
집 >데이터 베이스 >MySQL 튜토리얼 >빅데이터 학습을 위한 MYSQL 고급
빅데이터 학습을 위한 MYSQL 고급

- coldplay.xixi앞으로
- 2021-01-27 09:48:442463검색
무료 학습 권장 사항: mysql 비디오 튜토리얼
문서 디렉토리
- 1 성능에 영향을 미치는 여러 측면
- 1.1 하드웨어 측면
- 1.2 서버 시스템
- 1.3 데이터베이스 스토리지 엔진 Selection
- 1.4 데이터베이스 매개변수 구성
- 1.5 데이터베이스 구조 설계 및 SQL 문(키)
- 2 하드웨어 측면
- 2.1 CPU 리소스 및 사용 가능한 메모리 크기
- 2.1.1 CPU 선택 방법
- 2.1.2 메모리
- 2.1.2.1 일반적으로 사용되는 MySQL 스토리지 엔진
- 2.1.2.2 팁
- 2.1.2.3 메모리 선택 방법
- 2.2 디스크 구성 및 선택
- 2.2. 1 사용 기존 머신 하드 디스크
- 2.2.2 RAID를 사용하여 기존 머신 하드 디스크의 성능 향상
- 2.2.2.1 RAID란 무엇입니까
- 2.2.2.2 RAID 레벨
- 2.2.2.2.1 RAID 0
- 2.2.2.2.2 RAID 1
- 2.2.2.2.3 RAID 5 - 공통 RAID 그룹
- 2.2.2.2.4 RAID 10 - 일반적으로 사용되는 RAID 그룹
- 2.2.2.3 RAID 레벨 선택
- 2.2. 3 솔리드 스테이트 스토리지 SSD 및 PCIe 카드 사용
- 2.2.4 네트워크 스토리지 NAS 및 SAN 사용
-
- 2.2.4.1 네트워크 스토리지 사용 시나리오
- 2.2.4.2 네트워크 성능 제한
- 2.2.4.3 네트워크 성능 영향
- 2.3 요약
- 3 운영 체제가 성능에 미치는 영향
- 3.1 CentOS 시스템 매개변수 최적화
- 4 파일 시스템이 성능에 미치는 영향
- 5 MySQL 아키텍처
1 여러 측면 그 성능에 영향
1.1 하드웨어 측면
일반적으로 개인용 컴퓨터는 컴퓨터 하드웨어 문제, 일반적으로 CPU, 메모리, 디스크 IO 등과 같은 요인 때문에 느리다고 말합니다. 또한 이런 문제가 발생하게 됩니다.
1.2 서버 시스템
일반적으로 개인용 컴퓨터의 운영 체제는 Windows입니다. Windows 시스템의 버전에 따라 성능이 다르거나 특정 매개변수가 다른 성능을 유발하도록 구성됩니다. 이는 서버 시스템에서도 마찬가지이며, 매개변수 설정도 서버 성능에 영향을 미칩니다.
1.3 데이터베이스 스토리지 엔진 선택
MySQL에는 플러그인 스토리지 엔진이 있으며 다양한 비즈니스 요구에 따라 다양한 스토리지 엔진을 선택할 수 있습니다.
스토리지 엔진마다 특성도 다릅니다.
- MyISAM: 트랜잭션 및 테이블 수준 잠금을 지원하지 않습니다.
- InnoDB: 트랜잭션 수준 스토리지 엔진으로 행 수준 잠금 및 트랜잭션 ACID 기능을 완벽하게 지원합니다.
1.4 데이터베이스 매개변수 구성
스토리지 엔진마다 매개변수 구성이 다릅니다. 일부 매개변수는 스토리지 엔진에 최소한의 영향을 미치지만 일부 매개변수는 성능에 결정적인 역할을 합니다. 따라서 선택한 스토리지 엔진과 다양한 비즈니스 요구 사항을 기반으로 매개변수를 최적화하는 것도 중요합니다.
1.5 데이터베이스 구조 설계 및 SQL 문(핵심 사항)
데이터베이스 구조를 설계할 때, 테이블 구조를 쿼리하고 업데이트하기 위해 향후 데이터베이스에서 어떤 종류의 SQL 문을 실행할지 고려해야 합니다. 유일한 방법입니다. 그래야만 요구 사항을 충족하는 테이블 구조를 디자인할 수 있습니다.
느린 쿼리의 경우 성능 저하의 주범이며, 이는 데이터베이스 테이블 구조의 불합리한 설계로 인해 발생합니다. 이러한 유형의 SQL은 프로젝트가 온라인 상태가 되면 데이터베이스 테이블 구조를 수정하기 어렵기 때문에 최적화하기가 가장 어렵습니다.
그래서 데이터베이스 성능 최적화에 중점을 두는 것은 다음과 같습니다.
데이터베이스 테이블 구조 설계
SQL 문 작성 및 최적화
다음은 각 측면에 대한 자세한 설명입니다.
2 하드웨어 측면
2.1 CPU 리소스 및 사용 가능한 메모리 크기
2.1.1 CPU 선택 방법
일반적으로 CPU를 선택할 때 우리 모두는 CPU의 주파수와 코어 수를 희망합니다. CPU는 최대한 높겠지만, 비용이나 여러 가지 요인으로 인해 둘 중 하나만 선택해야 하는 경우가 많습니다. 그렇다면 최선의 솔루션을 어떻게 선택해야 할까요? 따라서 CPU를 구매할 때 다음과 같은 몇 가지 문제에 주의를 기울여야 합니다.
- 우리 애플리케이션은 CPU를 많이 사용하나요?
- 애플리케이션이 CPU를 많이 사용하는 경우 SQL 처리 속도를 높이려면 더 많은CPU가 아닌 더 나은CPU가 필요합니다.
- 현재 MySQL의 경우 duoCPU는 동일한 SQL의 동시 처리를 지원하지 않습니다.
- 우리 시스템의 동시성은 무엇인가요?
- 시스템에 더 많은 처리량이 필요한 경우 CPU가 많을수록 좋습니다. CPU가 40개 있다고 가정하면 동시에 40개의 SQL을 처리할 수 있습니까?
- 데이터베이스 처리 능력 측정: QPS, 동시에 처리되는 SQL 수를 나타냅니다. 그런데 이 지표는 1초에 처리된 SQL의 개수인데, 앞선 시점에서 설명한 동시 처리는 나노초 차원이다.
- MySQL은 일반적으로 웹 애플리케이션에 사용되며 동시성 양이 상대적으로 큰 경우가 많습니다. 이때 CPU 주파수보다 CPU 수가 더 중요합니다.
