
집 >데이터 베이스 >MySQL 튜토리얼 >예제를 사용하여 SQL을 최적화하는 방법을 알려줍니다.
예제를 사용하여 SQL을 최적화하는 방법을 알려줍니다.

- 醉折花枝作酒筹앞으로
- 2021-08-04 09:26:361650검색
요즈음 하드웨어 비용이 떨어졌지만, 하드웨어를 업그레이드하여 시스템 성능을 향상시키는 것도 일반적인 최적화 방법입니다. 실시간 요구 사항이 높은 시스템은 여전히 SQL 측면에서 최적화가 필요합니다. 오늘은 예제를 기반으로 SQL을 최적화하는 방법을 소개하겠습니다.
문제 SQL 판단
SQL에 문제가 있는지 여부를 두 가지 증상으로 판단할 수 있습니다.
-
시스템 수준 증상
CPU 소모가 심함
IO 대기가 심함
페이지 응답 시간이 너무 깁니다. 긴
애플리케이션의 로그에 시간 초과 및 기타 오류
가 있는 경우 sar 명령과 top 명령을 사용하여 현재 시스템 상태를 볼 수 있습니다. Prometheus, Grafana 등의 모니터링 도구를 통해서도 시스템 상태를 관찰할 수 있습니다.
-
SQL 문 표현
길다
실행 시간이 너무 깁니다
전체 테이블 스캔에서 데이터 가져오기
-
실행 계획의 행과 비용이 매우 큽니다.
긴 SQL은 이해하기 쉽습니다. SQL이 너무 길면 가독성도 떨어지고 문제 발생 빈도도 확실히 높아집니다. SQL 문제를 더 자세히 판단하려면 아래와 같이 실행 계획부터 시작해야 합니다.

실행 계획에 따르면 이 쿼리는 전체 테이블 스캔 Type=ALL을 사용하며 행이 매우 큽니다(9950400). ). 기본적으로 이것이 단락이라고 판단할 수 있습니다.
문제 SQL 가져오기
다른 데이터베이스에는 이를 가져오는 방법이 다릅니다. 다음은 현재 주류 데이터베이스를 위한 느린 쿼리 SQL 획득 도구입니다.
-
MySQL
느린 쿼리 로그
-
테스트 도구 loadrunner
Percona 회사의 ptquery 및 기타 도구
-
Oracle
AWR 보고서
테스트 도구 loadrunner 등
-
v$, _잠깐만요 등등
GRID Control 모니터링 도구
-
Dameng 데이터베이스
AWR 보고서
테스트 도구 loadrunner 등
-
Dameng 성능 모니터링 도구(dem)
-
관련 내부 견해 v$, $session_wait 등
SQL 작성 기술
SQL 작성에는 몇 가지 일반적인 기술이 있습니다.
• 인덱스를 합리적으로 사용하세요
인덱스 수가 적을수록 쿼리 속도가 느려집니다. 더 많은 공간을 차지하며 추가, 삭제 및 수정을 실행할 때 인덱스를 동적으로 유지해야 하며 이는 성능에 영향을 미칩니다. 선택 비율이 높고(중복 값이 적음) B-트리 인덱스가 필요한 곳에서 자주 참조됩니다.
일반적으로 복잡한 문서 유형 쿼리는 전체 텍스트 인덱스를 사용하여 쿼리와 DML 간에 균형을 유지해야 합니다. 선행 열이 아닌 쿼리에 주의하세요
• UNION 대신 UNION ALL을 사용하세요
UNION ALL은 UNION보다 실행 효율성이 더 높으며 UNION은 실행 시 데이터 정렬이 필요합니다
• select * writing을 피하세요
SQL을 실행할 때 옵티마이저는 *를 특정 열로 변환해야 하며 각 쿼리는 테이블로 반환되어야 하며 포함 인덱스는 사용할 수 없습니다.
• JOIN 필드는 인덱싱하는 것이 좋습니다.
일반적으로 JOIN 필드는 미리 인덱싱됩니다.
• 복잡한 SQL 문 방지
가독성 향상, 여러 개의 짧은 쿼리로 변환될 수 있음 , 업무 종료로 처리
• 1=1 쓰기를 피하세요
• rand() 유사한 쓰기를 피하세요
RAND()로 인해 데이터 열이 여러 번 스캔됩니다
SQL 최적화
실행 계획
completed SQL을 최적화할 때는 먼저 실행 계획을 읽어야 합니다. 실행 계획을 보면 효율성이 낮은 부분과 최적화가 필요한 부분을 알려줍니다. 실행 계획이 무엇인지 알아보기 위해 MYSQL을 예로 들어 보겠습니다. (데이터베이스마다 실행계획이 다르기 때문에 직접 이해하셔야 합니다)

