
드디어 왔습니다...RocketMQ 활용 능력 장

- coldplay.xixi앞으로
- 2020-10-20 17:16:393175검색
오늘
java 기본 튜토리얼 칼럼에서는 RocketMQ에 대한 지식을 자세하게 소개합니다.

블로그를 하지 않는 이유는 셀 수 없이 많지만, 결론적으로 보면 여전히 '게으름'입니다. 오늘 드디어 게으른 암을 치료하기 위해 약을 먹고 블로그를 쓰기로 결심했습니다. 무엇을 소개해야 할까요? 고민 끝에 RocketMQ를 소개하려고 합니다. 결국 30개 이상의 블로그를 작성했지만 아직 MQ에 대한 좋은 블로그를 작성하지 않았습니다. 이 블로그는 상대적으로 기본적이며 소스 코드 분석은 포함하지 않고 읽고 쓰는 능력만 포함합니다.
MQ의 용도
Decoupling
어떤 관점에서는 마이크로서비스가 MQ의 활발한 발전을 촉진했다고 생각합니다. 원래 시스템에는 N개의 여러 모듈이 있었고 이제는 모든 모듈이 강력하게 결합되었습니다. 모듈은 시스템이고 시스템은 확실히 상호 작용해야 합니다. 세 가지 일반적인 상호 작용 방법이 있습니다. 하나는 RPC, 하나는 HTTP, 다른 하나는 MQ입니다.
Asynchronous
원래 비즈니스는 N개의 단계로 나누어져 있으며 이를 단계별로 처리해야 최종 결과가 사용자에게 반환됩니다. 이제 MQ에서는 가장 중요한 부분을 먼저 처리한 다음 메시지를 보냅니다. MQ로 전송되어 사용자에게 직접 반환됩니다. 후속 단계는 백그라운드에서 천천히 처리해 보겠습니다. 이는 실제로 사용자 경험을 개선하기 위한 아티팩트입니다.
Peak Shaving
특정 인터페이스에 대한 요청 수가 갑자기 급증하면 필연적으로 애플리케이션 서버와 데이터베이스 서버에 많은 부담이 가해집니다. 이제 MQ를 사용하면 요청이 얼마나 많이 오는지 걱정할 필요가 없습니다. 백그라운드에서 천천히 처리됩니다.
RocketMQ 소개
RocketMQ는 Java로 작성되었으며 Alibaba의 오픈 소스 메시지 미들웨어이며 Kafka의 많은 장점을 흡수합니다. Kafka도 널리 사용되는 메시지 미들웨어이지만 Kafka는 Scala로 작성되어 Java 프로그래머가 소스 코드를 읽는 데 도움이 되지 않으며 Java 프로그래머가 일부 맞춤형 개발을 수행하는 데도 도움이 되지 않습니다. Kafka를 접해 본 친구들은 Kafka를 잘 사용하는 것이 쉽지 않다는 것을 알고 있습니다. 상대적으로 RocketMQ는 훨씬 간단하며 RocketMQ는 Alibaba의 축복을 받아 N Double 11의 테스트를 경험했습니다. 국내 인터넷 회사에 더 적합합니다. , 국내에서는 RocketMQ 회사가 많이 사용되고 있습니다.
