
Oracle에서 인덱스 생성 및 사용(요약 공유)

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWB앞으로
- 2021-12-31 18:53:5212086검색
이 기사는 Oracle의 인덱스 생성 및 사용에 대한 관련 지식을 제공하는 데 도움이 되기를 바랍니다.

OLTP 시스템 인덱스 생성
인덱스 생성의 역할
1 고유한 인덱스를 생성함으로써 데이터베이스 테이블의 각 데이터 행의 고유성을 보장할 수 있습니다.
2. 데이터 검색 속도를 크게 높일 수 있으며 이는 인덱스를 만드는 주요 이유이기도 합니다.
3. 테이블 간의 연결 속도를 높일 수 있으며 이는 특히 데이터의 참조 무결성을 달성하는 데 의미가 있습니다.
4. 데이터 검색을 위해 그룹화 및 정렬 절을 사용하면 쿼리의 그룹화 및 정렬 시간도 크게 줄일 수 있습니다.
5. 인덱스를 사용하면 쿼리 과정에서 최적화 숨기기를 사용하여 시스템 성능을 향상시킬 수 있습니다.
인덱스 열 선택 방법
1. 작성해야 하는 인덱스 열의 특징
1) 자주 작성해야 하는 열.
2) 기본 키인 열에 해당 열의 고유성을 적용하고 테이블의 데이터 배열 구조를 구성합니다.
3) 자주 사용되는 열에; 연결에서 이러한 열은 주로 연결 속도를 높일 수 있는 일부 외래 키입니다.
4) 인덱스가 정렬되어 있고 지정된 범위를 기준으로 자주 검색해야 하는 열에 인덱스를 만듭니다.
5) 자주 정렬해야 하는 열에서 인덱스가 정렬되었으므로 해당 열에 인덱스를 생성하면 쿼리에서 인덱스 정렬을 사용하여 정렬 쿼리 시간을 단축할 수 있습니다. 6) WHERE 절에서 자주 사용되는 컬럼에 인덱스를 생성하여 조건 판단을 빠르게 합니다.
2. 인덱스를 생성하면 안되는 컬럼의 특징
1) 쿼리에서 거의 사용되거나 참조되지 않는 컬럼에 대해서는 인덱스를 생성하면 안 됩니다. 이는 이러한 열이 거의 사용되지 않기 때문에 인덱싱 여부에 관계없이 쿼리 속도가 향상되지 않기 때문입니다. 반대로, 인덱스 추가로 인해 시스템 유지 속도가 감소하고 필요한 공간이 증가합니다.
2) 데이터 값이 적은 열의 경우 인덱스를 늘리면 안 됩니다. 이는 이러한 컬럼은 인사 테이블의 성별 컬럼과 같이 값이 매우 적기 때문에 질의 결과에서는 결과 세트의 데이터 행이 테이블의 데이터 행 중 큰 부분을 차지하기 때문입니다. 테이블에서 검색해야 할 데이터 행의 비율이 엄청납니다. 인덱스를 늘려도 검색 속도는 크게 향상되지 않습니다.
3) Blob 데이터 유형으로 정의된 열에 대해서는 인덱스를 늘려서는 안 됩니다. 이는 이러한 열의 데이터 볼륨이 상당히 크거나 값이 거의 없기 때문입니다.
4) 수정 성능이 검색 성능보다 훨씬 높을 경우 인덱스를 생성하면 안 됩니다. 수정 성능과 검색 성능이 서로 상반되기 때문이다. 인덱스를 추가하면 검색 성능은 향상되지만 수정 성능은 저하됩니다. 인덱스를 줄이면 수정 성능이 향상되고 검색 성능이 저하됩니다. 따라서 수정 성능이 검색 성능보다 훨씬 높을 경우에는 인덱스를 생성하지 않아야 합니다. (데이터 양이 많으므로 파티션 인덱스 생성을 고려하세요.)
