
집 >데이터 베이스 >MySQL 튜토리얼 >관계형 데이터베이스 mysql 3: SQL의 수명 주기부터 시작
관계형 데이터베이스 mysql 3: SQL의 수명 주기부터 시작

- coldplay.xixi앞으로
- 2020-11-13 17:16:473001검색
mysql tutorial 칼럼에서는 관계형 데이터베이스에서 SQL의 수명주기를 소개합니다.
MYSQL 쿼리 처리
sql 실행 프로세스는 기본적으로 mysql 아키텍처와 동일합니다.
실행 프로세스:
. 연결은 SQL 문을 쿼리하고 권한을 결정하는 데 사용됩니다. 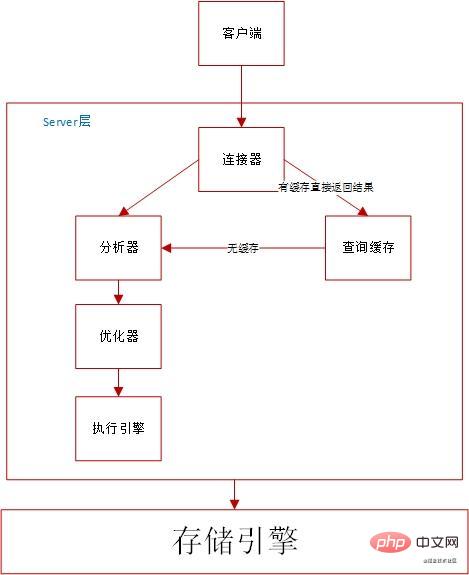
문이 쿼리 캐시에 없으면 후속 실행 단계로 계속됩니다. 실행이 완료된 후 실행 결과는 쿼리 캐시에 저장됩니다. 쿼리가 캐시에 도달하면 MySQL은 후속 복잡한 작업을 수행하지 않고 결과를 직접 반환할 수 있으므로 분석기:
분석기에서는 먼저 구문 분석을 수행합니다. 어휘 분석을 수행합니다. SQL 문의 구성 요소를 분석합니다. 입력된 SQL 문이 구문 규칙을 만족하는지 확인합니다.
- 최적화 프로그램:
- 최적화 프로그램은 테이블에 여러 인덱스가 있거나 명령문에 여러 테이블 연결(조인)이 있는 경우 사용할 인덱스를 결정하며 각 테이블의 연결 순서를 결정합니다. 다양한 실행 방법의 논리적 결과는 동일하지만 실행 효율성은 다르며, 어떤 솔루션을 사용할지 결정하는 것이 옵티마이저의 역할입니다.
- Executor:
실행 계획 이해하기
EXPLAIN 명령은 MySQL이 SQL 문을 실행하는 방법을 출력하지만 데이터를 반환하지 않음- 사용방법
[root@localhost][(none)]> explain select * from 表名 where project_id = 36; +----+-------------+--------------------------+------------+------+---------------+------------+---------+-------+--------+----------+-------+ | id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra | +----+-------------+--------------------------+------------+------+---------------+------------+---------+-------+--------+----------+-------+ | 1 | SIMPLE | 表名 | NULL | ref | project_id | project_id | 4 | const | 797964 | 100.00 | NULL | +----+-------------+--------------------------+------------+------+---------------+------------+---------+-------+--------+----------+-------+复制代码
id
id가 다르며, id 값이 클수록 우선 순위가 높을수록 빨리 실행됩니다
select_type
SIMPLE: 단순 선택 쿼리, 쿼리에 하위 쿼리나 공용체가 포함되어 있지 않음- PRIMARY: 쿼리에 하위 부분이 포함되어 있고 가장 바깥쪽 쿼리가 기본 쿼리로 표시됨
- DERIVED:
- MATERIALIZED: where 뒤에 있는 in 조건의 하위 쿼리를 의미합니다.
