



이 기사에서는 MySQL의 인덱스와 관련하여 발생할 수 있는 몇 가지 문제를 소개합니다. 인덱스는 데이터베이스의 핵심이라고 할 수 있습니다. 데이터베이스에 인덱스가 없으면 데이터베이스 자체의 존재는 거의 의미가 없습니다. 모든 사람에게 도움이 되기를 바랍니다.

인덱스는 데이터베이스의 큰 심장이라고 할 수 있습니다. 데이터베이스에 인덱스가 없으면 데이터베이스 자체는 의미가 거의 없으며 일반 파일과 다르지 않습니다. 따라서 데이터베이스 시스템에서는 특히 좋은 인덱스가 중요합니다. 오늘은 MySQL 인덱스에 대해 세부적인 관점과 실제 비즈니스 관점에서 MySQL의 B+ 트리 인덱스의 이점과 지식 포인트를 살펴보겠습니다. 인덱스를 사용할 때 주의할 점은 다음과 같습니다.
인덱스의 합리적인 사용
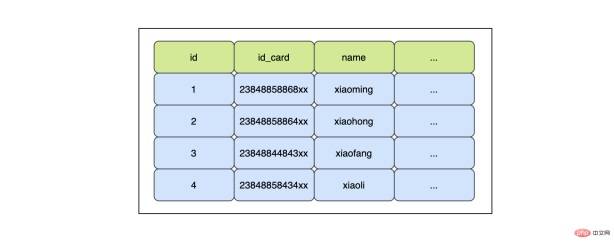
작업에서 데이터 테이블의 필드를 인덱싱해야 하는지 판단하는 가장 직접적인 방법은 이 필드가 where 조건 중간에 자주 나타나는지 여부입니다. . 거시적인 관점에서는 이런 생각을 해도 문제가 없지만, 장기적 관점에서 보면 때로는 좀 더 세부적인 생각이 필요할 수도 있습니다. 예를 들어 이 분야에 대해서만 지표를 만들어야 하는 것은 아닌가? 여러 필드에 대한 공동 인덱스가 더 좋나요? 사용자 테이블을 예로 들면, 사용자 테이블의 필드에는 where条件中。从宏观的角度来说,这样思考没有问题,但是从长远的角度来看,有时可能需要更细致的思考,比如我们是不是不仅仅需要在这个字段上建立一个索引?多个字段的联合索引是不是更好?以一张用户表为例,用户表中的字段可能会有用户的姓名、用户的身份证号、用户的家庭地址等等。
「1.普通索引的弊端」
现在有个需求需要根据用户的身份证号找到用户的姓名,这时候很显然想到的第一个办法就是在id_card사용자 이름
사용자 ID 번호
,- 사용자 집 주소
- 등이 포함될 수 있습니다.

