
Redis 로그: 빠른 복구를 위한 팁

- coldplay.xixi앞으로
- 2021-03-02 09:54:132343검색

"독립하는 것이 맞고, 서클에 통합되는 것이 옳습니다. 자신이 원하는 삶이 어떤 것인지, 그에 대한 대가는 얼마인지 파악하는 것이 핵심입니다.
"
우리는 일반적으로 Redis를 캐시로 사용하여 읽기 응답 성능을 향상시킵니다. Redis가 다운되면 메모리에 있는 모든 데이터가 손실됩니다. 데이터베이스에 직접 액세스하여 대량의 트래픽이 MySQL에 도달하면 더 심각한 문제를 야기합니다.
또한 데이터베이스에서 Redis로 천천히 읽는 성능은 필연적으로 Redis에서 가져오는 것보다 빠르며, 이로 인해 응답도 느려집니다.
다운타임에 대한 두려움 없이 빠른 복구를 달성하기 위해 Redis는 AOF(Append Only FIle) 로그와 RDB 스냅샷이라는 두 가지 주요 킬러 기능을 설계했습니다.
기술을 배울 때, 여러분은 대개 머릿속에 완전한 지식 프레임워크와 아키텍처 시스템을 구축하지 않고 체계적인 관점도 없이 흩어져 있는 기술적 포인트만 접하게 됩니다. 이것은 매우 어려울 것이며 언뜻 보기에는 할 수 있을 것처럼 보이지만 나중에는 잊어버리고 혼란스러워질 것입니다.
함께 Redis를 철저하게 이해하고, Redis의 핵심 원리와 실무 능력을 깊이 있게 마스터해 보세요. 완전한 지식 프레임워크를 구축하고 글로벌 관점에서 전체 지식 시스템을 구성하는 방법을 배웁니다.
이 글은 하드코어한 글입니다. 저장해 두시고, 좋아요를 누르시고, 진정하시고 읽으시면 많은 이득을 얻으실 것이라 믿습니다.
이전 글에서는 Redis의 핵심 데이터 구조, IO 모델, 스레드 모델을 분석하고 다양한 데이터에 따라 적절한 데이터 인코딩을 사용했습니다. 정말 빠른 이유를 깊이 파악해보세요!
권장(무료): redis
이 문서에서는 다음 사항에 중점을 둘 것입니다.
다운타임 후 빠르게 복구하는 방법은 무엇입니까?
이 다운되었습니다. Redis는 어떻게 데이터 손실을 방지하나요?
RDB 메모리 스냅샷이란 무엇인가요?
AOF 로그 구현 메커니즘
기록 중 복사 기술이란 무엇인가요?
….
관련된 지식 포인트는 그림에 표시된 것과 같습니다.
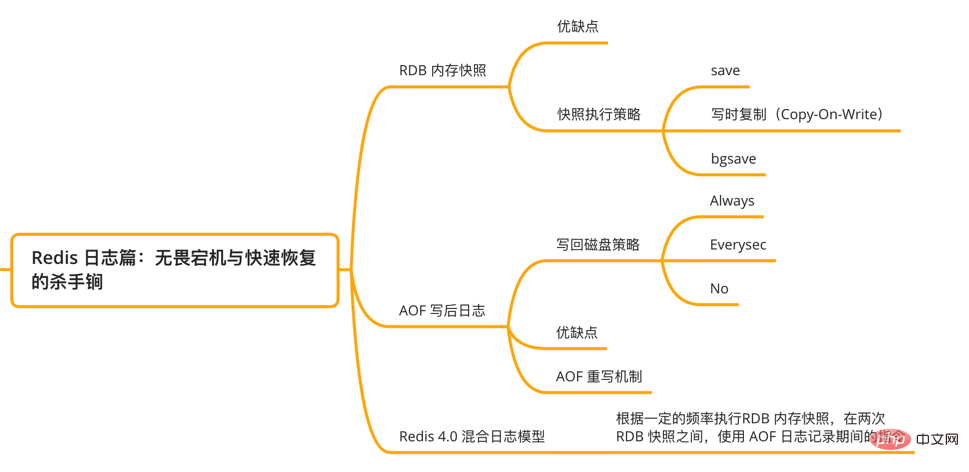
Redis 파노라마
파노라마를 중앙에 배치할 수 있습니다. 대략 2개 정도를 3개 차원으로 확장하면 다음과 같습니다.
애플리케이션 차원: 캐시 사용량, 클러스터 사용량, 데이터 구조의 영리한 사용
시스템 차원: 세 가지로 분류 가능
고성능: 스레드 모델, 네트워크 IO 모델 , 데이터 구조, 지속성 메커니즘
고가용성: 마스터-슬레이브 복제, 클러스터 샤딩 클러스터
고확장: 로드 밸런싱
Redis 시리즈 장은 다음 마인드 맵을 중심으로 진행됩니다. Redis를 함께 살펴보겠습니다. 고성능, 내구성 있는 메커니즘의 비밀입니다.
파노라마 뷰를 갖고 시스템 뷰를 마스터하세요.
시스템 뷰는 실제로 어느 정도 중요합니다. 문제를 해결할 때 시스템 뷰가 있다는 것은 문제를 기반으로 체계적으로 찾아 해결할 수 있다는 것을 의미합니다.