인덱스 생성 구문
CREATEUNIUQE | BITMAP INDEX <schema>.<index_name> ON <schema>.<table_name> (<column_name> | <expression> ASC | DESC, <column_name> | <expression> ASC | DESC,...) TABLESPACE <tablespace_name> STORAGE <storage_settings> LOGGING | NOLOGGING COMPUTE STATISTICS NOCOMPRESS | COMPRESS<nn> NOSORT | REVERSE PARTITION | GLOBAL PARTITION<partition_setting>
관련 지침
1) UNIQUE | BITMAP: 고유 값 인덱스로 UNIQUE, 비트맵 인덱스로 BITMAP 지정, B-트리 인덱스.
2)
3) TABLESPACE: 인덱스가 있는 테이블 공간을 지정합니다. 저장됨(인덱스 및 원본 테이블이 동일한 테이블스페이스에 없을 때 더 효율적임)
4) STORAGE: 테이블스페이스의 저장 매개변수를 추가로 설정할 수 있습니다
5) LOGGING | REDO 로그 생성 여부 (대형 테이블의 경우 NOLOGGING을 사용하여 점유 공간을 줄이고 효율성을 높이세요)
6) COMPUTESTATISTICS: 새 인덱스를 생성할 때 통계 정보를 수집합니다
7) NOCOMPRESS | COMPRESSe3893df0bf62425a743f89f707bc0058: "키 사용 여부" 압축" (키 압축을 사용하면 키 열에 나타나는 중복 값을 삭제할 수 있음)
8) NOSORT | REVERSE: NOSORT는 테이블과 동일한 순서로 인덱스를 생성한다는 의미이고, REVERSE는 인덱스 값을 테이블에 저장한다는 의미입니다. 역순
9) PARTITION | NOPARTITION: 생성된 인덱스는 분할된 테이블과 분할되지 않은 테이블 모두에서 분할될 수 있습니다.
인덱스 사용에 대한 오해
제한된 인덱스
제한된 인덱스는 경험이 부족한 개발자가 자주 범하는 실수 중 하나입니다. SQL에는 일부 인덱스를 사용할 수 없게 만드는 함정이 많이 있습니다. 몇 가지 일반적인 문제는 아래에 설명되어 있습니다.
1. 부등식 연산자(a8093152e673feb7aba1828c43532094, !=) 사용 아래 쿼리에 cust_rated 열에 대한 인덱스가 있더라도 쿼리 문은 여전히 전체 테이블 스캔을 수행합니다. . select cust_Id,cust_name from customers wherecust_rating<> 'aa';
비용 기반(보다 지능적인) 최적화 도구 대신 규칙 기반 최적화 도구를 사용할 때 인덱스가 사용되도록 위 명령문을 다음 쿼리 명령문으로 변경합니다.
select cust_Id,cust_name fromcustomers where cust_rating<'aa' orcust_rating > 'aa';
특별 참고 사항: 불평등 연산자를 OR 조건으로 변경하면 인덱스를 사용하여 전체 테이블 스캔을 피할 수 있습니다.
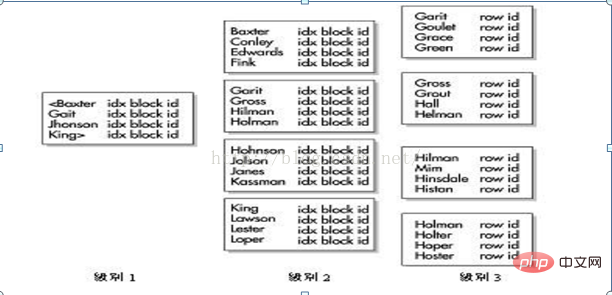
