
Python의 정규식에 대한 자세한 설명

- coldplay.xixi앞으로
- 2020-11-03 16:54:303989검색
python教程栏目讲解正则表达式知识。

正则表达式应用的场景也非常多。常见的比如:搜索引擎的搜索、爬虫结果的匹配、文本数据的提取等等都会用到,所以掌握甚至精通正则表达式是一个硬性技能,非常必要。
正则表达式
正则表达式是一个特殊的字符序列,由普通字符和元字符组成。元字符能帮助你方便的检查一个字符串是否与某种模式匹配。
Python中则提供了强大的正则表达式处理模块,即 re 模块, 为Python的内置模块。
下面,我带大家来一个入门demo例子,代码如下:
import rereg_string = "hello9527python@wangcai.@!:xiaoqiang" reg = "hello"result = re.findall(reg,reg_string) print(result)复制代码
这里reg_string就是我们的普通字符,reg就是我们的元字符。
我们使用 re 模块中的findall函数,进行匹配,返回的结果是列表数据类型。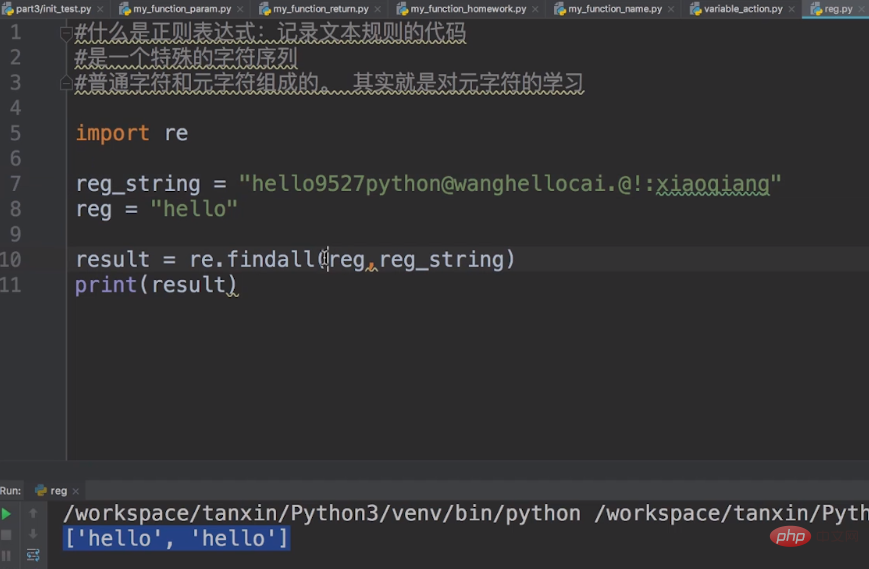
我们使用正则表达式,就是为了在很长的字符串中,找到我们需要的字符串片段。
元字符
Python中常见元字符及其含义如下:
| 元字符 | 含义 |
|---|---|
| . | 匹配除换行符以外的任意字符 |
| \\\\w | 匹配数字字母下划线汉字 |
| \\\\s | 匹配任意空白符 |
| \\\\d | 匹配所有的数字 |
| \\\\b | 匹配单词的开始或结束 |
| ^ | 匹配字符串的开始 |
| $ | 匹配字符串的开始结束 |
| 下面,我们具体使用下Python中的常见的元字符。 |
我们还是使用上次的例子,这次我们需要在reg_string匹配出我们的数字,只需要将reg换成\\\\d,代码如下图所示。
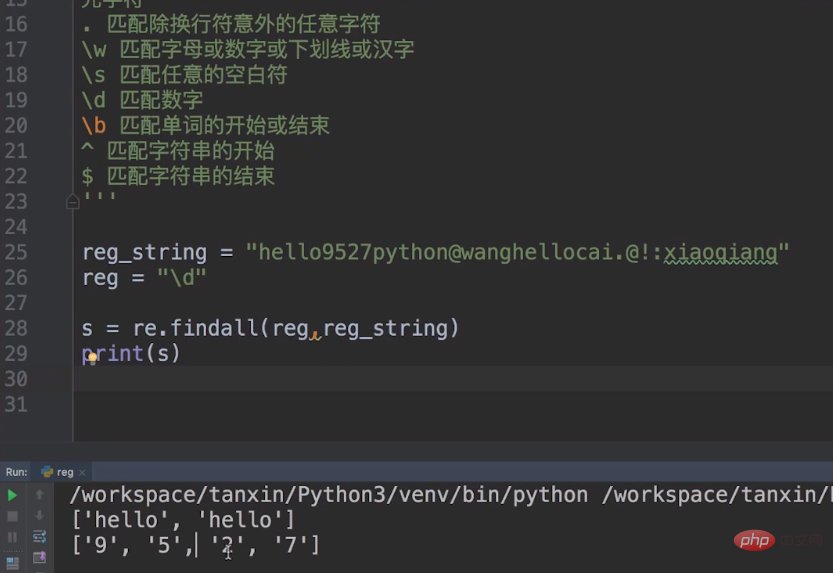 比如,我们在之前的reg的hello前面加上一个^,意味着我们 匹配字符串的开始的hello,那么结果就是一个,就是我们开头的hello。
比如,我们在之前的reg的hello前面加上一个^,意味着我们 匹配字符串的开始的hello,那么结果就是一个,就是我们开头的hello。