| Field | Explanation |
|---|---|
| id | 각각의 독립적으로 실행되는 작업 식별은 id 값이 클수록 먼저 실행되는 개체를 식별합니다. 실행 순서는 위에서 아래로 아래 |
| select_type | 쿼리의 각 select 절 유형 |
| table | 작업 중인 개체의 이름, 일반적으로 테이블 이름이지만 다른 이름도 있습니다. format |
| partitions | 일치하는 파티션 정보(파티셔닝되지 않은 테이블의 경우 값은 NULL) |
| type | 조인 작업 유형 |
| possible_keys | possible indexes |
| 키 | 옵티마이저가 실제로 사용하는 인덱스(가장 중요한 열) 조인 유형은 최고부터 최악까지 const, eq_reg, ref, range, index, ALL입니다. ALL이 나타나면 현재 SQL에 "악취"가 있다는 의미 |
| key_len | 옵티마이저가 선택한 인덱스 키의 길이, 단위는 바이트 |
| ref | 의 참조 객체를 나타냅니다. 이 행의 연산된 객체, 비참조 객체는 NULL |
| rows | 쿼리 실행으로 스캔된 튜플 수(innodb의 경우 이 값은 추정치임) |
| filtered | 튜플 수 데이터가 필터링되는 조건 테이블에서 Percent |
| extra | 실행 계획의 중요한 보충 정보입니다. 이 열에 Using filesort, Using temporary라는 단어가 나타날 때 주의하세요. beoptimized |
다음으로 실제 최적화 사례를 사용하여 SQL 최적화 프로세스와 최적화 기술을 설명합니다.
최적화 사례
테이블 구조
CREATE TABLE `a`
(
`id` int(11) NOT NULLAUTO_INCREMENT,
`seller_id` bigint(20) DEFAULT NULL,
`seller_name` varchar(100) CHARACTER SET utf8 COLLATE utf8_bin DEFAULT NULL,
`gmt_create` varchar(30) DEFAULT NULL,
PRIMARY KEY (`id`)
);
CREATE TABLE `b`
(
`id` int(11) NOT NULLAUTO_INCREMENT,
`seller_name` varchar(100) DEFAULT NULL,
`user_id` varchar(50) DEFAULT NULL,
`user_name` varchar(100) DEFAULT NULL,
`sales` bigint(20) DEFAULT NULL,
`gmt_create` varchar(30) DEFAULT NULL,
PRIMARY KEY (`id`)
);
CREATE TABLE `c`
(
`id` int(11) NOT NULLAUTO_INCREMENT,
`user_id` varchar(50) DEFAULT NULL,
`order_id` varchar(100) DEFAULT NULL,
`state` bigint(20) DEFAULT NULL,
`gmt_create` varchar(30) DEFAULT NULL,
PRIMARY KEY (`id`)
);세 개의 테이블은 현재 사용자의 현재 시간 전후 10시간 주문 상태를 쿼리하고, 주문 생성 시간에 따라 오름차순으로 정렬하는 관련 테이블입니다.
select a.seller_id,
a.seller_name,
b.user_name,
c.state
from a,
b,
c
where a.seller_name = b.seller_name
and b.user_id = c.user_id
and c.user_id = 17
and a.gmt_create
BETWEEN DATE_ADD(NOW(), INTERVAL – 600 MINUTE)
AND DATE_ADD(NOW(), INTERVAL 600 MINUTE)
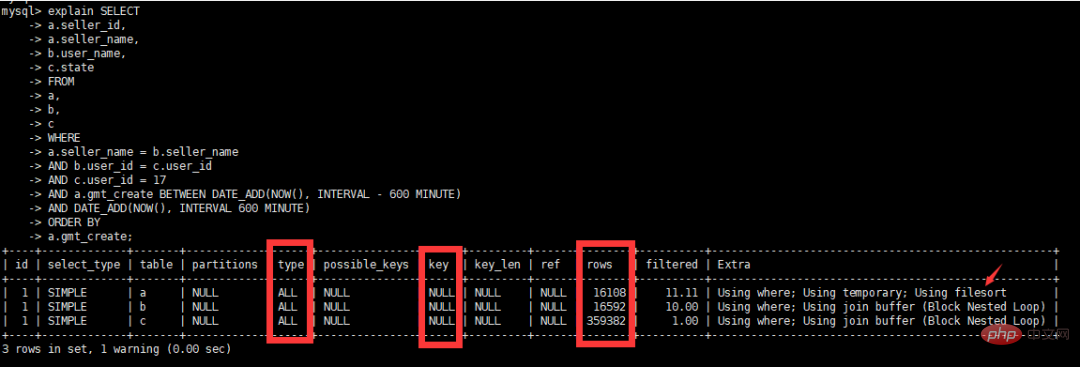
order by a.gmt_create;데이터 볼륨 보기