RocketMQ의 네 가지 주요 구성 요소
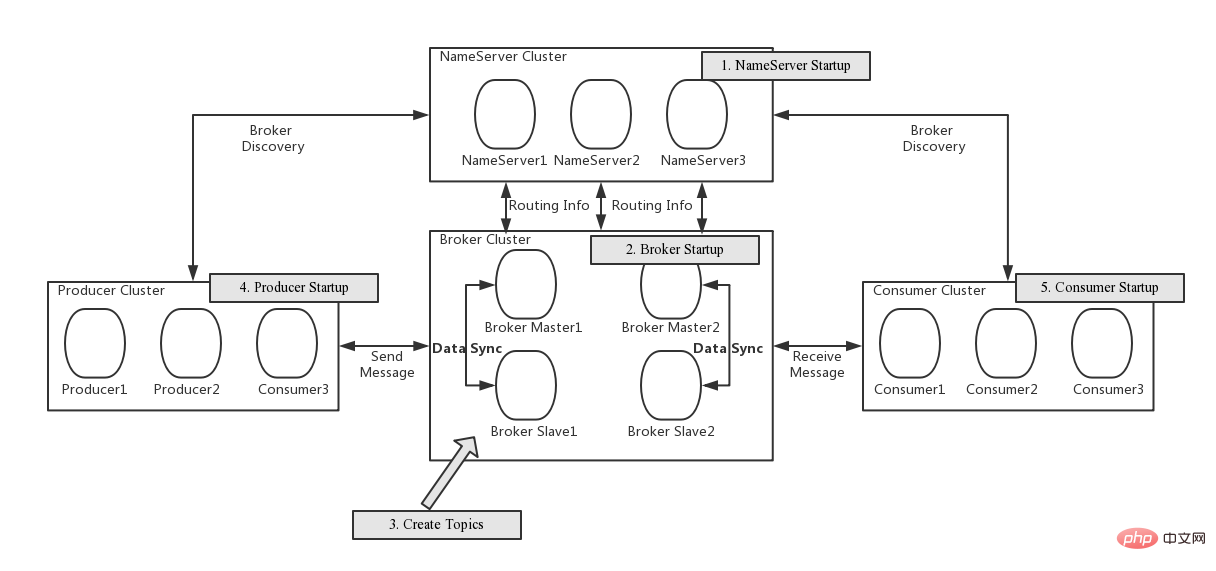 Gitee.com/mirrors/roc의 사진...
Gitee.com/mirrors/roc의 사진...
RocketMQ에는 네 가지 주요 구성 요소가 있음을 알 수 있습니다.
NameServer
- 상태 비저장 서비스, 등록 센터, 클러스터 배포 가능, 하지만 NameServer 노드 간에는 데이터 상호 작용이 없습니다.
- Borker는 정기적으로 모든 네임서버에 주제 라우팅 정보를 보고합니다. 생산자와 소비자는 정기적으로 라우팅 정보를 업데이트하기 위해 NameServer 주제를 무작위로 선택합니다.
- 주제 라우팅 정보는 NameServer 클러스터에서 최종 일관성을 채택합니다.
- AP 보장.
Borker
- RocketMQ의 서버는 메시지를 저장하고 배포하는 데 사용됩니다.
- Borker는 자신이 소유한 모든 주제 라우팅 정보를 NameServer에 정기적으로 보고합니다.
- Borker에는 마스터와 팔로어의 두 가지 역할이 있습니다. 마스터는 읽기(메시지 소비) 및 쓰기(메시지 생성) 작업을 담당합니다. 마스터가 바쁘거나 사용할 수 없는 경우 팔로어가 읽기 작업을 수행할 수 있습니다. BorkerId=0은 Matser를 의미하고 BorkerId!=0은 Follower를 의미합니다. 주의할 점은 두 가지입니다. 첫째, 지금까지는 BorkerId=1인 팔로어만 읽기 작업을 수행할 수 있습니다. 둘째, 상위 버전의 RocketMQ만이 마스터 노드가 중단될 때 팔로어를 마스터로 자동 업그레이드하는 기능을 지원합니다.
Producer
Producer는 정기적으로 NameServer에 대한 Topic 라우팅 정보 쿼리를 시작합니다.
Consumer
Consumer는 정기적으로 NameServer에 대한 주제 라우팅 정보 쿼리를 시작합니다.
등록 센터에서 Zookeeper를 사용하지 않는 이유
사실 RocketMQ 하위 버전에서는 실제로 Zookeeper를 등록 센터로 사용했지만 나중에 현재 NameServer로 변경된 주된 이유는 다음과 같습니다.
- RocketMQ는 이미 미들웨어이므로 더 이상 다른 미들웨어에 의존하고 싶지 않습니다.
- Zookeeper는 상대적으로 무겁고 RocketMQ에서 사용할 수 없는 기능이 많습니다. 가벼운 등록 센터를 작성하는 것이 좋습니다.
- Zookeeper는 리더 선택이 시작되면 등록 센터를 사용할 수 없습니다. 그러나 RocketMQ의 등록 센터는 최종 일관성을 보장하는 한 강력한 일관성을 요구하지 않습니다.
