
스울 코루틴이 세 번이나 물었을 때 나는 거의 울 뻔했습니다!

- coldplay.xixi앞으로
- 2020-12-03 17:46:574232검색
swoole 튜토리얼코루틴 관련 면접 질문 소개

추천(무료): swoole 튜토리얼
프로세스란 무엇인가요?
프로세스는 애플리케이션의 시작 인스턴스입니다. 독립적인 파일 자원, 데이터 자원 및 메모리 공간.
스레드란 무엇인가요?
스레드는 프로세스에 속하며 프로그램의 실행자입니다. 프로세스에는 하나 이상의 기본 스레드가 포함되어 있으며 더 많은 하위 스레드가 있을 수도 있습니다. 스레드에는 두 가지 스케줄링 전략이 있습니다. 하나는 시간 공유 스케줄링이고 다른 하나는 선점형 스케줄링입니다.
나의 공식 펭귄 그룹
코루틴이 무엇인가요?
코루틴은 경량 스레드이고, 코루틴도 스레드에 속하며, 코루틴은 스레드에서 실행됩니다. 코루틴의 스케줄링은 사용자가 수동으로 전환하므로 사용자 공간 스레드라고도 합니다. 코루틴의 생성, 전환, 정지, 소멸은 모두 메모리 작업이며 소모량이 매우 적습니다. 코루틴의 스케줄링 전략은 협업 스케줄링입니다.
Swoole 코루틴의 원리
Swoole4는 단일 스레드 및 다중 프로세스이며 동일한 프로세스에서 동시에 실행되는 코루틴은 하나만 있습니다.
Swoole 서버는 데이터를 수신하고 작업자 프로세스에서 onReceive 콜백을 트리거하여 Ctrip을 생성합니다. Swoole은 각 요청에 대해 해당 Ctrip을 생성합니다. 하위 코루틴은 코루틴에서도 생성될 수 있습니다.
코루틴의 기본 구현은 단일 스레드이므로 동시에 작동하는 코루틴은 하나만 있고 코루틴의 실행은 직렬입니다.
그래서 멀티 태스킹과 멀티 코루틴이 실행될 때 하나의 코루틴이 실행되면 다른 코루틴은 작동을 멈춥니다. 차단 IO 작업을 수행할 때 현재 코루틴이 중단되고 기본 스케줄러가 이벤트 루프에 들어갑니다. IO 완료 이벤트가 발생하면 기본 스케줄러는 이벤트에 해당하는 코루틴의 실행을 재개합니다. . 따라서 코루틴은 IO 시간 소비가 없으며 동시성이 높은 IO 시나리오에 매우 적합합니다. (아래 그림 참조)
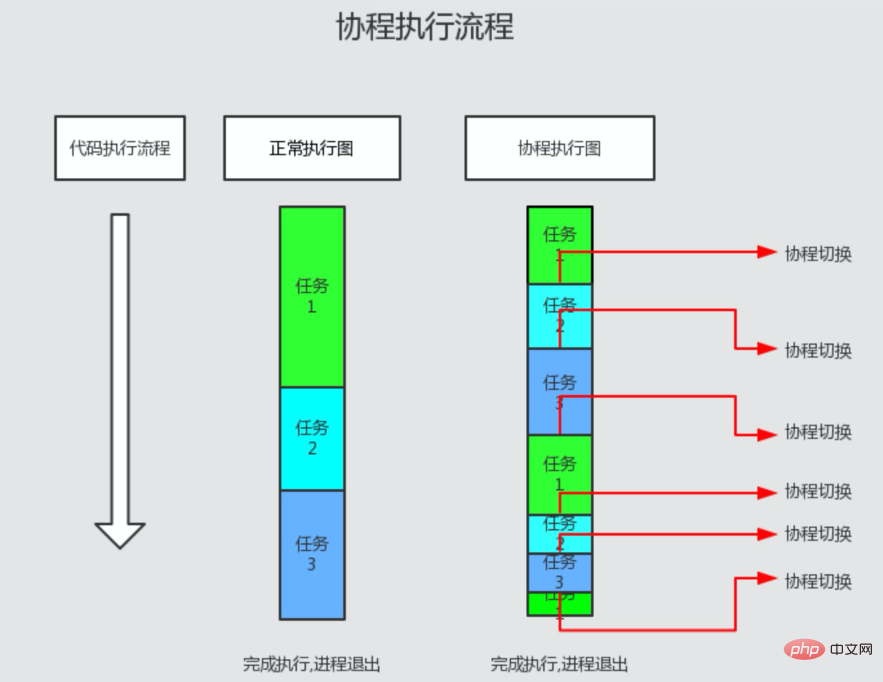
Swoole의 코루틴 실행 프로세스
코루틴에는 IO가 없고 PHP 코드의 정상적인 실행을 기다리며 실행 흐름 전환이 발생하지 않습니다
코루틴 IO를 만나 즉각적인 제어를 기다립니다. IO가 완료된 후 실행 흐름은 원래 코루틴이 잘린 지점으로 다시 전환됩니다
-
코루틴과 병렬 코루틴은 이전 코루틴과 동일한 논리로 순차적으로 실행됩니다
외부에서 내부로 중첩된 코루틴 실행 프로세스 레이어는 IO가 발생할 때까지 들어간 다음 외부 코루틴으로 전환됩니다. 상위 코루틴은 하위 코루틴이 끝날 때까지 기다리지 않습니다.
코루틴의 실행 순서
먼저 기본 예제를 살펴보겠습니다.
go(function () {
echo "hello go1 \n";});echo "hello main \n";go(function () {
echo "hello go2 \n";});
go()는 Co::create()의 약어이며 코루틴을 생성하고 수락하는 데 사용됩니다. 콜백의 코드는 새로 생성된 코루틴에서 실행됩니다. go() 是 Co::create() 的缩写, 用来创建一个协程, 接受 callback 作为参数, callback 中的代码, 会在这个新建的协程中执行.
备注: SwooleCoroutine 可以简写为 Co
上面的代码执行结果:
root@b98940b00a9b /v/w/c/p/swoole# php co.phphello go1 hello main hello go2
执行结果和我们平时写代码的顺序, 好像没啥区别. 实际执行过程:
运行此段代码, 系统启动一个新进程
遇到
go(), 当前进程中生成一个协程, 协程中输出heelo go1, 协程退出进程继续向下执行代码, 输出
hello main再生成一个协程, 协程中输出
heelo go2, 协程退出
运行此段代码, 系统启动一个新进程. 如果不理解这句话, 你可以使用如下代码:
