
집 >데이터 베이스 >MySQL 튜토리얼 >울어..MySQL 인덱스를 잘 아는줄 알았는데
울어..MySQL 인덱스를 잘 아는줄 알았는데

- coldplay.xixi앞으로
- 2020-11-04 17:24:182094검색
mysql 동영상 튜토리얼칼럼에서는 실제 인덱스를 소개합니다.

관련 무료 학습 권장사항: mysql 동영상 튜토리얼
1. 인덱스란 무엇인가요?
관계형 데이터베이스에서 인덱스는 데이터베이스 테이블에 있는 하나 이상의 열 값을 정렬하는 별도의 물리적 저장 구조이며, 테이블에 있는 하나 이상의 열 값과 해당 A의 집합입니다. 이러한 값을 물리적으로 식별하는 테이블의 데이터 페이지에 대한 논리적 포인터 목록입니다. 색인은 책의 목차와 같습니다. 목차의 페이지 번호를 기준으로 원하는 내용을 빠르게 찾을 수 있습니다.
테이블에 레코드가 많을 때 테이블을 쿼리하고 싶을 때, 정보를 검색하는 첫 번째 방법은 테이블 전체를 검색하는 것, 즉 모든 레코드를 하나씩 꺼내서 비교하는 것입니다. 쿼리 조건을 사용하여 조건을 충족하는 레코드를 반환하면 데이터베이스 시스템 시간이 많이 소모되고 두 번째는 테이블에 인덱스를 생성하는 것입니다. 그런 다음 쿼리 조건에 맞는 인덱스 값을 인덱스에서 찾고, 마지막으로 인덱스에 저장된 ROWID(ROWID)(페이지 번호와 동일)를 전달하면 테이블에서 해당 레코드를 빠르게 찾을 수 있습니다.
MySQL5.5 이후 InnoDB 스토리지 엔진에서 사용되는 인덱스 데이터 구조는 주로 다음을 사용합니다. B+Tree; 이 기사에서는 B+Tree의 과거와 현재의 삶에 대해 이야기합니다.
**Mark**
:
B+Tree는 와일드카드로 시작하지 않는 , >=, BETWEEN, IN 및 LIKE에 대한 인덱스를 사용할 수 있습니다. (MySQL 5.5 이후)
이러한 사실은 귀하가 읽은 다른 기사나 책 등 일부 인식을 뒤집을 수 있습니다. 위의 모든 항목은 "범위 쿼리"이며 색인이 생성되지 않습니다!
그렇습니다. 5.5 이전에는 옵티마이저가 인덱스를 통한 검색을 선택하지 않았습니다. 옵티마이저는 이 방법으로 검색한 행이 전체 테이블 스캔의 행보다 많다고 믿었습니다. 왜냐하면 여전히 테이블로 돌아가야 하기 때문입니다. I/O가 포함될 수 있으며 행 수가 많아 최적화 프로그램에서 삭제됩니다.
알고리즘 최적화(B+Tree) 후 일부 범위 유형의 스캔을 지원합니다(B+Tree 데이터 구조의 질서를 활용). 이 접근 방식은 또한 가장 왼쪽 접두사 원칙을 위반하므로 범위 쿼리 이후의 조건이 결합 인덱스를 사용할 수 없게 됩니다. 이에 대해서는 나중에 자세히 설명하겠습니다.
2. 인덱스의 장점과 단점
1. 장점
- 인덱스는 서버가 스캔해야 하는 데이터의 양을 크게 줄입니다.
- 인덱스는 서버가 정렬 및 임시 테이블을 피하는 데 도움이 됩니다.
- 인덱스는 무작위 I/ O를 시퀀스 I/O로
2. 단점
- 인덱스를 사용하면 쿼리 속도가 크게 향상되지만 테이블에 대한 INSERT, UPDATE, DELETE 등의 업데이트 속도도 느려집니다. 테이블을 업데이트할 때 MySQL은 데이터를 저장할 뿐만 아니라 인덱스 파일도 저장해야 하기 때문입니다.