RDB 메모리 스냅샷, 가동 중지 시간으로부터 빠른 복구 가능
"65 Brother: Redis가 어떤 이유로 다운되어 모든 트래픽이 백엔드 MySQL에 도달하게 됩니다. Redis를 즉시 다시 시작했지만 해당 데이터는 다음 위치에 저장되어 있습니다. 다시 시작한 후에도 데이터가 없습니다. 다시 시작한 후 데이터 손실을 방지하는 방법은 무엇입니까?
"
65 걱정하지 마십시오. "코드 바이트"는 Redis 충돌 후 빠르게 복구하는 방법을 단계별로 안내합니다.
Redis 데이터는 메모리에 저장됩니다. 메모리에 있는 데이터를 디스크에 쓰는 것도 고려할 수 있나요? Redis가 재시작되면 디스크에 저장된 데이터가 메모리에 빠르게 복원되므로 재시작 후에도 정상적인 서비스를 제공할 수 있습니다.
"65 형제: 해결책을 생각했습니다. 메모리를 작동하기 위해 "쓰기" 작업이 수행될 때마다 동시에 디스크에 기록됩니다
"
이 솔루션에는 치명적인 문제가 있습니다. 명령어는 메모리뿐만 아니라 디스크에도 기록됩니다. 메모리에 비해 디스크의 성능이 너무 느려서 Redis의 성능이 크게 저하됩니다.
Memory Snapshot
"65 Brother : 동시 쓰기 문제를 방지하는 방법은 무엇입니까?
”
우리는 일반적으로 Redis를 캐시로 사용하므로 Redis가 모든 데이터를 저장하지 않더라도 데이터베이스를 통해 얻을 수 있으므로 Redis 데이터 지속성은 "RDB 데이터 스냅샷을 사용합니다. " 방법 가동 중지 시간으로부터 신속한 복구를 달성합니다.
"65 Brother: 그러면 RDB 메모리 스냅샷이 무엇인가요?
"
Redis가 "write" 명령을 실행하는 동안 메모리 데이터는 계속 변경됩니다. 소위 메모리 스냅샷은 특정 순간에 Redis 메모리에 있는 데이터의 상태 데이터를 말합니다.
특정 순간에 시간이 정지된 것과 같습니다. 사진을 찍으면 사진을 통해 특정 순간의 순간을 완벽하게 기록할 수 있습니다.
Redis도 이와 비슷합니다. 특정 순간의 데이터를 파일 형식으로 가져와서 디스크에 씁니다. 이 스냅샷 파일을 RDB 파일이라고 하며, RDB는 Redis DataBase의 약어입니다.
Redis는 RDB 메모리 스냅샷을 정기적으로 실행하므로 "write" 명령을 실행할 때마다 디스크에 쓸 필요는 없습니다. 메모리 스냅샷을 실행할 때만 디스크에 쓰면 됩니다. 빠르면서도 깨지지 않는 것을 보장할 뿐만 아니라 내구성도 확보하고 다운타임으로부터 빠르게 복구할 수 있습니다.
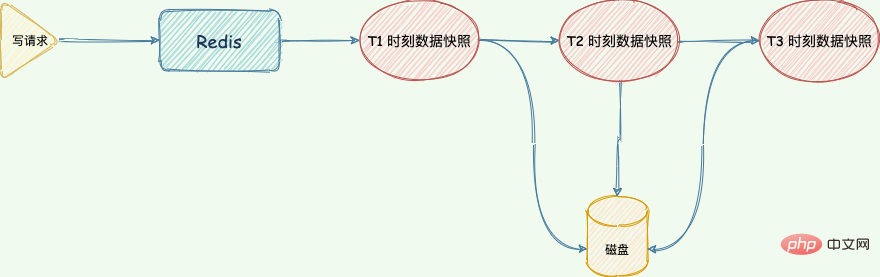
데이터 복구를 수행할 때 RDB 파일을 메모리로 직접 읽어 복구를 완료합니다.
"65 형님: 어떤 데이터를 스냅샷으로 찍어야 하나요? 아니면 얼마나 자주 스냅샷을 찍어야 하나요? 이게 스냅샷의 실행 효율성에 영향을 미치게 됩니다.
"
65 형님, 데이터 효율성을 고려하기 시작했어요. 문제. "Redis Core: 가장 빠르고 깨지지 않는 비밀"에서 우리는 단일 스레드 모델이 메인 스레드를 차단하는 작업을 피하고 RDB 파일 생성이 메인 스레드를 차단하는 것을 방지하기 위해 최선을 다해야 한다고 결정한다는 것을 알고 있습니다.
Generate RDB strategy
Redis는 RDB 파일 생성을 위한 두 가지 지침을 제공합니다.
save: 메인 스레드에 의해 실행되며 차단됩니다.
bgsave: glibc 함수
fork를 호출합니다. code> RDB 파일을 쓰기 위한 하위 프로세스를 생성합니다. 스냅샷 지속성은 하위 프로세스에 의해 완전히 처리되며, 상위 프로세스는 계속해서 클라이언트 요청을 처리하고 RDB 파일의 기본 구성을 생성합니다. <code>fork产生一个子进程用于写入 RDB 文件,快照持久化完全交给子进程来处理,父进程继续处理客户端请求,生成 RDB 文件的默认配置。
“65 哥:那在对内存数据做「快照」的时候,内存数据还能修改么?也就是写指令能否正常处理?
”
首先我们要明确一点,避免阻塞和 RDB 文件生成期间能处理写操作不是一回事。虽然主线程没有阻塞,到那时为了保证快照的数据的一致性,只能处理读操作,不能修改正在执行快照的数据。
很明显,为了生成 RDB 而暂停写操作,Redis 是不答应的。
“65 哥:那 Redis 如何实现一边处理写请求,同时生成 RDB 文件呢?
