
느린 SQL 최적화 연습 기록

- coldplay.xixi앞으로
- 2020-12-25 17:23:576347검색
sql tutorial느린 SQL 쿼리 최적화 소개

권장(무료): sql tutorial
기존 문제
SQL 느린 쿼리 후 최적화, 우리 시스템에서 다음과 같은 유형의 문제가 발견되었습니다:
1.未建索引:整张表没有建索引;2.索引未命中:有索引,但是部分查询条件下索引未命中;3.搜索了额外的非必要字段,导致回表;4.排序,聚合导致慢查询;5.相同内容多次查询数据库;6.未消限制搜索范围或者限制的搜索范围在预期之外,导致全部扫描;
2. 솔루션
1.优化索引,增加或者修改当前的索引; 2.重写sql;3.利用redis缓存,减少查询次数;4.增加条件,避免非必要查询;5.增加条件,减少查询范围;
3. 사례 분석
(1) 약재 검색 인터페이스
전체 SQL 문은 읽기의 편의를 위해 부록에 있으며 일부 공통 필드는 중국어로 되어 있습니다.
여기에서는 SQL 문을 받은 후의 전체 분석 과정, 논리에 대한 생각, 프로세스 조정 및 최종 솔루션에 대해 주로 이야기합니다.
몇 가지 참고 자료를 제공하고 더 나은 제안을 해주실 수 있기를 바랍니다.
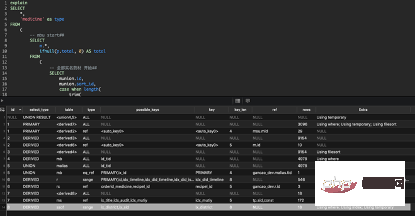
이 SQL 문은 의사가 약재를 찾기 위해 검색한 병음이나 한자 기반의 퍼지 쿼리를 요구하고, 의사가 선택한 약재 라이브러리를 기반으로 다음 공급업체를 검색한 후 일치시키는 쿼리가 필요합니다. 공급업체를 기준으로 약재를 선별하여 공급업체가 보유하지 않은 약재에 대해서는 실명순, 별명순, 완전일치순, 부분일치순, 의사순으로 정렬합니다. 지난 6개월 동안의 사용 습관. 최종적으로는 동일한 약품을 다른 이름으로 모아서 실명(다른 이름)의 형태로 제시하는 것입니다.
1. sql
- 분석 (1) 14-8
행 14, ID 8로 결과 분석 설명:
①Explain
8,DERIVED,ssof,range,"ix_district,ix_供应商id",ix_district,8,NULL,18,Using where; Using index; Using temporary
②Sql
SELECT DISTINCT (ssof.供应商id) AS 供应商id FROM 药库供应商关系表 AS ssof WHERE ssof.药库id IN ( 1, 2, 8, 9, 10, 11, 12, 13, 14, 15, 17, 22, 24, 25, 26, 27, 31, 33) AND ssof.药方剂型id IN (1)
© Index
PRIMARY KEY (`id`), UNIQUE KEY `ix_district` ( `药库id`, `药方剂型id`, `供应商id` ) USING BTREE,KEY `ix_供应商id` (`供应商id`) USING BTREE
④분석
인덱스를 사용하여 임시 테이블을 생성하면 여기에서 인덱스가 완전히 다루어졌지만 여전히 테이블 반환 작업이 있습니다.
이유는 in을 사용하여 테이블이 반환되기 때문입니다. in이 mysql과 동일하도록 자동으로 최적화될 수 있는 경우 테이블은 반환되지 않습니다. 최적화할 수 없으면 테이블로 돌아갑니다.
임시테이블은 독특하기 때문에 피할 수 없습니다.
in을 동시에 사용할 때는 그 안에 포함된 값의 개수가 수만 개로 상대적으로 클 경우 주의하세요. 차이가 높더라도 인덱스 실패로 이어지기 때문에 여러 번의 일괄 쿼리가 필요합니다.
2. 12-7
- (1)Explain
7,DERIVED,<derived8>,ALL,NULL,NULL,NULL,NULL,18,Using temporary; Using filesort
- (2)Sql
INNER JOIN (上面14-8临时表) tp ON tp.供应商id= ms.供应商id
- (3) Index
None
- (4) Analysis
임시 테이블 작업의 경우 no 색인 , 파일 정렬을 사용합니다.