- UNION: Union의 두 번째 또는 두 번째를 의미합니다. 다음 select 문
- table
- Table 개체
- type
- system > > 범위 > 인덱스 > ALL (쿼리 효율성)
- system:表中只有一条数据,这个类型是特殊的const类型
- const:针对于主键或唯一索引的等值查询扫描,最多只返回一个行数据。速度非常快,因为只读取一次即可。
- eq_ref:此类型通常出现在多表的join查询,表示对于前表的每一个结果,都只能匹配到后表的一行结果,并且查询的比较操作通常是=,查询效率较高
- ref:此类型通常出现在多表的join查询,针对于非唯一或非主键索引,或者是使用了最左前缀规则索引的查询
- range:范围扫描 这个类型通常出现在 <>, >, >=, <, <=, IS NULL, <=>, BETWEEN, IN() 操作中
- index:索引树扫描
- ALL:全表扫描(full table scan)
- 可能使用的索引,注意不一定会使用
- 查询涉及到的字段上若存在索引,则该索引将被列出来
- 当该列为NULL时就要考虑当前的SQL是否需要优化了
- 显示MySQL在查询中实际使用的索引,若没有使用索引,显示NULL。
- 查询中若使用了覆盖索引(覆盖索引:索引的数据覆盖了需要查询的所有数据),则该索引仅出现在key列表中
- 索引长度
- 表示上述表的连接匹配条件,即哪些列或常量被用于查找索引列上的值
- 返回估算的结果集数目,并不是准确的值
- 示返回结果的行数占需读取行数的百分比, filtered 的值越大越好
- Using where:表示优化器需要通过索引回表,之后到server层进行过滤查询数据
- Using index:表示直接访问索引就足够获取到所需要的数据,不需要回表
- Using index condition:在5.6版本后加入的新特性(Index Condition Pushdown)
- Using index for group-by:使用了索引来进行GROUP BY或者DISTINCT的查询
- Using filesort:当 Extra 中有 Using filesort 时, 表示 MySQL 需额外的排序操作, 不不能通过索引顺序达到排序效果. 一般有 Using filesort, 都建议优化去掉, 因为这样的查询 CPU 资源消耗大
- Using temporary 临时表被使用,时常出现在GROUP BY和ORDER BY子句情况下。(sort buffer或者磁盘被使用)
possible_keys
key
key_length
ref
rows
filtered
extra
光看 filesort 字面意思,可能以为是要利用磁盘文件进行排序,实则不全然。 当MySQL不能使用索引进行排序时,就会利用自己的排序算法(快速排序算法)在内存(sort buffer)中对数据进行排序,如果内存装载不下,它会将磁盘上的数据进行分块,再对各个 数据块进行排序,然后将各个块合并成有序的结果集(实际上就是外排序)。
当对连接操作进行排序时,如果ORDER BY仅仅引用第一个表的列,MySQL对该表进行filesort操作,然后进行连接处理,此时,EXPLAIN输出“Using filesort”;否则,MySQL必 须将查询的结果集生成一个临时表,在连接完成之后行行filesort操作,此时,EXPLAIN输出“Using temporary;Using filesort”。
提高查询效率
正确使用索引
为解释方便,来一个demo:
DROP TABLE IF EXISTS user; CREATE TABLE user( id int AUTO_INCREMENT PRIMARY KEY, user_name varchar(30) NOT NULL, gender bit(1) NOT NULL DEFAULT b’1’, city varchar(50) NOT NULL, age int NOT NULL )ENGINE=InnoDB DEFAULT CHARSET=utf8; ALTER TABLE user ADD INDEX idx_user(user_name , city , age); 复制代码
什么样的索引可以被使用?
- **全匹配:**SELECT * FROM user WHERE user_name='JueJin'AND age='5' AND city='上海';(与where后查询条件的顺序无关)
- 匹配最左前缀:(user_name )、(user_name, city)、(user_name , city , age)(满足最左前缀查询条件的顺序与索引列的顺序无关,如:(city, user_name)、(age, city, user_name))
- **匹配列前缀:**SELECT * FROM user WHERE user_name LIKE 'W%'
- **匹配范围值:**SELECT * FROM user WHERE user_name BETWEEN 'W%' AND 'Z%'
什么样的索引无法被使用?
- **where查询条件中不包含索引列中的最左索引列,则无法使用到索引: **
SELECT * FROM user WHERE city='上海';
SELECT * FROM user WHERE age='26';
SELECT * FROM user WHERE age='26' AND city=‘上海';
- ** where가 가장 왼쪽 인덱스 열인 경우에도 해당 인덱스를 사용하여 사용자 이름이 N으로 끝나는 사용자를 쿼리할 수 없습니다: **
SELECT * FROM user WHERE user_name LIKE '%N';
** where 쿼리 조건에 해당 컬럼의 범위 쿼리가 있는 경우 그 오른쪽의 모든 컬럼은 인덱스 최적화 쿼리를 사용할 수 없습니다: **- SELECT * FROM user WHERE user_name='JueJin' AND city LIKE '上%' AND age= 31;
- SELECT * FROM user WHERE user_name=concat(user_name,'PLUS');
적절한 인덱스 열 순서를 선택하세요.
