
충격! 하나의 SQL 문에 너무 많은 잠금이 있습니다 ...

- coldplay.xixi앞으로
- 2021-02-02 17:53:122944검색

권장(무료): SQL 튜토리얼
Gap 잠금과 행 잠금을 함께 사용하면 잠금 대기가 발생할지 여부를 판단하는 데 실수하기 쉽습니다.
간격 잠금은 반복 읽기 격리 수준에서만 효과적이므로 이 문서에서는 기본적으로 반복 읽기를 사용합니다.
잠금 규칙
- 원칙 1
잠금의 기본 단위는 열림과 닫힘 간격인 넥스트 키 잠금입니다. - 원칙 2
검색 과정에서 접근한 객체만 잠깁니다. - 최적화 1
인덱스에 대한 동등한 쿼리의 경우 고유 인덱스를 잠그면 다음 키 잠금이 행 잠금으로 변질됩니다. - 최적화 2
인덱스에 대한 동일 쿼리의 경우 오른쪽으로 순회하고 마지막 값이 동일 조건을 충족하지 않으면 다음 키 잠금이 간격 잠금으로 퇴화됩니다. - 버그
고유 인덱스에 대한 범위 쿼리는 조건을 충족하지 않는 첫 번째 값에 액세스합니다.
데이터 준비
테이블 이름: t
새 데이터: (0,0,0),(5,5,5),(10,10,10),(15,15,15), ( 20,20,20),(25,25,25)
다음 예는 기본적으로 그림 설명을 동반하므로 원고와 대조하여 읽어 보시기 바랍니다. 일부 예는 "세 가지 견해를 망칠" 수 있으므로 다음을 권장합니다. 기사를 읽은 후 직접 연습해 보세요.
Case
동일값 쿼리 간격 잠금
동일값 쿼리 간격 잠금

테이블 t에는 id=7이 없으므로 원칙 1에 따라 잠금 단위는 다음- 키 잠금, 따라서 세션 A의 잠금 범위 (5,10]
동시에 최적화 2에 따르면 동등한 쿼리(id=7)이지만 id=10이 만족되지 않으면 다음 키 lock은 gap lock으로 변질되므로 최종 잠금 범위는 (5,10)

따라서 세션 B가 id=8인 레코드를 이 gap에 삽입하면 잠기지만 세션 C는 다음과 같이 행을 수정할 수 있습니다. id=10.
비고유 인덱스에 해당합니다. Lock
비고유 인덱스에만 추가되는 잠금
세션 A는 c=5에 읽기 잠금을 추가해야 합니다. 인덱스 c의 행
원칙 1에 따르면 잠금 단위는 next-key 잠금이므로 (0,5]에 next-key 잠금을 추가합니다.
c는 일반 인덱스 이므로 레코드 c=5 에만 액세스할 수 없습니다. 즉시 중지, 오른쪽으로 이동하고 c=10을 찾은 경우에만 포기해야 합니다. 원칙 2에 따르면 액세스된 모든 항목은 잠겨 있어야 하므로 (5,10]에 다음 키 잠금을 추가합니다. 동시에 최적화 2: 동등성 판단을 충족하고 오른쪽으로 이동하며 마지막 값은 c=5의 동등성 조건을 충족하지 않으므로 간격 잠금(5,10)
원칙 2에 따르면, 액세스된 객체는 잠깁니다. 이 쿼리는 커버링 인덱스를 사용하고 기본 키 인덱스에 액세스할 필요가 없으므로 기본 키 인덱스에 잠금이 추가되지 않으므로 세션 B의 업데이트 문이 실행될 수 있습니다. C가 (7,7,7)을 삽입하려고 하면 세션 A의 간격 잠금(5,10)에 의해 잠깁니다. 이 예에서 공유 모드의 잠금은 포함 인덱스만 잠그지만 업데이트를 위해 실행하면 시스템은 다음에 데이터를 업데이트하려고 한다고 생각하므로 기본 키 인덱스의 조건을 충족하는 행에 행 잠금을 추가합니다.