2. IS NULL 또는 IS NOT NULL ISNULL 또는 ISNOT NULL을 사용하면 인덱스 사용도 제한됩니다. NULL 값이 정의되지 않았기 때문입니다. 在 SQL语句中使用NULL会有很多的麻烦。因此建议开发人员在建表时,把需要索引的列设成NOT NULL。如果被索引的列在某些行中存在NULL值,就不会使用这个索引(除非索引是一个位图索引,关于位图索引在稍后在详细讨论)。 3、使用函数 如果不使用基于函数的索引,那么在 SQL语句的 WHERE子句中对存在索引的列使用函数时,会使优化器忽略掉这些索引。 下面的查询不会使用索引(只要它不是基于函数的索引) 把上面的语句改成下面的语句,这样就可以通过索引进行查找。 4、比较不匹配的数据类型 也是比较难于发现的性能问题之一。 注意下面查询的例子,account_number是一个VARCHAR2类型,在 account_number字段上有索引。 下面的语句将执行全表扫描: Oracle 可以自动把 where子句变成to_number(account_number)=990354,这样就限 制了索引的使用,改成下面的查询就可以使用索引: 特别注意: 不匹配的数据类型之间比较会让Oracle自动限制索引的使用,即便对这个查询执行ExplainPlan也不能让您明白为什么做了一次―全表扫描。 5、查询索引 查 询 DBA_INDEXES视 图 可 得 到 表 中 所 有 索 引 的 列表 , 注 意 只 能 通 过USER_INDEXES的方法来检索模式(schema)的索引。访问 USER_IND_COLUMNS视图可得到一个给定表中被索引的特定列。 6、 组合索引 当某个索引包含有多个已索引的列时,称这个索引为组合(concatented)索引。在Oracle9i引入跳跃式扫描的索引访问方法之前,查询只能在有限条件下使用该索引。比如:表 emp 有一个组合索引键,该索引包含了 empno、 ename和 deptno。在Oracle9i之前除非在 where之句中对第一列(empno)指定一个值,否则就不能使用这个索引键进行一次范围扫描。 特别注意:在Oracle9i之前,只有在使用到索引的前导索引时才可以使用组合索引 Oracle提供了大量索引选项。知道在给定条件下使用哪个选项对于一个应用程序的性能来说非常重要。一个错误的选择可能会引发死锁,并导致数据库性能急剧下降或进程终止。而如果做出正确的选择,则可以合理使用资源,使那些已经运行了几个小时甚至几天的进程在几分钟得以完成,下面就将简单的讨论每个索引选项。 在这里讨论如下的索引类型: B树索引(默认类型) 位图索引 HASH索引 索引组织表索引 反转键(reverse key)索引 基于函数的索引 分区索引(本地和全局索引) 位图连接索引 B树索引在Oracle中是一个通用索引。在创建索引时它就是默认的索引类型。B树索引可以是一个列的(简单)索引,也可以是组合/复合(多个列)的索引。B树索引最多可以包括32列。 在下图的例子中,B树索引位于雇员表的last_name列上。这个索引的二元高度为3;接下来,Oracle会穿过两个树枝块(branch block),到达包含有ROWID的树叶块。在每个树枝块中,树枝行包含链中下一个块的ID号。 树叶块包含了索引值、ROWID,以及指向前一个和后一个树叶块的指针。Oracle可以从两个方向遍历这个二叉树。B树索引保存了在索引列上有值的每个数据行的ROWID值。Oracle不会对索引列上包含NULL值的行进行索引。如果索引是多个列的组合索引,而其中列上包含NULL值,这一行就会处于包含NULL值的索引列中,且将被处理为空(视为NULL)