如果,我们把reg换成\\\\w,代码如下图所示。
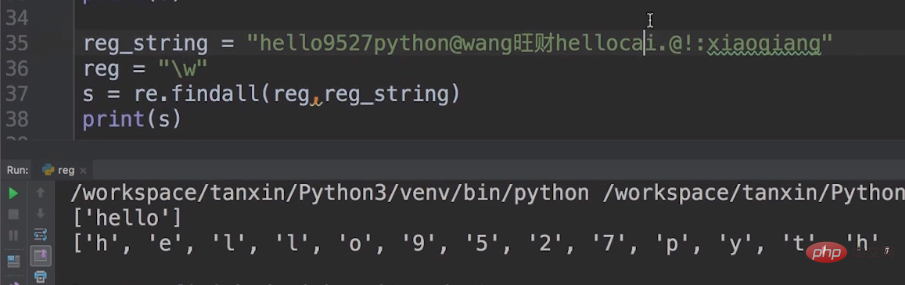
这样就是匹配数字字母下划线,包括我们的汉字。
反义代码
Python中常见反义代码 及其含义如下:
| 反义代码 | 含义 |
|---|---|
| \\\\W | 匹配任意不是数字字母下划线汉字的字符 |
| \\\\S | 匹配任意不是空白符的字符 |
| \\\\D | 匹配非数字 |
| \\\\B | 匹配不是单词的开始或结束 |
| [^a] | 匹配除了a以外的任意字符 |
| [^abcd] | 匹配除了abcd以外的任意字符 |
其实,记忆很简单,我们是不是知道\\\\d匹配数字,那么\\\\d的大写\\\\D就是匹配非数字,元字符[a]匹配a任意字符,那么[^a]就是匹配除了a以外的任意字符。
下面是具体例子
>>> import re>>> reg_string = "hello9527python@wangcai.@!:xiaoqiang" >>> reg = "\\\\D">>> re.findall(reg,reg_string) ['h', 'e', 'l', 'l', 'o', 'p', 'y', 't', 'h', 'o', 'n', '@', 'w', 'a', 'n', 'g', 'c', 'a', 'i', '.', '@', '!', ':', 'x', 'i', 'a', 'o', 'q', 'i', 'a', 'n', 'g'] >>> reg = "[^a-p]"['9', '5', '2', '7', 'y', 't', '@', 'w', '.', '@', '!', ':', 'x', 'q']复制代码
限定符
什么是限定符?就是限定我们匹配的个数的东西。
Python中常见限定符 及其含义如下:
| 限定符 | 含义 |
|---|---|
| * | 重复零次或多次 |
| + | 重复一次或多次 |
| ? | 重复零次或一次 |
| {n} | 重复n次 |
| {n,} | 重复n次或更多次 |
| {n,m} | 重复n次到m次 {1,3} |
이전의 reg_string을 계속 사용합니다. 이번에는 메타 문자를 \\d{4}로 제한합니다. 즉, 일치하는 숫자는 4여야 합니다.