// co.php<?phpsleep (100);
执行并使用 ps aux 查看系统中的进程:
root@b98940b00a9b /v/w/c/p/swoole# php co.php &⏎ root@b98940b00a9b /v/w/c/p/swoole# ps auxPID USER TIME COMMAND 1 root 0:00 php -a 10 root 0:00 sh 19 root 0:01 fish 749 root 0:00 php co.php 760 root 0:00 ps aux ⏎
我们来稍微改一改, 体验协程的调度:
use Co;go(function () {
Co::sleep(1); // 只新增了一行代码
echo "hello go1 \n";});echo "hello main \n";go(function () {
echo "hello go2 \n";});Co::sleep() 函数功能和 sleep() 差不多, 但是它模拟的是 IO等待(IO后面会细讲). 执行的结果如下:
root@b98940b00a9b /v/w/c/p/swoole# php co.phphello main hello go2 hello go1
怎么不是顺序执行的呢? 实际执行过程:
- 运行此段代码, 系统启动一个新进程
- 遇到
go(), 当前进程中生成一个协程 - 协程中遇到 IO阻塞 (这里是
Co::sleep()模拟出的 IO等待), 协程让出控制, 进入协程调度队列 - 进程继续向下执行, 输出
hello main - 执行下一个协程, 输出
hello go2 - 之前的协程准备就绪, 继续执行, 输出
hello go1참고:
SwooleCoroutine은 Co
의 실행 결과입니다. 위 코드:
go(function () {
Co::sleep(1);
echo "hello go1 \n";});echo "hello main \n";go(function () {
Co::sleep(1);
echo "hello go2 \n";});
실행 결과는 우리가 일반적으로 코드를 작성하는 순서와 다르지 않은 것 같습니다. 실제 실행 과정:
🎜🎜🎜이 코드를 실행하면 시스템이 새로운 프로세스를 시작합니다. 🎜🎜🎜🎜 를 발견합니다. go(), 현재 프로세스에서 코루틴이 생성되고가 코루틴에서 출력됩니다. heelo go1, 코루틴이 종료되고 🎜🎜🎜🎜프로세스가 계속해서 코드를 실행하고 hello main🎜🎜🎜🎜 그런 다음 코루틴을 생성하고 코루틴에서 heelo go2를 출력하면 코루틴이 종료됩니다🎜🎜🎜🎜이 코드를 실행하면 시스템이 새 작업을 시작합니다. 프로세스가 이해되지 않으면 다음 코드를 사용할 수 있습니다.🎜root@b98940b00a9b /v/w/c/p/swoole# php co.phphello main hello go1 hello go2 ⏎🎜실행하고
ps aux를 사용하세요. > 시스템의 프로세스를 확인하세요. 🎜$n = 4;for ($i = 0; $i 🎜 약간의 변화와 경험을 해보세요. 코루틴 스케줄링: 🎜<pre class="brush:php;toolbar:false">root@b98940b00a9b /v/w/c/p/swoole# time php co.php1528965075.4608: hello 01528965076.461: hello 11528965077.4613: hello 21528965078.4616: hello 3hello main real 0m 4.02s user 0m 0.01s sys 0m 0.00s ⏎🎜
Co::sleep() 함수 함수와 sleep() code>는 거의 동일하지만 IO 대기를 시뮬레이션합니다(IO에 대해서는 다음에서 설명합니다). 실행 결과는 다음과 같습니다. 🎜<pre class="brush:php;toolbar:false">$n = 4;go(function () use ($n) {