技巧:索引列的值都存储在索引中。因此,可以建立一个组合(复合)索引,这些索引可以直接满足查询,而不用访问表。这就不用从中检索数据,从而减少了I/O量。 B-tree特点: 适合与大量的增、删、改(OLTP) 不能用包含OR操作符的查询; 适合高基数的列(唯一值多) 典型的树状结构; 每个结点都是数据块; 大多都是物理上一层、两层或三层不定,逻辑上三层; 叶子块数据是排序的,从左向右递增; 在分支块和根块中放的是索引的范围; 位图索引 位图索引非常适合于决策支持系统(Decision Support System,DSS)和数据仓库,它们不应该用于通过事务处理应用程序访问的表。它们可以使用较少到中等基数(不同值的数量)的列访问非常大的表。 尽管位图索引最多可达30个列,但通常它们都只用于少量的列。 例如,您的表可能包含一个称为Sex的列,它有两个可能值:男和女。这个基数只为2,如果用户频繁地根据Sex列的值查询该表,这就是位图索引的基列。当一个表内包含了多个位图索引时,您可以体会到位图索引的真正威力。如果有多个可用的位图索引,Oracle就可以合并从每个位图索引得到的结果集,快速删除不必要的数据。 Bitmapt特点: 适合与决策支持系统;做 UPDATE代价非常高 非常适合 OR操作符的查询;基数比较少的时候才能建位图索引; 技巧:对于有较低基数的列需要使用位图索引。性别列就是这样一个例子,它有两个可能值:男或女(基数仅为2)。位图对于低基数(少量的不同值)列来说非常快,这是因为索引的尺寸相对于B树索引来说小了很多。因为这些索引是低基数的 B 树索引,所以非常小,因此您可以经常检索表中超过半数的行,并且仍使用位图索引。 当大多数条目不会向位图添加新的值时,位图索引在批处理(单用户)操作中加载表(插入操作)方面通常要比B树做得好。当多个会话同时向表中插入行时不应该使用位图索引,在大多数事务处理应用程序中都会发生这种情况。 示例 下面来看一个示例表PARTICIPANT,该表包含了来自个人的调查数据。列Age_Code、Income_Level、Education_Level和Marital_Status都包括了各自的位图索引。 下图显示了每个直方图中的数据平衡情况,以及对访问每个位图索引的查询的执行路径。图中的执行路径显示了有多少个位图索引被合并,可以看出性能得到了显著的提高。
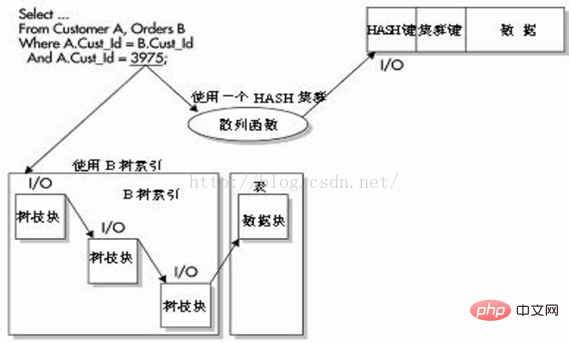
如上图图所示,优化器依次使用4个单独的位图索引,这些索引的列在WHERE子句中被引用。每个位图记录指针(例如0或1),用于示表中的哪些行包含位图中的已知值。有了这些信息后,Oracle就执行BITMAP AND操作以查找将从所有4个位图中返回哪些行。该值然后被转换为ROWID值,并且查询继续完成剩余的处理工作。注意,所有4个列都有非常低的基数,使用索引可以非常快速地返回匹配的行。 技巧:在一个查询中合并多个位图索引后,可以使性能显著提高。位图索引使用固定长度的数据类型要比可变长度的数据类型好。较大尺寸的块也会提高对位图索引的存储和读取性能。 下面的查询可显示索引类型。 B 树索引作为NORMAL列出;而位图索引的类型值为BITMAP。 技巧:如果要查询位图索引列表,可以在USER_INDEXES视图中查询index_type列。 建议不要在一些联机事务处理(OLTP)应用程序中使用位图索引。B树索引的索引值中包含ROWID,这样Oracle就可以在行级别上锁定索引。位图索引存储为压缩的索引值,其中包含了一定范围的ROWID,因此Oracle必须针对一个给定值锁定所有范围内的ROWID 这种锁定类型可能在某些DML语句中造成死锁。SELECT语句不会受到这种锁定问题的影响。 位图索引的使用限制: 基于规则的优化器不会考虑位图索引。 