복합 인덱스를 생성할 때 인덱스 열의 순서는 매우 중요합니다. 올바른 인덱스 순서는 쿼리 방법에 따라 다릅니다. 인덱스 사용- 복합 인덱스의 인덱스 순서는 선택 가능합니다. 이 규칙은 접두 인덱스의 선택 방식과 일치합니다. 이는 모든 결합 인덱스의 순서를 의미하지는 않습니다. 이 규칙을 사용하여 특정 인덱스를 결정할 수 있습니다. 순서
- Covered 인덱스 조건
- SELECT user_name, city, age FROM user WHERE user_name='Tony' AND age= '28' AND city='Shanghai';
Using index
로, 커버링 인덱스가 사용되었음을 증명합니다. 액세스 성능을 크게 향상시킬 수 있습니다.ORDER BY 절을 충족해야 합니다. 이후의 컬럼 순서는 결합된 인덱스의 컬럼 순서와 일치해야 하며, 모든 정렬 컬럼의 정렬 방향(정/역순)이 일관되어야 합니다. 쿼리된 필드 값이 인덱스 컬럼에 포함되어야 하며, 포함 색인정렬에 인덱스 사용
정렬 작업 중에 인덱스를 사용하여 정렬할 수 있다면 정렬 속도를 크게 향상시킬 수 있습니다.
- 정렬 사용 가능한 데모:
- SELECT user_name, city, age FROM user_test WHERE user_name='Tony' ORDER BY city;
- 사용할 수 없는 데모 정렬:
- SELECT user_name, city, age FROM user_test ORDER BY user_name gender
- gender
- FROM user_test ORDER BY user_name; SELECT user_name, city, age FROM user_test ORDER BY user_name ASC
- ,city DESC; 이름, 도시 , age FROM user_test WHERE user_name LIKE 'W%'
- ORDER BY city;데이터 획득 제안
- 사용자 프로그램에서 필요하지 않은 데이터는 반환하지 마세요. 반환 횟수를 제한하세요
: MySQL은 필요한 만큼의 데이터를 반환할 수 없습니다. 즉, MySQL은 항상 모든 데이터를 쿼리합니다. LIMIT 절을 사용하는 것은 실제로 네트워크 데이터 전송의 부담을 줄이기 위한 것이며 읽혀지는 데이터 행 수를 줄이지 않습니다.
불필요한 열 제거
SELECT * 문은 필드의 데이터가 호출 애플리케이션에 유용한지 여부에 관계없이 테이블의 모든 필드를 제거합니다. 이는 서버 리소스를 낭비하고 서버 성능에 영향을 미칠 수도 있습니다. 향후 테이블 구조가 변경되면 SELECT * 문에서 잘못된 데이터가 나올 수 있습니다.
SELECT * 문을 실행할 때는 먼저 테이블에 어떤 열이 있는지 확인한 후 SELECT * 문을 실행해야 합니다. 경우에 따라 성능 문제가 발생할 수 있습니다. SELECT * 문을 사용하면 인덱스가 포함되지 않아 쿼리 성능 최적화에 도움이 되지 않습니다.
- 인덱스를 올바르게 사용하는 경우의 이점
-
- 전체 테이블 스캔 방지
- 단일 테이블을 쿼리할 때 전체 테이블 스캔은 모든 행을 쿼리해야 합니다.
- 여러 테이블을 쿼리할 때 전체 테이블 스캔은 모든 테이블의 최소한 모든 행을 검색해야 합니다.
- 속도 향상
- 결과 집합의 첫 번째 행을 빠르게 찾을 수 있습니다
- 관련 없는 결과 제외
- 모든 행에서 MIN() 또는 MAX() 값을 확인할 필요가 없습니다
- 정렬 효율성 향상 및 그룹핑
- 커버링 인덱스를 사용할 수 있는 경우 행 루프업 방지 비용
index
- 인덱스가 너무 많으면 데이터 수정 속도가 느려집니다
- 해당 인덱스를 업데이트해야 합니다
- 쓰기 집약적인 환경에서는 매우 스트레스가 됩니다
- 인덱스는 너무 많은 디스크 공간을 소비합니다.
- InnoDB 스토리지 엔진은 인덱스와 데이터를 함께 저장합니다.
- 디스크 공간을 모니터링해야 합니다.
인덱스 모범 사례
인덱스 사용을 고려하세요. 다음 열의 경우
- WHERE 절
- ORDER BY 또는 GROUP BY 절의 열
- 테이블 조인 조건 열
문자열 열에 접두사 인덱스 사용을 고려하세요
- 더 빠르게 비교하고 루프할 수 있습니다.
- 디스크 줄이기 I/ O
select 문 효율성이 낮은 경우 전체 테이블 스캔을 피하는 것이 좋습니다
- 인덱스를 늘려보세요
- where 문
- 테이블 연결 조건
- Analyze Table을 사용하여 통계 정보 수집
- 스토리지 엔진 계층을 고려하여 스토리지 엔진 계층 최적화
- 테이블 조인 방법 조정
ON 또는 USING 절의 열에 인덱스 추가
- SELECT STRAIGHT_JOIN을 사용하여 테이블 연결 순서 강제 적용
- 인덱스 추가 ORDER BY 및 GROUP BY
- join 열이 반드시 하위 쿼리보다 효율적인 것은 아닙니다
mysql tutorial(동영상)
위 내용은 관계형 데이터베이스 mysql 3: SQL의 수명 주기부터 시작의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!