- 우리가 사용하는 MySQL 버전
- 버전 5.0 이전에는 MySQL이 멀티코어 CPU를 제대로 지원하지 못했고, 현재 버전인 5.6, 5.7에서는 멀티코어 지원이 매우 심각했습니다. - 코어 CPU가 좋지 않습니다. 지원이 크게 개선되었습니다. 따라서 더 나은 성능을 얻으려면 최신 버전의 MySQL을 사용하는 것이 좋습니다.
- 32비트 또는 64비트 CPU를 선택하시겠습니까?
- 현재 서버 CPU는 기본적으로 모두 64비트 아키텍처이지만, 64비트 시스템 위에 32비트 서버 버전이 설치되어 있는지 확인하는 것이 주의가 필요합니다. 이는 서버 성능에 심각한 영향을 미칠 수 있습니다.
2.1.2 메모리
메모리 크기는 데이터베이스 성능에 직접적인 영향을 미칩니다. 현재 메모리는 디스크보다 훨씬 효율적입니다. 따라서 데이터를 메모리에 캐싱하면 서버 성능이 크게 향상될 수 있습니다.
2.1.2.1 일반적으로 사용되는 MySQL 스토리지 엔진
일반적으로 사용되는 스토리지 엔진에는 MyISAM과 InnoDB 두 가지가 있습니다.
MyISAM:
인덱스는 메모리에 저장되고 데이터는 하드디스크에 저장됩니다. 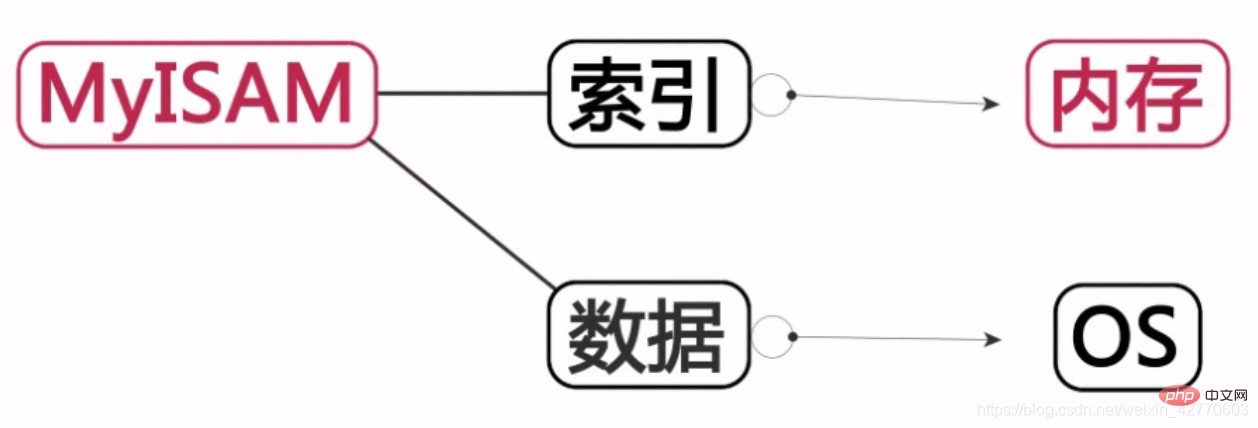
InnoDB:
인덱스와 데이터 모두 메모리에 저장되므로 데이터베이스의 운영 효율성이 향상됩니다. 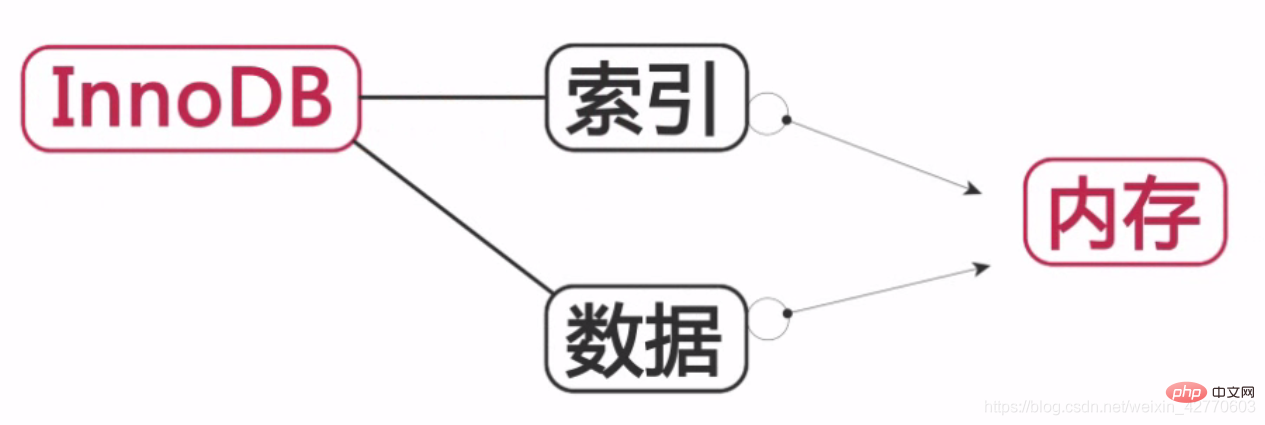
2.1.2.2 팁
- 메모리가 많을수록 좋지만 시스템 성능에 미치는 영향은 제한적입니다.
데이터베이스의 데이터가 100G인 경우 128G 정도의 메모리를 선택하면 최대 성능을 얻을 수 있습니다. 이때 모든 데이터가 핫 데이터인 경우 메모리에 캐시할 필요가 없습니다. 256G 메모리를 선택하지만 더 큰 메모리를 선택하면 운영 체제와 같은 다른 서비스의 성능도 향상되므로 단기간에 메모리 업그레이드를 고려할 필요가 없습니다. - 메모리 캐시에서의 쓰기 작업의 경우 쓰기를 지연하여 데이터베이스에 대한 부담을 줄일 수 있습니다.
메모리는 이미 읽기 작업을 잘 지원하고 있으며 쓰기 작업도 메모리에서 완료할 수 있습니다. 결국 디스크에 데이터를 써야 하지만 디스크에 쓰는 것을 피할 수는 없지만 쓰기 작업을 지연하고 여러 쓰기를 하나로 병합할 수 있습니다. 데이터베이스에 대한 부담을 줄이기 위해 작성합니다. 데이터베이스는 여러 쓰기 작업을 캐시 풀에서 하나로 병합하고 최종적으로 디스크에 쓸 수 있는 유사한 기능을 제공합니다.