이 부분은 임시 테이블과 약재 테이블 간의 연관 작업의 일부입니다. 파일 정렬은 약재 테이블 ID별로 그룹화해야 하기 때문에 발생합니다.
1. 기본적으로 group by를 사용한 후 mysql은 임시 테이블을 생성한 다음 이를 정렬합니다(여기서 기본 정렬은 빠른 정렬입니다). 이는 성능을 소모합니다.
2. 그룹화의 핵심은 [먼저 정렬한 다음 그룹화하는 것이 아니라] 먼저 그룹화한 다음 정렬하는 것입니다.
3. 열별 그룹화는 기본적으로 열별로 그룹화한 후 열별로 오름차순으로 정렬합니다. 기본적으로 열별로 그룹화한 다음 대상 기본 키 ID에 따라 오름차순으로 정렬합니다.
3. 13-7
- (1)Explain
7,DERIVED,ms,ref,"ix_title,idx_audit,idx_mutiy",idx_mutiy,5,"tp.供应商id,const",172,NULL
- (2)Sql
SELECT ms.药材表id, max(ms.audit) AS audit, max(ms.price) AS price, max(ms.market_price) AS market_price,max(ms.is_granule) AS is_granule,max(ms.is_decoct) AS is_decoct, max(ms.is_slice) AS is_slice,max(ms.is_cream) AS is_cream, max(ms.is_extract) AS is_extract,max(ms.is_cream_granule) AS is_cream_granule, max(ms.is_extract_granule) AS is_extract_granule,max(ms.is_drychip) AS is_drychip, max(ms.is_pill) AS is_pill,max(ms.is_powder) AS is_powder, max(ms.is_bolus) AS is_bolus FROM 供应商药材表 AS ms INNER JOIN ( SELECT DISTINCT (ssof.供应商id) AS 供应商id FROM 药库供应商关系表 AS ssof WHERE ssof.药库id IN ( 1, 2, 8, 9, 10, 11, 12, 13, 14, 15, 17, 22, 24, 25, 26, 27, 31, 33 ) AND ssof.药方剂型id IN (1) ) tp ON tp.供应商id= ms.供应商id WHERE ms.audit = 1 GROUP BY ms.药材表id
- (3) Index
KEY `idx_mutiy` (`供应商id`, `audit`, `药材表id`)
- (4) Analysis
를 치고, 인터테이블 연결은 공급자 ID를 사용했으며, 인덱스 생성 순서는 공급자 ID, where 조건에 대한 감사, 조건 약재 테이블 ID로 그룹화됩니다.
이 부분은 당분간 변경할 필요가 없습니다.
4.10-6
- (1) explain
6,DERIVED,r,range,"PRIMARY,id,idx_timeline,idx_did_timeline,idx_did_isdel_statuspay_timecreate_payorderid,idx_did_statuspay_ischecked_isdel",idx_did_timeline,8,NULL,546,Using where; Using index; Using temporary; Using filesort
- (2) Sql
SELECT count(*) AS total, rc.i AS m药材表id FROM 处方药材表 AS rc INNER JOIN 药方表AS r ON r.id = rc.药方表_id WHERE r.did = 40 AND r.timeline > 1576115196 AND rc.type_id in (1, 3) GROUP BY rc.i
- (3) 인덱스
KEY `idx_did_timeline` (`did`, `timeline`),
- (4) 분석
드라이버 테이블과 퀼트 테이블, 작은 테이블이 큰 테이블을 구동합니다.
조인할 때 먼저 어떤 테이블이 구동 테이블이고 어떤 테이블이 구동 테이블인지 이해하세요.
1. 왼쪽 조인을 사용하는 경우 왼쪽 테이블은 구동 테이블이고 오른쪽 테이블은 구동 테이블입니다.
2. 오른쪽 조인을 사용하면 오른쪽 테이블이 구동 테이블이고 왼쪽 테이블이 구동 테이블이 됩니다.