for ($i = 0; $i 🎜왜 순차적으로 실행되지 않나요? 실제 실행 과정: 🎜🎜🎜이 코드를 실행하면 시스템이 새로운 프로세스를 시작합니다. 🎜🎜 <code>go(), 현재 프로세스에서 코루틴이 생성됩니다. 🎜🎜코루틴이 IO 차단을 발견하고(여기서는 <code>Co::sleep()</code> 시뮬레이션된 IO 대기), 코루틴이 제어를 포기하고 코루틴에 들어갑니다. 스케줄링 대기열 🎜🎜프로세스는 아래쪽으로 계속 실행되고 <code>hello main</code>을 출력🎜🎜다음 코루틴을 실행하고 <code>hello go2</code>🎜🎜이전 코루틴이 준비되었습니다. 실행을 계속합니다. 그리고 <code>hello go1</code>🎜🎜🎜을 출력합니다. 이 시점에서 우리는 이미 코루틴과 swoole의 프로세스 사이의 관계와 코루틴의 스케줄링을 볼 수 있습니다. 바로 지금 프로그램을 변경합니다.🎜 <pre class="brush:php;toolbar:false">root@b98940b00a9b /v/w/c/p/swoole# time php co.phphello main1528965150.4834: hello 01528965151.4846: hello 11528965152.4859: hello 21528965153.4872: hello 3real 0m 4.03s
user 0m 0.00s
sys 0m 0.02s
⏎</pre>🎜결과가 어떻게 나오는지 이미 알고 계시리라 생각합니다:🎜<pre class="brush:php;toolbar:false">root@b98940b00a9b /v/w/c/p/swoole# php co.phphello main
hello go1
hello go2
⏎</pre>
<h2>协程快在哪? 减少IO阻塞导致的性能损失</h2>
<p>大家可能听到使用协程的最多的理由, 可能就是 协程快. 那看起来和平时写得差不多的代码, 为什么就要快一些呢? 一个常见的理由是, 可以创建很多个协程来执行任务, 所以快. 这种说法是对的, 不过还停留在表面.</p>
<p>首先, 一般的计算机任务分为 2 种:</p>
<ul>
<li>CPU密集型, 比如加减乘除等科学计算</li>
<li>
<li>IO 密集型, 比如网络请求, 文件读写等</li>
</ul>
<p>其次, 高性能相关的 2 个概念:</p>
<ul>
<li>并行: 同一个时刻, 同一个 CPU 只能执行同一个任务, 要同时执行多个任务, 就需要有多个 CPU 才行</li>
<li>
<li>并发: 由于 CPU 切换任务非常快, 快到人类可以感知的极限, 就会有很多任务 同时执行 的错觉</li>
</ul>
<p>了解了这些, 我们再来看协程, 协程适合的是 IO 密集型 应用, 因为协程在 IO阻塞 时会自动调度, 减少IO阻塞导致的时间损失.</p>
<p>我们可以对比下面三段代码:</p>
<ul><li>普通版: 执行 4 个任务</li></ul>
<pre class="brush:php;toolbar:false">$n = 4;for ($i = 0; $i <pre class="brush:php;toolbar:false">root@b98940b00a9b /v/w/c/p/swoole# time php co.php1528965075.4608: hello 01528965076.461: hello 11528965077.4613: hello 21528965078.4616: hello 3hello main
real 0m 4.02s
user 0m 0.01s
sys 0m 0.00s
⏎</pre></pre>
<ul><li>单个协程版:</li></ul>
<pre class="brush:php;toolbar:false">$n = 4;go(function () use ($n) {
for ($i = 0; $i <pre class="brush:php;toolbar:false">root@b98940b00a9b /v/w/c/p/swoole# time php co.phphello main1528965150.4834: hello 01528965151.4846: hello 11528965152.4859: hello 21528965153.4872: hello 3real 0m 4.03s
user 0m 0.00s
sys 0m 0.02s
⏎</pre></pre>
<ul><li>多协程版: 见证奇迹的时刻</li></ul>