「1. 일반 인덱스의 단점」
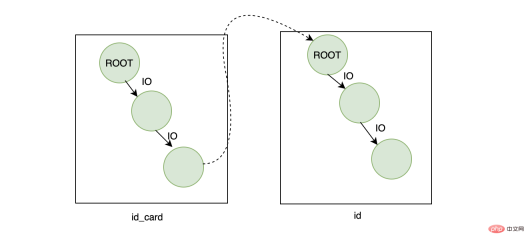 이제 사용자의 ID 번호를 기준으로 사용자 이름을 찾아야 할 필요가 있습니다. 이때 가장 먼저 떠오르는 방법은 엄밀히 말하면
이제 사용자의 ID 번호를 기준으로 사용자 이름을 찾아야 할 필요가 있습니다. 이때 가장 먼저 떠오르는 방법은 엄밀히 말하면 id_card에 색인을 생성하는 것입니다. 는 고유 인덱스입니다. ID 번호가 확실히 고유하기 때문에 다음 쿼리를 실행할 때:
SELECT name FROM user WHERE id_card=xxx
해당 프로세스는 다음과 같아야 합니다.
먼저 id_card 인덱스 트리에서 해당하는 기본 키 ID를 찾습니다. id_cardPass 기본키 인덱스에서 id를 검색해서 해당 이름을 찾아보세요
효과적인 측면에서는 결과는 문제가 없지만 효율성 측면에서는 이 쿼리가 좀 비싼 것 같습니다 하나의 트리를 가정하고 두 개의 B+ 트리를 검색하기 때문입니다. 높이는 3이고 두 트리의 높이는 6입니다. 루트 노드가 메모리(여기서는 루트 노드 2개)에 있으므로 수행할 최종 IO 수는 6입니다. 디스크는 하나의 임의 디스크 IO 시간을 기준으로 4번입니다. 평균 시간 소모가 10ms라면 최종적으로는 40ms가 소요됩니다. 이 수치는 평균 수치이며 빠르지는 않습니다.
「2. 기본 키 인덱스의 함정」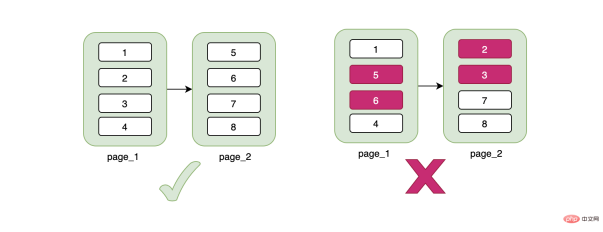
문제는 테이블 반환이므로 두 트리 모두에서 검색되므로 핵심 문제는 하나의 트리에서만 검색할 수 있는지 확인하는 것입니다. . 비즈니스 관점에서 여기에서 진입점을 찾았을 수 있습니다. ID 번호는 고유하므로 기본 키는 기본 자동 증가 ID를 사용할 수 없습니까? 기본 키를 ID 번호로 설정하여 전체 테이블에는 하나의 인덱스만 있으면 되고, 우리 이름을 포함해 필요한 모든 데이터는 ID 번호를 통해 찾을 수 있다고 생각하면 된다. , 괜찮을 텐데, 조심스럽게 생각해보면 문제가 있는 것 같습니다.
B+트리의 특징에 대해 이야기해보겠습니다. B+트리의 데이터는 리프 노드에 저장되며, 한 페이지가 16K로 관리된다는 것은 무엇을 의미합니까? 지금 한 행의 데이터가 있어도 16K 데이터 페이지를 차지합니다. 데이터 페이지가 가득 찬 경우에만 새 데이터 페이지와 이전 데이터 페이지가 물리적으로 분리됩니다. 반드시 연속적일 필요는 없지만 한 가지 중요한 점은 데이터 페이지가 물리적으로 불연속적이지만 데이터는 논리적으로 연속적이라는 것입니다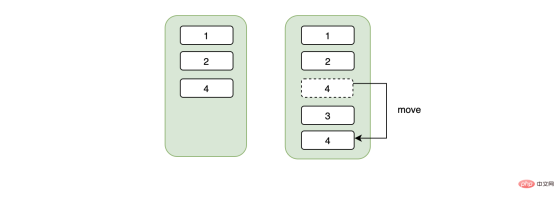 .
.
总结来说,不连续的身份证号当主键可能会造成页数据的移动、随机IO、频繁申请新页相关的开销。如果我们用的是自增的主键,那么对于id来说一定是顺序的,不会因为随机IO造成数据移动的问题,在插入方面开销一定是相对较小的。
其实不推荐用身份证号当主键的还有另外一个原因:身份证号作为数字来说太大了,得用bigint来存,正常来说一个学校的学生用int已经足够了,我们知道一页可以存放16K,当一个索引本身占用的空间越大时,会导致一页能存放的数据越少,所以在一定数据量的情况下,使用bigint要比int需要更多的页也就是更多的存储空间。
「3.联合索引的矛与盾」
由上面两条结论可以得出:
- 尽量不要去回表
- 身份证号不适合当主键索引
所以自然而然地想到了联合索引,创建一个【身份证号+姓名】的联合索引,注意联合索引的顺序,要符合最左原则。这样当我们同样执行以下sql时:
select name from user where id_card=xxx
不需要回表就可以得到我们需要的name字段,然而还是没有解决身份证号本身占用空间过大的问题,这是业务数据本身的问题,如果你要解决它的话,我们可以通过一些转换算法将原本大的数据转换成小的数据,比如crc32:
crc32.ChecksumIEEE([]byte("341124199408203232"))
可以将原本需要8个字节存储空间的身份证号用4个字节的crc码替代,因此我们的数据库需要再加个字段crc_id_card,联合索引也从【身份证号+姓名】变成了【crc32(身份证号)+姓名】,联合索引占的空间变小了。但是这种转换也是有代价的:
每次额外的crc,导致需要更多cpu资源
额外的字段,虽然让索引的空间变小了,但是本身也要占用空间
crc会存在冲突的概率,这需要我们查询出来数据后,再根据id_card过滤一下,过滤的成本根据重复数据的数量而定,重复越多,过滤越慢。
关于联合索引存储优化,这里有个小细节,假设现在有两个字段A和B,分别占用8个字节和20个字节,我们在联合索引已经是[A,B]的情况下,还要支持B的单独查询,因此自然而然我们在B上也建立个索引,那么两个索引占用的空间为 8+20+20=48,现在无论我们通过A还是通过B查询都可以用到索引,如果在业务允许的条件下,我们是否可以建立[B,A]和A索引,这样的话,不仅满足单独通过A或者B查询数据用到索引,还可以占用更小的空间:20+8+8=36。
「4.前缀索引的短小精悍」
有时候我们需要索引的字段是字符串类型的,并且这个字符串很长,我们希望这个字段加上索引,但是我们又不希望这个索引占用太多的空间,这时可以考虑建立个前缀索引,以这个字段的前一部分字符建立个索引,这样既可以享受索引,又可以节省空间,这里需要注意的是在前缀重复度较高的情况下,前缀索引和普通索引的速度应该是有差距的。
alter table xx add index(name(7));#name前7个字符建立索引 select xx from xx where name="JamesBond"
「5.唯一索引的快与慢」
在说唯一索引之前,我们先了解下普通索引的特点,我们知道对于B+树而言,叶子节点的数据是有序的。

