
집 >데이터 베이스 >MySQL 튜토리얼 >mysql 저장 프로시저를 이해하는 데 10분 정도 소요됩니다.
mysql 저장 프로시저를 이해하는 데 10분 정도 소요됩니다.

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWB앞으로
- 2021-12-31 18:35:1312958검색
이 글은 mysql 저장 프로시저를 배울 때 제가 기록한 내용을 여러분께 공유할 것입니다. mysql 저장 프로시저에 대한 관련 지식을 자세하게 소개하는 내용이 모든 분들께 도움이 되기를 바랍니다.

1. 정의
저장 프로시저(Stored Procedure)는 대규모 데이터베이스 시스템에서 특정 기능을 완료하는 데 사용되는 SQL 문 집합으로 처음 컴파일된 후 데이터베이스에 저장됩니다. 컴파일하기 위해 사용자는 이름을 지정하고 매개변수(저장 프로시저에 매개변수가 있는 경우)를 제공하여 저장 프로시저를 실행합니다. 저장 프로시저는 데이터베이스에서 중요한 개체입니다.
2. 저장 프로시저의 특징
1. 더 복잡한 판단과 연산을 완료할 수 있음
2. 프로그래밍 가능하고 유연함
3. SQL 프로그래밍 코드를 재사용할 수 있음
4. 실행 속도가 상대적으로 빠름
5 , 데이터 간 데이터 전송 감소
3. 간단한 저장 프로시저 생성
1. 저장 프로시저 생성을 위한 간단한 구문
create procedure 名称() begin ......... end
2. 간단한 저장 프로시저 생성
create procedure testa()
begin
select * from users;
select * from orders;
end;3. 저장 프로시저 호출
call testa();
작업 결과는 다음과 같습니다. 그림 (1) 및 그림 (2)와 같이: > ~ 그림 (2)
4. 저장 프로시저의 변수 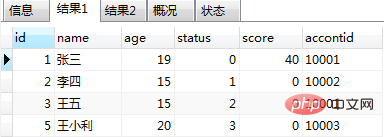
create procedure test2() begin -- 使用 declare语句声明一个变量 declare username varchar(32) default ''; -- 使用set语句给变量赋值 set username='xiaoxiao'; -- 将users表中id=1的名称赋值给username select name into username from users where id=1; -- 返回变量 select username; end;2. 요약
(1) 선언을 사용하여 변수를 선언합니다. 변수는 하나만 선언하고 변수를 먼저 선언한 다음 사용해야 합니다. 
(4) 변수를 반환해야 하는 경우 select 변수 이름과 같은 select 문을 사용할 수 있습니다. 량 량 5. 변수의 역할
1. 변수 범위 설명:
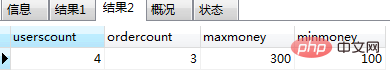
(1) 저장 프로시저의 변수는 기능적 범위입니다. ㅋㅋㅋ . 예제를 통해 변수의 범위를 확인하세요 요구 사항: 사용자 및 주문 테이블의 행 수와 주문 테이블의 최대 및 최소 금액을 계산하는 저장 프로시저를 생성하세요.create procedure test3()
begin
begin
declare userscount int default 0; -- 用户表中的数量
declare ordercount int default 0; -- 订单表中的数量
select count(*) into userscount from users;
select count(*) into ordercount from orders;
select userscount,ordercount; -- 返回用户表中的数量、订单表中的数量
end;
begin
declare maxmoney int default 0; -- 最大金额
declare minmoney int default 0; -- 最小金额
select max(money) into maxmoney from orders;
select min(money) into minmoney from orders;
select maxmoney,minmoney; -- 返回最金额、最小金额
end;
end;위 저장 프로시저를 호출하세요. 결과는 그림 (3) 및 그림 (4)와 같습니다. 3. 프로시저 test(3)를 다음과 같이 변경했습니다.
create 프로시저 test3()
start
start
사용자의 userscount로 count(*)를 선택합니다.
주문의 주문 개수로 count(*)를 선택합니다. ; int 기본값 0; -- 최소 금액
select min(money) into minmoney from orders;
select userscount,ordercount,maxmoney,minmoney; -- 返回最金额、最小金额
end;
end;
再次调用call test3(); 会报错如图(5):
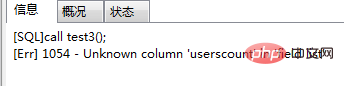
图(5)
4、将userscount,ordercount改为全局变量,再次验证
create procedure test3()
begin
declare userscount int default 0; -- 用户表中的数量
declare ordercount int default 0; -- 订单表中的数量
begin
select count(*) into userscount from users;
select count(*) into ordercount from orders;
select userscount,ordercount; -- 返回用户表中的数量、订单表中的数量
end;
begin
declare maxmoney int default 0; -- 最大金额
declare minmoney int default 0; -- 最小金额
select max(money) into maxmoney from orders;
select min(money) into minmoney from orders;
select userscount,ordercount,maxmoney,minmoney; -- 返回最金额、最小金额
end;
end;
再次调用call test3(); 会报错如图(6)和图(7):