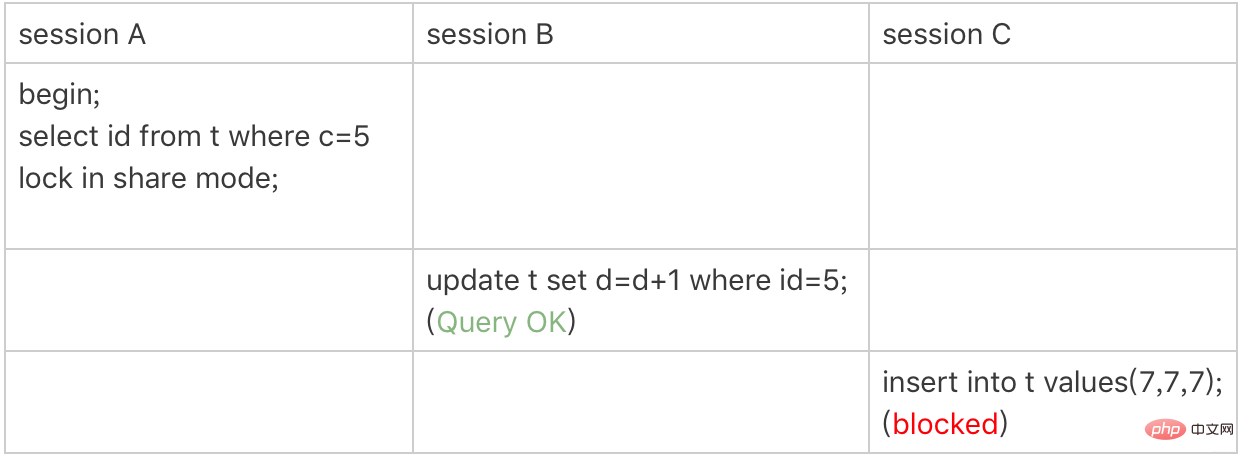
이 예는 다음과 같습니다. 동시에 인덱스에 잠금이 추가된다는 점을 설명합니다. 공유 모드에서 잠금을 사용하여 행에 읽기 잠금을 추가하여 데이터가 업데이트되는 것을 방지하려면 우회해야 한다는 지침이 제공됩니다. 커버링 인덱스의 최적화. 인덱스에 존재하지 않는 필드를 추가합니다. 예를 들어 공유 모드에서 c=5 잠금에서 d를 선택하도록 세션 A의 쿼리 문을 변경하면 효과를 직접 확인할 수 있습니다. 3 기본 키 인덱스 범위 잠금
Range 쿼리.
다음 두 쿼리 문은 동일한 잠금 범위를 갖나요? mysql> select * from t where id=10
mysql> * from t where id>=10 and id<11 for update;id가 int 유형으로 정의되므로 이 두 문장이 동일하다고 생각할 수도 있습니다. 사실, 그들은 완전히 동일하지 않습니다.
논리적으로 이 두 검색 문은 확실히 동일하지만 잠금 규칙은 다릅니다. 이제 세션 A가 두 번째 쿼리 문을 실행하여 잠금 효과를 살펴보겠습니다.
그림 3 기본 키 인덱스의 범위 쿼리에 대한 잠금
이제 앞서 언급한 잠금 규칙을 사용하여 세션 A에 어떤 잠금이 추가될지 분석해 보겠습니다.
따라서 이때 세션 A의 잠금 범위는 기본 키 인덱스, 행 잠금 id=10 및 다음 키 잠금(10,15]입니다. 이를 통해 세션 B와 세션 C의 결과를 이해할 수 있습니다.