원래 실행 시간

원래 실행 계획
초기 최적화 아이디어
SQL의 where 조건 필드 유형은 다음과 같습니다. 일관성을 유지하다 테이블의 user_id는 varchar(50) 유형입니다. 실제 SQL 사용된 int 유형은 암시적 변환을 가지며 인덱스가 추가되지 않습니다. 테이블 b와 c의 user_id 필드를 int 유형으로 변경합니다.
테이블 b와 테이블 c 사이에 연관이 있으므로 테이블 b와 테이블 c의 user_id에 인덱스를 생성합니다.
테이블 a와 테이블 b 사이에 연관이 있으므로 Seller_name에 인덱스를 생성합니다. 테이블 a와 b의 필드
복합 인덱스 사용 임시 테이블 및 정렬 제거
SQL의 예비 최적화
alter table b modify `user_id` int(10) DEFAULT NULL; alter table c modify `user_id` int(10) DEFAULT NULL; alter table c add index `idx_user_id`(`user_id`); alter table b add index `idx_user_id_sell_name`(`user_id`,`seller_name`); alter table a add index `idx_sellname_gmt_sellid`(`gmt_create`,`seller_name`,`seller_id`);
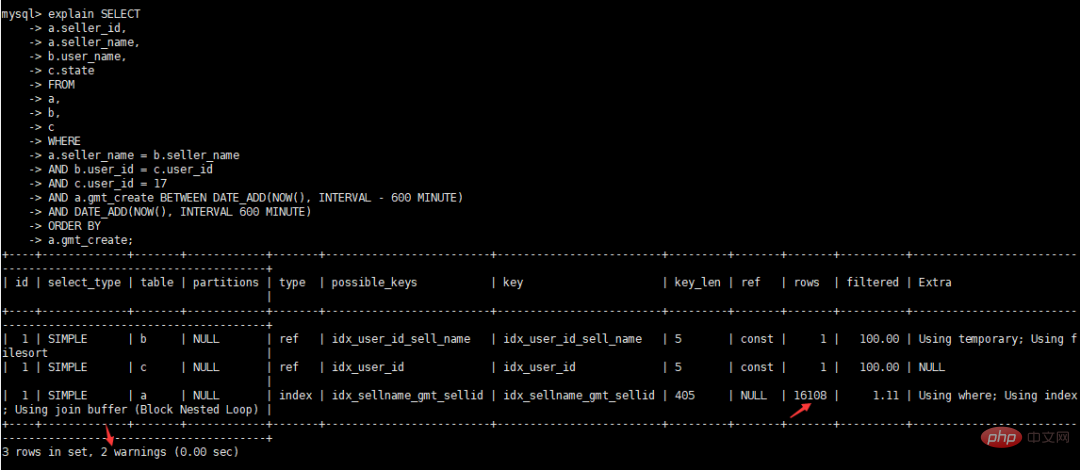
최적화 후 실행 시간 보기

