
Java에서 일반적으로 사용되는 데이터 구조는 무엇입니까?

- 青灯夜游원래의
- 2021-04-14 16:52:0743441검색
Java 데이터 구조에는 다음이 포함됩니다. 1. 배열, 재귀 데이터 구조 3. "후입 선출" 및 "선입 선출" 원칙에 따라 데이터를 저장하는 스택; . 큐 5. 트리는 n(n>0)개의 제한된 노드로 구성된 계층적 관계의 집합입니다. 6. 그래프 8.

이 튜토리얼의 운영 환경: windows7 시스템, java8 버전, DELL G3 컴퓨터.
Java의 일반적인 데이터 구조
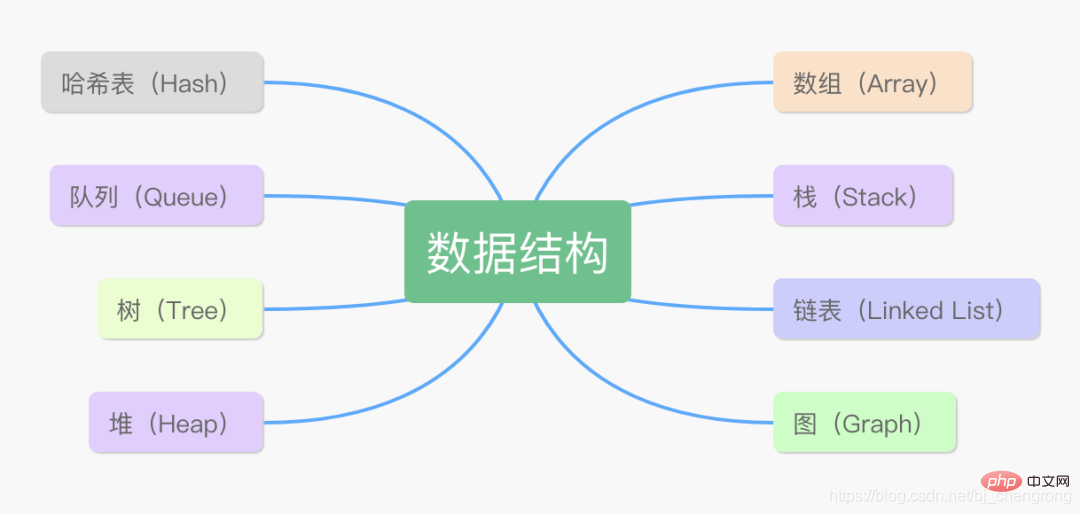
이 8가지 데이터 구조의 차이점은 무엇인가요?
①, array
장점:
인덱스로 요소를 쿼리하는 것이 빠릅니다.
인덱스로 배열을 탐색하는 것도 편리합니다.
단점:
배열의 크기는 생성 후에 결정되며 확장할 수 없습니다.
배열은 한 가지 유형의 데이터만 저장할 수 있습니다.
요소 추가 및 삭제 작업에는 시간이 걸립니다. -소비, 다른 요소를 이동해야 하기 때문입니다.
②, 연결 목록
-
책 "알고리즘(4판)"에서는 연결 목록을 다음과 같이 정의합니다.
연결 목록은 재귀적 데이터 구조로 비어 있거나(null) 또는 요소가 있는 노드에 대한 참조와 다른 연결 목록에 대한 참조입니다.
Java의 LinkedList 클래스는 연결 목록의 구조를 코드 형태로 매우 생생하게 표현할 수 있습니다.
public class LinkedList<E> {
transient Node<E> first;
transient Node<E> last;
private static class Node<E> {
E item;
Node<E> next;
Node<E> prev;
Node(Node<E> prev, E element, Node<E> next) {
this.item = element;
this.next = next;
this.prev = prev;
}
}
}이것은 이중 연결 목록입니다. 현재 요소 항목에는 prev와 next가 있지만 prev는 다음과 같습니다. 첫 번째는 null이고 마지막의 다음은 null입니다. 단방향 연결 리스트인 경우 다음만 있고 이전은 없습니다.