여기서 주목해야 할 점은 첫 번째 세션 A에서 id=10인 행을 찾으면 등가 쿼리로 판단하고, id=15까지 오른쪽으로 스캔하면 범위로 판단한다는 것입니다. 쿼리
.범위 쿼리 잠금을 다시 보면 사례 3과 비교할 수 있습니다.
고유하지 않은 인덱스 범위 잠금
| session_1 | session_2 | session_3 |
|---|---|---|
| begin; t에서 *를 선택하세요 여기서 업데이트의 경우 c>=10 및 c<11입니다. | update t set d=d+1 여기서 c=15;(차단됨) | |
session1 c=10</을 사용하는 경우 code>를 사용하여 처음으로 레코드를 찾으려면 인덱스 c에 <code>(5,10] next-key lock이 추가됩니다. | c는 | 고유하지 않은 인덱스입니다. 최적화 규칙은 없습니다. 즉, 행 잠금 | 으로 변질되지 않습니다. 따라서 session1은 최종적으로 c
| 따라서 결과 관점에서 sesson2가 (8,8,8)의 삽입 문을 삽입하려고 하면 차단됩니다. | 고유하지 않은 인덱스는 c=15로 스캔되어야 합니다. 계속해서 뒤로 이동할 필요는 없습니다.
c=10定位记录时,索引c加了(5,10] next-key lock- c是非唯一索引,无优化规则,即不会退变为行锁
- 因此最终sesion1加锁为c的
(5,10]和(10,15]next-key lock。
所以从结果上来看,sesson2要插入(8,8,8)的这个insert语句时就被阻塞。
非唯一索引要扫到c=15,才知道无需继续往后遍历。
唯一索引范围锁bug
前四案例用到两个原则和两个优化,再看加锁规则bug案例。
| session_1 | session_2 | session_3 |
|---|---|---|
| begin; select * from t where id>10 and id<=15 for update; | ||
| update t set d=d+1 where id=20;(阻塞) | ||
| insert into t values(16,16,16);(阻塞) |
session1是范围查询
- 按原则1,索引id只加
(10,15] next-key lock,因为id是唯一键,所以循环判断到id=15这行就该停止遍历。
但实现上,InnoDB会继续扫描到第一个不满足条件的行,即id=20,且由于这是范围扫描,因此id上的(15,20] next-key lock也会被锁。
所以session2要更新id=20这行会被阻塞。
session3要插入id=16,也会被阻塞。
按理说锁住id=20这行没必要,因为唯一索引扫描到id=15即可确定不用继续遍历。但实现上还是这么做了,可能是个bug。
非唯一索引上存在"等值"的例子
为更好地说明“间隙”概念。
插入记录7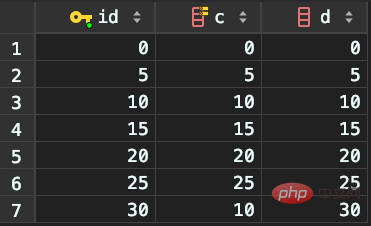
新插入的这一行c=10,即现在表里有两个c=10。那么,这时索引c上的间隙是什么状态了呢?
由于非唯一索引上包含主键的值,所以不可能存在“相同”两行。
但现在虽然有两个c=10,它们的主键值id却不同,因此这两个c=10记录之间也有间隙。
看如下案例。
6
delete加锁逻辑类似select ... for updatesession_1
| begin; | ||
|---|---|---|
|
업데이트 t | 세트 d =d+1 여기서 id=20;(blocking) |
|
| 따라서 session2가 id=20 행을 업데이트하려는 경우 차단됩니다. |
6 | 삭제 잠금 논리는 |
|---|---|
| session_2 session_3 |
|
| c=10 |
session1의 삭제 문에 제한 2가 추가되었습니다. 실제로 테이블 t에는 c=10인 레코드가 2개만 있으므로 제한 2를 추가하든 안 하든 삭제 효과는 동일하지만 잠금 효과는 다릅니다. Case 6의 결과와는 다르게 세션 B의 insert 문이 통과된 것을 확인할 수 있습니다.