3. 조인을 사용하면 mysql은 데이터 용량이 작은 테이블을 구동 테이블로 선택하고 큰 테이블을 구동 테이블로 선택합니다. ;
4. 다음은 드라이버 테이블이고, 앞에는 드라이버 테이블이 있습니다. 11-6
(1) explain
6,DERIVED,rc,ref,"orderid_药材表,药方表_id",药方表_id,5,r.id,3,Using where
- 위와 동일
(3) Index
KEY `idx_药方表_id` (`药方表_id`, `type_id`) USING BTREE,
- 인덱스 순서 문제는 없습니다. 여전히 테이블이 반환되는 원인입니다.
6.8-5
- (1)Explain
5,UNION,malias,ALL,id_tid,NULL,NULL,NULL,4978,Using where
- (2)Sql
SELECT mb.id, mb.sort_id, mb.title, mb.py, mb.unit, mb.weight, mb.tid, mb.amount_max, mb.poisonous, mb.is_auxiliary, mb.is_auxiliary_free, mb.is_difficult_powder, mb.brief, mb.is_fixed_recipe, ASE WHEN malias.py = 'GC' THEN malias.title ELSE CASE WHEN malias.title = 'GC' THEN malias.title ELSE '' END END AS atitle, alias.py AS apy, CASE WHEN malias.py = 'GC' THEN 2 ELSE CASE WHEN malias.title = 'GC' THEN 2 ELSE 1 END END AS ttid FROM 药材表 AS mb LEFT JOIN 药材表 AS malias ON malias.tid = mb.id WHERE alias.title LIKE '%GC%' OR malias.py LIKE '%GC%'
- (3)索引
KEY `id_tid` (`tid`) USING BTREE,
- (4)分析
因为like是左右like,无法建立索引,所以只能建tid。Type是all,遍历全表以找到匹配的行,左右表大小一样,估算的找到所需的记录所需要读取的行数有4978。这个因为是like的缘故,无法优化,这个语句并没有走索引,药材表 AS mb FORCE INDEX (id_tid) 改为强制索引,读取的行数减少了700行。
7.9-5
- (1)Explain
5,UNION,mb,eq_ref,"PRIMARY,ix_id",PRIMARY,4,malias.tid,1,NULL
- (2)Sql
同上
- (3)索引
PRIMARY KEY (`id`) USING BTREE,
- (4)分析
走了主键索引,行数也少,通过。
8.7-4
- (1)Explain
4,DERIVED,mb,ALL,id_tid,NULL,NULL,NULL,4978,Using where
-
(2)Sql
SELECT mb.id, mb.sort_id, mb.title, mb.py, mb.unit, mb.weight, mb.tid, mb.amount_max, mb.poisonous, mb.is_auxiliary, mb.is_auxiliary_free, mb.is_difficult_powder, mb.brief, mb.is_fixed_recipe, '' AS atitle, '' AS apy, CASE WHEN mb.py = 'GC' THEN 3 ELSE CASE WHEN mb.title = 'GC' THEN 3 ELSE 1 END END AS ttid FROM 药材表 AS mb WHERE mb.tid = 0 AND ( mb.title LIKE '%GC%' OR mb.py LIKE '%GC%' )
(3)索引
KEY `id_tid` (`tid`) USING BTREE,
-
(4)分析
tidint(11) NOT NULL DEFAULT ‘0’ COMMENT ‘真名药品的id’,
他也是like,这个没法优化。
9.6-3
- (1)Explain
3,DERIVED,<derived4>,ALL,NULL,NULL,NULL,NULL,9154,Using filesort
-
(2)Sql
UNION ALL
(3)索引
无
- (4)分析
就是把真名搜索结果和别人搜索结果合并。避免用or连接,加快速度 形成一个munion的表,初步完成药材搜索,接下去就是排序。
这一个进行了2次查询,然后用union连接,可以考虑合并为一次查询。用case when进行区分,计算出权重。
这边是一个优化点。
10.4-2
- (1)Explain
2,DERIVED,<derived3>,ALL,NULL,NULL,NULL,NULL,9154,NULL
-
(2)Sql