当执行 ALTER TABLE语句并修改包含有位图索引的列时,会使位图索引失效。位图索引不包含任何列数据,并且不能用于任何类型的完整性检查。位图索引不能被声明为唯一索引。位图索引的最大长度为30。 팁: 과도한 OLTP 환경에서는 비트맵 인덱스를 사용하지 마세요. HASH 인덱스를 사용하려면 HASH 클러스터를 사용해야 합니다. 클러스터 또는 HASH 클러스터가 설정되면 클러스터 키도 정의됩니다. 이 키는 Oracle에게 클러스터에 테이블을 저장하는 방법을 알려줍니다. 데이터를 저장할 때 이 클러스터 키와 관련된 모든 행은 데이터베이스 블록에 저장됩니다. 데이터가 모두 동일한 데이터베이스 블록에 저장되고 HASH 인덱스가 WHERE 절에서 정확히 일치하는 항목으로 사용되는 경우 Oracle은 이진 높이를 사용하는 대신 HASH 함수 및 I/O를 수행하여 데이터에 액세스할 수 있습니다. B-트리 인덱스 4를 사용하여 데이터에 액세스하려면 데이터를 검색할 때 4개의 I/O를 사용해야 합니다. 아래 그림과 같이 쿼리는 HASH 컬럼과 정확한 값을 일치시키는 등가 쿼리입니다. Oracle은 이 값을 사용하여 HASH 함수를 기반으로 행의 물리적 저장 위치를 신속하게 결정할 수 있습니다. HASH 인덱스는 데이터베이스의 데이터에 액세스하는 가장 빠른 방법일 수 있지만 그 자체의 단점도 있습니다. HASH 클러스터를 생성하기 전에 클러스터 키의 고유 값 수를 알아야 합니다. HASH 클러스터를 생성할 때 이 값을 지정해야 합니다. 서로 다른 클러스터 키 값의 개수를 과소평가하면 클러스터 충돌(동일한 해시 값을 갖는 두 개의 클러스터 키)이 발생할 수 있습니다. 이런 종류의 갈등은 자원 집약적입니다. 충돌로 인해 추가 행을 저장하는 데 사용되는 버퍼가 오버플로되어 추가 I/O가 발생할 수 있습니다. 다양한 해시 값의 개수가 과소평가된 경우 클러스터를 재구축한 후 이 값을 변경해야 합니다. ALTER CLUSTER 명령은 HASH 키 수를 변경할 수 없습니다. HASH 클러스터는 공간을 낭비할 수도 있습니다. 클러스터 키의 모든 행을 유지하는 데 필요한 공간을 결정할 수 없으면 공간을 낭비할 수 있습니다. 클러스터의 향후 성장을 위해 추가 공간을 할당할 수 없는 경우 HASH 클러스터가 최선의 선택이 아닐 수 있습니다. 애플리케이션이 클러스터링된 테이블에서 전체 테이블 스캔을 자주 수행하는 경우 HASH 클러스터링이 최선의 선택이 아닐 수 있습니다. 전체 테이블 스캔은 향후 성장을 위해 클러스터에 남은 공간을 할당해야 하기 때문에 리소스 집약적일 수 있습니다. HASH 클러스터를 구현하기 전에 주의하세요. 이 옵션을 구현하기 전에 테이블과 데이터에 대해 많은 것을 이해하고 있는지 확인하기 위해 애플리케이션을 철저하게 조사해야 합니다. 일반적으로 HASH는 정렬된 값을 포함하는 일부 정적 데이터에 매우 효과적입니다. 팁: HASH 인덱스는 제한이 있을 때 매우 유용합니다(값 범위가 아닌 특정 값을 지정해야 함)