이것은 Case 7의 삭제 문이 명확하게 제한 2의 제한을 추가했기 때문에 라인(c=10, id=30)으로 이동한 후 이미 조건을 충족하는 두 개의 명령문이 있고 루프가 종료되기 때문입니다.
따라서 인덱스 c의 잠금 범위는 아래 그림과 같이 (c=5, id=5)에서 (c=10, id=30)까지 전면 열림 및 후면 닫힘 간격이 됩니다.
제한 2
의 잠금 효과를 보면 (c=10, id=30) 이후의 간격이 잠금 범위에 있지 않으므로 c=12를 삽입하는 insert 문이 성공적으로 실행될 수 있습니다.
우리 실습에서 이 예의 중요한 의미는 데이터를 삭제할 때 제한을 추가하려고 시도하는 것입니다. 이는 삭제된 데이터의 수를 제어하여 작업을 보다 안전하게 할 뿐만 아니라 잠금 범위를 줄여줍니다.
교착상태 예시
이전 예시에서는 분석할 때 next-key lock의 로직에 따라 분석했는데, 이렇게 분석하는 것이 더 편리하기 때문입니다. 마지막으로 설명하기 위해 또 다른 사례를 살펴보겠습니다. 다음 키 잠금은 실제로 간격 잠금과 행 잠금의 합계 결과입니다.
이런 컨셉이 처음에도 언급되지 않았는지 궁금하시죠? 걱정하지 마세요. 다음 예를 먼저 살펴보겠습니다.
케이스 8
session A의 작업 순서 A. 트랜잭션 시작 후 쿼리 문을 실행하고 공유 모드에서 잠금을 추가한 후 next-key를 추가합니다. lock(인덱스 c의 5,10] 및 갭 잠금(10,15);
세션 B의 업데이트 문은 또한 인덱스 c에 다음 키 잠금(5,10]을 추가하고 잠금 대기를 입력해야 합니다.
그런 다음 세션 A는 (8,8,8)을 삽입해야 합니다. 이 줄은 세션 B의 갭 잠금으로 인해 잠겨 있습니다. 교착 상태로 인해 InnoDB는 세션 B를 롤백합니다.
세션의 다음 키 잠금이 아닌가? B가 성공적으로 적용되었나요?
실제로 세션 B의 "다음 키 잠금 추가(5,10]" 작업은 실제로 두 단계로 나누어집니다. 먼저 (5,10)의 간격 잠금을 추가합니다. 잠금이 성공하면 c=10을 추가합니다. 이때 행 잠금이 잠깁니다. 즉, 다음 키 잠금을 사용하여 잠금 규칙을 분석할 수 있지만 특정 실행 중에는 갭 잠금으로 나누어야 하며 행 잠금은 2단계로 실행됩니다.요약
모든 경우는 반복 읽기에서 확인됩니다. 모든 잠긴 리소스는 2단계 잠금 프로토콜을 따릅니다. 마지막 경우에는 실제로 next-key 잠금이 gap 잠금과 row 잠금으로 구현된다는 것을 확실히 알 수 있는데, 읽기 커밋 격리 수준으로 전환하면 gap 잠금 부분이 제거되어 이해하기 쉽습니다. 그 과정에서 행 잠금 부분만 남습니다. 읽기 커밋 격리 수준 아래에는 또 다른 최적화가 있습니다. 즉, 문 실행 중에 행 잠금이 추가되는 것입니다. "조건을 충족하지 않는 행"에서는 트랜잭션이 커밋될 때까지 기다리지 않고 직접 해제해야 합니다. 읽기-커밋 격리 수준에서는 잠금 범위가 작고 잠금 시간이 짧아서 많은 기업에서도 사용합니다.
SQL
무료 칼럼~~을 참조하세요.
위 내용은 충격! 하나의 SQL 문에 너무 많은 잠금이 있습니다 ...의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!