2.1.2.3 메모리 선택 방법
마더보드가 최대 주파수
- 를 지원할 수 있는 메모리를 사용해 업그레이드를 구성하세요. 각 채널의 메모리는 동일한 브랜드여야 합니다. 입자, 주파수, 전압, 검증 기술 및 모델.
- 데이터베이스 크기에 따라 메모리를 선택하세요.
2.2 디스크 구성 및 선택
메모리는 데이터베이스 성능에 큰 역할을 하지만 IO 하위 시스템이 성능에 미치는 영향을 무시할 수는 없습니다. 현재 우리는 일반적으로 다음 4가지 유형의 디스크 옵션을 사용합니다.
2.2.1 기존 시스템 하드 드라이브 사용
특징: 큰 저장 공간, 저렴한 가격, 가장 많이 사용됨, 가장 일반적, 느린 읽기 및 쓰기
- 전통적인 기계 기계 하드 드라이브를 선택하는 방법은 무엇입니까? storage 용량의 원인 변환 속도 속도 액세스 타임 핀들 속도 속도
- 2.2.2 RAID를 사용하여 전통적인 기계 하드 드라이브의 성능을 향상 시키십시오 .2.2.2.1 RAID는 무엇입니까?
- RAID는 Redundant Arrays of Independent Disks의 약어입니다. 간단히 말해서 RAID의 기능은 더 작은 용량의 여러 디스크를 더 큰 용량의 디스크 그룹으로 결합하고 데이터 무결성을 보장하는 기술입니다.
2.2.2.2 RAID 레벨
2.2.2.2.1 RAID 0RAID 0은 데이터 스트라이핑이라고도 하는 최초의 RAID 모드입니다. 구성요소 디스크 어레이 중 가장 간단한 형태입니다. 2개 이상의 하드 디스크만 있으면 됩니다. 비용이 저렴하고 전체 디스크의 성능과 처리량을 향상시킬 수 있습니다. RAID 0은 중복성 또는 오류 복구 기능을 제공하지 않지만 구현 비용이 가장 저렴합니다. 그러나 데이터 복구 및 신뢰성 요소를 고려할 때 RAID 0에는 중복성이 없고 단일 디스크보다 데이터 손상 확률이 높기 때문에 가장 비용이 많이 드는 구성이 되었습니다. 디스크의 데이터 손상으로 인해 데이터가 손실되기 때문입니다. 예를 들어, 3개의 디스크로 구성된 RAID 0은 단일 하드 디스크보다 손상될 가능성이 3배 더 높습니다. 따라서 RAID 0은 언제든지 다른 데이터베이스에서 복제할 수 있는 대기 데이터베이스 또는 일회성 사용만 필요한 일부 데이터베이스와 같이 단일 데이터가 손실되지 않는 상황에 적합합니다. 간단히 말해서 RAID 0은 하드 드라이브를 직렬로 연결하여 다음과 같이 더 큰 디스크를 형성하는 것입니다. RAID 0과의 차이점은 중간에 등호가 있다는 점입니다. 두 디스크의 데이터는 동일하고 중복성도 좋지만 그에 따라 비용이 증가합니다. 디스크 오류가 발생하면 정상적으로 실행될 수 있지만 오류가 발생한 디스크를 교체해야 합니다. 그렇지 않으면 시스템이 충돌합니다. 새 디스크를 교체한 후 데이터 동기화에 많은 시간이 소요되지만 데이터 액세스에는 영향을 미치지 않지만 시스템 성능이 저하됩니다. RAID 1은 많은 경우에 좋은 읽기 RAID 0 및 RAID 1의 경우 전체 어레이 구성에 디스크 1개의 용량만 필요하므로 가장 경제적인 중복 구성입니다. 저장된 체크 디지트 값을 계산하려면 각 쓰기에 2번의 읽기와 디스크 간 2번의 쓰기가 필요하기 때문에 RAID 5에서는 쓰기 속도가 느려집니다. 그러나 읽을 때 패리티 비트를 계산할 필요가 없기 때문에 무작위 읽기와 순차 읽기 모두 빠릅니다. RAID 5는 읽기 기반 데이터베이스 서비스에 더 적합합니다. RAID 5의 가장 큰 문제는 디스크에 장애가 발생하는 경우입니다. 데이터를 다른 디스크에 다시 할당해야 하기 때문에 디스크 성능에 심각한 영향을 미치게 되므로 다시 읽는 경우에는 RAID 5를 사용하는 것이 가장 좋습니다. 2.2.3 솔리드 스테이트 스토리지 SSD 및 PCIe 카드 사용 솔리드 스테이트 스토리지는 플래시 메모리라고도 합니다. SSD 기능: 솔리드 스테이트 스토리지 PCIe 카드 기능: Solid State Storage의 사용 시나리오 2.2.4 네트워크 저장소 사용 NAS 및 SAN SAN(Storage Area Network) 및 NAS(Network-Attached Storage)는 외부 파일 저장 장치를 서버에 장착하는 두 가지 방법입니다. SAN: 2.2.4.1 네트워크 스토리지 사용 시나리오 데이터베이스 백업에 적합합니다. 2.2.4.2 네트워크 성능의 한계 네트워크 성능의 한계는 주로 대기 시간과 대역폭입니다. 2.2.4.3 네트워크가 성능에 미치는 영향 2.3 요약 CPU: 메모리 크기는 성능에 중요하므로 최대한 크게 만드세요 3.1 CentOS 시스템 매개변수 최적화 增加资源限制(/etc/security/limit.conf) 리소스 제한 증가( /etc/security/limit .conf) 🎜 디스크 스케줄링 정책(/sys/block/devname/queue/scheduler) 4 文件系统对性能的影响 推荐使用XFS文件系统,在EXT3和EXT4下需要配置以下参数: noop(엘리베이터 예약 전략): 예상(예상 I/O 스케줄링 전략): 더 많은 관련 무료 학습 권장 사항: mysql 튜토리얼(동영상)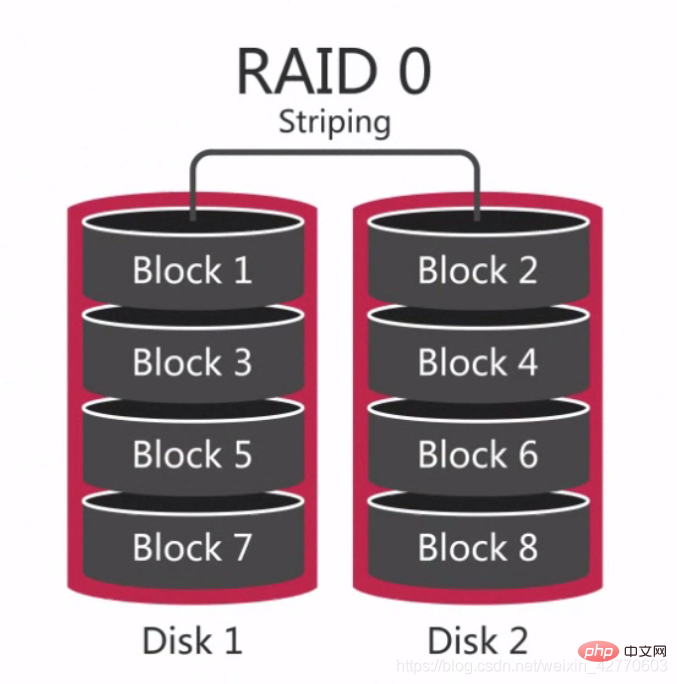 그리고 동시 프로세스에서는 단일 하드 드라이브 성능의 3배를 달성할 수 있습니다.
