
집 >데이터 베이스 >MySQL 튜토리얼 >InnoDB의 Checkpoint 기술 이해
InnoDB의 Checkpoint 기술 이해

- coldplay.xixi앞으로
- 2020-10-28 17:14:332709검색
mysql tutorial 칼럼을 통해 InnoDB의 Checkpoint 기술을 이해할 수 있습니다.

한 문장으로 말하면 체크포인트 기술은 특정 시점에 캐시 풀의 더티 페이지를 디스크로 다시 플러시하는 작업입니다.
문제가 발생했나요?
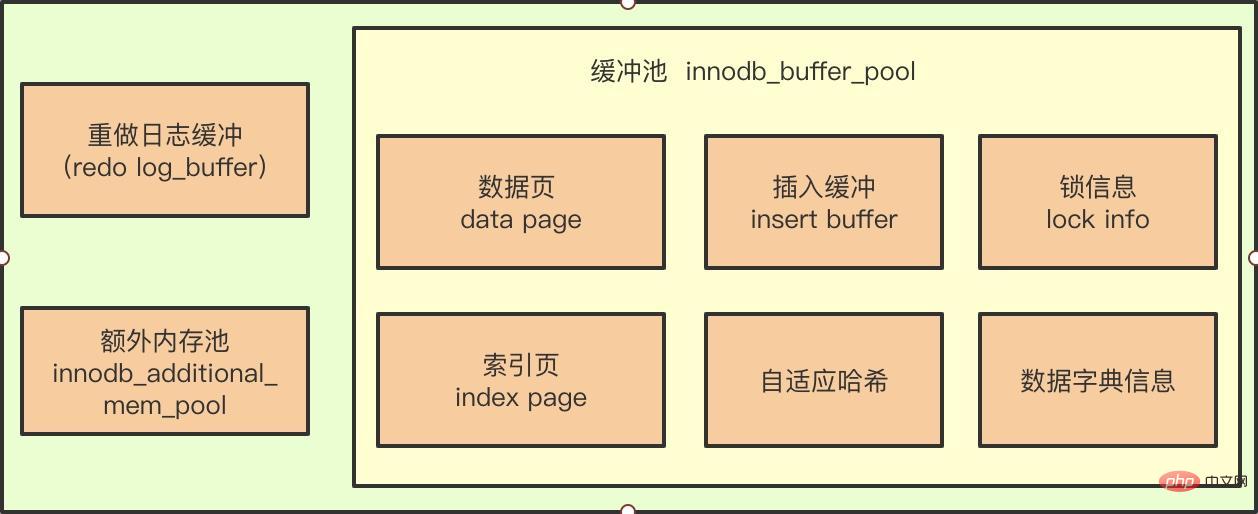
버퍼 풀의 출현은 CPU와 디스크 속도의 격차를 해소하여 데이터베이스를 읽고 쓸 때 디스크 IO 작업을 수행할 필요가 없다는 사실을 우리 모두 알고 있습니다. 버퍼 풀을 사용하면 모든 페이지 작업이 먼저 버퍼 풀에서 완료됩니다.
예를 들어 DML 문에서 데이터 업데이트나 삭제 작업을 수행하면 버퍼 풀 페이지의 데이터가 디스크에 있는 데이터보다 최신이므로 이때의 페이지는 변경됩니다. 더티 페이지(dirty page)라고 합니다.
무슨 일이 있어도 총회 후 메모리 페이지 데이터를 다시 디스크로 플러시해야 합니다. 여기에는 몇 가지 문제가 있습니다.
- 페이지가 변경될 때마다 새 페이지 버전이 디스크로 플러시됩니다. , 그렇다면 이 오버헤드는 매우 큽니다
- 핫 데이터가 특정 페이지에 집중되면 데이터베이스 성능이 매우 저하됩니다
- 페이지의 새 버전이 버퍼 풀에서 페이지로 플러시될 때 다운타임이 발생하면
Write Ahead Log(미리 쓰기 로그)
WAL 전략은 페이지 데이터를 디스크에 새로 고칠 때 다운타임으로 인한 데이터 손실 문제를 해결하는 데 사용됩니다. 원자성 및 내구성 속성(ACID 속성 중 두 가지)을 제공합니다.