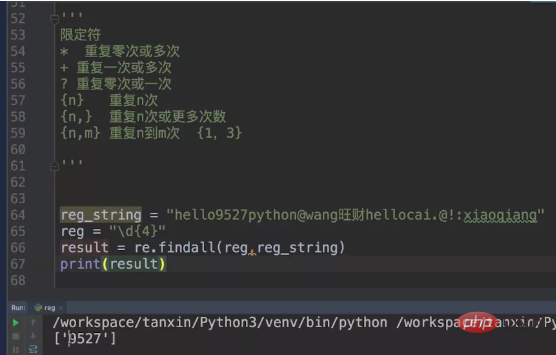
다음으로 난이도를 높여서 문자와 숫자를 맞춰보겠습니다. 제한은 4개입니다.
이런 식으로 [0-9a-z]{4}를 메타 문자로 사용할 수 있습니다. [0-9a-z]는 0부터 9까지의 10개의 숫자와 a부터 z까지의 26개의 소문자 영어 문자를 나타냅니다. [0-9a-z]{4}는 숫자를 4로 제한합니다.
출력물을 인쇄해 봅시다.
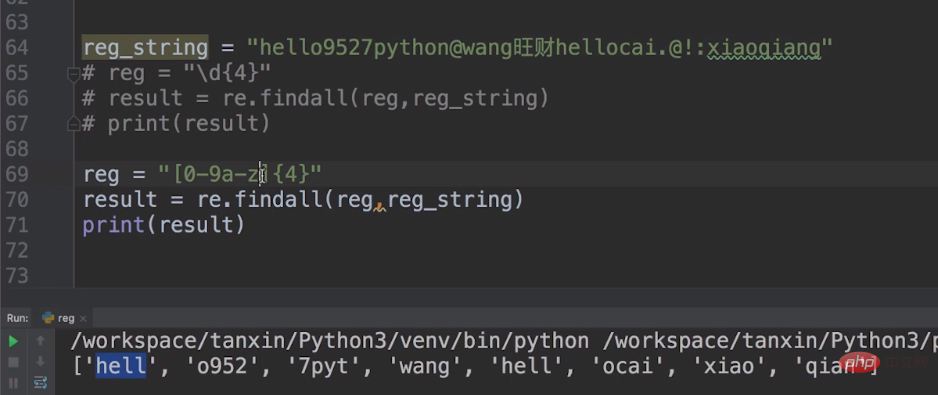
[0-9a-z] 범위 내에 있지 않은 항목이 발견되면 다음 4개가 [0-9a-z] 범위 내에 있을 때까지 건너뛰고 인쇄됩니다.
IP 주소 일치
인터넷에서 호스트는 하나의 IP 주소만 가지고 있습니다. IP 주소는 TCP/IP 통신 프로토콜에서 각 컴퓨터의 주소를 표시하는 데 사용되며 일반적으로 192.168.1.100과 같이 10진수로 표시됩니다.
윈도우 시스템에서는 ipconfig를 통해 우리의 IP를 확인할 수 있습니다. Linux 시스템에서는 ifconfig를 통해 IP를 볼 수 있습니다.