그리고 동시 프로세스에서는 단일 하드 드라이브 성능의 3배를 달성할 수 있습니다.
2.2.2.2.2 RAID 1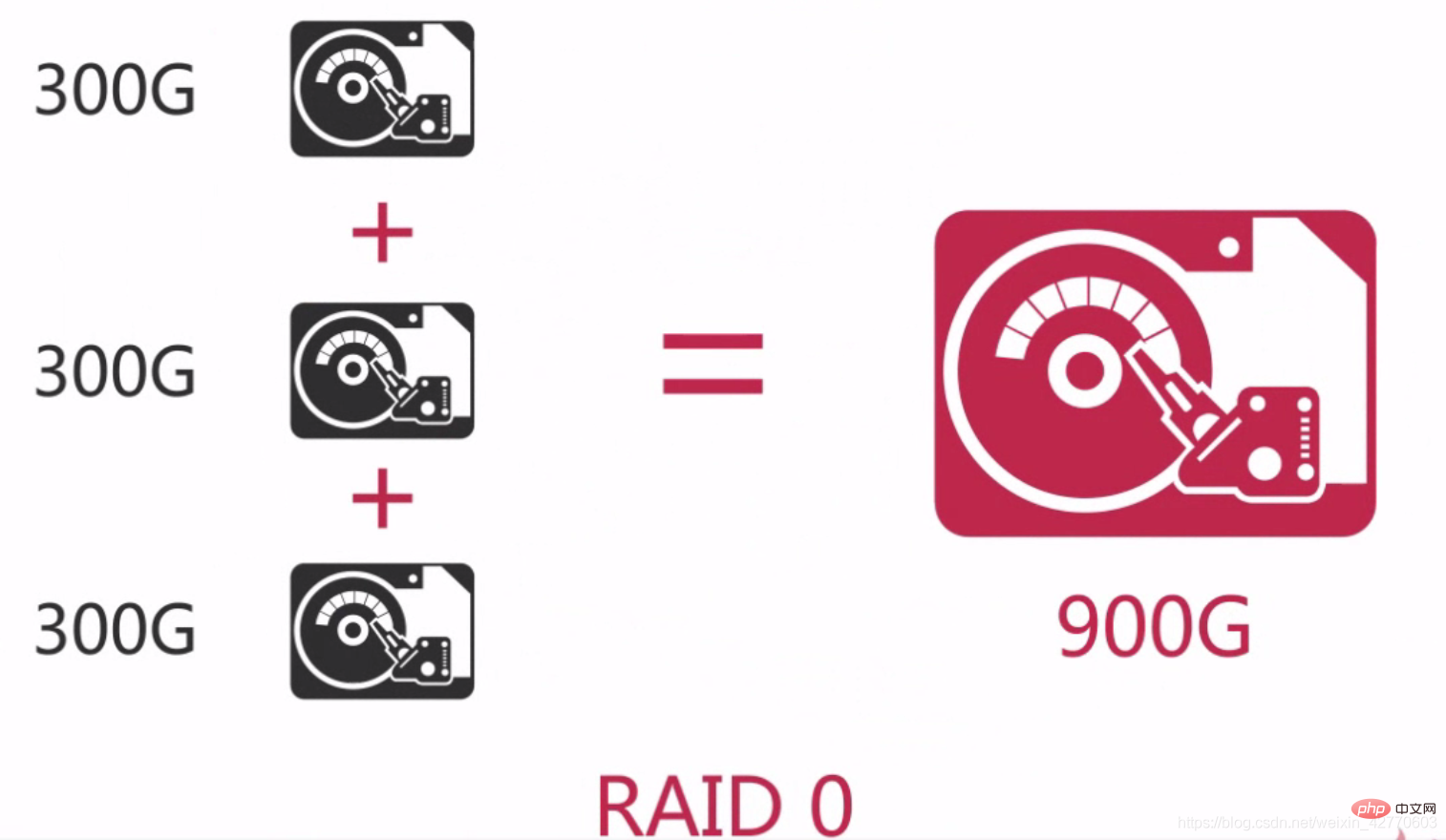
RAID 1은 이라고도 합니다. 한 디스크의 데이터를 다른 디스크에 미러링하는 것이 원칙입니다. 성능에 영향을 주지 않고 시스템의 안정성과 복구 가능성을 최대화하려면 제한된 디스크에 이미지 파일을 생성합니다.