”
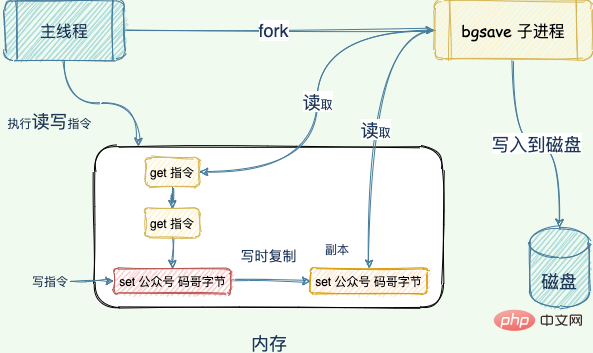
Redis 使用操作系统的多进程写时复制技术 COW(Copy On Write) 来实现快照持久化,这个机制很有意思,也很少人知道。多进程 COW 也是鉴定程序员知识广度的一个重要指标。
Redis 在持久化时会调用 glibc 的函数fork产生一个子进程,快照持久化完全交给子进程来处理,父进程继续处理客户端请求。
子进程刚刚产生时,它和父进程共享内存里面的代码段和数据段。这时你可以将父子进程想像成一个连体婴儿,共享身体。
这是 Linux 操作系统的机制,为了节约内存资源,所以尽可能让它们共享起来。在进程分离的一瞬间,内存的增长几乎没有明显变化。
bgsave 子进程可以共享主线程的所有内存数据,读取主线程的数据并写入到 RDB 文件。
在执行 SAVE 命令或者BGSAVE命令创建一个新的 RDB 文件时,程序会对数据库中的键进行检查,已过期的键不会被保存到新创建的 RDB 文件中。
当主线程执行写指令修改数据的时候,这个数据就会复制一份副本, bgsave
" 65 Brother: 메모리 데이터의 "스냅샷"을 찍을 때 메모리 데이터를 계속 수정할 수 있나요? 즉, write 명령이 정상적으로 처리될 수 있는가?
65 Brother: 메모리 데이터의 "스냅샷"을 찍을 때 메모리 데이터를 계속 수정할 수 있나요? 즉, write 명령이 정상적으로 처리될 수 있는가?
”
Redis는 운영 체제의 다중 프로세스 기록 중 복사 기술 COW(기록 중 복사)를 사용하여 스냅샷 지속성을 달성합니다. 이 메커니즘은 매우 흥미롭고 다중 프로세스 COW도 중요한 요소라는 사실을 아는 사람은 거의 없습니다. 프로그래머의 지식 범위를 식별하는 데 사용됩니다. Redis는 glibc 함수 fork를 호출하여 하위 프로세스에 의해 스냅샷 지속성이 완전히 처리되며 상위 프로세스는 계속됩니다. 클라이언트 요청이 처음 생성되면 메모리의 코드 세그먼트와 데이터 세그먼트를 상위 프로세스와 공유합니다. 이때 상위 프로세스와 하위 프로세스가 본문을 공유하는 것으로 상상할 수 있습니다. Linux 운영체제의 메커니즘이므로 메모리 자원을 최대한 공유하도록 노력하세요. 프로세스가 분리되는 순간 메모리 증가에는 거의 눈에 띄는 변화가 없습니다. bgsave 하위 프로세스는 메인 스레드의 모든 메모리 데이터를 공유하고, 이를 RDB 파일에 쓸 수 있습니다.
SAVE 명령을 실행하거나 새 RDB 파일을 생성하기 위해 BGSAVE 명령을 실행하면 프로그램은 데이터베이스의 키가 만료되었는지 확인합니다.
- 메인 스레드가 실행될 때 키는 새로 생성된 RDB 파일에 저장되지 않습니다. 데이터를 수정하는 쓰기 명령을 사용하면 데이터 복사본이 만들어지고
- 기록 중 복사 기술을 사용하면 스냅샷 중에 데이터가 수정될 수 있습니다. 이는 스냅샷의 무결성을 보장할 뿐만 아니라 메인 스레드가 동시에 수정을 방지할 수 있도록 해줍니다. Redis는 bgsave를 사용하여 현재 메모리에 있는 모든 데이터의 스냅샷을 찍습니다. 이 작업은 백그라운드에서 하위 프로세스에 의해 완료되므로 메인 스레드가 동시에 데이터를 수정할 수 있습니다. "
bgsave 하위 프로세스가 복사본 데이터를 읽으므로 기본 스레드가 원본을 직접 수정할 수 있습니다. "
전체 데이터 스냅샷을 너무 자주 실행하면 두 가지 심각한 성능 오버헤드가 발생합니다.
자주 RDB 파일을 생성하여 디스크에 기록하면 과도한 디스크 부담이 발생합니다. 이전 RDB가 아직 실행되지 않은 것으로 나타납니다. 다음 작업이 시작되었습니다.
bgsave 하위 프로세스에서 벗어나면 메인 스레드의 메모리가 커질수록 차단 시간이 길어집니다.