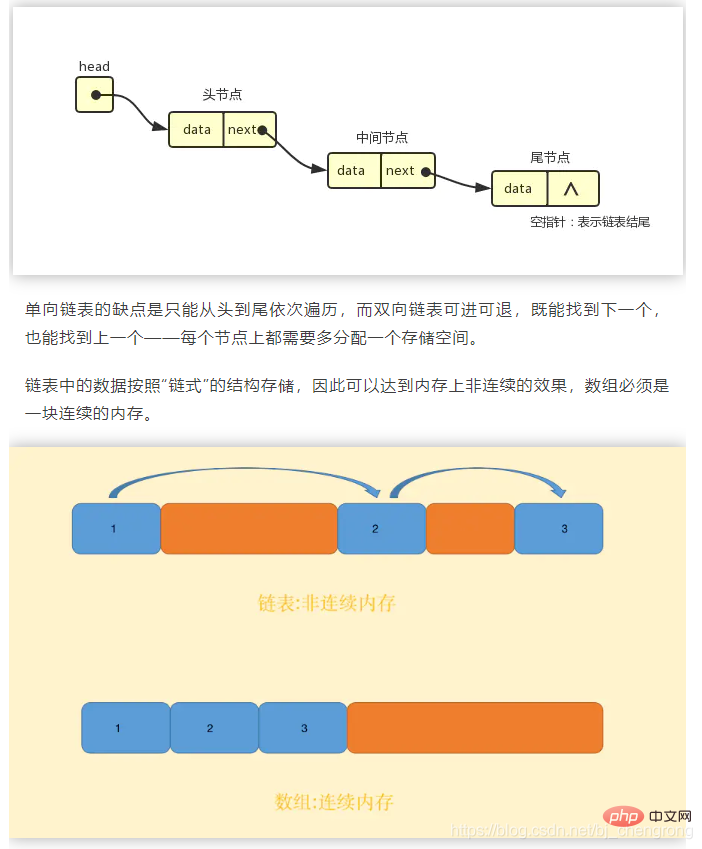
순차적으로 저장할 필요가 없기 때문에 연결된 목록은 삽입 및 삭제 시 O(1) 시간 복잡도를 달성할 수 있습니다. 배열과 같은 다른 요소를 이동해야 함). 또한 연결된 목록은 데이터 크기를 미리 알아야 하는 배열의 단점도 극복하여 유연한 동적 메모리 관리가 가능합니다.
장점:
용량을 초기화할 필요가 없습니다.
모든 요소를 추가할 수 있습니다.
삽입 및 삭제 시에만 참조를 업데이트하세요.
단점:
에는 많은 수의 참조가 포함되어 있으며 많은 메모리 공간을 차지합니다.
요소를 찾으려면 전체 연결 목록을 탐색해야 하므로 시간이 많이 걸립니다.
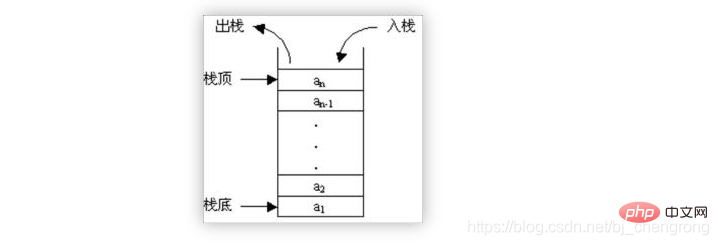
3, 스택
스택은 양동이처럼 바닥은 밀봉되어 있고 윗부분은 열려있어 물이 들어오고 나갈 수 있습니다. 물통을 사용해 본 친구들은 이 원리를 이해해야 합니다. 먼저 들어가는 물은 물통 바닥에 있고, 나중에 들어가는 물은 물통 꼭대기에 있습니다. 먼저 들어간 물은 나중에 쏟아집니다.