성능을 제공할 수 있고, 서로 다른 디스크 간의 중복 데이터를 제공할 수 있으므로 데이터 중복성이 매우 좋습니다. RAID 1은 RAID 0보다 읽기 성능이 뛰어나므로 로그 저장이나 유사한 작업에 더 적합합니다. 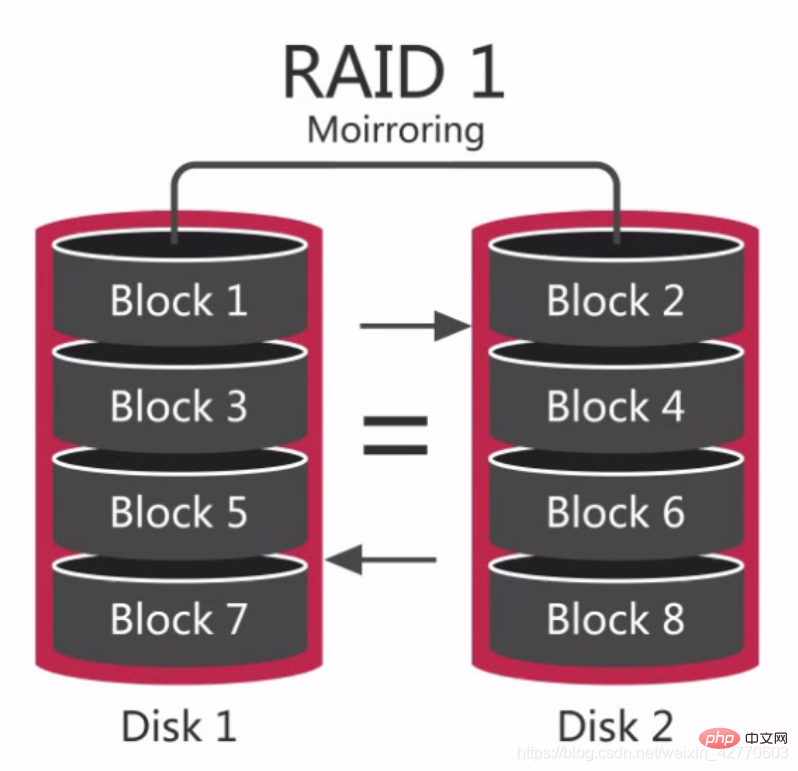
2.2.2.2.3 RAID 5 - 공통 RAID 그룹
RAID 5는 분산 패리티 디스크 어레이라고도 합니다. 데이터는 분산 패리티 블록을 통해 여러 디스크에 분산되므로 디스크 데이터에 오류가 발생하면 패리티 블록에서 재구성할 수 있습니다. 그러나 두 개의 디스크에 장애가 발생하면 전체 볼륨의 데이터를 복구할 수 없습니다. 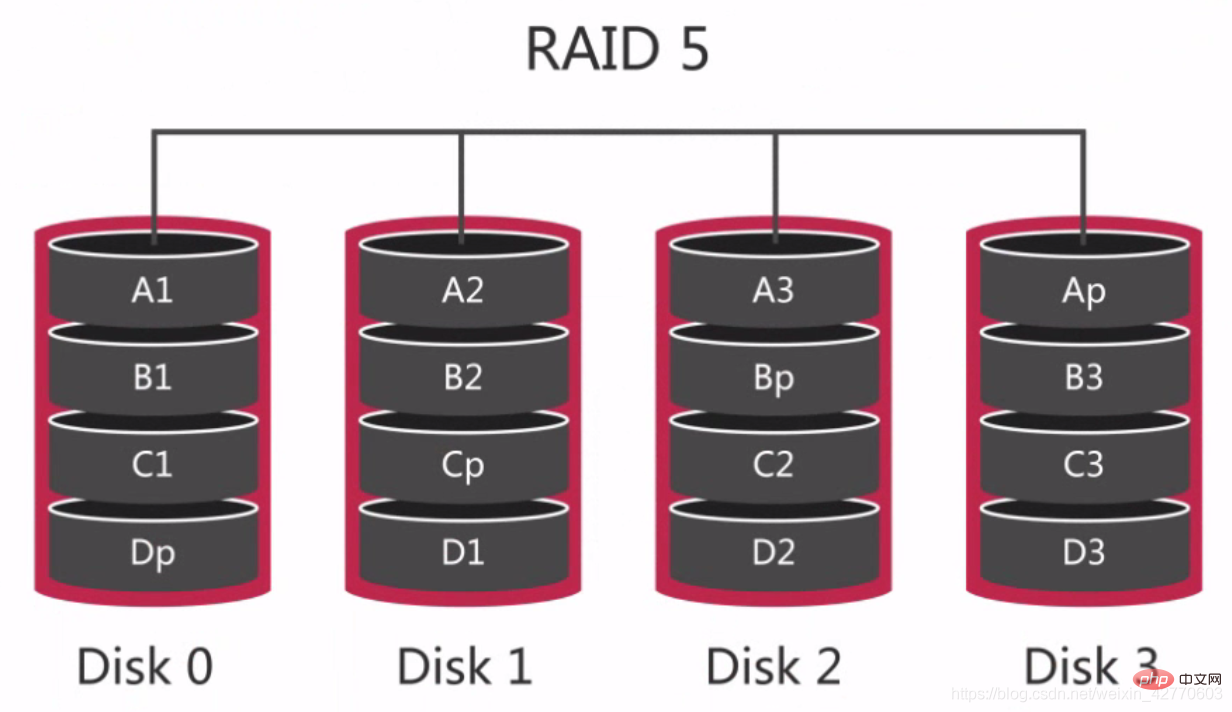 2.2.2.2.4 RAID 10 - 일반적으로 사용되는 RAID 그룹
2.2.2.2.4 RAID 10 - 일반적으로 사용되는 RAID 그룹
RAID 10은 샤드 미러링이라고도 합니다. 먼저 디스크에서 RAID 1을 수행한 다음 RAID 1 디스크 두 세트에서 RAID 0을 수행하므로 읽기 및 쓰기 성능이 RAID 5에 비해 더 쉽고 빠릅니다. 2.2.2.3 RAID 레벨 선택
레벨
Features
Redundancy
디스크 수
Read
Write
RAID 0 싸고 빠르며 위험해요
아니요
N
Fast
Fast
RAID 1
고속 읽기, 간편하고 안전함
Yes
2
Fast
Slow
RAID 5 안전하고 비용 효율적
N+1
빠름
가장 느린 디스크에 따라 다릅니다
RAID 10
비싸고, 빠르며, 안전
있습니다
2N
빠릅니다
빠릅니다
기능:
SAN 장치는 광섬유를 통해 서버에 연결되며, 블록 인터페이스를 통해 장치에 액세스하고 서버는 이를 하드 디스크로 사용할 수 있습니다. 
SAN 기능: 
NAS:
NAS 장치는 네트워크 연결을 사용하며 NFS 또는 SMB와 같은 파일 기반 프로토콜을 통해 액세스됩니다.