장점 및 단점
🎜스냅샷 복구 속도는 빠르지만, 빈도 조절이 어렵습니다. 빈도가 너무 낮으면 더 많은 데이터가 손실되고 추가 오버헤드가 발생합니다. 🎜🎜RDB는 작은 파일 크기와 빠른 데이터 복구를 위해 바이너리 + 데이터 압축을 사용합니다. 🎜 🎜RDB 전체 스냅샷 외에도 Redis는 AOF 쓰기 후 로그도 설계합니다. 🎜🎜🎜다운타임 중 데이터 손실을 방지하기 위한 AOF 쓰기 후 로그🎜🎜🎜AOF 로그는 Redis에 저장됩니다. 서버의 순차적 명령 시퀀스인 AOF 로그는 메모리를 수정하는 명령 기록만 기록합니다🎜.AOF 로그가 Redis 인스턴스 생성 이후 수정된 모든 명령 시퀀스를 기록한다고 가정하면, 빈 Redis 인스턴스에서 모든 명령을 순차적으로 실행하는 즉, "재생 중" 상태를 통해 현재 Redis 인스턴스의 메모리 데이터 구조를 복원할 수 있습니다. .
쓰기 전 로그와 쓰기 후 로그 비교
WAL(Write Ahead Log): 실제로 데이터를 쓰기 전에 수정된 데이터를 로그 파일에 기록하므로 장애 복구가 보장됩니다.
예를 들어 MySQL Innodb 스토리지 엔진의 redo 로그는 실제로 데이터를 수정하기 전에 수정 로그를 기록하고 수정된 데이터가 실행되는 데이터 로그입니다.
쓰기 후 로그: 먼저 "쓰기" 명령 요청을 실행하고 데이터를 메모리에 쓴 다음 로그를 기록합니다.
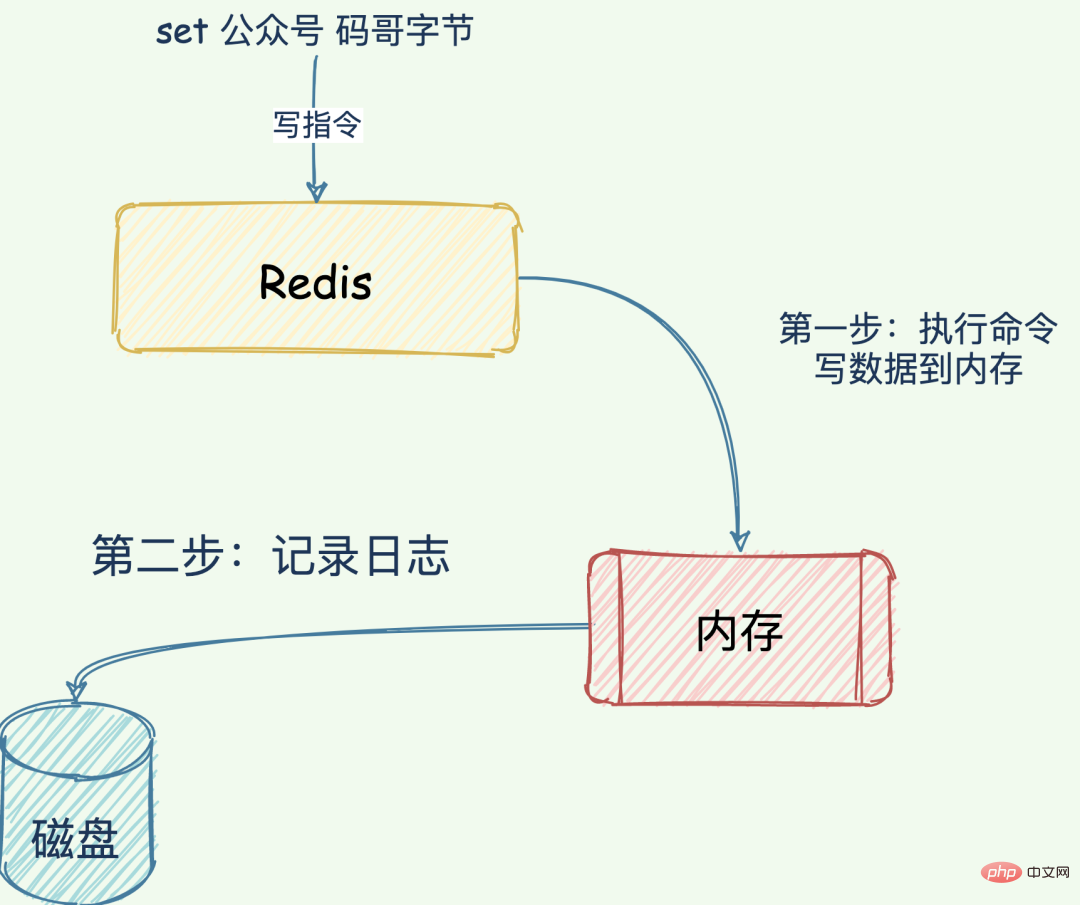
로그 형식
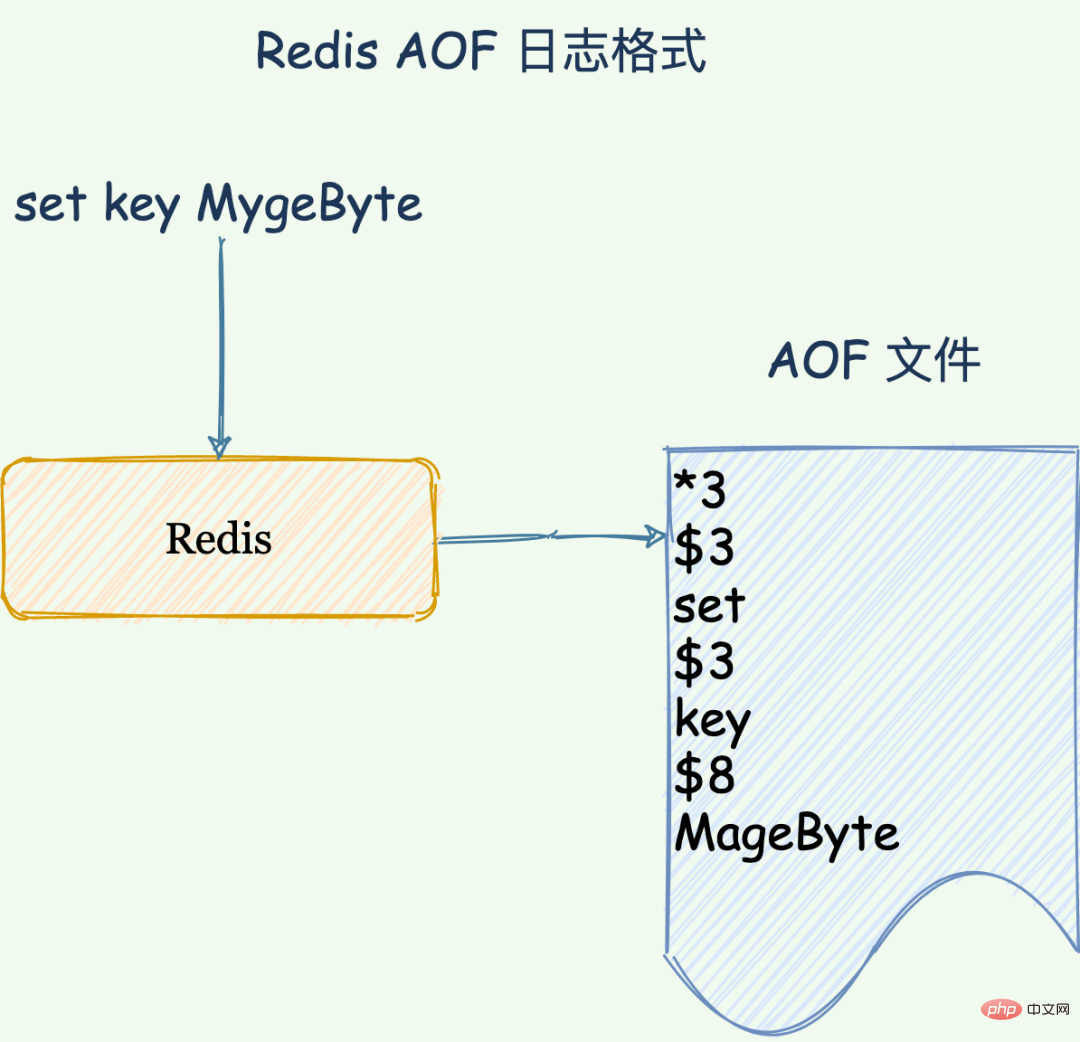
Redis가 메모리에 데이터를 쓰는 "set key MageByte" 명령을 받으면 Redis는 AOF 파일을 다음 형식으로 씁니다.