최적화 후 실행 계획 보기
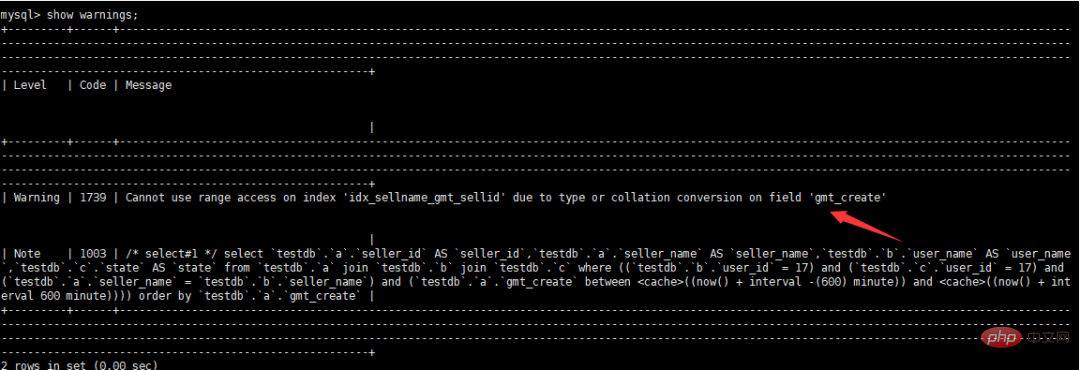
경고 정보 보기
계속해서 테이블 변경 및 수정 "gmt_create" datetime DEFAULT NULL;
실행 시간 보기

실행 계획 보기
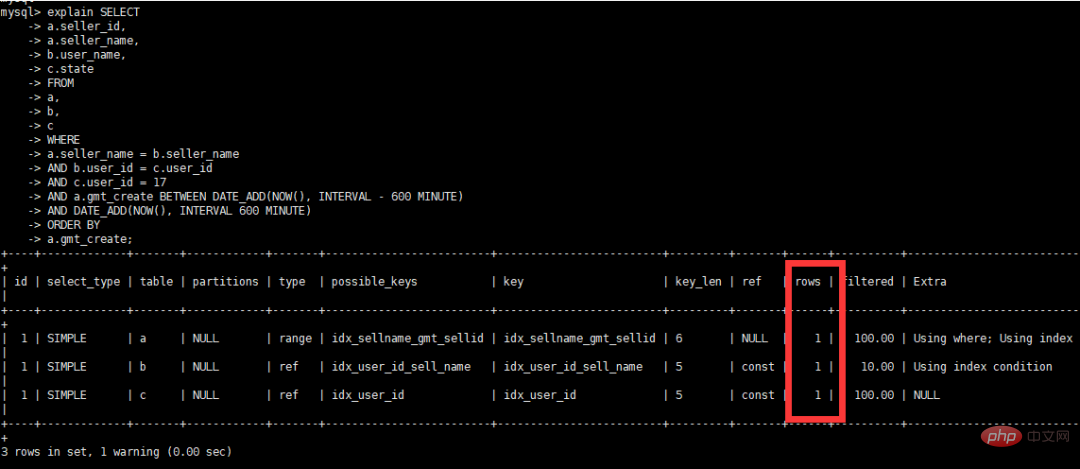
요약
실행 계획 보기 설명
-
알람 메시지가 있으면 알람 확인 정보 표시 경고;
SQL에 관련된 테이블 구조 및 인덱스 정보 보기
에 따라 가능한 최적화 포인트를 생각해 보세요. 실행 계획
최적화 가능한 지점에 따라 테이블 구조 변경, 인덱스 추가, SQL 재작성 등을 수행합니다. 네 번째 단계를 반복하세요
-
관련 권장 사항: "
mysql 튜토리얼 "
위 내용은 예제를 사용하여 SQL을 최적화하는 방법을 알려줍니다.의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!