图(6)
图(7)
因此,存储过程中变量的作用域,作用范围在begin和end块之间,end结束变量的作用范围即结束
六、存储过程参数
1、基本语法
create procedure 名称([IN|OUT|INOUT] 参数名 参数数据类型 ) begin ......... end
存储过程的参数类型有:IN,OUT,INOUT,下面分别介绍这个三种类型:
2、存储过程的传出参数IN
说明:
(1)、传入参数:类型为in,表示该参数的值必须在调用存储过程事指定,如果不显示指定为in,那么默认就是in类型。
(2)、IN类型参数一般只用于传入,在调用过程中一般不作为修改和返回
(3)、如果调用存储过程中需要修改和返回值,可以使用OUT类型参数
通过一个实例来演示:
需求:编写存储过程,传入id,根据id返回name
create procedure test4(userId int)
begin
declare username varchar(32) default '';
declare ordercount int default 0;
select name into username from users where id=userId;
select username;
end;运行如图(8)
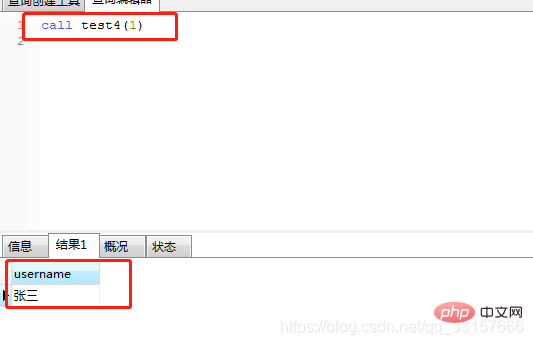
图(8)
3、存储过程的传出参数out
需求:调用存储过程时,传入userId返回该用户的name
create procedure test5(in userId int,out username varchar(32))
begin
select name into username from users where id=userId;
end;
调用及运行结果如图(9):
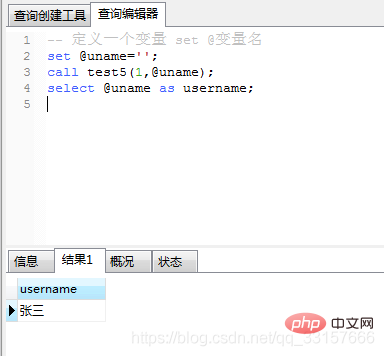
图(9)
概括:
1、传出参数:在调用存储过程中,可以改变其值,并可返回;
2、out是传出参数,不能用于传入参数值;
3、调用存储过程时,out参数也需要指定,但必须是变量,不能是常量;
4、如果既需要传入,同时又需要传出,则可以使用INOUT类型参数
(3).存储过程的可变参数INOUT
需求:调用存储过程时,传入userId和userName,即使传入,也是传出参数。
create procedure test6(inout userId int,inout username varchar(32))
begin
set userId=2;
set username='';
select id,name into userId,username from users where id=userId;
end;调用及运行结果如图(10)
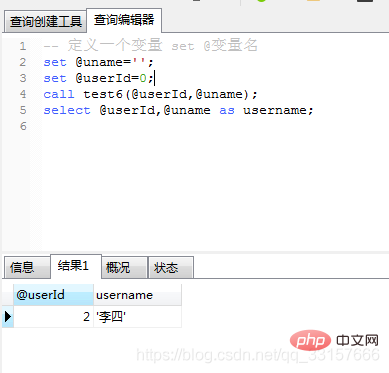
图(10)
概括:
1、可变变量INOUT:调用时可传入值,在调用过程中,可修改其值,同时也可返回值;
2、INOUT参数集合了IN和OUT类型的参数功能;
3、INOUT调用时传入的是变量,而不是常量;
七、存储过程条件语句
1、基本结构
(1)、条件语句基本结构:
if() then...else...end if;
(2)、多条件判断语句:
if() then... elseif() then... else ... end if;
2、实例
实例1:编写存储过程,如果用户userId是偶数则返回username,否则返回userId
create procedure test7(in userId int)
begin
declare username varchar(32) default '';
if(userId%2=0)
then
select name into username from users where id=userId;
select username;
else
select userId;
end if;
end;调用及运行结果如图(11)和图(12):
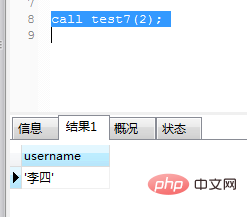
图(11)

