
집 >데이터 베이스 >MySQL 튜토리얼 >MySQL의 조인문 알고리즘과 최적화 방법에 대한 심층적인 이해
MySQL의 조인문 알고리즘과 최적화 방법에 대한 심층적인 이해

- 青灯夜游앞으로
- 2021-08-27 18:59:212449검색
이 글에서는 MySQL의 조인문 알고리즘을 소개하고, 조인문을 최적화하는 방법을 소개합니다.

1. Join 문 알고리즘
t1과 t2라는 두 개의 테이블을 생성합니다.
CREATE TABLE `t2` (
`id` int(11) NOT NULL,
`a` int(11) DEFAULT NULL,
`b` int(11) DEFAULT NULL,
PRIMARY KEY (`id`),
KEY `a` (`a`)
) ENGINE=InnoDB;
CREATE DEFINER=`root`@`%` PROCEDURE `idata`()
BEGIN
declare i int;
set i=1;
while(i<=1000)do
insert into t2 values(i, i, i);
set i=i+1;
end while;
END
create table t1 like t2;
insert into t1 (select * from t2 where id<=100);두 테이블 모두 기본 키 인덱스 id와 인덱스 a를 가지며, b 필드에는 인덱스가 없습니다. 저장 프로시저 idata()는 테이블 t2에 1000행의 데이터를 삽입하고, 테이블 t1
1에 100행의 데이터를 삽입했습니다. Index Nested-Loop Join
select * from t1 straight_join t2 on (t1.a=t2.a);
조인 문을 직접 사용하면 MySQL 최적화 프로그램이 테이블 t1 또는 t2를 구동 테이블로 선택하고 Straight_join을 사용하여 MySQL이 고정 연결 방법을 사용하여 쿼리를 실행하도록 합니다. 이 명령문에서 t1은 구동 테이블이고 t2는 구동 테이블 t2에 필드 인덱스가 있습니다. a. 조인 프로세스는 이 인덱스를 사용하므로 이 명령문의 실행 흐름은 다음과 같습니다.
1. 테이블 t1에서 데이터 R의 행을 읽습니다. 
2. 데이터 행 R에서 a 필드를 테이블로 가져옵니다. t2 Search
3 테이블 t2의 조건을 충족하는 행을 꺼내서 R을 결과 집합의 일부로 구성합니다
4. 루프가 테이블 t1
에서 끝날 때까지 1~3단계를 반복합니다. 이 프로세스를 사용할 수 있습니다. 드라이버 테이블의 인덱스는 Index Nested-Loop Join 또는 줄여서 NLJ라고 합니다.
이 프로세스에서는:
1 드라이버 테이블 t1의 전체 테이블 스캔이 수행됩니다. 100행 스캔
2. R의 각 행에 대해 트리 검색 프로세스를 사용하여 a 필드를 기반으로 테이블 t2에서 검색합니다. 우리가 구성하는 데이터는 일대일 대응이므로 각 검색 프로세스는 하나의 행만 스캔하고 총 100개의 행을 스캔합니다
3 따라서 전체 실행 프로세스에서 스캔되는 총 행 수는 200
입니다.조인이 사용되지 않는다고 가정하면 단일 테이블로만 쿼리할 수 있습니다.
1. 테이블 t1의 모든 데이터를 찾으려면 select * from t1을 실행하세요
. 2. 다음 100개 데이터 행을 반복합니다.
select * from t1,查出表t1的所有数据,这里有100行
2.循环遍历这100行数据:
- 从每一行R取出字段a的值$R.a
- 执行
select * from t2 where a=$R.a각 행에서 $R.a 필드의 값을 가져옵니다. R - 실행
select * from t2 where a=$R.a
이 쿼리 프로세스도 200개의 행을 스캔했지만 총 101개의 문을 실행했습니다. 이는 직접 조인보다 100번 더 많은 상호 작용입니다. 또한 클라이언트는 SQL 문과 결과를 자체적으로 연결해야 합니다. 이것은 직접 조인하는 것만큼 좋지 않습니다
- 주도 테이블의 인덱스를 사용할 수 있는 경우:
- 조인 문을 사용하면 강제로 여러 개의 단일 테이블로 분할하여 SQL을 실행하는 것보다 성능이 좋습니다. 문
2. Simple Nested-Loop Join
select * from t1 straight_join t2 on (t1.a=t2.b);
테이블 t2의 필드 b에는 인덱스가 없으므로 전체 테이블 스캔을 위해 t2로 갈 때마다 이를 수행해야 합니다. 이 알고리즘을 단순 중첩 루프 조인이라고 합니다
이런 방식으로 계산하면 이 SQL 요청은 테이블 t2를 최대 100회 스캔하여 총 100*100=100,000개 행을 스캔합니다.