권장 사항:
3 운영 체제가 성능에 미치는 영향
MySQL에 적합한 운영 체제: Windows, FreeBSD, Solaris, Linux
net.core.somaxconn = 65535net.core.somaxconn = 65535
对于处于一个监听状态的端口,都有一个自己的监听队列,这个参数决定了每个端口的监听队列的最大长度。这个参数的默认值可能会比较小,对于很大的服务器来说是不够的,一般会修改成2048或更大的值。net.core.netdev_max_backlog=65535net.ipv4.tcp_max_syn_backlog=65535
其中backlog这个参数决定了在每个网络接口接收数据包的速率比内核处理机处理快的时候,允许被发送到队列中的数据包的最大的数目,而另一个参数了是决定了这些还未获得对方连接的这种请求可保存在队中的最大数目。对于超过这个值大小的连接可能会被抛弃,所以要同时调大一些。net.ipv4.tcp_fin_timeout = 10
这个参数是用于控制tcp连接处理的等待状态的超时时间。对于连接比较频繁的系统,通常由大量的连接数处于等待状态,这个参数的设置就是减少连接超时的时间,加快tcp的回收速度。同样有对tcp连接有影响的参数有以下两个:net.ipv4.tcp_tw_reuse = 1、net.ipv4.tcp_tw_recycle = 1
这三个参数都是主要加快tcp的回收,在高负载的系统下,如果tcp连接被占满的话,就会出现连接数据库500的错误,因此这三个参数的作用是很大的。net.core.wmem_default = 87380、net.core.wmem_max = 16777216、net.core.r0mem_default = 87380、net.core.rmem_max = 16777216
以上4个参数决定了tcp连接接收和发送缓冲区大小的默认值和最大值。对于数据库来说,应该把这几个参数的值调整的稍微大一些。net.ipv4.tcp_keepalive_time = 120、net.ipv4.tcp_keepalive_intvl = 30、net.ipv4.tcp_keepalive_probes = 3
以上三个参数用于减少失效连接所占用的tcp系统资源的数量,加快资源回收的效率,net.ipv4.tcp_keepalive_time是表示tcp发送tcp_keepalive探测消息的时间的间隔,单位为秒, 用于确认tcp连接是否有效。net.ipv4.tcp_keepalive_intvl用于当探测这个tcp连接没有反应后,重新发送探测消息的时间间隔,单位为秒,net.ipv4.tcp_keepalive_probes表示在认定tcp连接失效之前,需要发送多少个tcp_keepalive探测消息。这三个参数的默认值对于一个平常系统来说稍微有点大了,所以这里分别对它们改为了小了一些。kernel.shmmax = 4294967295
这个参数是Linux内核参数中最重要的参数之一,用于定义单个共享内存段的最大值。
注意:
vm.swappiness = 0
这个参数当内存不足时会对性能产生比较明显的影响。这个参数就是告诉Linux系统内核除非虚拟内存完全满了,否则不要使用交换区。
Linux系统内存交换分区:
在Linux系统安装时都会有一个特殊的磁盘分区,称之为系统交换分区。如果我们使用free -m在系统中查看可以看到类似下面的内容,其中swap就是交换分区。当操作系统因为没有足够的内存时就会将一些虚拟内存写到磁盘的交换区中这样就会发生内存交换。
在MySQL服务所在的Linux系统上完全禁用交换分区,会带来以下两点风险:
limit.conf 수신 상태에 있는 포트의 경우 자체 수신 대기열이 있습니다. 이 매개변수는 각 포트에 대한 수신 대기열의 최대 길이를 결정합니다. 이 매개변수의 기본값은 비교적 작을 수 있으므로 대규모 서버에는 충분하지 않습니다. 일반적으로 2048 이상의 값으로 수정됩니다. net.core.netdev_max_backlog=65535net.ipv4.tcp_max_syn_backlog=65535 backlog 매개변수는 각 네트워크 인터페이스에서 수신되는 데이터 패킷 수를 결정합니다. 속도가 커널 프로세서보다 빠를 때 대기열로 보낼 수 있는 최대 패킷 수이며, 다른 매개변수는 아직 상대방으로부터 연결을 얻지 못한 요청의 최대 수를 결정합니다. 대기열. 이 값을 초과하는 연결은 폐기될 수 있으므로 동시에 크기를 늘리십시오.
backlog 매개변수는 각 네트워크 인터페이스에서 수신되는 데이터 패킷 수를 결정합니다. 속도가 커널 프로세서보다 빠를 때 대기열로 보낼 수 있는 최대 패킷 수이며, 다른 매개변수는 아직 상대방으로부터 연결을 얻지 못한 요청의 최대 수를 결정합니다. 대기열. 이 값을 초과하는 연결은 폐기될 수 있으므로 동시에 크기를 늘리십시오. net.ipv4.tcp_fin_timeout = 10
이 파라미터는 TCP 연결 처리 대기 상태의 타임아웃 시간을 제어하는 데 사용됩니다. 상대적으로 연결이 빈번한 시스템의 경우 일반적으로 많은 수의 연결이 대기 상태에 있습니다. 이 매개변수의 설정은 연결 시간 초과 시간을 줄이고 TCP 재활용 속도를 높이는 것입니다. TCP 연결에 영향을 미치는 두 가지 매개변수도 있습니다: net.ipv4.tcp_tw_reuse = 1, net.ipv4.tcp_tw_recycle = 1🎜 이 세 가지 매개변수는 주로 다음과 같습니다. 부하가 높은 시스템에서 TCP 연결이 가득 차면 데이터베이스 연결 오류 500이 발생하므로 이 세 가지 매개 변수는 매우 중요합니다. 🎜net.core.wmem_default = 87380, net.core.wmem_max = 16777216, net.core.r0mem_default = 87380, net.core.rmem_max = 16777216🎜 위의 4개 매개변수는 TCP 연결 수신 및 전송 버퍼 크기의 기본값과 최대값을 결정합니다. 데이터베이스의 경우 이러한 매개변수의 값을 약간 더 크게 조정해야 합니다. 🎜net.ipv4.tcp_keepalive_time = 120, net.ipv4.tcp_keepalive_intvl = 30, net.ipv4.tcp_keepalive_probes = 3🎜 위의 세 가지 매개변수는 실패한 연결이 차지하는 TCP 시스템 리소스의 양을 줄이고 리소스 재활용의 효율성을 높이기 위해 사용됩니다. net.ipv4.tcp_keepalive_time은 TCP가 tcp_keepalive 탐지 메시지를 보내는 시간 간격을 나타냅니다. , 초 단위로 TCP 연결이 유효한지 확인하는 데 사용됩니다. net.ipv4.tcp_keepalive_intvl은 tcp 연결이 응답하지 않음을 감지한 후 감지 메시지를 다시 보내는 데 사용됩니다. 단위는 net.ipv4.tcp_keepalive_probes가 감지되었음을 나타냅니다. message TCP 연결이 실패하기 전에 전송해야 하는 tcp_keepalive 탐지 메시지 수입니다. 이 세 가지 매개변수의 기본값은 일반 시스템에 비해 너무 크므로 여기서는 더 작은 값으로 변경합니다. 🎜kernel.shmmax = 4294967295🎜 이 매개변수는 Linux 커널 매개변수에서 가장 중요한 매개변수 중 하나이며 단일 공유 메모리 세그먼트의 최대값을 정의하는 데 사용됩니다. 🎜참고: 🎜이 매개변수는 공유 메모리 세그먼트의 전체 Innodb 버퍼 풀 크기를 수용할 수 있을 만큼 크게 설정되어야 합니다. 🎜64비트 Linux 시스템의 경우 가능한 최대 값은 물리적 메모리 값(1바이트)입니다. 권장 값은 일반적으로 Innodb 버퍼 크기보다 큽니다. 풀은 실제 메모리 가져오기 - 1바이트일 수 있습니다.