图(12)
2、存储过程的多条件语句应用示例
需求:根据用户传入的uid参数判断
(1)、如果用户状态status为1,则给用户score加10分;
(2)、 如果用户状态status为2,则给用户score加20分;
(3)、 其他情况加30分
create procedure test8(in userid int)
begin
declare my_status int default 0;
select status into my_status from users where id=userid;
if(my_status=1)
then
update users set score=score+10 where id=userid;
elseif(my_status=2)
then
update users set score=score+20 where id=userid;
else
update users set score=score+30 where id=userid;
end if;
end;调用程之前的users表的数据如图(13),调用 call test8(1); 及运行结果图(14):
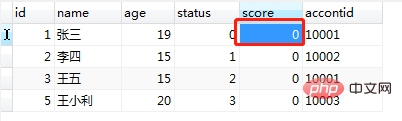
图(13)
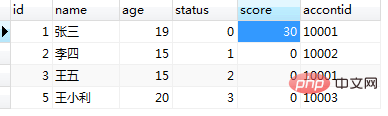
图(14)
八、存储过程循环语句
1、while语句
(1)、while语句的基本结构
while(表达式) do ...... end while;
(2)、示例
需求:使用循环语句,向表test1(id)中插入10条连续的记录
create procedure test9()
begin
declare i int default 0;
while(i<10) do
begin
select i;
set i=i+1;
insert into test1(id) values(i);
end;
end while;
end;调用及运行结果结果如图(15)和图(16):

图(15)
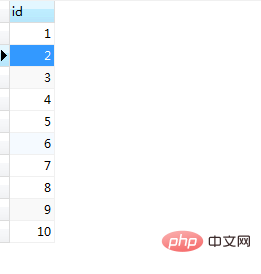
图(16)
2、repeat语句
(1)、repeat语句基本的结构:
repeat...until...end repeat;
(2)、示例
需求:给test1表中的id字段插入数据,从1到10
create procedure test10()
begin
declare i int default 0;
repeat
begin
select i;
set i=i+1;
insert into test1(id) values(i);
end;
until i>=10 -- 如果i>=10,则跳出循环
end repeat;
end;调用及运行结果结果如图(17)和图(18)
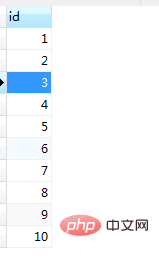
图(17)

图(18)
概括:
until判断返回逻辑真或者假,表达式可以是任意返回真或者假的表达式,只有当until语句为真是,循环结束。
九、存储过程游标的使用
1、什么是游标
游标是保存查询结果的临时区域
2、示例
需求:编写存储过程,使用游标,把users表中 id为偶数的记录逐一更新用户名
create procedure test11()
begin
declare stopflag int default 0;
declare username VARCHAR(32);
-- 创建一个游标变量,declare 变量名 cursor ...
declare username_cur cursor for select name from users where id%2=0;
-- 游标是保存查询结果的临时区域
-- 游标变量username_cur保存了查询的临时结果,实际上就是结果集
-- 当游标变量中保存的结果都查询一遍(遍历),到达结尾,将变量stopflag设置为1,用于循环中判断是否结束
declare continue handler for not found set stopflag=1;
open username_cur; -- 打卡游标
fetch username_cur into username; -- 游标向前走一步,取出一条记录放到变量username中
while(stopflag=0) do -- 如果游标还没有结尾,就继续
begin
-- 在用户名前门拼接 '_cur' 字符串
update users set name=CONCAT(username,'_cur') where name=username;
fetch username_cur into username;
end;
end while; -- 结束循环
close username_cur; -- 关闭游标
end;调用结果如图(19):
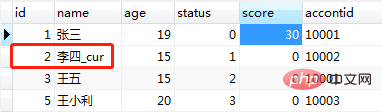
图(19)
十、自定义函数
函数与存储过程最大的区别是函数必须有返回值,否则会报错
1、一个简单的函数
create function getusername(userid int) returns varchar(32)
reads sql data -- 从数据库中读取数据,但不修改数据
begin
declare username varchar(32) default '';
select name into username from users where id=userid;
return username;
end;调用及运行结果如图(20):

