
Redis 학습 NoSQL 소개

- coldplay.xixi앞으로
- 2021-02-02 17:44:462238검색

추천(무료): redis 입문 튜토리얼
1. 인터넷 시대의 큰 기회, NoSQL을 사용해야 하는 이유
1.1 독립형 MySQL의 좋은 시대
In 1990년대에는 일반적으로 웹사이트 방문 횟수가 많지 않으며 단일 데이터베이스로 쉽게 처리할 수 있습니다.
당시에는 대부분 정적인 웹페이지였고, 동적인 대화형 웹사이트는 많지 않았습니다. 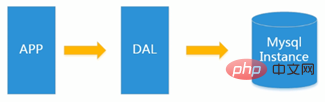
DAL dal은 Data Access Layer의 영어 약어인 Data Access Layer
위의 아키텍처에서 데이터 저장의 병목 현상은 무엇인지 살펴보겠습니다.
1. DAL 당 데이터 볼륨의 전체 크기 머신이 맞지 않을 때
2. 데이터 인덱스(B+ Tree)가 머신의 메모리에 저장되지 않을 때
3. 하나의 인스턴스가 허용할 수 없는 접속량(읽기와 쓰기 혼합)이 있을 때
1~3개일 경우 위 사항이 충족되면 진화합니다...
1.2.Memcached(캐시) + MySQL + 수직 분할
이후 방문자 수가 증가하면서 MySQL 아키텍처를 사용하는 대부분의 웹 사이트에서 데이터베이스 성능 문제가 발생하기 시작했습니다. 프로그램은 더 이상 기능에만 초점을 맞추지 않고 성능도 추구합니다. 프로그래머들은 데이터베이스에 대한 부담을 완화하고 데이터베이스의 구조와 인덱스를 최적화하기 위해 캐싱 기술을 광범위하게 사용하기 시작했습니다. 처음에는 파일 캐싱을 사용하여 데이터베이스 부담을 완화하는 것이 더 인기를 얻었지만 방문 횟수가 계속 증가하면 파일 캐싱을 통해 여러 웹 시스템을 공유할 수 없으며 많은 수의 작은 파일 캐시도 상대적으로 높은 IO를 가져옵니다. 압력. 이때 Memcached는 자연스럽게 매우 패셔너블한 기술 제품이 되었습니다.
기존 dao 레이어가 데이터베이스에 직접 접근하는 것과 동일하며, 이제 중간에 캐시 레이어가 삽입됩니다. 데이터베이스에 자주 액세스하면 성능 저하가 발생하므로 부담을 줄이기 위해 일부 콘텐츠를 캐시에 넣습니다. 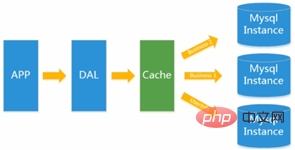
데이터베이스에 대한 쓰기 압력이 증가했기 때문에
Memcached는 데이터베이스에 대한 읽기 압력만 완화할 수 있습니다. 하나의 데이터베이스에 읽기와 쓰기가 집중되면 데이터베이스가 압도됩니다. 대부분의 웹사이트에서는 읽기 및 쓰기 성능과 읽기 데이터베이스의 확장성을 향상시키기 위해 읽기와 쓰기를 분리하는 마스터-슬레이브 복제 기술을 사용하기 시작했습니다. Mysql의 마스터-슬레이브 모드는 현재 웹사이트의 표준이 되었습니다. 설명: 기본 라이브러리에 레코드 업데이트가 있습니다. 데이터 무결성을 보장하려면 슬레이브 라이브러리에 복사해야 합니다. 읽기 및 쓰기 분리: 마스터/슬레이버. 마스터 라이브러리에 쓰기 작업을 배치하고 슬레이브 라이브러리에 읽기 작업을 배치할 수 있습니다. 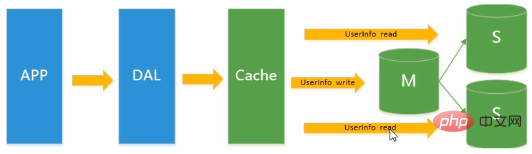
1.4. 테이블 및 데이터베이스 분할 + 수평 분할 + mysql 클러스터
Memcached의 캐시를 기반으로 MySQL의 마스터-슬레이브 복제 및 읽기-쓰기 분리, 이때 MySQL 기본 데이터베이스의 쓰기 압력이 시작됩니다. 병목 현상이 나타나고
데이터 양이 계속해서 급증합니다.MyISAM은 테이블 잠금을 사용하므로 높은 동시성에서 심각한 잠금 문제가 발생할 수 있으며 많은 동시성 MySQL 애플리케이션이 MyISAM 대신 InnoDB 엔진을 사용하기 시작했습니다. . 동시에 쓰기 부담과 데이터 증가로 인한 확장 문제를 완화하기 위해 하위 테이블과 하위 데이터베이스를 사용하는 것이 인기를 얻었습니다. 이때 서브테이블과 서브데이터베이스는 대중적인 기술이 되었고, 면접질문의 인기를 끌며 업계에서 뜨거운 기술이슈가 되었습니다. 이때 MySQL은 아직 안정되지 않은 테이블 파티션을 출시했는데, 이는 평균적인 기술력을 가진 기업들에게도 희망을 안겨주었습니다. MySQL이 MySQL 클러스터 클러스터를 출시했지만 그 성능은 인터넷 요구 사항을 잘 충족할 수 없지만 높은 안정성 측면에서 매우 큰 보장만 제공합니다.