假设现在我们要查询2这条数据,那么在通过索引树找到2的时候,存储引擎并没有停止搜索,因为可能存在多个2,这表现为存储引擎会在叶子节点上接着向后查找,在找到第二个2之后,就停止了吗?答案是否,因为存储引擎并不知道后面还有没有更多的2,所以得接着向后查找,直至找到第一个不是2的数据,也就是3,找到3之后,停止检索,这就是普通索引的检索过程。
唯一索引就不一样了,因为唯一性,不可能存在重复的数据,所以在检索到我们的目标数据之后直接返回,不会像普通索引那样还要向后多查找一次,从这个角度来看,唯一索引是要比普通索引快的,但是当普通索引的数据都在一个页内的话,其实也并不会快多少。在数据的插入方面,唯一索引可能就稍逊色,因为唯一性,每次插入的时候,都需要将判断要插入的数据是否已经存在,而普通索引不需要这个逻辑,并且很重要的一点是唯一索引会用不到change buffer(见下文)。
「6.不要盲目加索引」
在工作中,你可能会遇到这样的情况:这个字段我需不需要加索引?。对于这个问题,我们常用的判断手段就是:查询会不会用到这个字段,如果这个字段经常在查询的条件中,我们可能会考虑加个索引。但是如果只根据这个条件判断,你可能会加了一个错误的索引。我们来看个例子:假设有张用户表,大概有100w的数据,用户表中有个性别字段表示男女,男女差不多各占一半,现在我们要统计所有男生的信息,然后我们给性别字段加了索引,并且我们这样写下了sql:
select * from user where sex="男"
如果不出意外的话,InnoDB是不会选择性别这个索引的。如果走性别索引,那么一定是需要回表的,在数据量很大的情况下,回表会造成什么样的后果?我贴一张和上面一样的图想必大家都知道了:

主要就是大量的IO,一条数据需要4次,那么50w的数据呢?结果可想而知。因此针对这种情况,MySQL的优化器大概率走全表扫描,直接扫描主键索引,因为这样性能可能会更高。
「7.索引失效那些事」
某些情况下,因为我们自己使用的不当,导致mysql用不到索引,这一般很容易发生在类型转换方面,也许你会说,mysql不是已经支持隐式转换了吗?比如现在有个整型的user_id索引字段,我们因为查询的时候没注意,写成了:
select xx from user where user_id="1234"
注意这里是字符的1234,当发生这种情况下,MySQL确实足够聪明,会把字符的1234转成数字的1234,然后愉快的使用了user_id索引。 但是如果我们有个字符型的user_id索引字段,还是因为我们查询的时候没注意,写成了:
select xx from user where user_id=1234
这时候就有问题了,会用不到索引,也许你会问,这时MySQL为什么不会转换了,把数字的1234转成字符型的1234不就行了? 这里需要解释下转换的规则了,当出现字符串和数字比较的时候,要记住:MySQL会把字符串转换成数字。也许你又会问:为什么把字符型user_id字段转换成数字就用不到索引了? 这又要说到B+树索引的结构了,我们知道B+树的索引是按照索引的值来分叉和排序的,当我们把索引字段发生类型转换时会发生值的变化,比如原来是A值,如果执行整型转换可能会对应一个B值(int(A)=B),这时这颗索引树就不能用了,因为索引树是按照A来构造的,不是B,所以会用不到索引。
索引优化
「1.change buffer」
我们知道在更新一条数据的时候,要先判断这条数据的页是否在内存里,如果在的话,直接更新对应的内存页,如果不在的话,只能去磁盘把对应的数据页读到内存中来,然后再更新,这会有什么问题呢?
- 去磁盘的读这个动作稍显的有点慢
- 如果同时更新很多数据,那么即有可能发生很多离散的IO
为了解决这种情况下的速度问题,change buffer出现了,首先不要被buffer这个单词误导,change buffer除了会在公共的buffer pool里之外,也是会持久化到磁盘的。当有了change buffer之后,我们更新的过程中,如果发现对应的数据页不在内存里的话,也不去磁盘读取相应的数据页了,而是把要更新的数据放入到change buffer中,那change buffer的数据何时被同步到磁盘上去?如果此时发生读动作怎么办?首先后台有个线程会定期把change buffer的数据同步到磁盘上去的,如果线程还没来得及同步,但是又发生了读操作,那么也会触发把change buffer的数据merge到磁盘的事件。