"*3": 현재 명령이 세 부분으로 나누어져 있음을 나타냅니다. 각 부분은 "$ + 숫자"로 시작하고 그 뒤에 해당 부분의 특정 "명령, 키, 값"이 옵니다.
"Number": 명령, 키 및 값의 이 부분이 차지하는 바이트 크기를 나타냅니다. 예를 들어 "$3"은 이 부분에 "set" 명령인 3바이트가 포함되어 있음을 의미합니다.
"65 Brother: Redis는 왜 쓰기 후 로그를 사용합니까?
"
쓰기 후 로그는 추가 검사 오버헤드를 방지하고 실행된 명령 검사에 구문이 필요하지 않습니다. 미리 쓰기 로깅을 사용하는 경우 구문이 올바른지 먼저 확인해야 합니다. 그렇지 않으면 로그에 잘못된 명령이 기록되어 로그 복구 사용 시 오류가 발생합니다.
또한 쓰기 후 로그를 기록해도 현재 "쓰기" 명령의 실행이 차단되지 않습니다.
“65형: 그럼 AOF만 있으면 다 안전해?
”
바보야, 그렇게 간단하지 않잖아. Redis가 방금 명령 실행을 마치고 로그를 기록하기 전에 충돌이 발생하면 명령과 관련된 데이터가 손실될 수 있습니다.
또한 AOF는 현재 명령을 차단하는 것을 방지하지만 다음 명령을 차단할 위험이 있을 수 있습니다. AOF 로그는 기본 스레드에 의해 실행됩니다. 디스크에 로그를 쓰는 동안 디스크 압력이 높으면 디스크에 쓰기가 매우 느려져 후속 "쓰기" 명령이 차단됩니다.
이 두 가지 문제가 디스크 쓰기 저장과 관련이 있다는 사실을 알고 계셨나요? "write" 명령이 실행된 후 AOF 로그를 디스크에 다시 쓰는 타이밍을 합리적으로 제어할 수 있다면 문제가 해결될 것입니다.