테이블 잠금과 행 잠금?
하위 라이브러리 및 하위 테이블 1-3000이 1번 라이브러리에 들어갑니다. 3001-6000은 창고 2로 이동합니다. 잠깐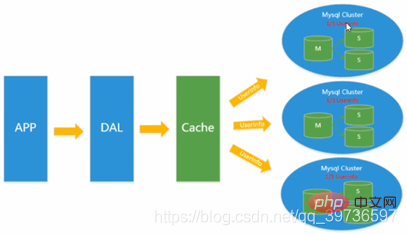
1.5. MySQL 확장성 병목현상
MySQL 데이터베이스는 종종 큰 텍스트 필드를 저장하므로 데이터베이스 테이블이 매우 커지므로 데이터베이스 복구가 매우 느리고 데이터베이스를 빠르게 복원하기가 어렵습니다. 예를 들어, 4KB 텍스트 1천만 개는 크기가 40GB에 가깝습니다. 이 데이터를 MySQL에서 생략할 수 있다면 MySQL은 매우 작아질 것입니다. 관계형 데이터베이스는 강력하지만 모든 애플리케이션 시나리오에 대처할 수는 없습니다. MySQL은 확장성이 좋지 않고(복잡한 기술이 필요함) 빅 데이터에 대한 높은 IO 부담, 테이블 구조 변경의 어려움 등이 현재 MySOL을 사용하는 개발자들이 직면한 문제입니다.
1.6. 오늘은 어떤 모습인가요?
Firewall-nginx-Tomcat 클러스터
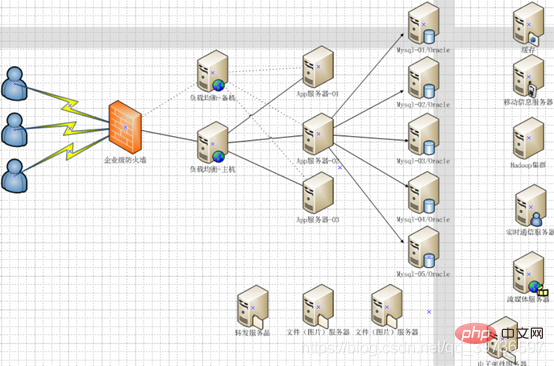
1.7.
오늘날 우리는 제3자 플랫폼(예: Google, Facebook 등)을 통해 데이터에 쉽게 액세스하고 데이터를 캡처할 수 있습니다. 사용자의 개인정보, 소셜 네트워크, 지리적 위치, 사용자 생성 데이터 및 사용자 작업 로그가 기하급수적으로 증가했습니다. 이러한 사용자 데이터를 마이닝하려는 경우 SQL 데이터베이스는 더 이상 이러한 애플리케이션에 적합하지 않습니다. 그러나 NoSQL 데이터베이스를 개발하면 이러한 대규모 데이터를 매우 잘 처리할 수 있습니다. 
