
ThinkPHP 데이터베이스 작업 저장 프로시저, 데이터 세트, 분산 데이터베이스

- 藏色散人앞으로
- 2021-01-28 17:15:232331검색
다음 튜토리얼 칼럼인 thinkphp에서는 ThinkPHP 데이터베이스 작업의 저장 프로시저, 데이터 세트, 분산 데이터베이스에 대해 소개하겠습니다. 도움이 필요한 친구들에게 도움이 되길 바랍니다!

저장 프로시저
5.0은 저장 프로시저 sp_query를 정의하는 경우 다음과 같은 방법으로 호출할 수 있습니다.
$result = Db::query('call sp_query(8)');
2차원 배열을 반환합니다. 예를 들어 매개변수 바인딩을 사용할 수 있습니다.
$result = Db::query('call sp_query(?)',[8]);
// 或者命名绑定$result = Db::query('call sp_query(:id)',['id'=>8]);
dataset
데이터베이스의 쿼리 결과도 데이터 세트입니다. 기본 구성에서 데이터 세트 유형은 2차원 배열입니다. 이를 데이터 세트 클래스로 구성할 수 있으며 데이터 세트에 대해 더 많은 객체 기반 작업을 지원할 수 있습니다. 데이터 세트 클래스 함수를 사용해야 합니다. 다음과 같이 데이터베이스의 resultset_type 매개변수를 구성할 수 있습니다. 데이터셋 객체는 thinkCollection으로 배열과 동일한 사용법을 제공하며, 추가적으로 몇 가지 메소드가 캡슐화되어 있습니다. 배열을 사용하여 데이터 세트 객체를 직접 조작할 수 있습니다. 예:
return [ // 数据库类型 'type' => 'mysql', // 数据库连接DSN配置 'dsn' => '', // 服务器地址 'hostname' => '127.0.0.1', // 数据库名 'database' => 'thinkphp', // 数据库用户名 'username' => 'root', // 数据库密码 'password' => '', // 数据库连接端口 'hostport' => '', // 数据库连接参数 'params' => [], // 数据库编码默认采用utf8 'charset' => 'utf8', // 数据库表前缀 'prefix' => 'think_', // 数据集返回类型 'resultset_type' => 'collection',];데이터 세트가 비어 있는지 판단하려면 비어 있음을 직접 사용하여 판단할 수 없지만 isEmpty를 사용해야 합니다. 판단할 데이터 세트 객체의 메소드(예:
// 获取数据集
$users = Db::name('user')->select();
// 直接操作第一个元素
$item = $users[0];
// 获取数据集记录数
$count = count($users);
// 遍历数据集
foreach($users as $user){ echo $user['name']; echo $user['id'];
}Collection 클래스에는 다음과 같은 주요 메소드가 포함되어 있습니다.
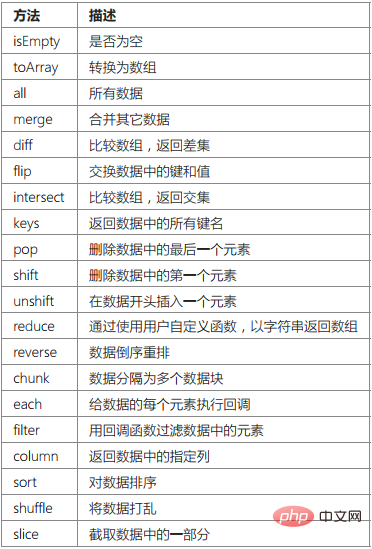 개별 데이터만 쿼리하여 데이터 세트 객체를 반환해야 하는 경우
개별 데이터만 쿼리하여 데이터 세트 객체를 반환해야 하는 경우
$users = Db::name('user')->select();if($users->isEmpty()){ echo '数据集为空';
}
를 사용할 수 있습니다.) 분산 데이터베이스ThinkPHP에는 마스터-슬레이브 데이터베이스의 읽기-쓰기 분리를 포함하여 분산 데이터베이스에 대한 배포 지원이 내장되어 있지만 분산 데이터베이스는 데이터베이스 유형이 동일해야 합니다.
분산 데이터베이스 지원을 사용하려면 Database.deploy를 1로 구성하세요. 분산 데이터베이스를 사용하는 경우 데이터베이스 구성 정보를 정의하는 방법은 다음과 같습니다.
Db::name('user') ->fetchClass('\think\Collection') ->select();
연결된 데이터베이스 수는 호스트 이름 정의 수에 따라 달라지므로 동일한 IP 2개라도 반복적으로 정의해야 하지만 다른 매개변수가 있는 경우 동일합니다. 정의를 반복할 필요가 없습니다. 예를 들어
//分布式数据库配置定义 return [ // 启用分布式数据库 'deploy' => 1, // 数据库类型 'type' => 'mysql', // 服务器地址 'hostname' => '192.168.1.1,192.168.1.2', // 数据库名 'database' => 'demo', // 数据库用户名 'username' => 'root', // 数据库密码 'password' => '', // 数据库连接端口 'hostport' => '',]
와
'hostport'=>'3306,3306'
는 동일합니다.
'hostport'=>'3306'
와
'username'=>'user1', 'password'=>'pwd1',
는 동일합니다.
분산 데이터베이스의 읽기와 쓰기가 분리되어 있는지도 설정할 수 있습니다. 기본적으로 읽기와 쓰기가 분리되지 않습니다. 즉, 마스터-슬레이브 데이터베이스의 경우 각 서버에서 읽기 및 쓰기 작업을 수행할 수 있어야 합니다. 읽기 및 쓰기 분리를 설정하려면 다음 설정으로 충분합니다.
'username'=>'user1,user1', 'password'=>'pwd1,pwd1',
읽기-쓰기 분리의 경우 기본 첫 번째 데이터베이스 구성은 데이터 쓰기를 담당하는 메인 서버의 구성 정보입니다. master_num 매개변수가 설정되면 여러 주 서버에 쓰기가 지원될 수 있습니다. 다른 사람은 데이터베이스의 구성 정보에서 데이터를 읽는 역할을 담당하며 그 수에는 제한이 없습니다. 슬레이브 서버에 연결하고 읽기 작업을 수행할 때마다 시스템은 슬레이브 서버에서 무작위로 선택합니다.
slave_no를 설정하여 읽기 작업을 위한 서버를 지정할 수도 있습니다.
슬레이브 데이터베이스 연결에 오류가 있으면 자동으로 메인 데이터베이스 연결로 전환됩니다.
모델의 CURD 작업을 호출하면 시스템은 현재 실행되는 메서드가 읽기 작업인지 쓰기 작업인지 자동으로 결정합니다. 기본 SQL을 사용하는 경우 시스템의 기본 규칙에 주의해야 합니다.
쓰기 작업은 모델의 실행 메서드를 사용해야 하고, 읽기 작업은 모델의 쿼리 메서드를 사용해야 합니다. 그렇지 않으면 마스터-슬레이브 읽기 및 쓰기 혼란이 발생합니다.
참고: 마스터-슬레이브 데이터베이스의 데이터 동기화 작업은 프레임워크에서 구현되지 않으며 데이터베이스는 자체 동기화 또는 복제 메커니즘을 고려해야 합니다.위 내용은 ThinkPHP 데이터베이스 작업 저장 프로시저, 데이터 세트, 분산 데이터베이스의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!