마찬가지로 스택은 "후입선출"과 "선입선출"의 원칙에 따라 데이터를 저장합니다. 먼저 삽입된 데이터는 스택의 맨 아래로 푸시되고 나중에 삽입된 데이터는 스택에 저장됩니다. 데이터를 읽으면 순차적으로 읽기 시작됩니다.
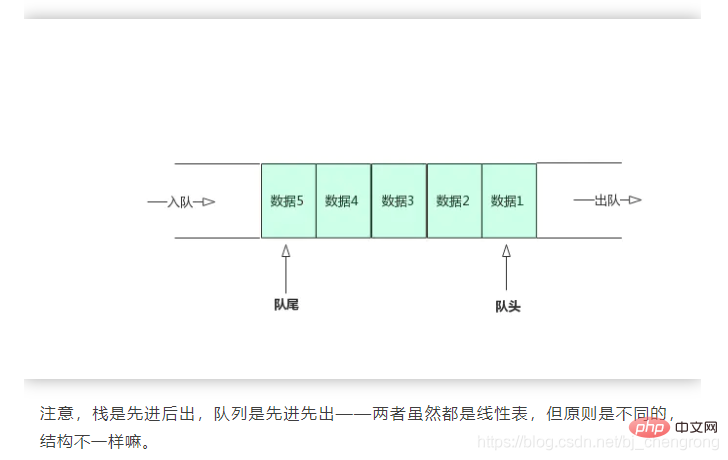
4, 대기열
대기열은 마치 수도관의 한 부분과 같으며 양쪽 끝이 열려 있고 한쪽 끝에서 물이 들어오고 다른 쪽 끝에서 나옵니다. 먼저 들어간 물이 먼저 나오고, 마지막으로 들어간 물이 나중에 나옵니다.
수관과 다소 다르게 대기열은 두 개의 끝을 정의합니다. 한 쪽 끝은 대기열의 리더라고 하고 다른 쪽 끝은 대기열의 꼬리라고 합니다. 큐의 헤드는 삭제 작업(dequeue)만 허용하고 큐의 꼬리는 삽입 작업(enqueue)만 허용합니다.
⑤, tree
트리는 n(n>0)개의 제한된 노드로 구성된 계층적 관계의 집합인 전형적인 비선형 구조입니다.
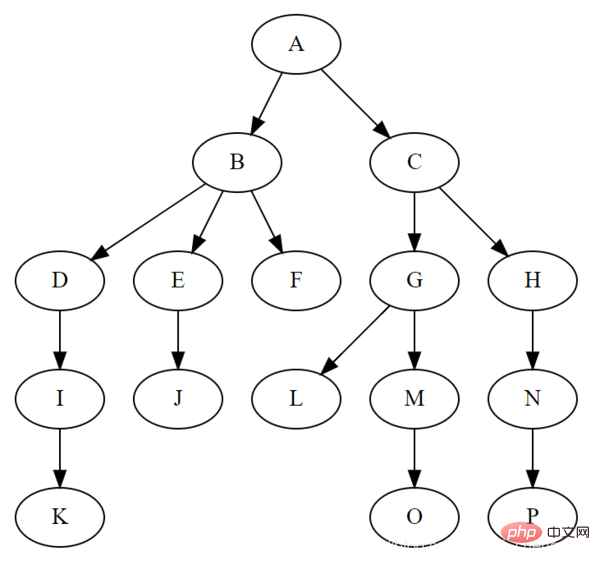
트리라고 불리는 이유는 이 데이터 구조가 뿌리가 맨 위에 있고 잎이 맨 아래에 있다는 점만 제외하면 거꾸로 된 나무처럼 보이기 때문입니다. 트리 데이터 구조에는 다음과 같은 특징이 있습니다.