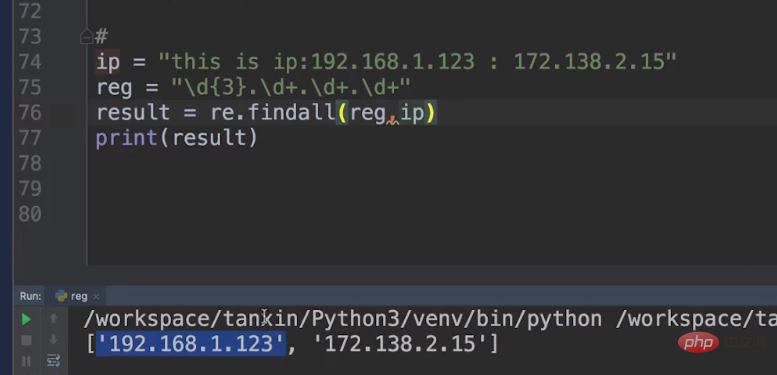
우리의 IP 문자열은 다음과 같습니다: ip = "this is ip:192.168.1.123 :172.138.2.15"ip = "this is ip:192.168.1.123 :172.138.2.15"
下面要求使用正则表达式,将ip匹配出来。
其实,我们主要编写元字符。比如:reg = "\d{3}.\d+.\d+.\d+",因为第一个数字必须是三位数开头,我们可以设定\d{3}固定起来。
 我们除了可以使用findall,还可以使用search,我们把元字符
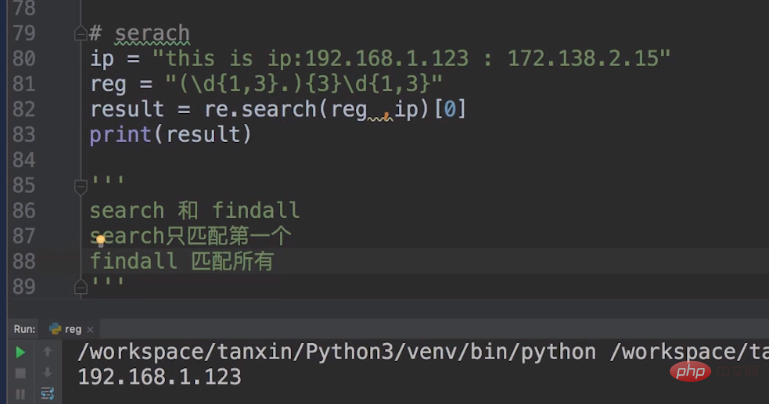
我们除了可以使用findall,还可以使用search,我们把元字符reg = "(\d{1,3}.){3}\d{1,3}"。
这元字符中的\d{1,3}.指定是我们ip前三个数字,后面加{3}就是重复3次。\d{1,3}指的就是我们ip最后一个数字。
但是search和findall是有区别的,search只能匹配第一个,我们需要使用列表取出第一个,而findall匹配所有。
组匹配
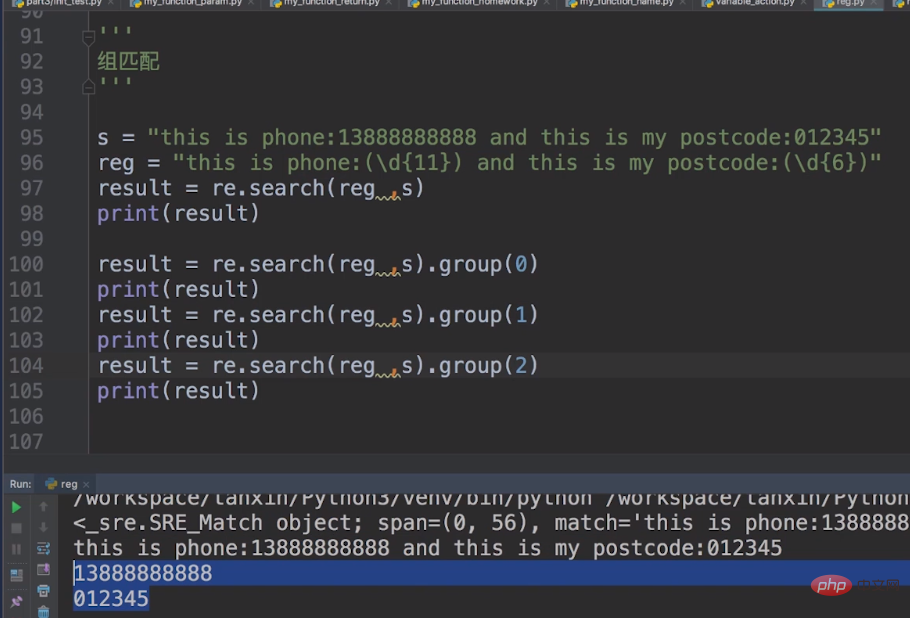
什么是组匹配,比如说这里边我有一个字符串s = this is phone:13888888888 and this is my postcode:012345,我需要你把手机号和验证码匹配出来。
因为,我们要匹配两个,而已每个的元字符都是不一样的。所以,我们需要分组匹配。
正则表达式的括号表示分组匹配,括号中的模式可以用来匹配分组的内容。