- 인덱스 파일을 생성하면 디스크 공간을 차지하게 됩니다. 일반적으로 이 문제는 심각하지 않지만, 큰 테이블에 여러 개의 조합 인덱스를 생성하여 많은 양의 데이터를 삽입하면 인덱스 파일 크기가 급격히 늘어나게 됩니다.
- 데이터 열에 반복되는 내용이 많으면 색인을 생성해도 실질적인 효과가 크지 않습니다.
- 매우 작은 테이블의 경우 대부분의 경우 간단한 전체 테이블 스캔이 더 효율적입니다.
따라서 가장 자주 쿼리되고 가장 자주 정렬되는 데이터 열만 인덱싱되어야 합니다. (MySQL에서는 동일한 데이터 테이블의 인덱스 총 개수는 16개로 제한됩니다.)
데이터베이스의 존재 의미 중 하나는 데이터 저장과 빠른 검색을 해결하는 것입니다. 그렇다면 데이터베이스의 데이터는 어디에 존재합니까? 그렇죠, 디스크입니다. 디스크의 장점은 무엇인가요? 값이 싼! 단점은 어떻습니까? 메모리 접근보다 느립니다.
그렇다면 MySQL 인덱스에서 주로 사용하는 데이터 구조를 알고 계시나요?
B+트리! 당신은 무심코 말했다.
B+ 트리는 어떤 데이터 구조인가요? MySQL이 인덱스로 B+ 트리를 선택한 이유는 무엇입니까?
사실 B+ 트리의 최종 선택은 오랜 진화를 거쳤습니다.
Binary sorting tree → Binary Balanced Tree → B-Tree(B 트리) → B+Tree(B+ 트리) )
몇몇 친구들이 "B-tree와 B-tree의 차이점이 무엇인가요?"라고 물었습니다. 여기서 일반화하면 MySQL 데이터 구조는 B-Tree(B 트리)와 B+Tree(B+ 트리)만 존재하는데, 대부분은 단지 발음만 다를 뿐 일반적으로 B-Tree라고 부르기도 합니다. B-트리. ~~
그리고 친구들이 언급한 레드-블랙 트리는 MySQL이 아닌 프로그래밍 언어의 저장 구조입니다. 예를 들어 Java의 HashMap은 링크드 리스트와 레드-블랙 트리를 사용합니다.
자, 오늘은 B+트리로 진화하는 과정을 안내해드리겠습니다.
3. B+트리 인덱스의 과거와 현재 수명
1. 이진 정렬 트리
B+ 트리를 이해하기 전에 먼저 이진 정렬 트리에 대해 간략하게 설명하겠습니다. 노드의 경우 왼쪽 하위 트리의 자식 노드 값이 더 작아야 합니다. 자신보다 오른쪽 하위 트리의 하위 노드 값이 자신보다 큽니다. 모든 노드가 이 조건을 충족하면 이진 정렬 트리입니다. (여기서 이진 검색의 지식 포인트를 연결할 수 있습니다.) 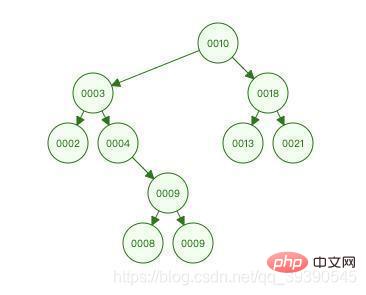
위 그림은 이진 정렬 트리의 특성을 사용하여 9를 찾는 과정을 경험해 볼 수 있습니다.
- 9는 10보다 작습니다. 왼쪽 하위 트리(노드 3)는 3보다 큰
- 9를 검색합니다. 노드 3(노드 4)의 오른쪽 하위 트리로 이동하여
- 9가 4보다 큰 것을 찾습니다. 노드 4(노드 9)의 오른쪽 하위 트리에서
- 노드 9와 9가 동일하여 검색에 성공했습니다
총 4번의 비교가 이루어졌습니다. 위 구조를 최적화하는 방법에 대해 생각해 본 적이 있나요?