图(20)
概括:
1.创建函数使用create function 函数名(参数) returns 返回类型;
2.函数体放在begin和end之间;
3.returns指定函数的返回值;
4.函数调用使用select getusername()。
2、示例
需求:根据userid,获取accoutid,id,name组合成UUID作为用户的唯一标识
create function getuuid(userid int) returns varchar(64)
reads sql data -- 从数据库中读取数据,但不修改数据
begin
declare uuid varchar(64) default '';
select concat(accontid,'_',id,'_',name) into uuid from users where id=userid;
return uuid;
end;调用及运行结果如图(21)
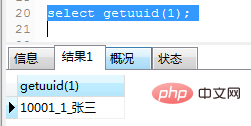
图(21)
十一、触发器
1、什么是触发器
触发器与函数、存储过程一样,触发器是一种对象,它能根据对表的操作时间,触发一些动作,这些动作可以是insert,update,delete等修改操作。
2、示例1
(1)、需求:出于审计目的,当有人往表users插入一条记录时,把插入的userid,username,插入动作和操作时间记录下来。
create trigger tr_users_insert after insert on users
for each row
begin
insert into oplog(userid,username,action,optime)
values(NEW.id,NEW.name,'insert',now());
end; 创建成功后,给uses表中插入一条记录:
insert into users(id,name,age,status,score,accontid)
values(6,'小周',23,1,'60','10001'); 执行成功后,打开oplog表,可以看到oplog表中插入了一条记录如图(22)