각 노드에는 제한된 하위 노드만 있거나 하위 노드가 없습니다.
상위 노드가 없는 노드를 루트 노드라고 합니다. 그리고 상위 노드는 하나만 있습니다.
루트 노드를 제외하고 각 하위 노드는 여러 개의 분리된 하위 트리로 나눌 수 있습니다.
-
아래 그림은 나무에 대한 몇 가지 용어를 보여줍니다.
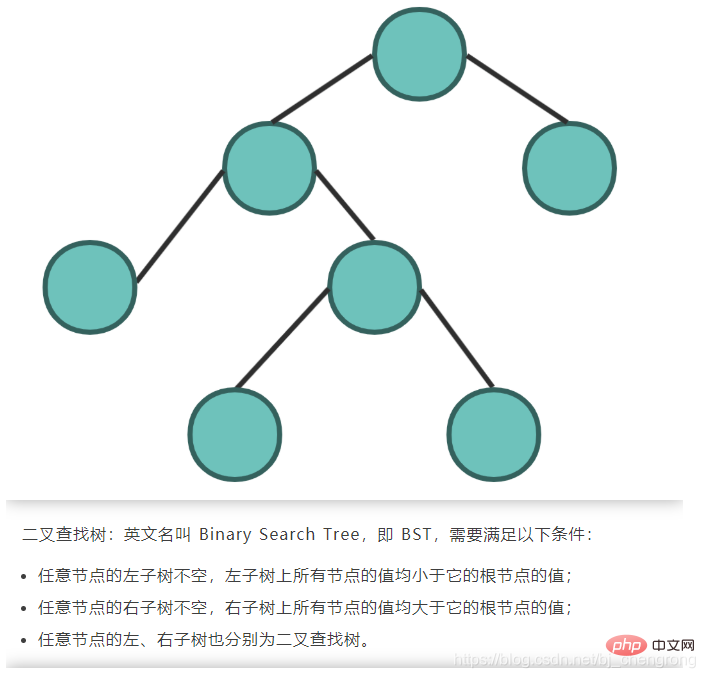
이진 탐색 트리의 특성상 다른 자료구조에 비해 탐색과 삽입의 시간복잡도가 O(logn)로 낮다는 장점이 있다. 위 그림에서 5개의 요소를 찾으려면 루트 노드 7에서 시작합니다. 5를 찾으면 7의 왼쪽에 있어야 합니다. 4를 찾으면 5는 4의 오른쪽에 있어야 합니다. 우리는 6을 찾았습니다. 그러면 5는 6의 왼쪽에 있어야 합니다. 측면이 발견되었습니다. 이상적으로는 BST를 통해 노드를 찾으면 확인해야 하는 노드 수를 절반으로 줄일 수 있습니다.
이상적으로는 BST를 통해 노드를 찾으면 확인해야 하는 노드 수를 절반으로 줄일 수 있습니다. 균형 이진 트리: 노드의 두 하위 트리 간 높이 차이가 1보다 크지 않은 경우에만 이진 트리입니다. 구소련 수학자 Adelse-Velskil과 Landis가 1962년에 제안한 고도로 균형 잡힌 이진 트리는 과학자의 영어 이름에 따라 AVL 트리라고도 합니다.