2. AVL 트리(자체 균형 이진 검색 트리)
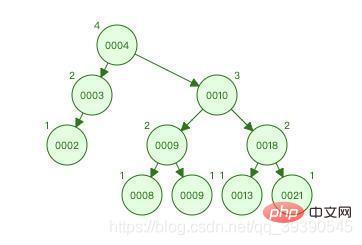
위 그림은 AVL 트리입니다. 노드의 수와 값은 이진 정렬 트리와 정확히 같습니다.
그 과정을 살펴보겠습니다. 9를 찾으면:
- 9가 4보다 크면 오른쪽 하위 트리로 가서
- 9가 10보다 작으면 왼쪽 하위 트리로 가서
- 노드 9가 9와 같으면 검색에 성공합니다
총 3번 비교하면 동일한 데이터의 수량이 이진 정렬 트리의 수보다 1개 적습니다. 이유는 무엇입니까? AVL 트리의 높이는 이진 정렬 트리의 높이보다 작기 때문에 높이가 높을수록 이 최적화 시간을 과소평가하지 마십시오. 비교하면 확연히 달라집니다.
1백만 개의 노드와 20의 트리 높이를 가진 균형 잡힌 이진 트리를 상상할 수 있습니다. 쿼리는 20개의 데이터 블록에 액세스해야 할 수도 있습니다. 기계식 하드디스크 시대에는 디스크에서 데이터 블록을 무작위로 읽는 데 약 10ms의 탐색 시간이 걸렸다. 즉, 100만 개의 행이 있는 테이블의 경우 이진 트리를 사용하여 저장하면 단일 행에 액세스하는 데 20 10ms가 걸릴 수 있습니다. 이 쿼리는 정말 느립니다.
3. B-트리(균형 트리) 다중 방향 균형 탐색 트리
B-트리는 다중 방향 자체 균형 탐색 트리입니다. 각 노드가 더 많은 자식을 가질 수 있습니다. B-트리의 개략도는 다음과 같습니다.
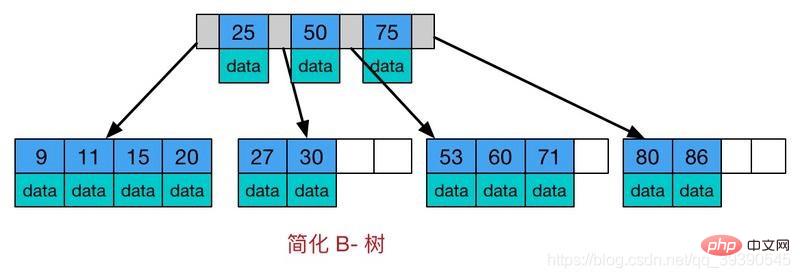
B-트리의 특징:
- 모든 키 값은 트리 전체에 분산됩니다.
- 모든 키워드가 나타나며 하나의 노드에만 나타납니다.
- 리프가 아닌 노드에서도 검색이 가능합니다. 끝
- 전체 키워드 집합에서 검색을 수행하면 성능은 이진 검색 알고리즘에 가깝습니다.
효율성을 높이려면 디스크 I/O 개수를 줄여야 합니다. 최소화됩니다. 실제 프로세스에서는 매번 요청 시 디스크를 엄격하게 읽지 않고 매번 미리 읽습니다.
디스크가 필요한 데이터를 읽은 후 순서대로 더 많은 데이터를 메모리로 읽어옵니다. 이에 대한 이론적 근거는 컴퓨터 과학에서 언급한 지역성 원칙입니다.
- 디스크에서 순차적 읽기의 효율성이 매우 높기 때문입니다. 높음 높음(어드레싱 시간이 필요하지 않고 회전 시간이 거의 없음)이므로 지역성이 있는 프로그램의 경우 사전 읽기는 I/O 효율성을 향상시킬 수 있습니다. 일반적으로 사전 읽기 길이는 페이지의 정수배입니다.