인덱스 구성 테이블은 테이블의 저장 구조를 B-트리 구조로 변경하고 테이블의 기본 키를 기준으로 정렬합니다. 다른 유형의 테이블과 마찬가지로 이 특수 테이블은 테이블의 모든 DML 및 DDL 문을 실행할 수 있습니다. 테이블의 특수한 구조로 인해 ROWID는 테이블의 행과 연관되지 않습니다. 정확한 일치 및 범위 검색과 관련된 일부 명령문의 경우 인덱스 구성 테이블은 빠른 키 기반 데이터 액세스 메커니즘을 제공합니다. 행이 물리적으로 정렬되므로 기본 키 값을 기반으로 하는 UPDATE 및 DELETE 문의 성능도 향상됩니다. 키 컬럼 값이 테이블과 인덱스에서 반복되지 않기 때문에 저장에 필요한 공간도 줄어듭니다. 기본 키 열에 대해 데이터를 자주 쿼리하지 않는 경우 인덱스 구성 테이블의 다른 열에 보조 인덱스를 생성해야 합니다. 기본 키를 기반으로 테이블을 자주 쿼리하지 않는 애플리케이션은 인덱스를 사용하여 테이블을 구성하는 데 따른 모든 이점을 누릴 수 없습니다. 기본 키의 정확한 일치 또는 범위 스캔을 통해 항상 액세스되는 테이블의 경우 인덱스를 사용하여 테이블을 구성하는 것을 고려하십시오. 팁: 인덱스 구성 테이블에 보조 인덱스를 생성할 수 있습니다. 일부 정렬된 데이터를 로드할 때 인덱스는 확실히 I/O와 관련된 일부 병목 현상을 겪게 됩니다. 데이터를 로드하는 동안 인덱스와 디스크의 일부 부분은 다른 부분보다 훨씬 더 자주 사용됩니다. 이 문제를 해결하기 위해 파일을 여러 디스크에 물리적으로 분할할 수 있는 디스크 아키텍처에 인덱스 테이블스페이스를 저장할 수 있습니다. 이 문제를 해결하기 위해 Oracle은 키 인덱스를 역전시키는 방법도 제공합니다. 데이터가 역방향 키 인덱스로 저장되면 데이터의 값은 원래 저장된 값과 반대가 됩니다. 이런 방식으로 데이터 1234, 1235, 1236이 4321, 5321, 6321로 저장됩니다. 결과적으로 인덱스는 새로 삽입된 각 행에 대해 서로 다른 인덱스 블록을 업데이트합니다. 팁: 디스크 용량이 제한되어 있고 순서대로 많은 로드를 수행하는 경우 역방향 키 인덱싱을 사용할 수 있습니다. 비트맵 인덱스나 인덱스 구성 테이블에는 역키 인덱스를 사용할 수 없습니다. 비트맵 인덱스와 인덱스 구성 테이블은 역방향 키를 사용할 수 없기 때문입니다. 테이블에 함수 기반 인덱스를 만들 수 있습니다. 함수 기반 인덱스가 없으면 열에서 함수를 수행하는 쿼리는 해당 열의 인덱스를 사용할 수 없습니다. 예를 들어 다음 쿼리는 함수 기반 인덱스가 아닌 이상 JOB 열의 인덱스를 사용할 수 없습니다. 下面的查询使用 JOB列上的索引,但是它将不会返回JOB列具有Mgr或mgr值的行: 可以创建这样的索引,允许索引访问支持基于函数的列或数据。可以对列表达式 UPPER(job)创建索引,而不是直接在JOB列上建立索引,如: 能限制在这个列上使用的函数吗?如果能,能限制所有在这个列上执行的所有函数吗?是否有足够应付额外索引的存储空间?在每列上增加的索引数量会对针对该表执行的DML语句的性能带来何种影响? 基于函数的索引非常有用,但在实现时必须小心。在表上创建的索引越多,INSERT、UPDATE和DELETE语句的执行就会花费越多的时间。 注意:对于优化器所使用的基于函数的索引来说,必须把初始参数QUERY_REWRITE _ ENABLED 设定为 TRUE。 示例: 分区索引就是简单地把一个索引分成多个片断。通过把一个索引分成多个片断,可以访问更小的片断(也更快),并且可以把这些片断分别存放在不同的磁盘驱动器上(避免I/O问题)。 