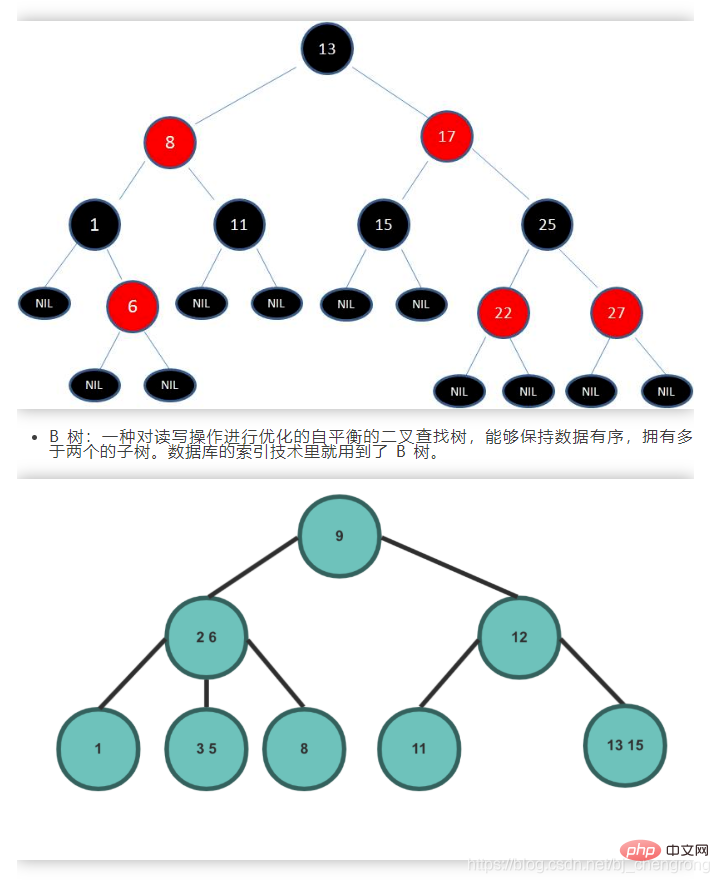
균형 이진 트리는 본질적으로 이진 탐색 트리입니다. 그러나 왼쪽과 오른쪽 하위 트리 사이의 높이 차이를 제한하고 선형 구조로 진화하는 경향이 있는 기울어진 트리와 같은 상황을 피하기 위해 각각의 왼쪽 및 오른쪽 하위 트리가 필요합니다. 이진 검색 트리의 노드는 트리에 제한이 있습니다. 왼쪽과 오른쪽 하위 트리 사이의 높이 차이를 균형 인자라고 합니다. 트리의 각 노드의 균형 인자의 절대값은 1보다 크지 않습니다.이진 트리 균형을 맞추는 데 어려운 점은 노드를 삭제하거나 추가할 때 왼쪽 또는 오른쪽 회전을 통해 좌우 균형을 유지하는 방법입니다. Java에서 가장 일반적인 균형 이진 트리는 빨간색-검은색 트리입니다. 이진 트리의 균형은 색상 제약 조건을 통해 유지됩니다.
1) 각 노드는 빨간색 또는 검은색만 가능합니다. 2) 루트 노드는 검정색입니다3) 각 리프 노드(NIL 노드, 빈 노드)는 검정색입니다. 4) 노드가 빨간색이면 해당 하위 노드는 모두 검정색입니다. 즉, 인접한 두 개의 빨간색 노드가 경로에 나타날 수 없습니다.