Writeback strategy
파일 쓰기 효율성을 높이기 위해 사용자가 파일에 일부 데이터를 쓰기 위해 write 함수를 호출하면 운영 체제는 일반적으로 기록된 데이터를 임시로 메모리에 저장합니다. 버퍼에 있는 데이터는 버퍼 공간이 가득 차거나 지정된 시간 제한을 초과할 때까지 실제로 디스크에 기록되지 않습니다. write 函数,将一些数据写入到文件的时候,操作系统通常会将写入数据暂时保存在一个内存缓冲区里面,等到缓冲区的空间被填满、或者超过了指定的时限之后,才真正地将缓冲区中的数据写入到磁盘里面。
这种做法虽然提高了效率,但也为写入数据带来了安全问题,因为如果计算机发生停机,那么保存在内存缓冲区里面的写入数据将会丢失。
为此,系统提供了fsync和fdatasync两个同步函数,它们可以强制让操作系统立即将缓冲区中的数据写入到硬盘里面,从而确保写入数据的安全性。
Redis 提供的 AOF 配置项appendfsync写回策略直接决定 AOF 持久化功能的效率和安全性。
always:同步写回,写指令执行完毕立马将
aof_buf缓冲区中的内容刷写到 AOF 文件。everysec:每秒写回,写指令执行完,日志只会写到 AOF 文件缓冲区,每隔一秒就把缓冲区内容同步到磁盘。
no: 操作系统控制,写执行执行完毕,把日志写到 AOF 文件内存缓冲区,由操作系统决定何时刷写到磁盘。
没有两全其美的策略,我们需要在性能和可靠性上做一个取舍。
always同步写回可以做到数据不丢失,但是每个「写」指令都需要写入磁盘,性能最差。
everysec每秒写回,避免了同步写回的性能开销,发生宕机可能有一秒位写入磁盘的数据丢失,在性能和可靠性之间做了折中。
no
이를 위해 시스템은
🎜Redis에서 제공하는 AOF 구성 항목fsync및fdatasync라는 두 가지 동기화 기능을 제공합니다. 이 기능을 사용하면 운영체제가 버퍼에 있는 데이터를 즉시 하드 디스크에 쓰도록 할 수 있습니다. 따라서 서면 데이터의 보안을 보장합니다.appendfsync쓰기 저장 전략은 AOF 지속성 기능의 효율성과 보안을 직접적으로 결정합니다. 🎜🎜🎜🎜항상: 동기식 쓰기 저장, 쓰기 명령이 실행된 직후aof_buf버퍼의 콘텐츠가 AOF 파일에 기록됩니다. 🎜🎜🎜🎜everysec: write 명령이 실행된 후 1초마다 로그가 AOF 파일 버퍼에만 기록되고 버퍼 내용이 1초마다 디스크에 동기화됩니다. 🎜🎜🎜🎜no: 운영 체제에 의해 제어되며 쓰기 실행이 완료된 후 로그가 AOF 파일 메모리 버퍼에 기록되고 운영 체제가 이를 디스크에 플러시할 시점을 결정합니다. 🎜🎜🎜🎜양쪽 모두를 위한 최선의 전략은 없습니다. 성능과 안정성 사이에서 절충점을 찾아야 합니다. 🎜🎜always동기식 쓰기 저장은 데이터 손실을 방지할 수 있지만 각 "쓰기" 명령은 성능이 가장 나쁜 디스크에 기록되어야 합니다. 🎜🎜everysec는 동기식 쓰기 저장의 성능 오버헤드를 방지하여 매초마다 쓰기를 수행하며, 가동 중지 시간이 발생하면 디스크에 기록된 데이터가 1초 동안 손실되어 성능과 안정성이 절충될 수 있습니다. 🎜🎜no운영 체제 제어는 쓰기 명령을 실행한 후 AOF 파일 버퍼에 기록하여 후속 "쓰기" 명령을 실행합니다. 성능은 가장 좋지만 많은 데이터가 손실될 수 있습니다. 🎜🎜“🎜65 형: 그럼 전략은 어떻게 선택해야 하나요?🎜”
고성능 및 높은 신뢰성에 대한 시스템 요구 사항에 따라 쓰기 저장 전략을 선택할 수 있습니다. 요약하자면, 높은 성능을 얻으려면 No 전략을 선택하고, 높은 신뢰성 보장을 얻으려면 Always 전략을 선택하세요. ; 약간의 데이터 손실을 허용하고 성능에 큰 영향을 미치기를 원한다면 Everysec 전략을 선택하세요.
장점 및 단점
장점: 로그는 성공적인 실행 후에만 기록되므로 명령 구문 검사의 오버헤드가 발생하지 않습니다. . 현재 "쓰기" 명령을 차단합니다.
단점: AOF는 각 명령어의 내용을 기록하므로 구체적인 형식은 위의 로그 형식을 참조하세요. 오류 복구 중에 모든 명령을 실행해야 합니다. 로그 파일이 너무 크면 전체 복구 프로세스가 매우 느려집니다.
또한 파일 시스템에도 파일 크기 제한이 있습니다. 너무 큰 파일은 저장할 수 없습니다. 파일이 커질수록 추가 효율성도 낮아집니다.
로그가 너무 큽니다: AOF 재작성 메커니즘
"65 Brother: AOF 로그 파일이 너무 크면 어떻게 해야 합니까?
"
AOF 사전 쓰기 로그는 각 "쓰기" 명령 작업을 기록합니다. . RDB 전체 스냅샷과 같은 성능 손실은 발생하지 않지만 실행 속도는 RDB만큼 빠르지 않습니다. 동시에 너무 큰 로그 파일은 속도만 원하는 Redis와 같은 실제 사람에게는 성능 문제를 일으킬 수도 있습니다. 그는 너무 큰 로그로 인해 발생하는 문제를 절대 용납할 수 없습니다.