SELECT munion.id, munion.sort_id, case when length( trim( group_concat(munion.atitle SEPARATOR ' ') ) )> 0 then concat( munion.title, '(', trim( group_concat(munion.atitle SEPARATOR ' ') ), ')' ) else munion.title end as title, munion.py, munion.unit, munion.weight, munion.tid, munion.amount_max, munion.poisonous, munion.is_auxiliary, munion.is_auxiliary_free, munion.is_difficult_powder, munion.brief, munion.is_fixed_recipe, -- trim( group_concat( munion.atitle SEPARATOR ' ' ) ) AS atitle, ## -- trim( group_concat(munion.apy SEPARATOR ' ') ) AS apy, ## max(ttid) * 100000 + id AS ttid FROM munion <derived4> GROUP BY id -- 全部实名药材 结束## (3)索引
无
- (4)分析
这里全部在临时表中搜索了。
11.5-2
- (1)Explain
2,DERIVED,<derived6>,ref,<auto_key0>,<auto_key0>,5,m.id,10,NULL
- (2)Sql
Select fields from 全部实名药材表 as m LEFT JOIN ( 个人使用药材统计表 ) p ON m.id = p.m药材表id
- (3)索引
无
- (4)分析
2张虚拟表left join
使用了优化器为派生表生成的索引
这边比较浪费性能,每次查询,都要对医生历史开方记录进行统计,并且统计还是几张大表计算后的结果。但是如果只是sql优化,这边暂时无法优化。
12.2-1
- (1)Explain
1,PRIMARY,<derived7>,ALL,NULL,NULL,NULL,NULL,3096,Using where; Using temporary; Using filesort
(2)Sql
(3)索引
(4)分析
临时表操作
13.3-1
- (1)Explain
1,PRIMARY,<derived2>,ref,<auto_key0>,<auto_key0>,4,msu.药材表id,29,NULL
(2)Sql
(3)索引
(4)分析
临时表操作
14.null
- (1)Explain
NULL,UNION RESULT,"<union4,5>",ALL,NULL,NULL,NULL,NULL,NULL,Using temporary
(2)Sql
(3)索引
(4)分析
临时表
(二)优化sql
上面我们只做索引的优化,遵循的原则是:
1.最左前缀匹配原则,非常重要的原则,mysql会一直向右匹配直到遇到范围查询(>、<、between、like)就停止匹配,比如a = 1 and b = 2 and c > 3 and d = 4 如果建立(a,b,c,d)顺序的索引,d是用不到索引的,如果建立(a,b,d,c)的索引则都可以用到,a,b,d的顺序可以任意调整。2.=和in可以乱序,比如a = 1 and b = 2 and c = 3 建立(a,b,c)索引可以任意顺序,mysql的查询优化器会帮你优化成索引可以识别的形式。3.尽量选择区分度高的列作为索引,区分度的公式是count(distinct col)/count(*),表示字段不重复的比例,比例越大我们扫描的记录数越少,唯一键的区分度是1,而一些状态、性别字段可能在大数据面前区分度就是0,那可能有人会问,这个比例有什么经验值吗?使用场景不同,这个值也很难确定,一般需要join的字段我们都要求是0.1以上,即平均1条扫描10条记录。4.索引列不能参与计算,保持列“干净”,比如from_unixtime(create_time) = ’2014-05-29’就不能使用到索引,原因很简单,b+树中存的都是数据表中的字段值,但进行检索时,需要把所有元素都应用函数才能比较,显然成本太大。所以语句应该写成create_time = unix_timestamp(’2014-05-29’)。5.尽量的扩展索引,不要新建索引。比如表中已经有a的索引,现在要加(a,b)的索引,那么只需要修改原来的索引即可。
查询优化神器 - explain命令
关于explain命令相信大家并不陌生,具体用法和字段含义可以参考官网explain-output,这里需要强调rows是核心指标,绝大部分rows小的语句执行一定很快(有例外,下面会讲到)。所以优化语句基本上都是在优化rows。
化基本步骤:
0.先运行看看是否真的很慢,注意设置SQL_NO_CACHE1.where条件单表查,锁定最小返回记录表。这句话的意思是把查询语句的where都应用到表中返回的记录数最小的表开始查起,单表每个字段分别查询,看哪个字段的区分度最高;2.explain查看执行计划,是否与1预期一致(从锁定记录较少的表开始查询);3.order by limit 形式的sql语句让排序的表优先查;4.了解业务方使用场景;5.加索引时参照建索引的几大原则;6.观察结果,不符合预期继续从0分析;
上面已经详细的分析了每一个步骤,根据上面的sql,去除union操作, 增加索引。可以看出,优化后虽然有所改善。但是距离我们的希望还有很大距离,但是光做sql优化,感觉也没有多少改进空间,所以决定从其他方面解决。
(三)拆分sql
由于速度还是不领人满意,尤其是个人用药情况统计,其实没必要每次都全部统计一次,再要优化,只靠修改索引应该是不行的了,所以考虑使用缓存。
接下来是修改php代码,把全部sql语句拆分,然后再组装。
- (1)搜索真名,别名(缓存)