<pre class="brush:php;toolbar:false">$n = 4;for ($i = 0; $i <pre class="brush:php;toolbar:false">root@b98940b00a9b /v/w/c/p/swoole# time php co.phphello main1528965245.5491: hello 01528965245.5498: hello 31528965245.5502: hello 21528965245.5506: hello 1real 0m 1.02s
user 0m 0.01s
sys 0m 0.00s
⏎</pre><p>为什么时间有这么大的差异呢:</p></pre>
<ul>
<li><p>普通写法, 会遇到 IO阻塞 导致的性能损失</p></li>
<li><p>单协程: 尽管 IO阻塞 引发了协程调度, 但当前只有一个协程, 调度之后还是执行当前协程</p></li>
<li><p>多协程: 真正发挥出了协程的优势, 遇到 IO阻塞 时发生调度, IO就绪时恢复运行</p></li>
</ul>
<p>我们将多协程版稍微修改一下:</p>
<ul><li>多协程版2: CPU密集型</li></ul>
<pre class="brush:php;toolbar:false">$n = 4;for ($i = 0; $i <pre class="brush:php;toolbar:false">root@b98940b00a9b /v/w/c/p/swoole# time php co.php1528965743.4327: hello 01528965744.4331: hello 11528965745.4337: hello 21528965746.4342: hello 3hello main
real 0m 4.02s
user 0m 0.01s
sys 0m 0.00s
⏎</pre><p>只是将 <code>Co::sleep() 改成了 sleep(), 时间又和普通版差不多了. 因为:
sleep()可以看做是 CPU密集型任务, 不会引起协程的调度Co::sleep()模拟的是 IO密集型任务, 会引发协程的调度
这也是为什么, 协程适合 IO密集型 的应用.
再来一组对比的例子: 使用 redis
// 同步版, redis使用时会有 IO 阻塞$cnt = 2000;for ($i = 0; $i connect('redis');
$redis->auth('123');
$key = $redis->get('key');}// 单协程版: 只有一个协程, 并没有使用到协程调度减少 IO 阻塞go(function () use ($cnt) {
for ($i = 0; $i connect('redis', 6379);
$redis->auth('123');
$redis->get('key');
}});// 多协程版, 真正使用到协程调度带来的 IO 阻塞时的调度for ($i = 0; $i connect('redis', 6379);
$redis->auth('123');
$redis->get('key');
});}
性能对比:
# 多协程版root@0124f915c976 /v/w/c/p/swoole# time php co.phpreal 0m 0.54s user 0m 0.04s sys 0m 0.23s ⏎# 同步版root@0124f915c976 /v/w/c/p/swoole# time php co.phpreal 0m 1.48s user 0m 0.17s sys 0m 0.57s ⏎
swoole 协程和 go 协程对比: 单进程 vs 多线程
接触过 go 协程的 coder, 初始接触 swoole 的协程会有点 懵, 比如对比下面的代码:
package main
import (
"fmt"
"time")func main() {
go func() {
fmt.Println("hello go")
}()
fmt.Println("hello main")
time.Sleep(time.Second)}
> 14:11 src $ go run test.go hello main hello go
刚写 go 协程的 coder, 在写这个代码的时候会被告知不要忘了 time.Sleep(time.Second), 否则看不到输出 hello go, 其次, hello go与 hello main 的顺序也和 swoole 中的协程不一样.