图(22)
(2)、总结
1、创建触发器使用create trigger 触发器名
2、什么时候触发?after insert on users,除了after还有before,是在对表操作之前(before)或者之后(after)触发动作的。
3、对什么操作事件触发? after insert on users,操作事件包括insert,update,delete等修改操作;
4、对什么表触发? after insert on users
5、影响的范围?for each row
3、示例2
需求:出于审计目的,当删除users表时,记录删除前该记录的主要字段值
create trigger tr_users_delete before delete on users
for each row
begin
insert into oplog(userid,username,action,optime)
values(OLD.id,OLD.name,'delete',now());
end; 删除users表中的一条记录
delete from users where id=6;
执行成功后,打开oplog表,可以看到oplog表中插入了一条记录如图(23)
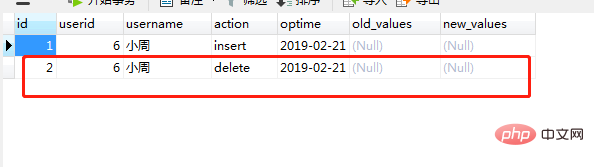
图(23)
十二、流程控制
1、case分支
(1)、基本语法结构
case ... when ... then.... when.... then.... else ... end case;
(2)、示例
users表中,根据userid获取status值,如果status为1,则修改score为10;如果status为2,则修改为20,如果status3,则修改为30;否则修改为40。
create procedure testcate(userid int)
begin
declare my_status int default 0;
select status into my_status from users where id=userid;
case my_status
when 1 then update users set score=10 where id=userid;
when 2 then update users set score=20 where id=userid;
when 3 then update users set score=30 where id=userid;
else update users set score=40 where id=userid;
end case;
end;调用过程 call testcate(1); ,执行结果如图(24);
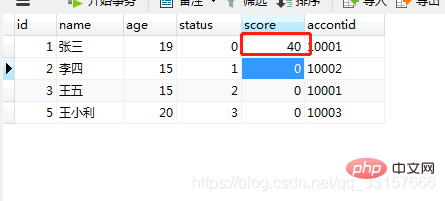
图(24)
十四、存储过程+event(事件)
1、使用存储过程+事件事件一个简单的实现福彩3D开奖
需求:设计一个福彩的开奖过程,没3分钟开奖一次
第一步:先编写一个存储过程open_lottery,产生3个随机数,生成一条开奖记录
第二步:编写一个时间调度器,每3分钟调用一次这个过程
create procedure open_lottery()
begin
insert into lottery(num1,num2,num3,ctime)
select FLOOR(rand()*9)+1,FLOOR(rand()*9)+1,FLOOR(rand()*9)+1,now();
end;create event if not exists lottery_event -- 创建一个事件
on schedule every 3 minute -- on schedule 什么时候来执行,没三分钟执行一次
on completion preserve
do call open_lottery;运行结果如图(25)
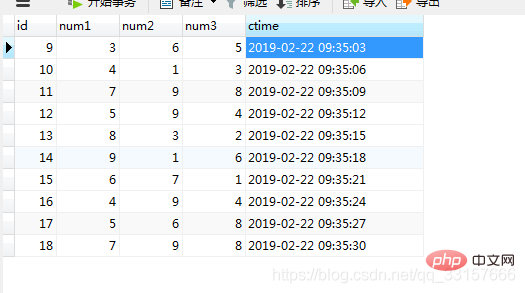
图(25)
注意,如果event之一没有运行,请按照以下办法解决:
(1)、 show variables like '%event_scheduler%';
set global event_scheduler=on;
(2)、 alert event lottery_event enable;
2、解析event的创建格式
(1)、基本语法
create event[IF NOT EXISTS]event_name -- 创建使用create event
ON SCHEDULE schedule -- on schedule 什么时候来执行
[ON COMPLETION [NOT] PRESERVE] -- 调度计划执行完成后是否还保留
[ENABLE | DISABLE] -- 是否开启事件,默认开启
[COMMENT 'comment'] -- 事件的注释
DO sql_statement; -- 这个调度计划要做什么?(2)、执行时间说明
1.单次计划任务示例
在2019年2月1日4点执行一次
on schedule at '2019-02-01 04:00:00'
2. 重复计划执行
on schedule every 1 second 每秒执行一次
on schedule every 1 minute 每分钟执行一次
on schedule every 1 day 没天执行一次
3.指定时间范围的重复计划任务
每天在20:00:00执行一次
on schedule every 1 day starts '2019-02-01 20:00:00'
十五、本文所用到的表
1、lottery表
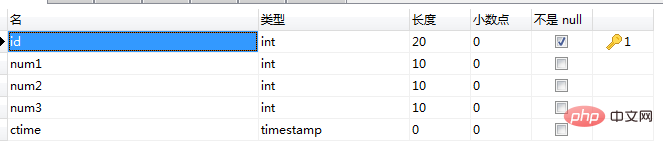
2、oplog表
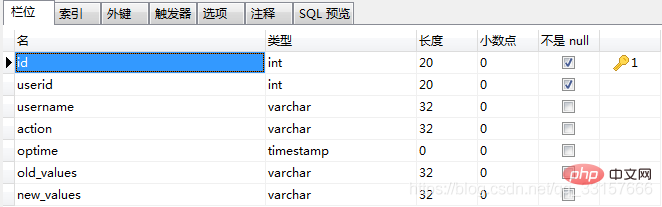
3、orders表
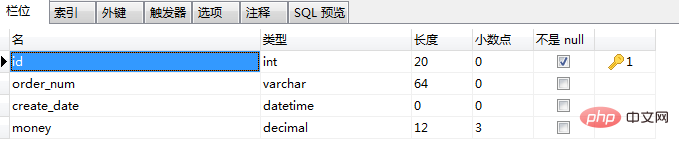
4、test1表

5、user表
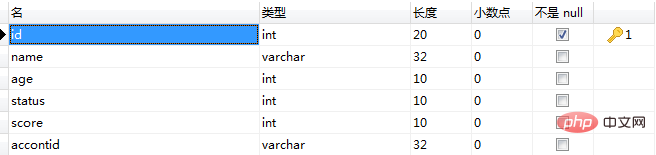
推荐学习:mysql视频教程
위 내용은 mysql 저장 프로시저를 이해하는 데 10분 정도 소요됩니다.의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!