SELECT mb.id, mb.sort_id, mb.title, mb.py, mb.unit, mb.weight, mb.tid, mb.amount_max, mb.poisonous, mb.is_auxiliary, mb.is_auxiliary_free, mb.is_difficult_powder, mb.brief, mb.is_fixed_recipe, IFNULL(group_concat(malias.title),'') atitle, IFNULL(group_concat(malias.py),'') apy FROM 药材表 AS mb LEFT JOIN 药材表 AS malias ON malias.tid = mb.id WHERE mb.tid = 0 AND ( malias.title LIKE '%GC%' OR malias.py LIKE '%GC%' or mb.title LIKE '%GC%' OR mb.py LIKE '%GC%' ) group by mb.id

- (2)如果命中有药材
①排序
真名在前,别名在后,完全匹配在前,部分匹配在后
//对搜索结果进行处理,增加权重
②对供应商药材搜索
SELECT ms.药材表id, max( ms.audit ) AS audit, max( ms.price ) AS price, max( ms.market_price ) AS market_price, max( ms.is_granule ) AS is_granule, max( ms.is_decoct ) AS is_decoct, max( ms.is_slice ) AS is_slice, max( ms.is_cream ) AS is_cream, max( ms.is_extract ) AS is_extract, max( ms.is_cream_granule) AS is_cream_granule, max( ms.is_extract_granule) AS is_extract_granule, max( ms.is_drychip ) AS is_drychip, max( ms.is_pill ) AS is_pill, max( ms.is_powder ) AS is_powder, max( ms.is_bolus ) AS is_bolus FROM 供应商药材表 AS ms WHERE ms.audit = 1 AND ms.供应商idin ( SELECT DISTINCT ( ssof.供应商id) AS 供应商id FROM 药库供应商关系表 AS ssof WHERE ssof.药库id IN ( 1,2,8,9,10,11,12,13,14,15,17,22,24,25,26,27,31,33 ) AND ssof.药方剂型id IN (1) ) AND ms.药材表id IN ( 78,205,206,207,208,209,334,356,397,416,584,652,988,3001,3200,3248,3521,3522,3599,3610,3624,4395,4396,4397,4398,4399,4400,4401,4402,4403,4404,4405,4406,4407,4408,5704,5705,5706,5739,5740,5741,5742,5743,6265,6266,6267,6268,6514,6515,6516,6517,6518,6742,6743 ) AND ms.is_slice = 1 GROUP BY ms.药材表id

③拿医生历史开方药材用量数据(缓存)
SELECT count( * ) AS total, rc.i AS 药材表id FROM 处方药材表 AS rc INNER JOIN 药方表AS r ON r.id = rc.药方表_id WHERE r.did = 40 AND r.timeline > 1576116927 AND rc.type_id in (1,3) GROUP BY rc.i

④ 装配及排序微调



- (3)小结
运行速度,对于开方量不是特别多的医生来说,两者速度都是0.1秒左右.但是如果碰到开方量大的医生,优化后的sql速度比较稳定,能始终维持在0.1秒左右,优化前的sql速度会超过0.2秒.速度提升约一倍以上。
最后对搜索结果和未优化前的搜索结果进行比对,结果数量和顺序完全一致.本次优化结束。
四、附录:
SELECT sql_no_cache
*FROM
(
-- mbu start## SELECT
m.*,
ifnull(p.total, 0) AS total FROM
(
--全部实名药材
开始
##SELECT
munion.id,
munion.sort_id,
case when length(
trim(
group_concat(munion.atitle SEPARATOR ' ')
)
)> 0 then concat(
munion.title,
'(',
trim(
group_concat(munion.atitle SEPARATOR ' ')
),
')'
) else munion.title end as title,
munion.py,
munion.unit,
munion.weight,
munion.tid,
munion.amount_max,
munion.poisonous,
munion.is_auxiliary,
munion.is_auxiliary_free,
munion.is_difficult_powder,
munion.brief,
munion.is_fixed_recipe,