2. "단지 SQL이 아님"을 의미하는
NoSQL(NoSQL = Not Only SQL)이란 일반적으로 비관계형 데이터베이스를 의미합니다. 인터넷 web2.0 웹사이트의 등장으로 전통적인 관계형 데이터베이스는 web2.0 웹사이트, 특히 초대형 및 동시성 SNS 유형 web2.0 순수 동적 웹사이트에 대처할 수 없게 되어 극복할 수 없는 많은 문제를 노출시켰습니다. 데이터베이스는 그 자체의 특성으로 인해 매우 빠르게 발전해 왔습니다. NoSQL 데이터베이스는 대규모 데이터 수집과 다양한 데이터 유형으로 인한 문제, 특히 초대형 데이터 저장을 포함한 빅데이터 애플리케이션 문제를 해결하기 위해 만들어졌습니다.
(예: Google 또는 Facebook은 사용자를 위해 매일 수조 비트의 데이터를 수집합니다). 이러한 유형의 데이터 저장소에는 고정된 스키마가 필요하지 않으며 중복 작업 없이 확장할 수 있습니다.
3. 할 수 있는 일
확장 용이
NoSQL 데이터베이스에는 여러 유형이 있지만 공통적인 특징은 관계형 데이터베이스의 관계형 특성을 제거한다는 것입니다. 데이터 간의 관계가 없으므로 확장이 매우 쉽습니다. 또한 아키텍처 수준에서 확장성 기능을 눈에 보이지 않게 제공합니다.
대량 데이터 볼륨에 대한 고성능
NoSQL 데이터베이스는 읽기 및 쓰기 성능이 매우 높으며, 특히 대용량 데이터 볼륨에서도 성능이 좋습니다.
이는 비관계형 특성과 단순한 데이터베이스 구조 때문입니다.
일반적으로 MySQL은 테이블이 업데이트될 때마다 캐시가 무효화됩니다. web2.0에서 상호 작용이 빈번한 애플리케이션에서는 캐시 성능이 높지 않습니다.
NoSQL의 캐시는 레코드 수준의 세분화된 캐시이므로 NoSQL은 이 수준에서 훨씬 더 높은 성능을 발휘합니다.
다양하고 유연한 데이터 모델
NoSQL은 저장할 데이터에 대한 필드를 미리 만들 필요가 없으며 언제든지 사용자 정의된 데이터 형식을 저장할 수 있습니다.
관계형 데이터베이스에서 필드를 추가하고 삭제하는 것은 매우 번거로운 일입니다. 매우 많은 양의 데이터가 포함된 테이블인 경우 필드를 추가하는 것은 그야말로 악몽입니다.
기존 RDBMS VS NOSQL
RDBMS
고도로 조직화된 구조적 데이터
구조적 쿼리 언어(SQL)
데이터와 관계가 별도의 테이블에 저장됨
데이터 조작 언어, 데이터 정의 언어
엄격한 일관성
기본 트랜잭션
NoSQL
SQL 그 이상의 의미
선언적 쿼리 언어 없음
사전 정의된 스키마 없음
키-값 저장소, 열 저장소, 문서 저장소, 그래프 데이터베이스
ACID 속성이 아닌 최종 일관성
구조화되지 않고 예측할 수 없는 데이터:
CAP 정리
고성능, 고가용성 및 확장성
4. NoSQL이란
Redis(데이터 유형 및 캐시, 모든 측면에서 우수함)
Memcached(캐시)
MongDB(관계형 데이터베이스와 가장 유사)
5.
KV Cache
Persistence
3V + 3 High
3V 빅 데이터 시대: 대용량
다양성
실시간 속도
시스템의 일부 문제에 대한 설명, Taobao Double Eleven의 대규모 데이터. 웨이보, 텍스트 필드, 비디오 필드, 배경 필드 등 다각화. 12306은 실시간 요구 사항이 높습니다. 절대 실시간은 불가능합니다
높은 동시성
높은 확장성
고성능
시스템은 12306과 같은 높은 동시성을 지원해야 합니다. 스레드를 얻는 네 가지 방법.
수평 및 수직 확장성. 수평적으로 한 대의 기계로 충분하지 않으면 기계를 더 추가하십시오.
고성능 요구 사항
더 많은 관련 학습 내용을 보려면 redis 칼럼을 방문하세요. .
위 내용은 Redis 학습 NoSQL 소개의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!