- MySQL(기본적으로 InnoDB 엔진 사용)은 레코드를 페이지 단위로 관리하며, 각 페이지의 기본 크기는 16K(수정 가능)입니다.
B-Tree는 컴퓨터 디스크 사전 읽기 메커니즘을 사용합니다.
새 노드가 생성될 때마다 한 페이지의 공간이 적용되므로 실제로는 각 노드 검색에 하나의 I/O만 필요합니다. 애플리케이션의 경우 노드 깊이가 매우 적으므로 검색 효율성이 매우 높습니다. 그러면 B+ 트리의 최종 버전은 어떻게 만들어 집니까?
4. B+ 트리(B+ 트리는 B 트리의 변형이자 다중 방향 검색 트리입니다.)
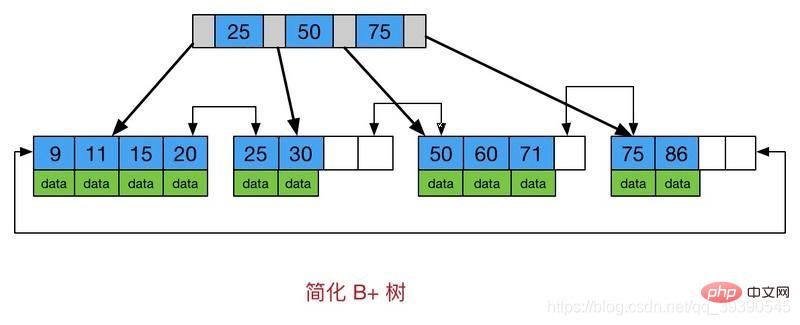 B+ 트리와 B 트리의 차이점은 다음과 같습니다.
B+ 트리와 B 트리의 차이점은 다음과 같습니다.
- 모든 키워드는 리프 노드에 저장됩니다. 비리프 노드는 실제 데이터를 저장하지 않으므로 리프 노드를 빠르게 찾을 수 있습니다.
- 모든 리프 노드에 체인 포인터 를 추가합니다. 이는 모든 값이 순서대로 저장되고 각 리프 페이지에서 루트까지의 거리가 동일하므로 범위 데이터를 찾는 데 매우 적합합니다.
- ** 따라서 B+Tree는 와일드카드로 시작하지 않는 , >=, BETWEEN, IN 및 LIKE에 대한 인덱스를 사용할 수 있습니다. **
- B+ 트리의 디스크 읽기 및 쓰기 비용이 더 저렴합니다
- B+ 트리의 쿼리 효율성이 더 안정적입니다
알아야 할 것은 테이블을 생성할 때마다 시스템이 자동으로 ID 기반의 테이블을 생성한다는 것입니다. 클러스터형 인덱스(위의 B+ 트리)는 모든 데이터를 저장합니다. 인덱스를 추가할 때마다 데이터베이스는 사용자를 위해 추가 인덱스(위에서 언급한 B+ 트리)를 생성합니다. 각 노드에 저장된 데이터 인덱스 수. 이 인덱스는 모든 데이터를 저장하지 않습니다.
4. MySQL이 인덱스로 B 트리 대신 B+ 트리를 선택하는 이유는 무엇입니까?
- B+ 트리는 외부 저장소(일반적으로 디스크 저장소를 나타냄)에 더 적합합니다. 내부 노드(비리프 노드)는 데이터를 저장하지 않기 때문에 하나의 노드는 더 많은 내부 노드를 저장할 수 있으며 각 노드는 더 크고 더 많은 인덱스를 생성할 수 있습니다. 정확한 범위. 즉, B+ 트리를 사용하는 단일 디스크 I/O의 정보량은 B 트리보다 많고, I/O 효율도 더 높다.
- MySQL은 관계형 데이터베이스이고 간격에 따라 인덱스 열에 액세스하는 경우가 많습니다. B+ 트리의 리프 노드 사이에 체인 포인터가 순서대로 설정되어 간격 액세스가 향상되므로 B+ 트리는 간격 범위에 매우 편리합니다. 인덱스 열에 대한 쿼리. B-트리의 각 노드의 키와 데이터가 함께 있으므로 구간 검색을 수행할 수 없습니다.