B树和位图索引都可以被分区,而HASH索引不可以被分区。可以有好几种分区方法:表被分区而索引未被分区;表未被分区而索引被分区;表和索引都被分区。 不管采用哪种方法,都必须使用基于成本的优化器。分区能够提供更多可以提高性能和可维护性的可能性有两种类型的分区索引:本地分区索引和全局分区索引。 每个类型都有两个子类型,有前缀索引和无前缀索引。表各列上的索引可以有各种类型索引的组合。如果使用了位图索引,就必须是本地索引。 把索引分区最主要的原因是可以减少所需读取的索引的大小,另外把分区放在不同的表空间中可以提高分区的可用性和可靠性。在使用分区后的表和索引时,Oracle还支持并行查询和并行DML。这样就可以同时执行多个进程,从而加快处理这条语句。
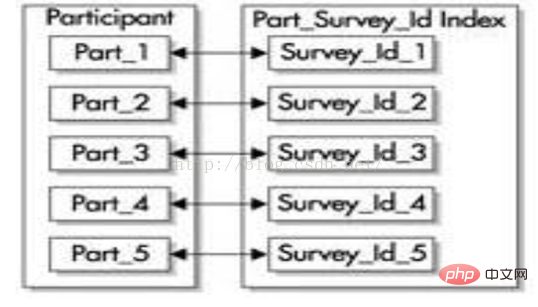
可以使用与表相同的分区键和范围界限来对本地索引分区。每个本地索引的分区只包含了它所关联的表分区的键和ROWID。本地索引可以是B树或位图索引。如果是 B树索引,它可以是唯一或不唯一的索引。 这种类型的索引支持分区独立性,这就意味着对于单独的分区,可以进行增加、截取、删除、分割、脱机等处理,而不用同时删除或重建索引。Oracle自动维护这些本地索引。本地索引分区还可以被单独重建,而其他分区不会受到影响。 (1) 有前缀的索引 有前缀的索引包含了来自分区键的键,并把它们作为索引的前导。例如,让我们再次回顾 participant表。在创建该表后,使用survey_id和survey_date这两个列进行范围分区,然后在survey_id列上建立一个有前缀的本地索引,如下图所示。这个索引的所有分区都被等价划分,就是说索引的分区都使用表的相同范围界限来创建。
技巧:本地的有前缀索引可以让Oracle快速剔除一些不必要的分区。也就是说
(2) Unprefixed 인덱스 Unprefixed 인덱스는 파티션 키의 선행 열을 인덱스의 선행 열로 사용하지 않습니다. 동일한 파티션 키(survey_id 및 Survey_date)를 사용하여 동일한 분할된 테이블을 사용하는 경우 Survey_date 열에 구축된 인덱스는 아래 그림과 같이 접두사가 없는 로컬 인덱스입니다. 접두사가 없는 로컬 인덱스는 테이블의 모든 열에 생성될 수 있지만 인덱스의 각 파티션에는 테이블의 해당 파티션에 대한 키 값만 포함됩니다.
접두사가 없는 인덱스를 고유 인덱스로 설정하려면 이 인덱스에 파티션 키의 하위 집합이 포함되어야 합니다. 팁: 글로벌 인덱스는 B-트리 인덱스만 가능합니다. Oracle은 기본적으로 글로벌 분할 인덱스를 유지하지 않습니다. 파티션이 절단, 추가, 분할, 삭제되는 경우 테이블 수정 시 ALTER TABLE 명령의 UPDATE GLOBAL INDEXES 절을 지정하지 않는 한 글로벌 파티션 인덱스를 다시 작성해야 합니다. (2) 접두사 인덱스 일반적으로 전역 접두사 인덱스는 기본 테이블에서 피어 분할되지 않습니다. 인덱스의 피어 파티셔닝을 제한하는 요소는 없지만 Oracle은 쿼리 계획을 생성하거나 파티션 유지 관리 작업을 수행할 때 피어 파티셔닝을 최대한 활용하지 않습니다. 인덱스가 피어 파티셔닝된 경우에는 아래 그림과 같이 Oracle이 인덱스를 유지하고 이를 사용하여 불필요한 파티션을 제거할 수 있도록 로컬 인덱스로 생성해야 합니다. 이 다이어그램에서 3개의 인덱스 파티션 각각에는 여러 테이블 파티션의 행을 가리키는 인덱스 항목이 포함되어 있습니다.