🎜vm.swappiness = 0🎜 이 매개변수는 메모리가 부족할 때 성능에 상당한 영향을 미칩니다. 이 매개변수는 가상 메모리가 완전히 채워지지 않는 한 스왑 영역을 사용하지 않도록 Linux 시스템 커널에 지시합니다. 🎜Linux 시스템 메모리 스왑 파티션: 🎜 Linux 시스템이 설치되면 시스템 스왑 파티션이라고 하는 특수 디스크 파티션이 있습니다. . free -m을 사용하여 시스템을 보면 다음과 유사한 내용을 볼 수 있습니다. 여기서 swap은 스왑 파티션입니다. 운영체제에 메모리가 부족하면 디스크의 스왑 영역에 일부 가상 메모리를 쓰고 메모리 스왑이 발생합니다. 🎜 MySQL 서비스가 위치한 Linux 시스템에서 스왑 파티션을 완전히 비활성화하면 다음 두 가지 위험이 발생합니다. 🎜운영 체제 성능 저하🎜메모리 오버플로, 충돌 또는 운영 체제에 의해 종료
limit.conf 이 파일은 실제로 플러그인 인증 모듈인 Linx PAM의 구성 파일입니다. 🎜 더 중요한 매개변수 구성 중 하나는 열린 파일 수에 대한 제한입니다. 🎜🎜🎜 결론: 충분한 파일 핸들을 열 수 있도록 열린 파일 수를 65535로 늘립니다. 🎜 참고: 이 파일의 수정 사항을 적용하려면 다시 시작해야 합니다. 🎜
cat /sys/block/sda/queue/scheduler 명령을 사용하면 현재 디스크에서 사용하는 스케줄링 정책을 볼 수 있습니다. . 다음 noop 예상 기한[cfq]은 시스템의 기본 cfq 예약 정책입니다. cat /sys/block/sda/queue/scheduler查看当前磁盘所使用的调度策略。下面的noop anticipatory deadline [cfq]为系统默认的cfq调度策略。
在MySQL数据库服务下,cfq并不合适,是由于在MySQL工作过程中,cfq会在队列中插入一些不必要的请求,导致很差的响应时间。
除了cfq调度策略,还有以下几种策略:
noop(电梯式调度策略):
deadline(截止时间调度策略):
anticipatory(预料I/O调度策略):
我们可以输入以下命令来改变磁盘的调度策略:echo schedulerName > /sys/block/sda/queue/scheduler
如:echo deadline > /sys/block/sda/queue/scheduler
EXT3/4系统的挂载参数(/etc/fstab):
cfq 예약 전략 외에도 , 또한 여러 전략이 있습니다: data=writeback | ordered | journal
这个参数一共有三个可选择的值,writeback表示只有元数据写入到日志,元数据写入和数据写入并不是同步的。这是一种最快的配置,因为InnoDB原本有自己的事务日志,所以通常是InnoDB最好的选择。ordered只会记录元数据,但提供了一些一致性的保证,在写元数据之前,会先写数据,使它们保持一致,这个选项比writeback稍微慢一点,但出现崩溃会更加安全。journal提供了原子日志的行为,在数据写入到最终的日志之前,将记录到日志中。这个选项对于InnoDB显然是没有必要的,也是三种中最慢的一种。noatime、nodiratime
这两个选项用于记录文件的访问时间和读取目录的时间。设置了这两个参数可以减少一些写的操作。系统在读取文件和目录时也不必写操作来记录以上两个时间。
下面是文件/dev/sda1/ext4中的一些配置:noatime,nodiratime,data=writeback 1 1 MySQL 데이터베이스 서비스에서는 cfq가 적합하지 않습니다. MySQL 작업 프로세스 중에 cfq가 불필요한 요청을 대기열에 삽입하여 응답 시간이 느려지기 때문입니다. 마감일(마감일 일정 전략):
다음 명령을 입력하여 디스크 예약 정책을 변경할 수 있습니다: 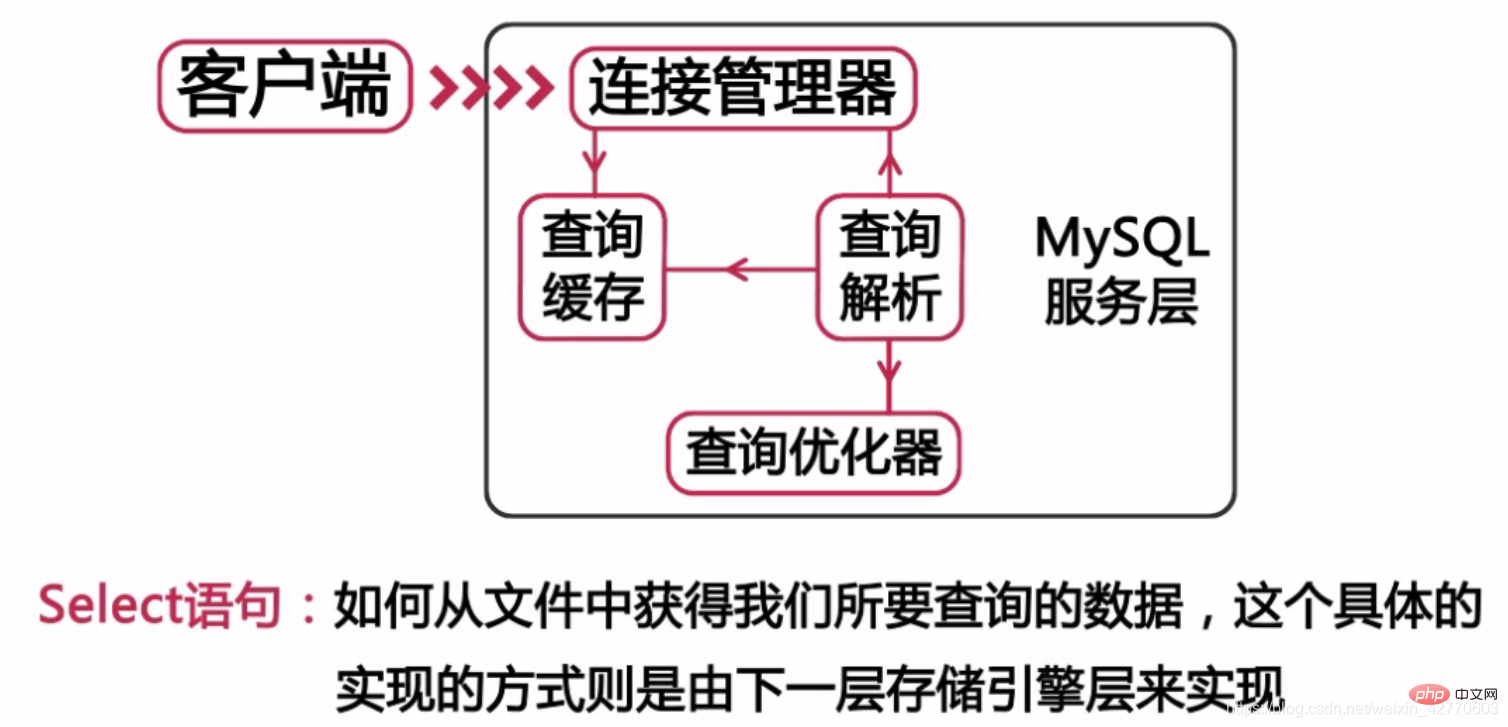
echo SchedulerName > /sys/block/sda/queue/scheduler