于是我们的元字符就变成:reg = this is phone:(\d{11}) and this is my postcode:(\d{6})
我们一般使用search进行分组匹配,上次我是不是说过search需要使用列表取出来,这里的组匹配也是一样,不过这里用的是group()方法。group(1)代表了我们的手机号,group(2)代表了我们的验证码,而group(0)
 사실 저희는 주로 메타문자를 씁니다. 예:
사실 저희는 주로 메타문자를 씁니다. 예: reg = "\\d{3}.\\d+.\\d+.\\d+",첫 번째 숫자는 세 자리 숫자로 시작해야 하므로 \\d{3}수정되었습니다.
findall을 사용하는 것 외에도 검색을 사용할 수도 있습니다. 메타문자 reg = "(\\d{1,3}.){3}\\d{1, 3 }".
이 메타 문자의 \\d{1,3}는 IP의 처음 3개 숫자를 지정하며, 그 뒤에 {3}를 추가하면 3번 반복된다는 의미입니다. \\d{1,3}는 우리 IP의 마지막 번호를 나타냅니다.
하지만 검색과 findall 사이에는 차이점이 있습니다. 검색은 첫 번째 항목만 일치할 수 있지만, findall은 모두 일치합니다. 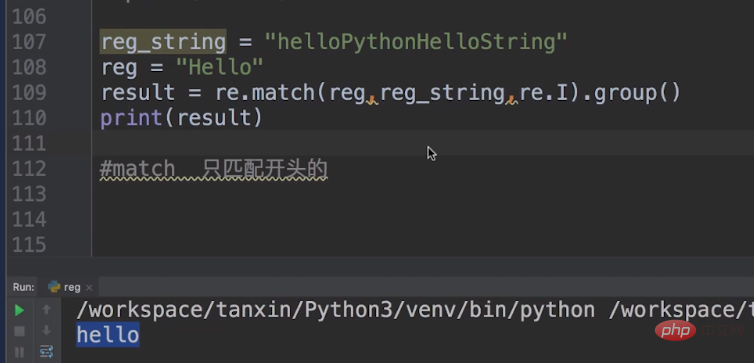
그룹 매칭
그룹 매칭이란 무엇인가요? 예를 들어 여기에 문자열이 있습니다.s = 이것은 전화:13888888888입니다. 내 우편번호는 012345입니다. 휴대폰 번호와 인증 코드를 일치시켜야 합니다.
두 개를 일치시켜야 하고 각각의 메타 문자가 다르기 때문입니다. 그래서 그룹 매칭이 필요합니다.