分区的、全局有前缀索引
( 2) 无前缀的索引
位图连接索引是基于两个表的连接的位图索引,在数据仓库环境中使用这种索引改进连接维度表和事实表的查询的性能。创建位图连接索引时,标准方法是 连接索引中常用的维度表和事实表。当用户在一次查询中结合查询事实表和维度表时,就不需要执行连接,因为在位图连接索引中已经有可用的连接结果。通过压缩位图连接索引中的ROWID进一步改进性能,并且减少访问数据所需的I/O数量。 创建位图连接索引时,指定涉及的两个表。相应的语法应该遵循如下模式: 位图连接的语法比较特别,其中包含 FROM子句和WHERE子句,并且引用两个单独的表。索引列通常是维度表中的描述列——就是说,如果维度是 CUSTOMER,并且它的主键是CUSTOMER_ID,则通常索引Customer_Name 这样的列。如果事实表名为 SALES,可以使用如下的命令创建索引: 如果用户接下来使用指定 Customer_Name列值的WHERE子句查询 SALES和CUSTOMER表,优化器就可以使用位图连接索引快速返回匹配连接 条件和 Customer_Name条件的行。 位图连接索引的使用一般会受到限制: 1) 只可以索引维度表中的列。 2) 用于连接的列必须是维度表中的主键或唯一约束;如果是复合主键,则 必须使用连接中的每一列。 3) 不可以对索引组织表创建位图连接索引,并且适用于常规位图索引的限 制也适用于位图连接索引。
注意:以上总结是对oracle数据库中索引创建的一些知识的介绍和关键点。需要读懂理解之后结合系统业务情况合理创建索引,以求达到预期性能。 本文部分内容摘自《Oracle超详细讲解.pdf》 推荐教程:《Oracle教程》select empno,ename,deptno from emp where trunc(hiredate)='01-MAY-81';
select empno,ename,deptno from emp where hiredate<(to_date('01-MAY-81')+0.9999);
select bank_name,address,city,state,zip from banks whereaccount_number = 990354;
select bank_name,address,city,state,zip from banks where account_number='990354';
索引分类
B树索引 (默认类型)

SQL> select index_name, index_type from user_indexes;
INDEX_NAME INDEX_TYPE
------------------------------ ----------------------
TT_INDEX NORMAL
IX_CUSTADDR_TP NORMAL
HASH 인덱스
인덱스 구성 테이블
Inverted Key Index
숫자 기반 인덱스
select * from emp where UPPER(job) = 'MGR';
select * from emp where job = 'MGR';
create index EMP$UPPER_JOB on emp(UPPER(job));尽管基于函数的索引非常有用,但在建立它们之前必须先考虑下面一些问题:
select count(*) from sample where ratio(balance,limit) >.5;
Elapsed time: 20.1 minutes
create index ratio_idx1 on sample (ratio(balance, limit));
select count(*) from sample where ratio(balance,limit) >.5;
Elapsed time: 7 seconds!!!
分区索引
本地分区索引(通常使用的索引)
没有包含 WHERE条件子句中任何值的分区将不会被访问,这样也提高了语句
的性能。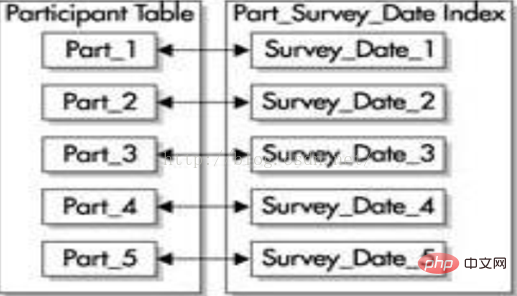
이 예에서는 survey 및 ( 또는 )이 포함된 열을 결합해야 합니다. 한만큼
survey_id은 인덱스의 첫 번째 열이 아니며 접두사 )이 있는 인덱스입니다.
技巧:如果一个全局索引将被对等分区,就必须把它创建为一个本地索引,
这样 Oracle可以维护这个索引,并使用它来删除不必要的分区。
Oracle不支持无前缀的全局索引。位图连接索引
create bitmap index FACT_DIM_COL_IDX on FACT(DIM.Descr_Col) from
FACT, DIM where FACT.JoinCol = DIM.JoinCol;
create bitmap index SALES_CUST_NAME_IDX
on SALES(CUSTOMER.Customer_Name) from SALES, CUSTOMER
where SALES.Customer_ID=CUSTOMER.Customer_ID;
위 내용은 Oracle에서 인덱스 생성 및 사용(요약 공유)의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!