MySQL은 이 단순 중첩 루프 조인을 사용하지 않습니다. 하지만 BNL
3이라고 하는 Block Nested-Loop Join이라는 또 다른 알고리즘을 사용합니다. Block Nested-Loop Join제어 테이블에는 사용 가능한 인덱스가 없습니다.
1. 테이블 넣기 t1의 데이터를 스레드 메모리 Join_buffer로 읽습니다. 이 명령문은 select *로 작성되었으므로 테이블 t1 전체가 메모리에 넣습니다
2. table t2, Join_buffer 안의 데이터를 비교하여 조인 조건에 맞는 데이터를 결과 세트로 반환합니다. 이 과정에서 테이블 t1과 테이블 t2 모두에 대해 전체 테이블 스캔이 수행되므로 스캔된 전체 행은 번호는 1100입니다. Join_buffer는 순서가 없는 배열로 구성되어 있으므로 테이블 t2의 각 행에 대해 100번의 판단이 이루어져야 합니다. 메모리에서 이루어져야 하는 총 판단 횟수는 100*1000=100,000번입니다
1) 테이블 t1을 스캔하고 데이터 행을 순차적으로 읽어 Join_buffer에 넣습니다. 88번째 줄
2)扫描表t2,把t2中的每一行取出来,跟join_buffer中的数据做对比,满足join条件的,作为结果集的一部分返回
3)清空join_buffer
4)继续扫描表t1,顺序读取最后的12行放入join_buffer中,继续执行第2步
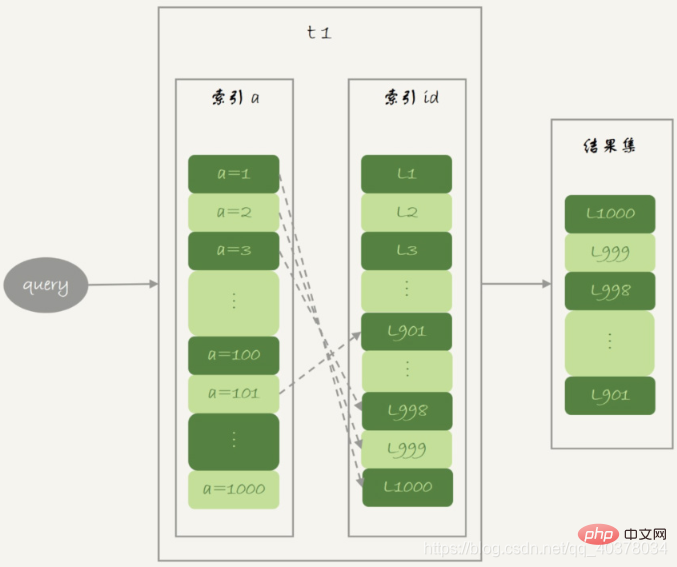
由于表t1被分成了两次放入join_buffer中,导致表t2会被扫描两次。虽然分成两次放入join_buffer,但是判断等值条件的此时还是不变的
4、能不能使用join语句?
1.如果可以使用Index Nested-Loop Join算法,也就是说可以用上被驱动表上的索引,其实是没问题的
2.如果使用Block Nested-Loop Join算法,扫描行数就会过多。尤其是在大表上的join操作,这样可能要扫描被驱动表很多次,会占用大量的系统资源。所以这种join尽量不要用
5、如果使用join,应该选择大表做驱动表还是选择小表做驱动表
1.如果是Index Nested-Loop Join算法,应该选择小表做驱动表
2.如果是Block Nested-Loop Join算法:
- 在join_buffer_size足够大的时候,是一样的
- 在join_buffer_size不够大的时候,应该选择小表做驱动表
在决定哪个表做驱动表的时候,应该是两个表按照各自的条件过滤,过滤完成以后,计算参数join的各个字段的总数据量,数据量小的那个表,就是小表,应该作为驱动表
二、join语句优化
创建两个表t1、t2
create table t1(id int primary key, a int, b int, index(a));create table t2 like t1;CREATE DEFINER = CURRENT_USER PROCEDURE `idata`()BEGIN
declare i int;