需要注意的是并不是所有的索引都能用到changer buffer,像主键索引和唯一索引就用不到,因为唯一性,所以它们在更新的时候要判断数据存不存在,如果数据页不在内存中,就必须去磁盘上把对应的数据页读到内存里,而普通索引就没关系了,不需要校验唯一性。change buffer越大,理论收益就越大,这是因为首先离散的读IO变少了,其次当一个数据页上发生多次变更,只需merge一次到磁盘上。当然并不是所有的场景都适合changer buffer,如果你的业务是更新之后,需要立马去读,changer buffer会适得其反,因为需要不停地触发merge动作,导致随机IO的次数不会变少,反而增加了维护changer buffer的开销。
「2.索引下推」
前面我们说了联合索引,联合索引要满足最左原则,即在联合索引是[A,B]的情况下,我们可以通过以下的sql用到索引:
select * from table where A="xx" select * from table where A="xx" AND B="xx"
其实联合索引也可以使用最左前缀的原则,即:
select * from table where A like "赵%" AND B="上海市"
但是这里需要注意的是,因为使用了A的一部分,在MySQL5.6之前,上面的sql在检索出所有A是“赵”开头的数据之后,就立马回表(使用的select *),然后再对比B是不是“上海市”这个判断,这里是不是有点懵?为什么B这个判断不直接在联合索引上判断,这样的话回表的次数不就少了吗?造成这个问题的原因还是因为使用了最左前缀的问题,导致索引虽然能使用部分A,但是完全用不到B,看起来是有点“傻”,于是在MySQL5.6之后,就出现了索引下推这个优化(Index Condition Pushdown),有了这个功能以后,虽然使用的是最左前缀,但是也可以在联合索引上搜索出符合A%的同时也过滤非B的数据,大大减少了回表的次数。
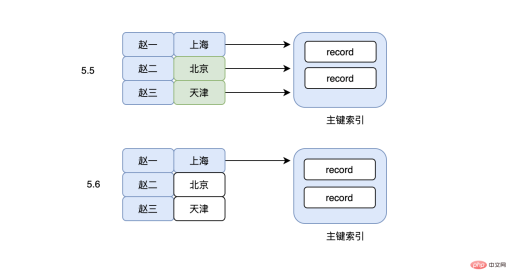
「3.刷新邻接页」
在说刷新邻接页之前,我们先说下脏页,我们知道在更新一条数据的时候,得先判断这条数据所在的页是否在内存中,如果不在的话,需要把这个数据页先读到内存中,然后再更新内存中的数据,这时会发现内存中的页有最新的数据,但是磁盘上的页却依然是老数据,那么此时这条数据所在的内存中的页就是脏页,需要刷到磁盘上来保持一致。所以问题来了,何时刷?每次刷多少脏页才合适?如果每次变更就刷,那么性能会很差,如果很久才刷,脏页就会堆积很多,造成内存池中可用的页变少,进而影响正常的功能。所以刷的速度不能太快但要及时,MySQL有个清理线程会定期执行,保证了不会太快,当脏页太多或者redo log已经快满了,也会立刻触发刷盘,保证了及时。

在脏页刷盘的过程中,InnoDB这里有个优化:如果要刷的脏页的邻居页也脏了,那么就顺带一起刷,这样的好处就是可以减少随机IO,在机械磁盘的情况下,优化应该挺大,但是这里可能会有坑,如果当前脏页的邻居脏页在被一起刷入后,邻居页立马因为数据的变更又变脏了,那此时是不是有种多此一举的感觉,并且反而浪费了时间和开销。更糟糕的是如果邻居页的邻居也是脏页...,那么这个连锁反应可能会出现短暂的性能问题。
「4.MRR」
在实际业务中,我们可能会被告知尽量使用覆盖索引,不要回表,因为回表需要更多IO,耗时更长,但是有时候我们又不得不回表,回表不仅仅会造成过多的IO,更严重的是过多的离散IO。
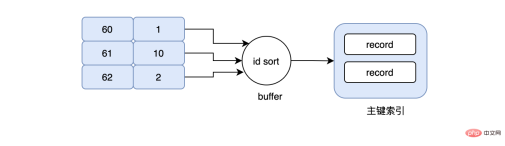
select * from user where grade between 60 and 70
现在要查询成绩在60-70之间的用户信息,于是我们的sql写成上面的那样,当然我们的grade字段是有索引的,按照常理来说,会先在grade索引上找到grade=60这条数据,然后再根据grade=60这条数据对应的id去主键索引上找,最后再次回到grade索引上,不停的重复同样的动作..., 假设现在grade=60对应的id=1,数据是在page_no_1上,grade=61对应的id=10,数据是在page_no_2上,grade=62对应的id=2,数据是在page_no_1上,所以真实的情况就是先在page_no_1上找数据,然后切到page_no_2,最后又切回page_no_1上,但其实id=1和id=2完全可以合并,读一次page_no_1即可,不仅节省了IO,同时避免了随机IO,这就是MRR。当使用MRR之后,辅助索引不会立即去回表,而是将得到的主键id,放在一个buffer中,然后再对其排序,排序后再去顺序读主键索引,大大减少了离散的IO。
推荐学习:mysql视频教程
위 내용은 MySQL 인덱스의 함정을 이해해야 합니다.의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!