原因就在于 swoole 和 go 中, 实现协程调度的模型不同.
上面 go 代码的执行过程:
- 运行 go 代码, 系统启动一个新进程
- 查找
package main, 然后执行其中的func mian() - 遇到协程, 交给协程调度器执行
- 继续向下执行, 输出
hello main - 如果不添加
time.Sleep(time.Second), main 函数执行完, 程序结束, 进程退出, 导致调度中的协程也终止
go 中的协程, 使用的 MPG 模型:
- M 指的是 Machine, 一个M直接关联了一个内核线程
- P 指的是 processor, 代表了M所需的上下文环境, 也是处理用户级代码逻辑的处理器
- G 指的是 Goroutine, 其实本质上也是一种轻量级的线程
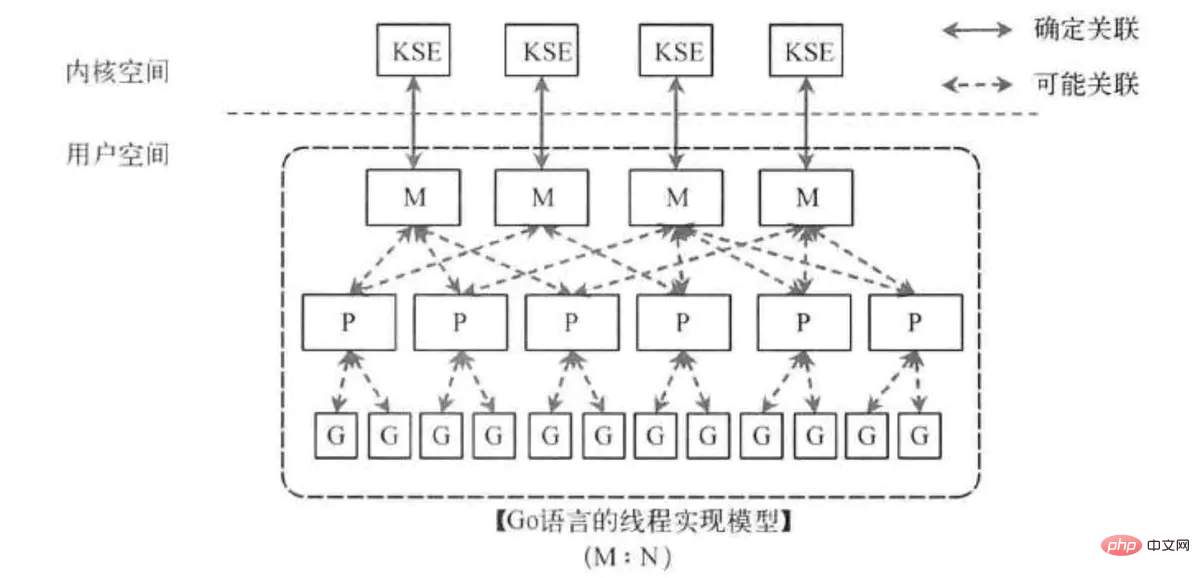
而 swoole 中的协程调度使用 单进程模型, 所有协程都是在当前进程中进行调度, 单进程的好处也很明显 – 简单 / 不用加锁 / 性能也高.
无论是 go 的 MPG模型, 还是 swoole 的 单进程模型, 都是对 CSP理论 的实现.
위 내용은 스울 코루틴이 세 번이나 물었을 때 나는 거의 울 뻔했습니다!의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!