set i=1;
while(i<=1000)do
insert into t1 values(i, 1001-i, i);
set i=i+1;
end while;
set i=1;
while(i<=1000000)do
insert into t2 values(i, i, i);
set i=i+1;
end while;END;在表t1中,插入了1000行数据,每一行的a=1001-id的值。也就是说,表t1中字段a是逆序的。同时,在表t2中插入了100万行数据
1、Multi-Range Read优化
Multi-Range Read(MRR)优化主要的目的是尽量使用顺序读盘
select * from t1 where a>=1 and a<=100;
主键索引是一棵B+树,在这棵树上,每次只能根据一个主键id查到一行数据。因此,回表是一行行搜索主键索引的
如果随着a的值递增顺序查找的话,id的值就变成随机的,那么就会出现随机访问,性能相对较差
因为大多数的数据都是按照主键递增顺序插入得到的,所以如果按照主键的递增顺序查询,对磁盘的读比较接近顺序读,能够提升读性能
这就是MRR优化的设计思路,语句的执行流程如下:
1.根据索引a,定位到满足条件的记录,将id值放入read_rnd_buffer中
2.将read_rnd_buffer中的id进行递增排序
3.排序后的id数组,依次到主键id索引中查记录,并作为结果返回
read_rnd_buffer的大小是由read_rnd_buffer_size参数控制的。如果步骤1中,read_rnd_buffer放满了,就会先执行完步骤2和3,然后清空read_rnd_buffer。之后继续找索引a的下个记录,并继续循环
如果想要稳定地使用MRR优化的话,需要设置set optimizer_switch="mrr_cost_based=off"
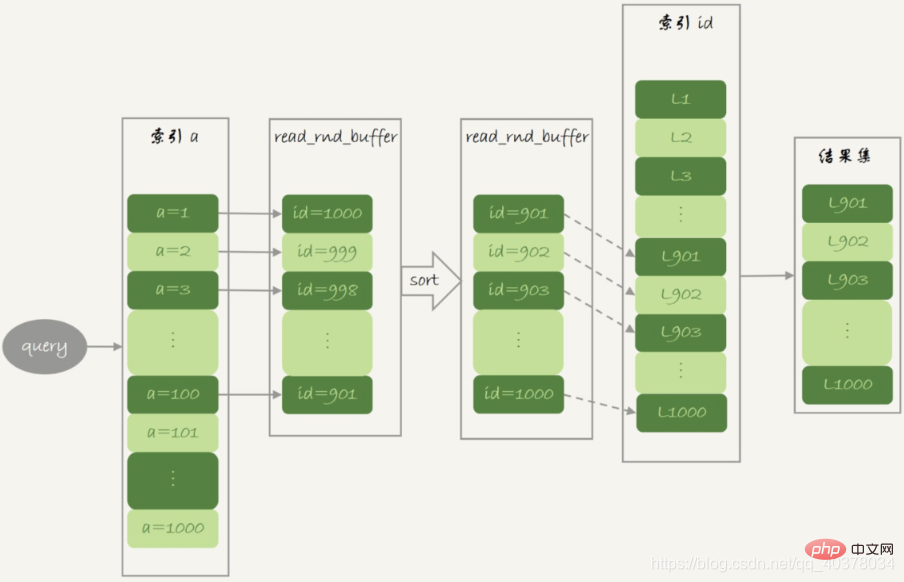

explain结果中,Extra字段多了Using MRR,表示的是用上了MRR优化。由于在read_rnd_buffer中按照id做了排序,所以最后得到的结果也是按照主键id递增顺序的
MRR能够提升性能的核心在于,这条查询语句在索引a上做的是一个范围查询,可以得到足够多的主键id。这样通过排序以后,再去主键索引查数据,才能体现出顺序性的优势
2、Batched Key Access
MySQL5.6引入了Batched Key Access(BKA)算法。这个BKA算法是对NLJ算法的优化
NLJ算法流程图:
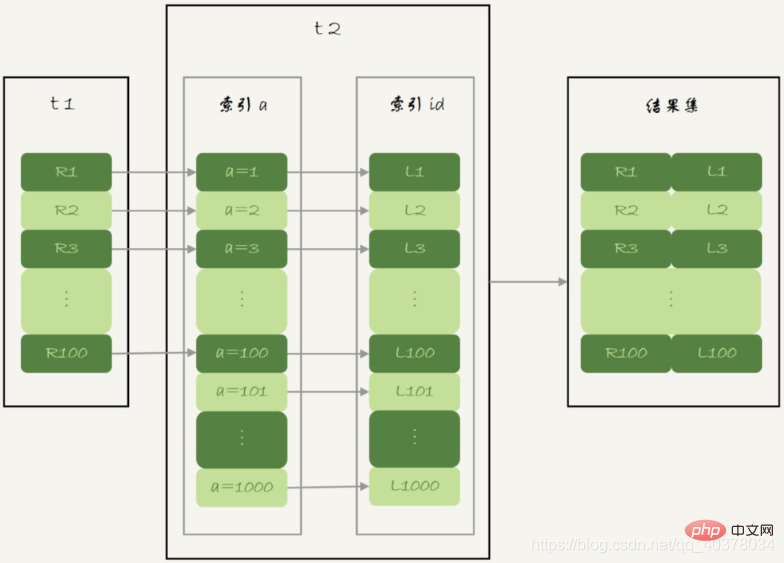
NLJ算法执行的逻辑是从驱动表t1,一行行地取出a的值,再到被驱动表t2去做join
BKA算法流程图:
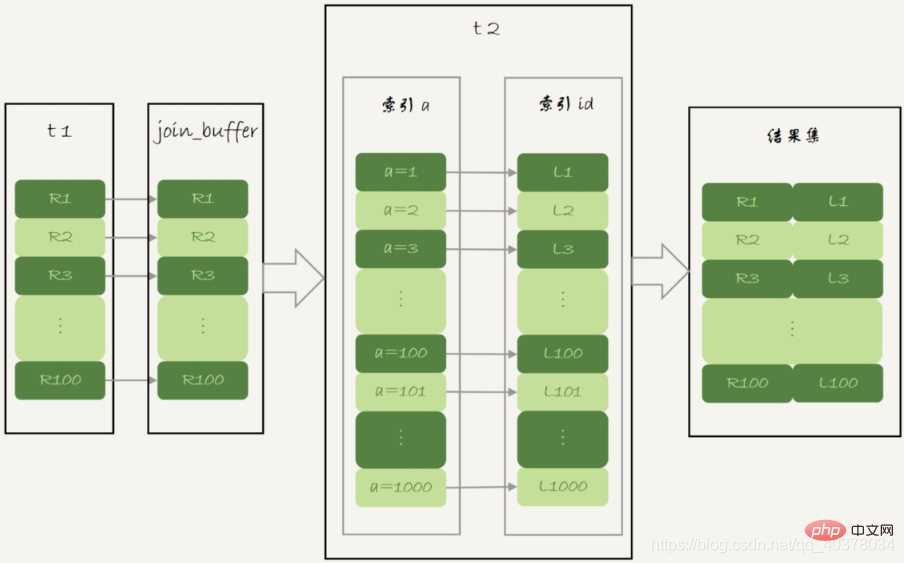
BKA算法执行的逻辑是把表t1的数据取出来一部分,先放到一个join_buffer,一起传给表t2。在join_buffer中只会放入查询需要的字段,如果join_buffer放不下所有数据,就会将数据分成多段执行上图的流程