-- trim( group_concat( munion.atitle SEPARATOR ' ' ) ) AS atitle,## -- trim( group_concat( munion.apy SEPARATOR ' ' ) ) AS apy,## max(ttid) * 100000 + id AS ttid FROM
(
-- #union start
联合查找,得到全部药材
## (
SELECT
mb.id,
mb.sort_id,
mb.title,
mb.py,
mb.unit,
mb.weight,
mb.tid,
mb.amount_max,
mb.poisonous,
mb.is_auxiliary,
mb.is_auxiliary_free,
mb.is_difficult_powder,
mb.brief,
mb.is_fixed_recipe,
'' AS atitle,
'' AS apy,
CASE WHEN mb.py = 'GC' THEN 3 ELSE CASE WHEN mb.title = 'GC' THEN 3 ELSE 1 END END AS ttid FROM
药材表 AS mb WHERE
mb.tid = 0
AND (
mb.title LIKE '%GC%'
OR mb.py LIKE '%GC%'
)
) --真名药材
结束
## UNION ALL
(
SELECT
mb.id,
mb.sort_id,
mb.title,
mb.py,
mb.unit,
mb.weight,
mb.tid,
mb.amount_max,
mb.poisonous,
mb.is_auxiliary,
mb.is_auxiliary_free,
mb.is_difficult_powder,
mb.brief,
mb.is_fixed_recipe,
CASE WHEN malias.py = 'GC' THEN malias.title ELSE CASE WHEN malias.title = 'GC' THEN malias.title ELSE '' END END AS atitle,
malias.py AS apy,
CASE WHEN malias.py = 'GC' THEN 2 ELSE CASE WHEN malias.title = 'GC' THEN 2 ELSE 1 END END AS ttid FROM
药材表 AS mb LEFT JOIN 药材表 AS malias ON malias.tid = mb.id WHERE
malias.title LIKE '%GC%'
OR malias.py LIKE '%GC%'
) --其他药材结束
## -- #union end## ) munion GROUP BY
id --全部实名药材
结束
## ) m LEFT JOIN (
--个人使用药材统计
开始
## SELECT
count(*) AS total,
rc.i AS m药材表id FROM
处方药材表 AS rc INNER JOIN 药方表AS r ON r.id = rc.药方表_id WHERE
r.did = 40
AND r.timeline > 1576115196
AND rc.type_id in (1, 3)
GROUP BY
rc.i --个人使用药材统计
结束
## ) p ON m.id = p.m药材表id -- mbu end ## ) mbu INNER JOIN (
-- msu start
供应商药材筛选
## SELECT
ms.药材表id,
max(ms.audit) AS audit,
max(ms.price) AS price,
max(ms.market_price) AS market_price,
max(ms.is_granule) AS is_granule,
max(ms.is_decoct) AS is_decoct,
max(ms.is_slice) AS is_slice,
max(ms.is_cream) AS is_cream,
max(ms.is_extract) AS is_extract,
max(ms.is_cream_granule) AS is_cream_granule,
max(ms.is_extract_granule) AS is_extract_granule,
max(ms.is_drychip) AS is_drychip,
max(ms.is_pill) AS is_pill,
max(ms.is_powder) AS is_powder,
max(ms.is_bolus) AS is_bolus FROM
供应商药材表 AS ms INNER JOIN (
SELECT
DISTINCT (ssof.供应商id) AS 供应商id FROM
药库供应商关系表 AS ssof WHERE
ssof.药库id IN (
1, 2, 8, 9, 10, 11, 12, 13, 14, 15, 17, 22,
24, 25, 26, 27, 31, 33
)
AND ssof.药方剂型id IN (1)
) tp ON tp.供应商id= ms.供应商id WHERE
ms.audit = 1
GROUP BY
ms.药材表id -- msu end ## ) msu ON mbu.id = msu.药材表idWHERE
msu.药材表id > 0
AND msu.is_slice = 1order by
total desc,
ttid desc
相关免费学习推荐:mysql视频教程
위 내용은 느린 SQL 최적화 연습 기록의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!