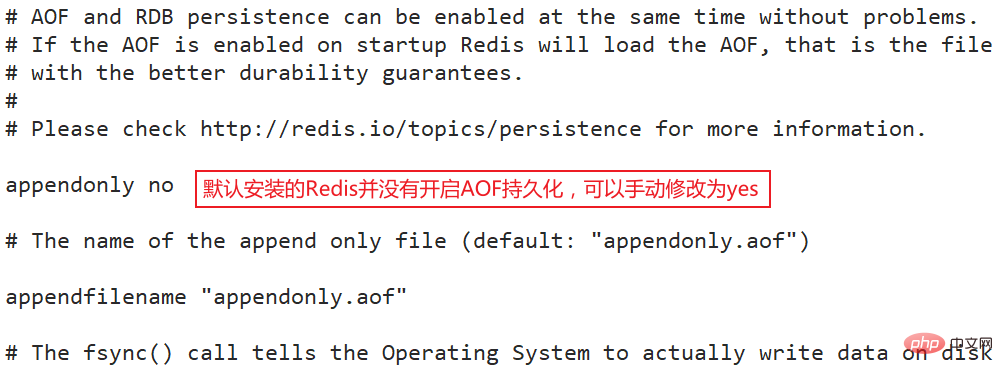
开启AOF持久化后,每次执行一条命令会会更改Redis中的数据的目录,Redis会将该命令写入磁盘中的AOF文件。AOF文件的保存位置和RDB文件的位置相同,都是通过dir参数设置,默认的文件名是appendonly.aof,可以通过appendfilename参数修改。
appendfilename "appendonly.aof

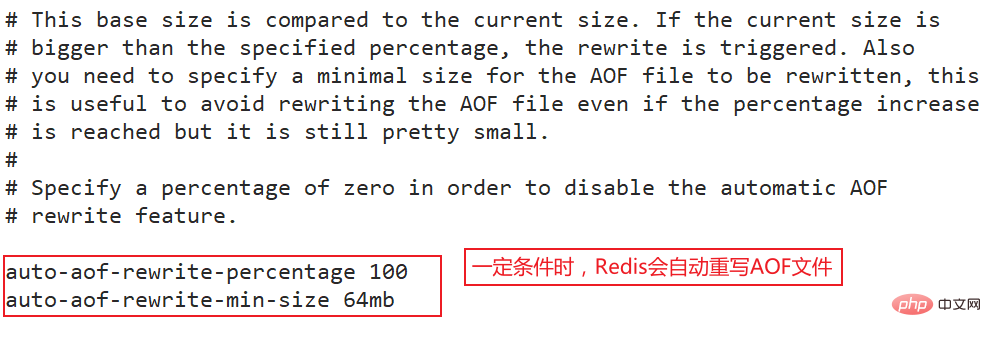
实际上Redis也正是这样做的,每当达到一定的条件时Redis就会自动重写AOF文件,这个条件可以通过redis.conf配置文件中设置:
auto-aof-rewrite-percentage 100auto-aof-rewrite-min-size 64mb
在启动时Redis会逐行执行AOF文件中的命令将硬盘中的数据加载到内存中,加载的速度相比RDB会慢一些。
虽然每次执行更改数据库内容的操作时,AOF都将命令记录在AOF文件中。但事实上,由于操作系统的缓存机制,数据并没与真正写入硬盘,而是进入了操作系统的硬盘缓存。在默认情况下,操作系统每30秒会执行一次同步操作,以便将硬盘缓存中的内容写入硬盘。
在Redis中可以通过appendfsync设置同步的时机:
# appendfsync always #默认设置为everysecappendfsync everysec # appendfsync no
Redis允许同时开启AOF和RDB。这样既保证了数据的安全,又对进行备份等操作比较友好。此时重新启动Redis后,会使用AOF文件来恢复数据。因为AOF方式的持久化,将会丢失数据的概率降至最小化。
4、Redis复制
通过持久化功能,Redis保证了即使服务器重启的情况下也不会丢失(少部分遗失)数据。但是数据库是存储在单台服务器上的,难免不会发生各种突发情况,比如硬盘故障,服务器突然宕机等等,也会导致数据遗失。
为了尽可能的避免故障,通常做法是将数据库复制多个副本以部署在不同的服务器上。这样即使有一台出现故障,其它的服务器依旧可以提供服务。为此,Redis提供了复制(replication)功能。即实现一个数据库中的数据更新后,自动将更新的数据同步到其它数据库上。
此时熟悉MySQL的同学,是不是觉得与MySQL的主从复制很像,以开启二进制日志binlog实现同步复制。
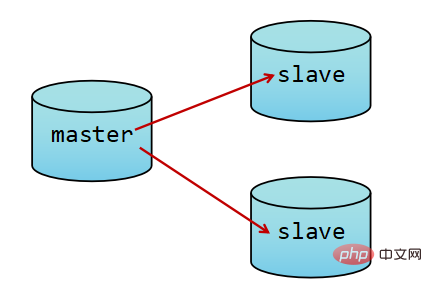
而Redis中使用复制功能更为容易,相比MySQL而言。只需要在从库中启动时加入slaveof 从数据库地址。
#在从库中配置slaveof master_database_ip_addr #测试,加了nohup与&是放入后台,并且输出日志到/root/目录下的nohup.outnohup /opt/redis-6.0.8/src/redis-server --6380 --slaveof 192.168.245.147 6379 &

4.1、原理
复制初始化。这里主要原理是从库启动,会向主库发送SYNC命令。同时主库接收到SYNC命令后会开始在后台保存快照,即RDB持久化的过程,并将快照期间接收的命令缓存起来。当快照完成后,Redis会将快照文件和所有缓存的命令发送给从数据库。从数据库收到后,会载入快照文件并执行收到的缓存命令。
复制同步阶段会贯穿整个主从同步过程,直到主从关系终止为止。在复制的过程中快照起到了至关重要的作用,只要执行复制就会进行快照,即使关闭了RDB方式的持久化,通过删除所有save参数。