如果想要使用BKA优化算法的话,执行SQL语句之前,先设置
set optimizer_switch='mrr=on,mrr_cost_based=off,batched_key_access=on';
其中前两个参数的作用是启用MRR,原因是BKA算法的优化要依赖与MRR
3、BNL算法的性能问题
InnoDB对Buffer Pool的LRU算法做了优化,即:第一次从磁盘读入内存的数据页,会先放在old区域。如果1秒之后这个数据页不再被访问了,就不会被移动到LRU链表头部,这样对Buffer Pool的命中率影响就不大
如果一个使用BNL算法的join语句,多次扫描一个冷表,而且这个语句执行时间超过1秒,就会在再次扫描冷表的时候,把冷表的数据页移到LRU链表头部。这种情况对应的,是冷表的数据量小于整个Buffer Pool的3/8,能够完全放入old区域的情况
如果这个冷表很大,就会出现另外一种情况:业务正常访问的数据页,没有机会进入young区域。
由于优化机制的存在,一个正常访问的数据页,要进入young区域,需要隔1秒后再次被访问到。但是,由于join语句在循环读磁盘和淘汰内存页,进入old区域的数据页,很可能在1秒之内就被淘汰了。这样就会导致MySQL实例的Buffer Pool在这段时间内,young区域的数据页没有被合理地淘汰

4、BNL转BKA
一些情况下,我们可以直接在被驱动表上建索引,这时就可以直接转成BKA算法了
如果碰到一些不适合在被驱动表上建索引的情况,可以考虑使用临时表。大致思路如下:
select * from t1 join t2 on (t1.b=t2.b) where t2.b>=1 and t2.b<=2000;
1)把表t2中满足条件的数据放在临时表tmp_t中
2)为了让join使用BKA算法,给临时表tmp_t的字段b加上索引
3)让表t1和tmp_t做join操作
SQL语句写法如下:
create temporary table temp_t(id int primary key, a int, b int, index(b))engine=innodb; insert into temp_t select * from t2 where b>=1 and b<=2000; select * from t1 join temp_t on (t1.b=temp_t.b);
5、扩展hash join
MySQL的优化器和执行器不支持哈希join,可以自己实现在业务端,实现流程大致如下:
1.select * from t1;取得表t1的全部1000行数据,在业务端存入一个hash结构
2.select * from t2 where b>=1 and b获取表t2中满足条件的2000行数据
3.把这2000行数据,一行一行地取到业务端,到hash结构的数据表中寻找匹配的数据。满足匹配的条件的这行数据,就作为结果集的一行
相关学习推荐:mysql教程(视频)
위 내용은 MySQL의 조인문 알고리즘과 최적화 방법에 대한 심층적인 이해의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!