| 우리는 일반적으로 그룹 검색을 사용합니다. 지난번에 검색은 목록을 사용하여 검색해야 한다고 말씀드렸습니다. 여기서는 그룹 일치에도 동일하지만 여기서는 | |
|---|---|
| 일치 사용법은 시작 부분만 일치하며, 다음 일치 예시와 같이 group()으로도 꺼내야 합니다. | 재입니다. 대소문자를 무시한다는 뜻입니다. |
| greedy 모드와 non-greedy 모드는 수량자에 의해 수정된 하위 표현식의 일치 동작에 영향을 미칩니다. Greedy 모드는 전체 표현식이 성공적으로 일치한다는 전제 하에 최대한 일치합니다. -greedy mode 전체 표현식이 성공적으로 일치한다는 전제 하에 가능한 한 적게 일치합니다. | 탐욕스러운 것과 그렇지 않은 것에 대한 매우 중요한 연산자가 몇 가지 있습니다. |
| 연산자 |
比如说这里边我有一个字符串reg_string = pythonnnnnnnnnpythonHelloPytho,我们先使用贪婪的模式下的元字符:reg = "python*"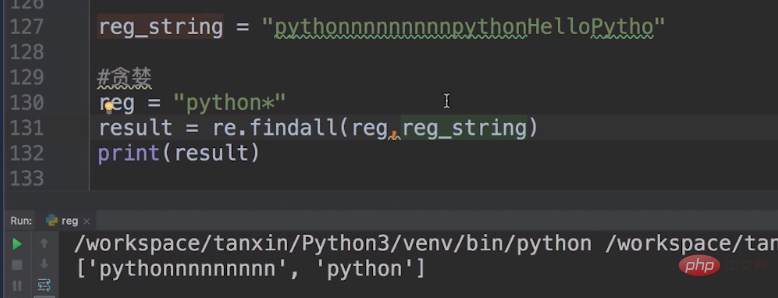
贪婪模式下的reg = "python*",意味着n重复零次或更多次。所以我们看到了第一关结果的pythonnnnnnnnn尽可能多的匹配。
下面使用非贪婪的模式下的元字符:reg = "python*?",reg = "python+?",reg = "python??"。
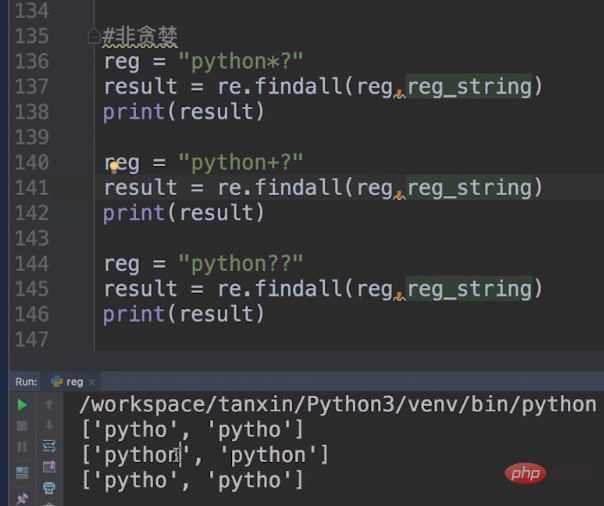 非贪婪模式下的
非贪婪模式下的reg = "python*",意味着n零次或一次,所以我们没有看到pythonnnnnnnnn的结果。
手机号码验证
首先,我们要知道我们的手机号码是什么开头的?