예: echo Deadline > /sys/block/sda/queue/scheduler 4 파일 시스템이 성능에 미치는 영향
4 파일 시스템이 성능에 미치는 영향
XFS 파일 시스템을 사용하는 것이 좋습니다. EXT3 및 EXT4 매개변수에 구성이 필요합니다:
data=writeback | 저널🎜 이 매개변수에는 세 가지 선택 값인 writeback이 있습니다. code>는 로그에 메타데이터만 기록되며, 메타데이터 쓰기와 데이터 쓰기가 동기화되지 않음을 의미합니다. InnoDB에는 원래 자체 트랜잭션 로그가 있으므로 이는 가장 빠른 구성이며 일반적으로 InnoDB에 가장 적합한 선택입니다. ordered는 메타데이터만 기록하지만 일부 일관성을 보장합니다. 메타데이터를 쓰기 전에 먼저 데이터를 작성하여 일관성을 유지합니다. 이 옵션은 writeback보다 약간 느립니다. 하지만 충돌로부터는 더 안전합니다. 저널은 데이터가 최종 로그에 기록되기 전에 로그에 기록되는 원자 로깅 동작을 제공합니다. 이 옵션은 InnoDB에는 분명히 필요하지 않으며 세 가지 옵션 중 가장 느립니다. 🎜noatime, nodiratime🎜 이 두 가지 옵션은 파일 액세스 시간과 디렉터리를 읽는 시간을 기록하는 데 사용됩니다. 이 두 매개변수를 설정하면 일부 쓰기 작업이 줄어들 수 있습니다. 시스템은 파일과 디렉터리를 읽을 때 위의 두 번을 기록하기 위해 작업을 작성할 필요가 없습니다. 🎜 다음은 /dev/sda1/ext4 파일의 일부 구성입니다. 🎜noatime,nodiratime,data=writeback 1 1🎜🎜🎜🎜5 MySQL 아키텍처 🎜🎜🎜 아키텍처의 최상위 계층을 클라이언트라고 합니다. 이 계층은 PHP, JAVA, C API, .Net, ODBC, JDBC 등과 같은 mysql 연결 프로토콜을 통해 mysql에 연결할 수 있는 클라이언트를 나타냅니다. 여기서 이 계층은 MySQL 아키텍처에 고유하지 않습니다. 대부분의 CS 아키텍처 서비스는 이 아키텍처를 채택합니다. 이 계층은 주로 연결 처리, 권한 부여 인증 및 보안과 같은 일부 기능을 완료합니다. mysql에 연결된 각 클라이언트는 서버 프로세스에 스레드를 가지고 있습니다. 앞서 언급했듯이 각 연결 쿼리는 하나의 CPU만 사용합니다. 🎜 그런 다음 이 시스템의 두 번째 레이어에는 아래 그림과 같이 대부분의 핵심 mysql 서비스가 이 레이어에 있습니다. 🎜🎜🎜 일반적으로 사용되는 DDL 또는 DML 문은 이 레이어에서 정의됩니다. 하지만 한 가지만 기억하면 됩니다. 모든 교차 스토리지 엔진 기능은 이 레이어에서 구현됩니다. 이 레이어는 서비스 레이어라고도 불리기 때문입니다. 🎜 구조 시스템의 세 번째 계층은 스토리지 엔진 계층입니다. MySQL은 일련의 스토리지 엔진 인터페이스를 정의하는 매우 뛰어난 오픈 소스 데이터베이스입니다. 스토리지 엔진의 요구 사항을 충족하는 한 MySQL 데이터베이스를 개발할 수 있습니다. . 일반적으로 사용되는 InnoDB와 같이 귀하의 요구 사항을 완벽하게 충족하는 스토리지 엔진을 선택하십시오. 현재 아래 그림과 같이 mysql에서 지원되는 많은 스토리지 엔진이 있습니다. 🎜🎜🎜🎜Note🎜: 스토리지 엔진은 테이블 및 라이브러리용 아님(라이브러리의 테이블마다 다른 스토리지 엔진을 사용할 수 있음) 🎜 간략한 설명을 위해 가장 일반적으로 사용되는 스토리지 엔진 중 일부를 선택해 보겠습니다. mysql에서 사용하는 스토리지 엔진은 데이터베이스 성능에 직접적인 영향을 미칩니다. 주의 깊게 읽어보시기 바랍니다. 스토리지 엔진의 일부 기능을 이해하고 작업을 마친 후에만 스토리지 엔진을 사용하십시오. 🎜

위 내용은 빅데이터 학습을 위한 MYSQL 고급의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!