WAL 전략의 핵심은
redo log,每当有事务提交时,先写入 redo log(redo 로그)로, 정전 발생 시 시스템을 다시 시작한 후에도 시스템이 계속 작동할 수 있도록 버퍼 풀 데이터 페이지를 수정합니다.
WAL 정책 메커니즘의 원리
InnoDB for 데이터가 손실되지 않고 REDO 로그가 유지되는지 확인하십시오. 버퍼 풀의 데이터 페이지를 수정하기 전에 수정된 내용을 Redo 로그에 기록하고 해당 데이터 페이지보다 먼저 Redo 로그를 디스크에 플러시해야 하는 것이 WAL 전략입니다.
오류가 발생하고 메모리 데이터가 손실되면 InnoDB는 다시 시작할 때 리두 로그를 재생하여 버퍼 풀 데이터 페이지를 충돌 이전 상태로 복원합니다.
Checkpoint
WAL 전략을 사용하면 우리는 편안히 앉아 휴식을 취할 수 있습니다. 하지만 리두 로그에 문제가 다시 나타납니다.
- 리두 로그는 무한할 수 없으며, 새로 고쳐지기를 기다리는 데이터를 디스크에 함께 끝없이 저장할 수 없습니다.
- 데이터베이스가 유휴 상태이고 복원될 때, 리두 로그가 너무 크면 복구 비용도 매우 높습니다
그래서 더티 페이지의 새로 고침 성능을 해결하기 위해 언제, 어떤 상황에서 더티 페이지를 새로 고쳐야 하는지 체크포인트(Checkpoint) 기술을 사용합니다.
체크포인트의 목적
1. 데이터베이스 복구 시간 단축
데이터베이스가 유휴 상태이고 복원되면 모든 로그 정보를 다시 실행할 필요가 없습니다. 체크포인트 이전의 데이터 페이지가 디스크로 다시 플러시되었기 때문입니다. 체크포인트 이후에 리두 로그를 복원하면 됩니다.
2. 버퍼 풀이 충분하지 않으면 더티 페이지를 디스크로 플러시합니다.
버퍼 풀 공간이 부족하면 LRU 알고리즘에 따라 가장 최근에 사용된 페이지가 오버플로됩니다. 그런 다음 페이지의 새 버전인 더티 페이지를 디스크로 플러시해야 합니다.
3. Redo 로그를 사용할 수 없는 경우 더티 페이지를 새로 고칩니다.
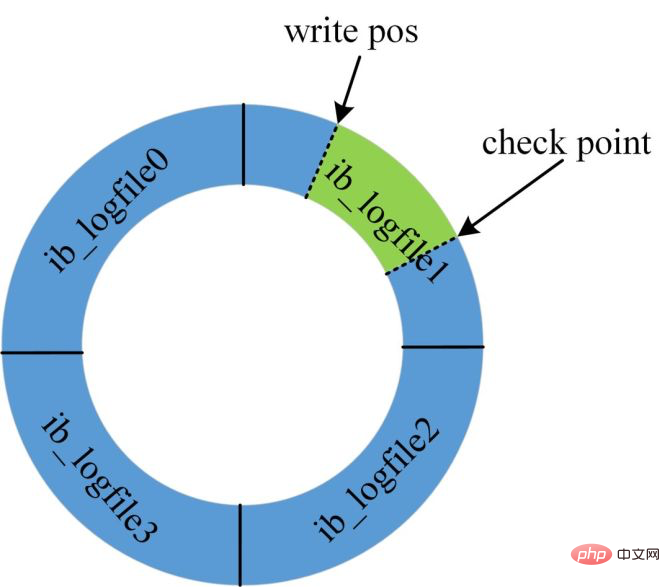
그림과 같이 현재 데이터베이스는 주기적으로 사용하도록 설계되어 공간이 무한하지 않기 때문에 Redo 로그를 사용할 수 없습니다. .
리두 로그가 가득 차면 현재 시스템에서 업데이트를 수락할 수 없기 때문에 모든 업데이트 문이 차단됩니다.