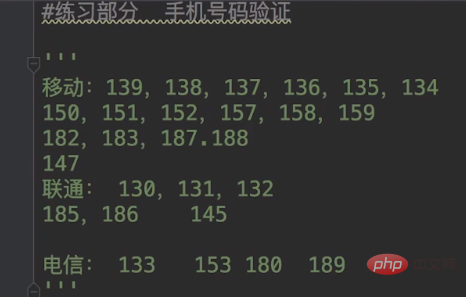
移动手机号码开头有16个号段:134、135、136、137、138、139、147、150、151、152、157、158、159、182、187、188。
联通手机号码开头有7种号段:130、131、132、155、156、185、186。
电信手机号码开头有4个号段:133、153、180、189。
这样我们就可以在开头做事情了,先判断开头是不是上面的号段, regex = "^((13[0-9])|(14[5|7])|(15([0-3]|[5-9]))|(18[0,5-9]))\\\\d{8}$",就是我们的元字符,代码如下:
import redef checkCellphone(cellphone): regex = "^((13[0-9])|(14[5|7])|(15([0-3]|[5-9]))|(18[0,5-9]))\\\\d{8}$" result = re.findall(regex,cellphone) if result: print("匹配成功") return True
else: print("匹配失败") return Falsecellphone = '13717378202'checkCellphone(cellphone)
匹配成功True复制代码
匹配邮箱合法性
下面,我们进行一个作业,就是来匹配我们的邮箱号码。
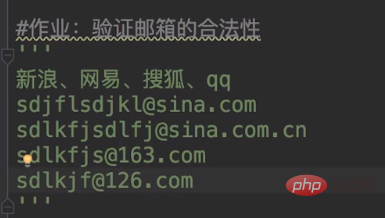
作业的答案如下:
import redef checkEmail(email): regex_1 = '^(\\\\w+)@sina.com$'
regex_2 = '^(\\\\w+)@sina.com.cn$'
regex_3 = '^(\\\\w+)@163.com$'
regex_4 = '^(\\\\w+)@126.com$'