5. 프로그래머들이 알아야 할 인덱스 지식 포인트
1. 테이블 반환 쿼리
예를 들어 이름과 나이 인덱스를 name_age_index로 생성하면 데이터 쿼리 시
select * from table where name ='陈哈哈' and age = 26; 1复制代码
를 사용합니다. 그리고 age는 추가 인덱스에 있으므로 인덱스에 도달한 후 데이터베이스는 다른 데이터를 찾기 위해 클러스터형 인덱스로 돌아가야 합니다. 이것이 테이블 반환을 기억한 이유이기도 합니다. select * less를 사용하세요.
2. 인덱스 적용 범위
테이블 반환과 결합하면 더 잘 이해됩니다. 예를 들어 위의 name_age_index 인덱스에는 쿼리
select name, age from table where name ='陈哈哈' and age = 26; 1复制代码
이 때 선택된 필드 name과 age를 인덱스 name_age_index에서 얻을 수 있습니다. 따라서 Index Coverage를 만족하는 테이블로 돌아갈 필요가 없으며, Index의 데이터를 직접 반환하므로 매우 효율적입니다. 이는 최적화 시 DBA 학생들이 선호하는 최적화 방법입니다.
3. 가장 왼쪽 접두사 원칙
B+ 트리의 노드 저장 인덱스 순서는 왼쪽에서 오른쪽으로 저장됩니다. 일반적으로 조인트 인덱스를 만들 때 왼쪽에서 오른쪽으로 일치하는 것이 자연스럽습니다. 여러 필드에 대한 인덱스 생성에 대한 것입니다. 인덱스를 생성한 학생들은 예를 들어 세 필드에 대한 공동 인덱스를 생성하려는 경우 Oracle과 MySQL 모두에서 인덱스 순서를 선택할 수 있다는 것을 알게 될 것입니다. a, b, c, 원하는 우선순위(a, b, c, b, a, c 또는 c, a, b 등)를 선택할 수 있습니다. 데이터베이스에서 필드 순서를 선택할 수 있는 이유는 무엇입니까? 모두 3개 분야의 공동지수 아닌가요? 이는 데이터베이스 인덱스의 가장 왼쪽 접두사 원칙으로 이어집니다.
개발 과정에서 이 필드에 대해 공동 인덱스가 생성되었지만 SQL이 이 필드를 쿼리할 때 인덱스가 사용되지 않는 문제에 자주 직면합니다. 예를 들어, abc_index 인덱스(a, b, c)는 a, b, c 세 필드의 결합 인덱스입니다. 다음 sql이 실행되면 abc_index 인덱스를 적중할 수 없습니다. 다음 세 가지 상황이 발생합니다. 인덱스를 사용하도록 설정:
select * from table where c = '1'; select * from table where b ='1' and c ='2'; 123复制代码
위의 두 가지 예에서 단서를 찾을 수 있나요?
예, 인덱스 abc_index: (a,b,c)는 (a), (a,b) 및 (a,b,c)의 세 가지 유형의 쿼리에만 사용됩니다. 사실 여기에는 약간의 모호함이 있습니다. 실제로 (a,c)도 사용되지만 a 필드 인덱스만 사용되며 c 필드는 사용되지 않습니다.
또한, 다음 유형에서는 a와 b만 색인화되고, c는 색인화되지 않는 특별한 경우가 있습니다.
select * from table where a = '1'; select * from table where a = '1' and b = '2'; select * from table where a = '1' and b = '2' and c='3'; 12345复制代码
위 유형의 SQL 문처럼 a와 b가 인덱싱된 후 c는 이미 순서가 어긋나 있으므로 c는 인덱싱할 수 없습니다. 옵티마이저는 테이블 전체에서 c 필드를 스캔하는 것이 더 낫다고 생각할 것입니다. 빠른.