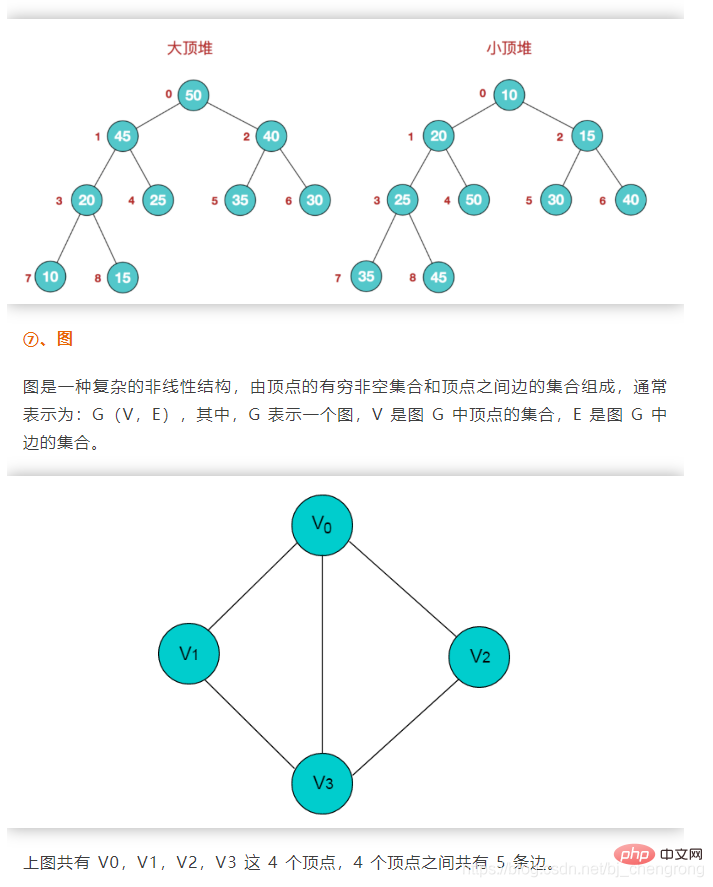
5) 모든 노드에서 각 리프까지의 모든 경로에는 동일한 수의 검정색 노드가 포함됩니다.⑥, heap
힙은 다음과 같은 특성을 지닌 트리의 배열 객체로 간주될 수 있습니다.
힙에 있는 노드의 값은 항상 크거나 작지 않습니다. 그것보다 상위 노드의 값
힙은 항상 완전한 이진 트리입니다.
가장 큰 루트 노드가 있는 힙을 최대 힙 또는 대형 루트 힙이라고 하며, 가장 작은 루트 노드가 있는 힙을 최소 힙 또는 작은 루트 힙이라고 합니다.
선형 구조에서는 데이터 요소 간에 고유한 선형 관계가 충족되며, 각 데이터 요소(첫 번째 및 마지막 제외)에는 고유한 "선행자"와 "후행자"가 있습니다.
트리 구조에서; , 데이터 요소 간에는 명백한 계층 관계가 있으며, 각 데이터 요소는 상위 계층의 하나의 요소(상위 노드)와 하위 계층의 여러 요소(하위 노드)에만 관련됩니다.
- 그래프 구조에서 관계는 다음과 같습니다. 노드 사이는 임의적이며 그래프의 두 데이터 요소는 서로 관련될 수 있습니다.
- 8, 해시 테이블
- 해시 테이블이라고도 불리는 해시 테이블은 키-값을 통해 직접 접근할 수 있는 데이터 구조로, 가장 큰 특징은 검색, 삽입, 삭제가 빠르게 구현된다는 점입니다.
배열의 가장 큰 특징은 검색은 쉽지만 삽입과 삭제가 어렵다는 것이고, 반면 연결리스트는 검색은 어렵지만 삽입과 삭제는 쉽다는 것입니다. 해시 테이블은 두 가지의 장점을 완벽하게 결합합니다. 또한 이를 기반으로 트리의 장점도 추가됩니다.
해시 함수는 해시 테이블에서 매우 중요한 역할을 합니다. 이는 임의 길이의 입력을 고정 길이 출력으로 변환할 수 있으며 출력은 해시 값입니다. 해시 함수는 데이터 시퀀스의 액세스 프로세스를 더욱 빠르고 효율적으로 만들어줍니다. 해시 함수를 통해 데이터 요소를 빠르게 찾을 수 있습니다.
키워드가 k인 경우 해당 값은
저장 위치에 저장됩니다. 따라서 k에 해당하는 값을 탐색하지 않고 바로 구할 수 있다.두 개의 다른 데이터 블록에 대해 해시 값이 동일할 가능성은 극히 적습니다. 즉, 특정 데이터 블록에 대해 동일한 해시 값을 가진 데이터 블록을 찾는 것이 매우 어렵습니다. 더욱이, 데이터 블록의 경우, 단지 1비트만 변경되어도 해시 값의 변화는 매우 클 것입니다. 이것이 바로 Hash의 값입니다!