regex_5 = '^[1-9][0,9]{4,}+@qq.com$'
regex = [regex_1 ,regex_2 ,regex_3, regex_4, regex_5]
for i in regex:
result = re.findall(i,email)
if result:
print("匹配成功")
return True else:
print("匹配失败")
return False
email = 'sdjflsdjkl@sina.com'checkEmail(email)复制代码
正则表达式测试工具
打开开源中国提供的正则表达式测试工具 tool.oschina.net/regex/,输入待匹…
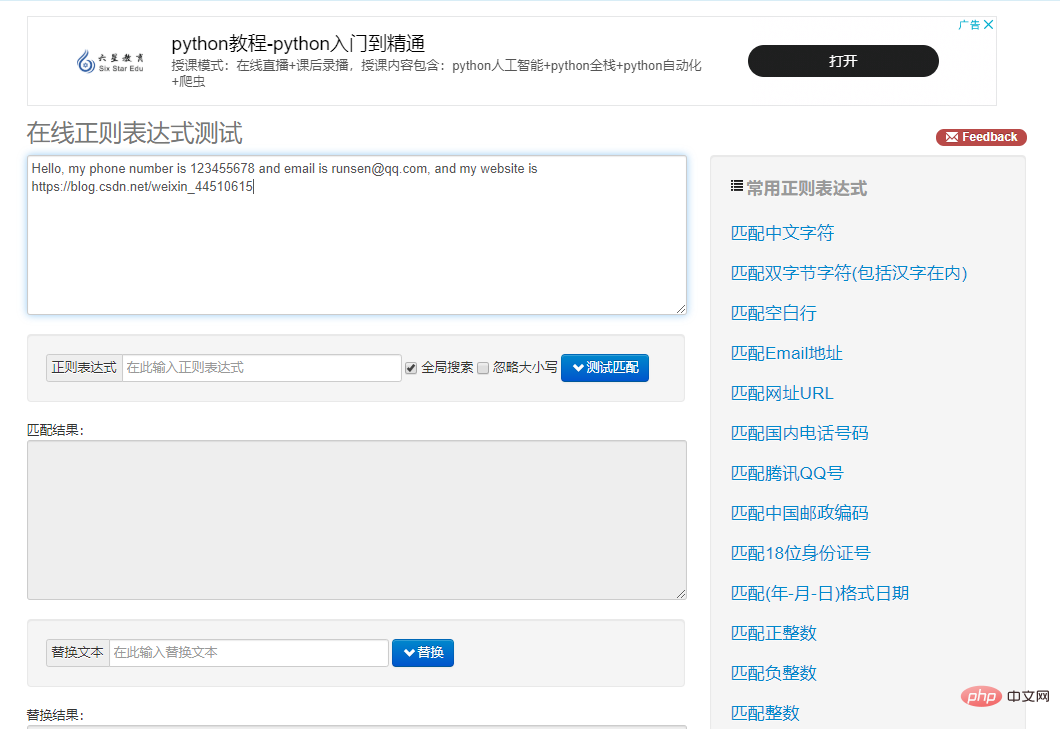
例如,输入下面这段待匹配的文本:
Hello, my phone number is 123455678 and email is runsen@qq.com, and my website is https://blog.csdn.net/weixin_44510615.复制代码
这段字符串中包含了一个电话号码和一个电子邮件,接下来就尝试用正则表达式提取出来,如图所示。
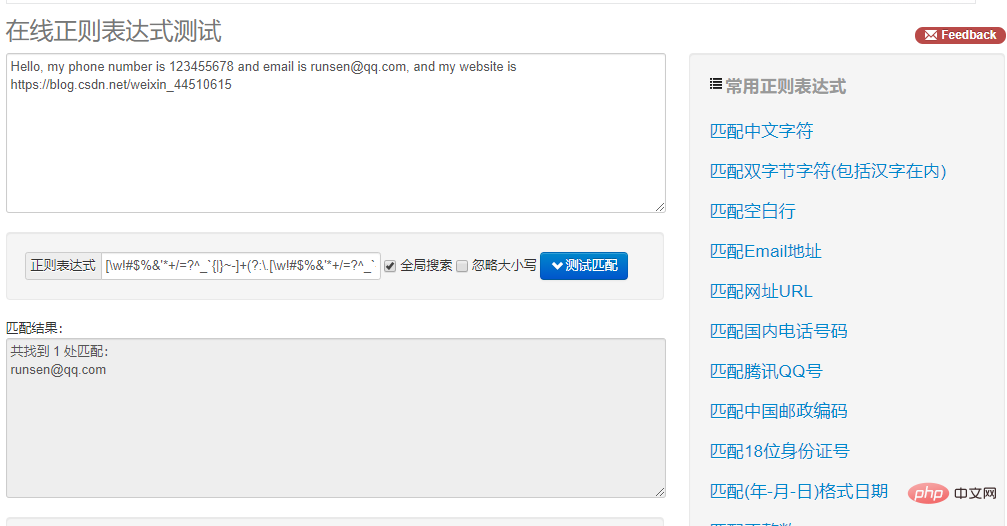
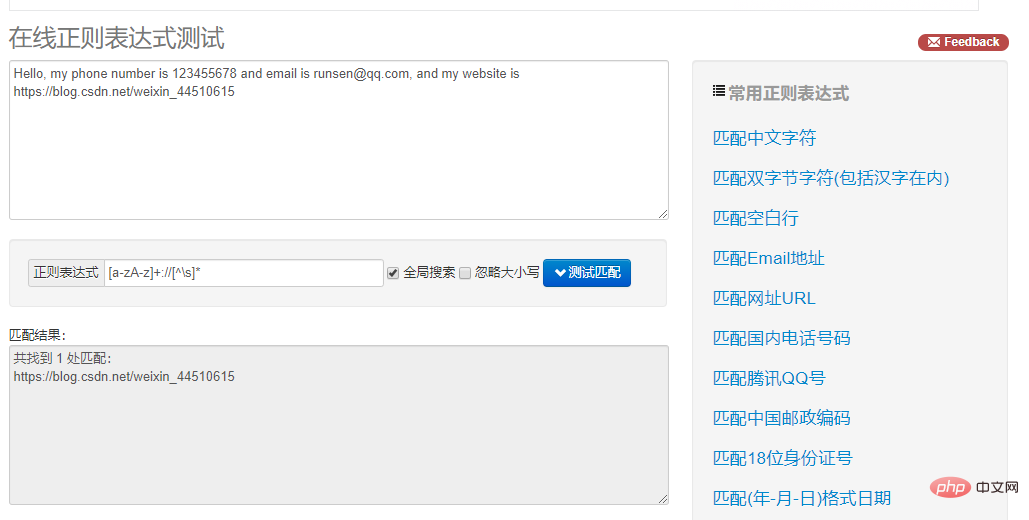
在网页右侧选择 “匹配 Email 地址”,就可以看到下方出现了文本中的 E-mail。如果选择 “匹配网址 URL”,就可以看到下方出现了文本中的 URL。是不是非常神奇?
相关免费学习推荐:python教程(视频)
위 내용은 Python의 정규식에 대한 자세한 설명의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!