4.2、乐观复制
Redis采用了乐观复制(optimistic replication)的复制策略。容忍在一定时间内主从数据库的内容是不同的,但是两者的数据最终是会同步的。具体来讲,Redis在主从数据库之间复制数据的过程本身是异步的,这就意味着,主数据库执行完客户端请求的命令会立即将命令在主数据库的执行结果反馈给客户端,并异步的将数据同步给从库,不会等待从数据库接收到该命令在返回给客户端。
当数据至少同步给指定数量的从库时,才是可写,通过参数指定:
#设置最少限制3min-slaves-to-write 3 #设置允许从数据最长失去连接时间min-slaves-max-lag 10
4.3、增量复制
基于以下三点实现
- 从库会存储主库的运行ID(run id)。每个Redis运行实例均会拥有一个唯一运行ID,每当实例重启后,就会自动生成一个新的运行ID。类似于MySQL的从节点配置的唯一ID去识别。
- 在复制同步阶段,主库一条命令被传送到从库时,会同时把该命令存放到一个积压队列(backlog)中,记录当前积压队列中存放的命令的偏移量范围。
- 从库接收到主库传来的命令时,会记录该命令的偏移量。
4.4、注意
当主数据库崩溃时,情况略微复杂。手动通过从数据库数据库恢复主库数据时,需要严格遵循以下原则:
- 在从数据库中使用
SLAVEOF NO ONE命令将从库提升为主库继续服务。 - 启动之前崩溃的主库,然后使用
SLAVEOF命令将其设置为新的主库的从库。
注意:当开启复制且数据库关闭持久化功能时,一定不要使用supervisor以及类似的进程管理工具令主库崩溃后重启。同样当主库所在的服务器因故障关闭时,也要避免直接重新启动。因为当主库重启后,没有开启持久化功能,数据库中所有数据都被清空。此时从库依然会从主库中接收数据,从而导致所有从库也被清空,导致数据库的持久化开了个寂寞。
手动维护确实很麻烦,好在Redis提供了一种自动化方案:哨兵去实现这一过程,避免手动维护易出错的问题。
5、哨兵(sentinel)
从Redis的复制历中,我们了解到在一个典型的一主多从的Redis系统中,从库在整个系统中起到了冗余备份以及读写分离的作用。当主库遇到异常中断服务后,开发人员手动将从升主时,使系统继续服务。过程相对复杂,不好实现自动化。此时可借助哨兵工具。
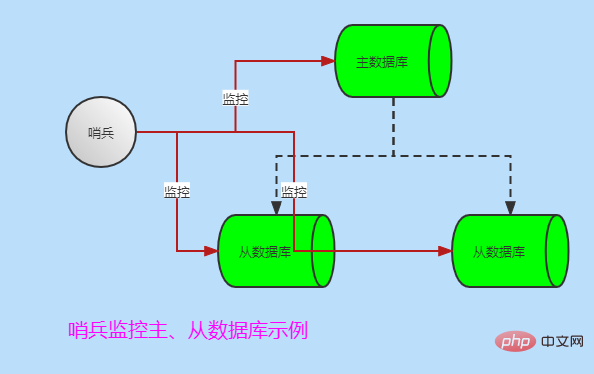
哨兵的作用
- 监控Redis系统运行情况
- 监控主库和从库是否正常运行
- 主库gg思密达,自动将从库升为主库,美滋滋
当然也有多个哨兵监控主从数据库模式,哨兵之间也会互相监控,如下图:

首先需要建立起一主多从的模型,然后开启配置哨兵。
#主库sentinel monitor master 127.0.0.1 6379 1 #建立配置文件,例如sentinel.confredis-sentinel /opt/path/to/sentinel.conf
关于哨兵就介绍这么多,现在大脑中有印象。至少知道有那么回事,可以和美女面试官多掰扯掰扯。
6、集群(cluster)
从Redis3.0开始加入了集群这一特性。
即使使用哨兵,此时的Redis集群的每个数据库依然存有集群中的所有数据,从而导致集群的总数据存储量受限于可用内存最小的数据库节点,继而出现木桶效应。正因为Redis所有数据都是基于内存存储,问题已经很突出,尤其是当Redis作为持久化存储服务时。