가능성은 극히 적지만 해시 충돌이 발생하면 Java의 HashMap은 연결 목록의 길이가 8보다 크면 배열의 동일한 위치에 추가합니다. 처리를 위해 레드-블랙 트리로 변환 — —소위 지퍼 방식(배열 + 연결 리스트)입니다.
더 많은 프로그래밍 관련 지식을 보려면 프로그래밍 비디오를 방문하세요! !
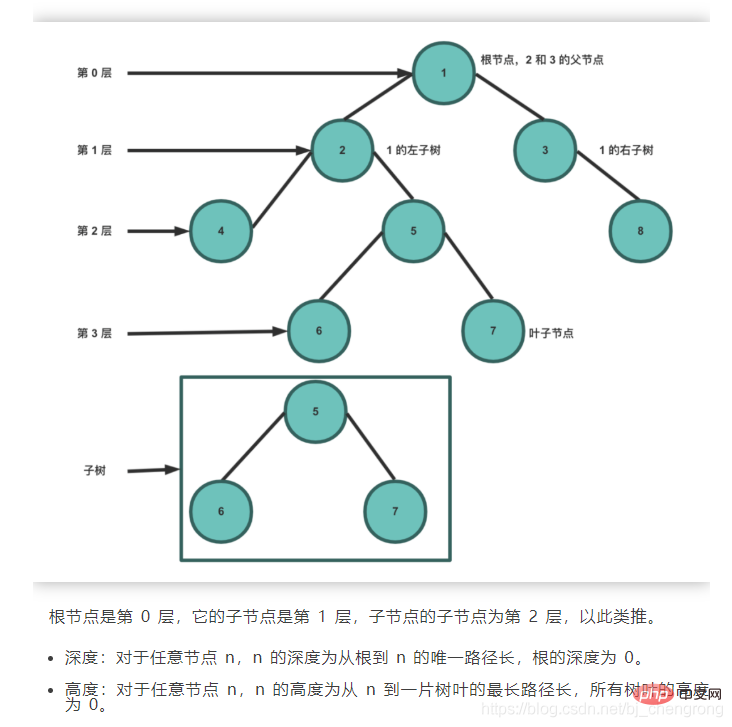 이상적으로는 BST를 통해 노드를 찾으면 확인해야 하는 노드 수를 절반으로 줄일 수 있습니다.
이상적으로는 BST를 통해 노드를 찾으면 확인해야 하는 노드 수를 절반으로 줄일 수 있습니다. 
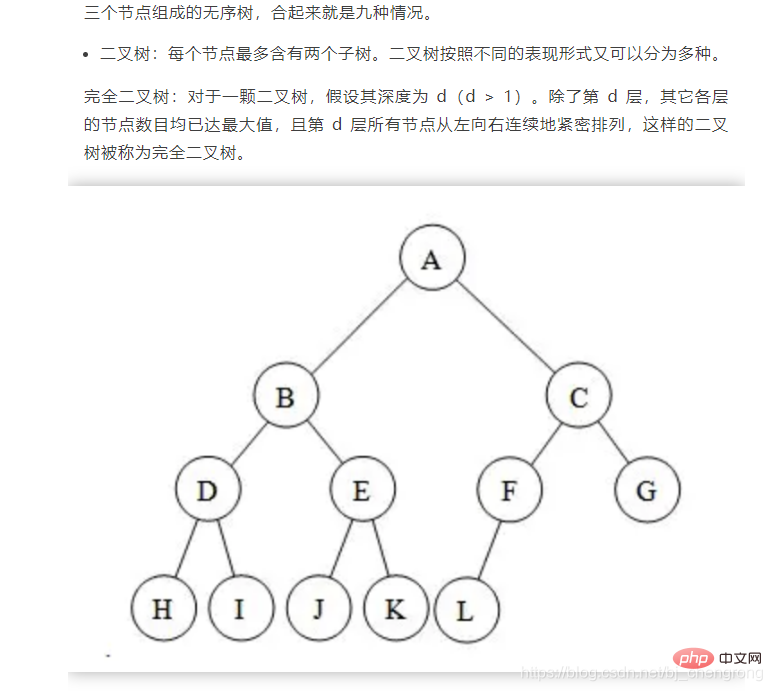 이진 트리 균형을 맞추는 데 어려운 점은 노드를 삭제하거나 추가할 때 왼쪽 또는 오른쪽 회전을 통해 좌우 균형을 유지하는 방법입니다.