 MySQL은 sqlite와 어떻게 다릅니 까?Apr 24, 2025 am 12:12 AM
MySQL은 sqlite와 어떻게 다릅니 까?Apr 24, 2025 am 12:12 AMMySQL과 Sqlite의 주요 차이점은 설계 개념 및 사용 시나리오입니다. 1. MySQL은 대규모 응용 프로그램 및 엔터프라이즈 수준의 솔루션에 적합하며 고성능 및 동시성을 지원합니다. 2. SQLITE는 모바일 애플리케이션 및 데스크탑 소프트웨어에 적합하며 가볍고 내부질이 쉽습니다.
 MySQL의 색인이란 무엇이며 성능을 어떻게 향상 시키는가?Apr 24, 2025 am 12:09 AM
MySQL의 색인이란 무엇이며 성능을 어떻게 향상 시키는가?Apr 24, 2025 am 12:09 AMMySQL의 인덱스는 데이터 검색 속도를 높이는 데 사용되는 데이터베이스 테이블에서 하나 이상의 열의 주문 구조입니다. 1) 인덱스는 스캔 한 데이터의 양을 줄임으로써 쿼리 속도를 향상시킵니다. 2) B-Tree Index는 균형 잡힌 트리 구조를 사용하여 범위 쿼리 및 정렬에 적합합니다. 3) CreateIndex 문을 사용하여 CreateIndexIdx_customer_idonorders (customer_id)와 같은 인덱스를 작성하십시오. 4) Composite Indexes는 CreateIndexIdx_customer_orderOders (Customer_id, Order_Date)와 같은 다중 열 쿼리를 최적화 할 수 있습니다. 5) 설명을 사용하여 쿼리 계획을 분석하고 피하십시오
 MySQL에서 트랜잭션을 사용하여 데이터 일관성을 보장하는 방법을 설명하십시오.Apr 24, 2025 am 12:09 AM
MySQL에서 트랜잭션을 사용하여 데이터 일관성을 보장하는 방법을 설명하십시오.Apr 24, 2025 am 12:09 AMMySQL에서 트랜잭션을 사용하면 데이터 일관성이 보장됩니다. 1) STARTTRANSACTION을 통해 트랜잭션을 시작한 다음 SQL 작업을 실행하고 커밋 또는 롤백으로 제출하십시오. 2) SavePoint를 사용하여 부분 롤백을 허용하는 저장 지점을 설정하십시오. 3) 성능 최적화 제안에는 트랜잭션 시간 단축, 대규모 쿼리 방지 및 격리 수준을 합리적으로 사용하는 것이 포함됩니다.
 MySQL을 통해 어떤 시나리오에서 PostgreSQL을 선택할 수 있습니까?Apr 24, 2025 am 12:07 AM
MySQL을 통해 어떤 시나리오에서 PostgreSQL을 선택할 수 있습니까?Apr 24, 2025 am 12:07 AMMySQL 대신 PostgreSQL을 선택한 시나리오에는 다음이 포함됩니다. 1) 복잡한 쿼리 및 고급 SQL 기능, 2) 엄격한 데이터 무결성 및 산 준수, 3) 고급 공간 기능이 필요하며 4) 큰 데이터 세트를 처리 할 때 고성능이 필요합니다. PostgreSQL은 이러한 측면에서 잘 수행되며 복잡한 데이터 처리 및 높은 데이터 무결성이 필요한 프로젝트에 적합합니다.
 MySQL 데이터베이스를 어떻게 보호 할 수 있습니까?Apr 24, 2025 am 12:04 AM
MySQL 데이터베이스를 어떻게 보호 할 수 있습니까?Apr 24, 2025 am 12:04 AMMySQL 데이터베이스의 보안은 다음 조치를 통해 달성 할 수 있습니다. 1. 사용자 권한 관리 : CreateUser 및 Grant 명령을 통한 액세스 권한을 엄격히 제어합니다. 2. 암호화 된 전송 : 데이터 전송 보안을 보장하기 위해 SSL/TLS를 구성합니다. 3. 데이터베이스 백업 및 복구 : MySQLDump 또는 MySQLPump를 사용하여 정기적으로 백업 데이터를 사용하십시오. 4. 고급 보안 정책 : 방화벽을 사용하여 액세스를 제한하고 감사 로깅 작업을 가능하게합니다. 5. 성능 최적화 및 모범 사례 : 인덱싱 및 쿼리 최적화 및 정기 유지 보수를 통한 안전 및 성능을 모두 고려하십시오.