그래서 Redis는 킬러 "AOF 재작성 메커니즘"을 설계했습니다. Redis는 AOF 로그를 줄이기 위한 bgrewriteaof 명령을 제공합니다.
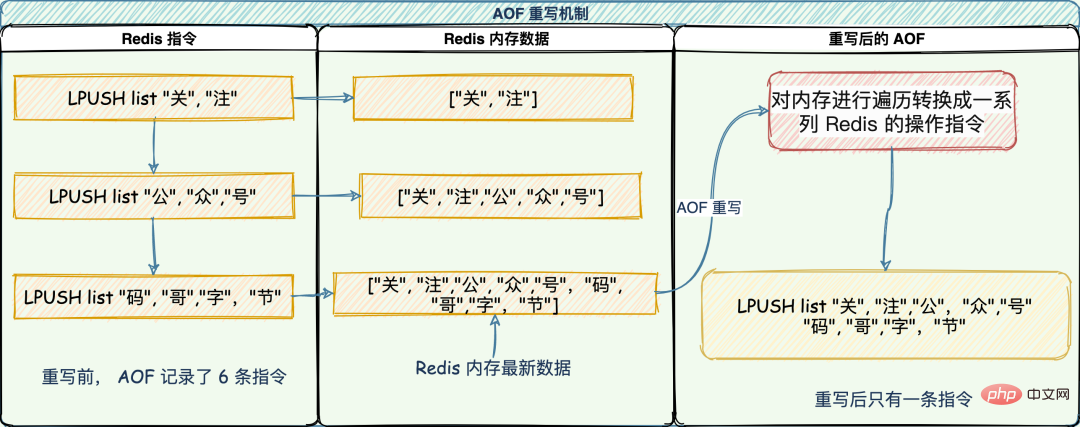
원칙은 하위 프로세스를 열어 메모리를 순회하고 이를 일련의 Redis 작업 지침으로 변환하여 새로운 AOF 로그 파일로 직렬화하는 것입니다. 직렬화가 완료되면 작업 중 발생한 증분 AOF 로그가 새 AOF 로그 파일에 추가되며, 추가가 완료되면 기존 AOF 로그 파일이 즉시 교체되어 슬리밍 작업이 완료됩니다.
"65 Brother: AOF 다시 쓰기 메커니즘이 로그 파일을 축소할 수 있는 이유는 무엇입니까?
"
다시 쓰기 메커니즘에는 이전 로그의 여러 명령을 실행된 명령으로 변환하는 "다중 대 1" 기능이 있습니다.
아래와 같이:
"65 Brother: 다시 쓴 후에는 AOF 로그가 더 작아지고 마침내 전체 데이터베이스의 최신 데이터가 됩니다. 작업 로그가 디스크에 기록됩니다. 다시 작성하면 메인 스레드가 차단되나요?
"
"Brother Ma"는 AOF 로그가 메인 스레드에 의해 다시 작성되고 AOF 다시 작성 프로세스가 실제로 백그라운드 하위 작업이라고 언급했습니다. 메인 스레드 차단을 방지하기 위해 bgrewriteaof 프로세스가 완료되었습니다.
재작성 프로세스
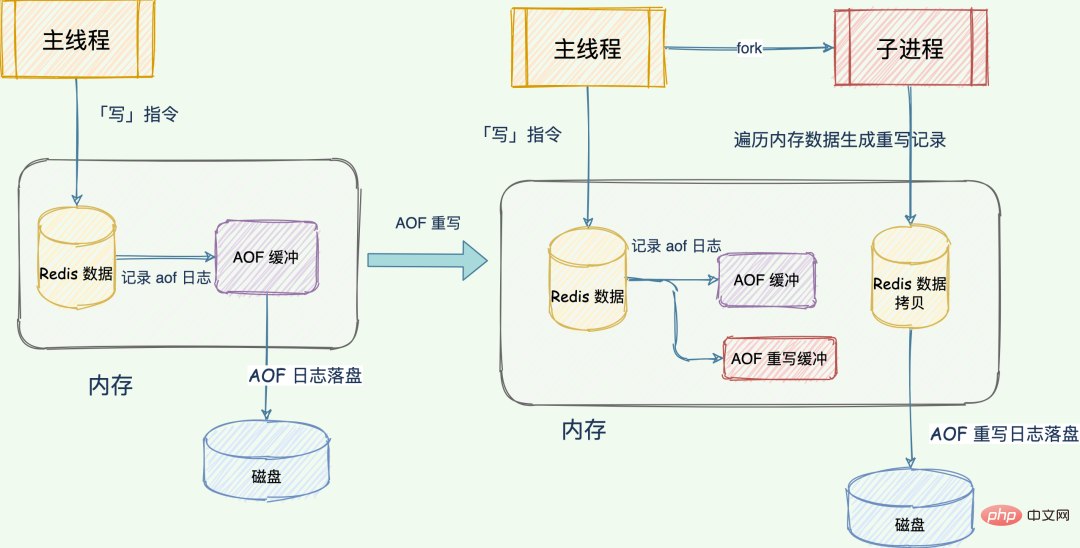
는 메인 스레드에 의해 다시 작성되는 AOF 로그와 다릅니다. 재작성 프로세스는 백그라운드 하위 프로세스인 bgrewriteaof에 의해 완료됩니다. 이는 또한 메인 스레드를 차단하고 데이터베이스 성능을 저하시키는 것을 방지하기 위한 것입니다.
일반적으로 로그는 메모리 데이터 복사본, 즉 기존 AOF 로그, 새로운 AOF 재작성 로그, Redis 데이터 복사본 총 2개가 있습니다.