이때 체크포인트를 강제로 생성하고 쓰기 위치를 앞으로 밀어야 합니다. 진행 범위 내의 더티 페이지를 디스크로 플러시해야 합니다.
체크포인트 유형
시간과 조건 체크포인트 발생과 더티 페이지 선택은 매우 복잡합니다.
체크포인트 매번 디스크에 플러시되는 더티 페이지 수는 몇 개입니까?
Checkpoint는 매번 어디에서 더티 페이지를 가져오나요?
체크포인트는 언제 실행되나요?
위 문제에 직면한 InnoDB 스토리지 엔진은 내부적으로 두 가지 유형의 체크포인트를 제공합니다.
-
샤프 체크포인트
는 데이터베이스가 종료되고 모든 더티 페이지가 디스크로 다시 플러시될 때 발생합니다. 메서드, 매개변수 innodb_fast_shutdown=1
-
Fuzzy Checkpoint
InnoDB 스토리지 엔진은 이 모드를 내부적으로 사용하며 모든 더티 페이지를 다시 디스크로 플러시하는 대신 더티 페이지의 일부만 플러시합니다
무슨 일이 발생하나요? to FuzzyCheckpoint
-
Master Thread Checkpoint
는 거의 매초 또는 10초마다 버퍼 풀의 더티 페이지 목록에서 특정 비율의 페이지를 디스크로 다시 플러시합니다.
이 프로세스는 비동기식입니다. 즉, InnoDB 스토리지 엔진은 이때 다른 작업을 수행할 수 있으며 사용자 쿼리 스레드는 차단되지 않습니다.
-
FLUSH_LRU_LIST Checkpoint
LRU 목록은 특정 수의 쿼리 스레드를 보장해야 하기 때문입니다. free 페이지를 사용할 수 있으므로 페이지가 충분하지 않은 경우 해당 페이지를 tail에서 제거합니다. 제거된 페이지에 더티 페이지가 포함되어 있으면 이 Checkpoint가 수행됩니다.
버전 5.6 이후에는 이 체크포인트가 별도의 페이지 클리너 스레드에 배치되며 사용자는 innodb_lru_scan_length 매개변수를 통해 LRU 목록에서 사용 가능한 페이지 수를 제어할 수 있습니다. 기본값은 1024
-
Async/Sync Flush Checkpoint
입니다.리두 로그 파일을 사용할 수 없는 상황을 말합니다. 이때 일부 페이지를 강제로 디스크에 플러시해야 합니다. 이때 더티 페이지 목록에서 더티 페이지가 선택됩니다.
이후 버전. 5.6, 사용자 쿼리가 차단되지 않습니다.
-
더티 페이지가 너무 많습니다. 즉, 더티 페이지 수가 너무 많아서 InnoDB 스토리지 엔진이 체크포인트를 강제 실행하게 됩니다.
전체적인 목적은 버퍼 풀에 사용 가능한 페이지가 충분한지 확인하는 것입니다.
innodb_max_dirty_pages_pct 매개변수로 제어할 수 있습니다. 예를 들어 값은 75입니다. 즉, 버퍼 풀의 더티 페이지가 75%를 차지하면 데이터베이스 DML 속도를 높이기 위해 CheckPoint가 강제로 수행됩니다. Operations
버퍼 풀 데이터 페이지와 디스크 데이터 간의 일관성 문제로 인해 WAL 전략(핵심은 redo 로그)이 나타납니다
버퍼 풀 더티 페이지의 새로 고침 성능 문제로 인해 Checkpoint가 등장합니다. technology
InnoDB. 실행 효율성을 높이기 위해 모든 DML 작업은 지속성을 위해 디스크와 상호 작용하지 않습니다. 대신 Write Ahead Log를 통해 먼저 Redo 로그를 작성하여 지속성을 보장합니다.
트랜잭션에서 수정된 버퍼 풀의 더티 페이지는 비동기식으로 플러시되며, 체크포인트 기술을 통해 여유 메모리 페이지 및 리두 로그의 가용성이 보장됩니다. - 더 많은 관련 무료 학습 권장사항:
(동영상)
위 내용은 InnoDB의 Checkpoint 기술 이해의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!