有这样一种场景。就扩容来说,在客户端分片后,如果像增加更多的节点,需要对数据库进行手动迁移。迁移的过程中,为了保证数据的一致性,需要将进群暂时下线,相对比较复杂。
此时考虑到Redis很小,啊不口误,是轻量的特点。可以采用预分片(presharding)在一定程度上避免问题的出现。换句话说,就是在部署的初期,提前考虑日后的存储规模,建立足够多的实例。
从上面的理论知识来看,哨兵和集群类似,但哨兵和集群是两个独立的功能。如果要进行水平扩容,集群是不错的选择。
配置集群,开启配置文件redis.conf中的cluster-enabled
cluster-enabled yes

配置集群每个节点配置不同工作目录,或者修改持久化文件
cluster-config-file nodes-6379.conf
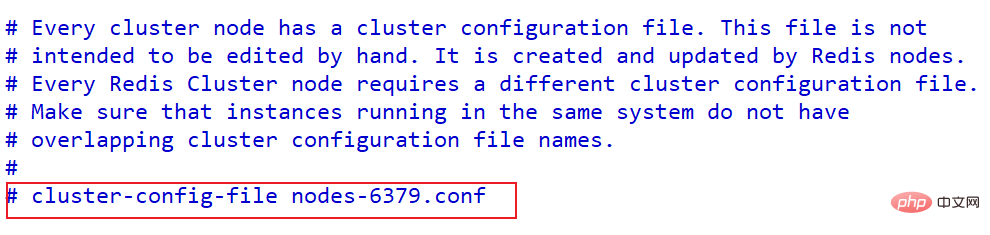
集群测试大家可以执行配置,参考其他书籍亦可,实现并不难。只要是知其原理。
四、Redis for Java
示例
package com.jedis;import redis.clients.jedis.Jedis;import redis.clients.jedis.JedisPool;import redis.clients.jedis.JedisPoolConfig;public class Test {
@org.junit.Test
public void demo() {
Jedis jedis = new Jedis("127.0.0.1", 6379);
jedis.set("name", "sky");
String params = jedis.get("jedis");
System.out.println(params);
jedis.close();
}
@org.junit.Test
public void config() {
// 获取连接池的配置对象
JedisPoolConfig config = new JedisPoolConfig();
// 设置最大连接数
config.setMaxTotal(30);
// 设置最大空闲连接数
config.setMaxIdle(10);
// 获取连接池
JedisPool pool = new JedisPool(config, "127.0.0.1", 6379);
// 获得核心对象
Jedis jedis = null;
try {
//通过连接池获取连接
jedis = pool.getResource();
//设置对象
jedis.set("poolname", "pool");
//获取对象
String pools = jedis.get("poolname");
System.out.println("values:"+pools);
} catch (Exception e) {
e.printStackTrace();
}finally{
//释放资源
if(jedis != null){
jedis.close();
}
if(pool != null){
pool.close();
}
}
}}
最后放一个制作很粗超的思维导图。
推荐学习:《Redis视频教程》、《2022最新redis面试题大全及答案》
위 내용은 Redis의 실무 진입 및 지속성에 대한 심층 분석(요약 공유)의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!