Redis는 재작성 프로세스 중에 수신된 "쓰기" 명령 작업을 이전 AOF 버퍼와 AOF 재작성 버퍼에 동시에 기록하므로 재작성 로그에도 최신 작업이 저장됩니다. 복사된 데이터의 모든 작업 기록을 다시 쓴 후 다시 쓰기 버퍼에 기록된 최신 작업도 새 AOF 파일에 기록됩니다.
AOF가 다시 작성될 때마다 Redis는 먼저 메모리 복사를 수행하여 데이터를 탐색하여 다시 쓰기 레코드를 생성합니다. 두 개의 로그를 사용하여 다시 쓰기 프로세스 중에 새로 작성된 데이터가 손실되지 않고 데이터가 일관되게 유지되는지 확인합니다. .
"65 Brother: AOF rewriting에도 rewriting 로그가 있는데 왜 AOF 자체의 로그를 공유하지 않는 걸까요?
"
좋은 질문입니다. 다음 두 가지가 있습니다. 이유:
한 가지 이유는 상위 프로세스와 하위 프로세스 간에 동일한 파일을 작성하면 필연적으로 경쟁 문제가 발생하기 때문입니다. 경쟁을 제어한다는 것은 상위 프로세스의 성능에 영향을 미친다는 의미입니다.
AOF 다시 쓰기 프로세스가 실패하면 원본 AOF 파일은 오염된 것과 동일하므로 복원 및 사용할 수 없습니다. 따라서 Redis AOF는 새 파일을 다시 작성합니다. 다시 작성하지 못한 경우에는 파일을 직접 삭제하면 됩니다. 원본 AOF 파일에는 영향을 미치지 않습니다. 재작성이 완료되면 기존 파일을 교체하면 됩니다.
Redis 4.0 하이브리드 로그 모델
Redis를 다시 시작할 때 많은 데이터가 손실되므로 메모리 상태를 복원하기 위해 rdb를 거의 사용하지 않습니다. 우리는 주로 AOF 로그 재생을 사용하는데, AOF 로그 재생의 성능은 RDB에 비해 훨씬 느리기 때문에 Redis 인스턴스가 클 경우 시작하는 데 시간이 오래 걸립니다.
이 문제를 해결하기 위해 Redis 4.0에서는 하이브리드 지속성이라는 새로운 지속성 옵션을 제공합니다. 증분 AOF 로그 파일과 함께 rdb 파일의 내용을 저장합니다. 여기서 AOF 로그는 더 이상 전체 로그가 아니라 지속성 시작부터 지속성 종료까지의 기간 동안 발생한 증분 AOF 로그입니다. 일반적으로 AOF 로그의 이 부분은 매우 작습니다.
따라서 Redis가 다시 시작되면 먼저 rdb 콘텐츠를 로드한 다음 증분 AOF 로그를 재생할 수 있습니다. 이는 이전 AOF 전체 파일 재생을 완전히 대체할 수 있어 다시 시작 효율성이 크게 향상됩니다.
따라서 RDB 메모리 스냅샷은 약간 느린 빈도로 실행되며, AOF 로깅을 사용하여 두 RDB 스냅샷 중에 발생한 모든 "쓰기" 작업을 기록합니다.
이렇게 하면 스냅샷을 자주 실행할 필요가 없습니다. 동시에 AOF는 두 스냅샷 사이에 발생하는 "쓰기" 명령만 기록하면 되므로 과도한 파일 크기를 피하기 위해 모든 작업을 기록할 필요가 없습니다. .
요약
Redis는 스냅샷 실행 중 읽기 및 쓰기 명령에 대한 영향을 최대한 방지하기 위해 bgsave 및 쓰기 시 복사를 설계했습니다. 빈번한 스냅샷은 디스크에 부담을 주고 포크는 기본 스레드를 차단합니다.
Redis는 데이터 손실 없이 가동 중지 시간을 빠르게 복구할 수 있는 두 가지 주요 킬러 기능을 설계했습니다.
로그가 너무 커지는 것을 방지하기 위해 데이터베이스의 최신 데이터 상태에 따라 데이터 쓰기 작업이 새 로그로 생성되고 메인 스레드를 차단하지 않고 백그라운드에서 완료되는 AOF 다시 쓰기 메커니즘이 제공됩니다. .
AOF와 RDB를 통합하면 Redis 4.0에서 새로운 지속성 전략과 하이브리드 로그 모델이 제공됩니다. Redis가 다시 시작되면 먼저 rdb 콘텐츠를 로드한 다음 증분 AOF 로그를 재생할 수 있습니다. 이는 이전 AOF 전체 파일 재생을 완전히 대체할 수 있으며 다시 시작 효율성이 크게 향상됩니다.
마지막으로 AOF와 RDB 선택과 관련하여 "Code Byte"에는 세 가지 제안이 있습니다.
데이터가 손실될 수 없는 경우 메모리 스냅샷과 AOF를 혼합하여 사용하는 것이 좋습니다.
허용하는 경우; 분 수준의 데이터 손실은 RDB만 사용할 수 있습니다.
AOF만 사용하는 경우 신뢰성과 성능 간의 균형을 유지하므로 Everysec 구성 옵션을 우선적으로 사용하세요.
두 번의 Redis 기사 시리즈를 마치면 독자는 Redis에 대한 전반적인 이해를 갖게 될 것입니다.
위 내용은 Redis 로그: 빠른 복구를 위한 팁의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!