 MySQL 성능을 모니터링하는 데 사용할 수있는 몇 가지 도구는 무엇입니까?Apr 23, 2025 am 12:21 AM
MySQL 성능을 모니터링하는 데 사용할 수있는 몇 가지 도구는 무엇입니까?Apr 23, 2025 am 12:21 AMMySQL 성능을 효과적으로 모니터링하는 방법은 무엇입니까? Mysqladmin, Showglobalstatus, Perconamonitoring and Management (PMM) 및 MySQL Enterprisemonitor와 같은 도구를 사용하십시오. 1. MySQLADMIN을 사용하여 연결 수를보십시오. 2. showglobalstatus를 사용하여 쿼리 번호를보십시오. 3.pmm은 자세한 성능 데이터 및 그래픽 인터페이스를 제공합니다. 4. MySQLENTERPRISOMITOR는 풍부한 모니터링 기능 및 경보 메커니즘을 제공합니다.
 MySQL은 SQL Server와 어떻게 다릅니 까?Apr 23, 2025 am 12:20 AM
MySQL은 SQL Server와 어떻게 다릅니 까?Apr 23, 2025 am 12:20 AMMySQL과 SqlServer의 차이점은 1) MySQL은 오픈 소스이며 웹 및 임베디드 시스템에 적합합니다. 2) SQLServer는 Microsoft의 상용 제품이며 엔터프라이즈 수준 애플리케이션에 적합합니다. 스토리지 엔진의 두 가지, 성능 최적화 및 응용 시나리오에는 상당한 차이가 있습니다. 선택할 때는 프로젝트 규모와 향후 확장 성을 고려해야합니다.
 MySQL을 통해 어떤 시나리오에서 SQL Server를 선택할 수 있습니까?Apr 23, 2025 am 12:20 AM
MySQL을 통해 어떤 시나리오에서 SQL Server를 선택할 수 있습니까?Apr 23, 2025 am 12:20 AM고 가용성, 고급 보안 및 우수한 통합이 필요한 엔터프라이즈 수준의 응용 프로그램 시나리오에서는 MySQL 대신 SQLServer를 선택해야합니다. 1) SQLServer는 고 가용성 및 고급 보안과 같은 엔터프라이즈 수준의 기능을 제공합니다. 2) VisualStudio 및 Powerbi와 같은 Microsoft Ecosystems와 밀접하게 통합되어 있습니다. 3) SQLSERVER는 성능 최적화에서 우수한 성능을 발휘하며 메모리 최적화 된 테이블 및 열 스토리지 인덱스를 지원합니다.


핫 AI 도구

Undresser.AI Undress
사실적인 누드 사진을 만들기 위한 AI 기반 앱

AI Clothes Remover
사진에서 옷을 제거하는 온라인 AI 도구입니다.

Undress AI Tool
무료로 이미지를 벗다

Clothoff.io
AI 옷 제거제

Video Face Swap
완전히 무료인 AI 얼굴 교환 도구를 사용하여 모든 비디오의 얼굴을 쉽게 바꾸세요!

인기 기사
뜨거운 도구

VSCode Windows 64비트 다운로드
Microsoft에서 출시한 강력한 무료 IDE 편집기

Atom Editor Mac 버전 다운로드
가장 인기 있는 오픈 소스 편집기

에디트플러스 중국어 크랙 버전
작은 크기, 구문 강조, 코드 프롬프트 기능을 지원하지 않음

드림위버 CS6
시각적 웹 개발 도구

SublimeText3 영어 버전
권장 사항: Win 버전, 코드 프롬프트 지원!