이진 트리 균형을 맞추는 데 어려운 점은 노드를 삭제하거나 추가할 때 왼쪽 또는 오른쪽 회전을 통해 좌우 균형을 유지하는 방법입니다. 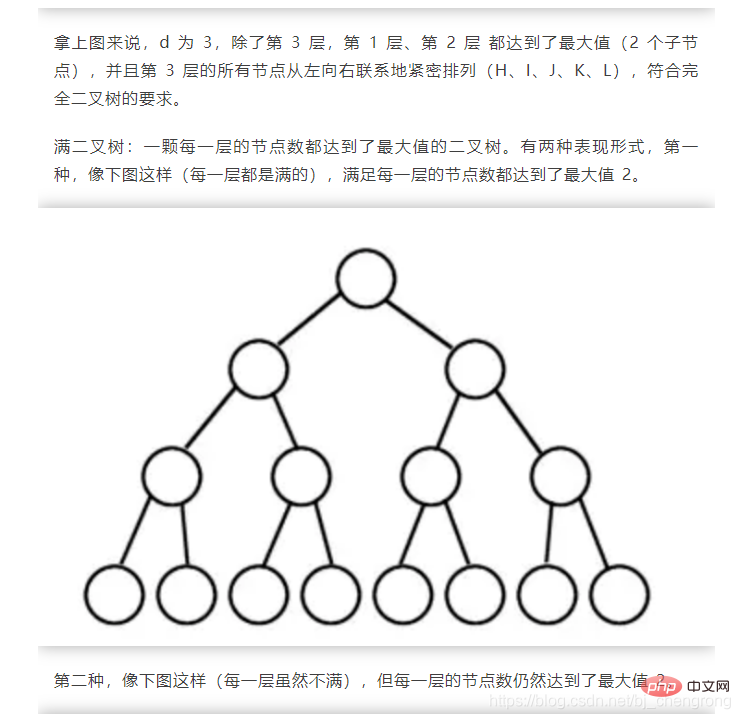
 3) 각 리프 노드(NIL 노드, 빈 노드)는 검정색입니다.
3) 각 리프 노드(NIL 노드, 빈 노드)는 검정색입니다. 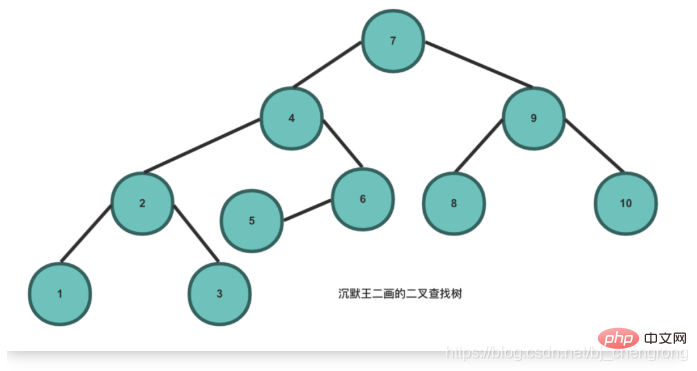
위 내용은 Java에서 일반적으로 사용되는 데이터 구조는 무엇입니까?의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!