**가장 왼쪽 접두사: 이름에서 알 수 있듯이 가장 왼쪽 우선순위를 의미합니다. 위 예에서는 a_b_c 다중 열 인덱스를 생성했는데, 이는 (a) 단일 열 인덱스, (a,b) 결합을 생성하는 것과 같습니다. 인덱스 및 (a,b,c) 결합 인덱스. **
따라서 다중 열 인덱스를 생성할 때 비즈니스 요구에 따라 where 절에서 가장 자주 사용되는 열이 가장 왼쪽에 배치됩니다.
4. 인덱스 푸시다운 최적화
또는 인덱스 name_age_index에는 다음 sql
select * from table where a = '1' and b > '2' and c='3'; 1复制代码
이 있습니다. 이 문에는 두 가지 실행 가능성이 있습니다.
name_age_index 공동 인덱스를 조회하고 이름이 "Chen"으로 시작하는 모든 데이터를 쿼리합니다. 그런 다음 테이블 쿼리를 만족하는 모든 행을 반환합니다.- name_age_index 공동 인덱스를 조회하고 이름이 "陈"로 시작하는 모든 데이터를 쿼리한 다음 age>20의 인덱스를 필터링한 다음 테이블로 돌아와 전체 데이터 행을 쿼리합니다.
- 분명히 두 번째 방법은 테이블 쿼리에 더 적은 수의 행을 반환하고 I/O 수도 줄어듭니다. 이는 인덱스 푸시다운입니다. 따라서 모든 좋아요가 색인에 도달하지 않는 것은 아닙니다.
6. 인덱스 사용 시 주의사항
1. 인덱스에는 Null 값이 포함된 열이 포함되지 않습니다.
해당 열에 Null 값이 포함되어 있는 한 해당 열은 인덱스에 포함되지 않습니다. 복합 인덱스에 null 값이 포함되어 있으면 이 열은 이 복합 인덱스에 유효하지 않습니다. 따라서 데이터베이스를 설계할 때 필드의 기본값을 null로 두지 않는 것이 좋습니다.
2、使用短索引
对串列进行索引,如果可能应该指定一个前缀长度。例如,如果有一个char(255)的列,如果在前10个或20个字符内,多数值是惟一的,那么就不要对整个列进行索引。短索引不仅可以提高查询速度而且可以节省磁盘空间和I/O操作。
3、索引列排序
查询只使用一个索引,因此如果where子句中已经使用了索引的话,那么order by中的列是不会使用索引的。因此数据库默认排序可以符合要求的情况下不要使用排序操作;尽量不要包含多个列的排序,如果需要最好给这些列创建复合索引。
4、like语句操作
一般情况下不推荐使用like操作,如果非使用不可,如何使用也是一个问题。like “%陈%” 不会使用索引而like “陈%”可以使用索引。
5、不要在列上进行运算
这将导致索引失效而进行全表扫描,例如
SELECT * FROM table_name WHERE YEAR(column_name)<h2 data-id="heading-21">6、不使用not in和操作</h2><p>这不属于支持的范围查询条件,不会使用索引。</p><h1 data-id="heading-22">我的体会</h1><p> 曾经,我一度以为我很懂MySQL。</p><p> 刚入职那年,我还是个孩子,记得第一个需求是做个统计接口,查询近两小时每隔5分钟为一时间段的网站访问量,JSONArray中一共返回24个值,当时菜啊,写了个接口循环二十四遍,发送24条SQL去查(捂脸),由于那个接口,被技术经理嘲讽~~表示他写的SQL比我吃的米都多。虽然我们山东人基本不吃米饭,但我还是羞愧不已。。<br>然后经理通过调用一个dateTime函数分组查询处理一下,就ok了,效率是我的几十倍吧。从那时起,我就定下目标,深入MySQL学习,万一日后有机会嘲讽回去?</p><p> 筒子们,MySQL路漫漫,其修远兮。永远不要眼高手低,一起加油,希望本文能对你有所帮助。</p>
위 내용은 울어..MySQL 인덱스를 잘 아는줄 알았는데의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!