RocketMQ 메시지 도메인 모델
Message
- 전송된 메시지입니다.
- 메시지에는 주제가 있어야 합니다.
- 메시지에는 여러 태그와 여러 키가 있을 수 있으며 이는 메시지의 추가 속성으로 간주될 수 있습니다.
Topic
- 메시지 모음입니다.
- 각 메시지에는 주제가 있어야 합니다.
- 첫 번째 수준의 메시지 유형입니다.
Tag
- 메시지에는 주제 외에도 태그가 있을 수 있습니다. 태그는 동일한 주제에서 다양한 유형의 메시지를 세분화하는 데 사용됩니다.
- 태그는 필요하지 않습니다.
- 두 번째 수준의 메시지 유형입니다.
Group
은 ProducerGroup과 ConsumerGroup으로 구분됩니다. ConsumerGroup에는 여러 Consumer가 포함되어 있다는 점에 더 주목합니다.
클러스터 소비 모드에서 ConsumerGroup의 소비자는 주제를 함께 소비하고 각 소비자는 N개의 대기열에 할당되지만 대기열은 하나의 소비자만 소비할 수 있습니다. 서로 다른 ConsumerGroup은 동일한 주제를 하나씩 소비할 수 있습니다. 이 주제를 구독하는 모든 ConsumerGroup이 소비합니다.
Queue
- 토픽에는 기본적으로 4개의 대기열이 포함되어 있습니다.
- 클러스터 소비 모드에서 동일한 ConsumerGroup의 소비자는 여러 대기열의 메시지를 소비할 수 있지만 하나의 대기열은 하나의 소비자만 소비할 수 있습니다.
- 큐의 메시지는 순서대로 정렬됩니다.
- 읽기 Queue와 쓰기 Queue로 나누어져 있는데, 일반적으로 읽기 Queue의 개수와 쓰기 Queue의 개수가 일치하지 않으면 문제가 발생하기 쉽습니다.
소비 모드
클러스터링(클러스터 소비)과 브로드캐스트(브로드캐스트 소비)의 두 가지 소비 모드가 있습니다.
메시지를 보낼 때 클러스터 소비 또는 브로드캐스트 소비를 지정하는 다른 MQ와 달리 RocketMQ는 소비자 측에서 클러스터 소비 또는 브로드캐스트 소비를 설정합니다.
클러스터링(클러스터 소비)
기본값은 클러스터 소비 모드입니다. 이 모드에서는 ConsumerGroup의 모든 소비자가 주제의 메시지를 공동으로 소비합니다. N개 대기열의 메시지를 소비합니다. even은 0이고 대기열에 할당되지 않음) 그러나 대기열은 하나의 소비자에 의해서만 소비됩니다. 소비자가 사망하면 ConsumerGroup에 속한 다른 소비자가 인계받아 계속 소비합니다.
클러스터 소비 모드에서는 Borker 측에서 소비 진행이 유지되며 저장 경로는 ${ROCKET_HOME}/store/config/ consumerOffset.json,如下图所示: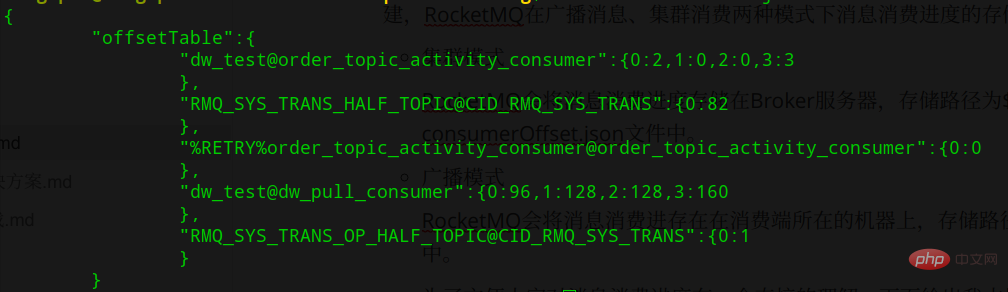 使用
使用topicName@consumerGroupName为Key,消费进度为Value,Value的形式是queueId:offset입니다. 즉, ConsumerGroup이 여러 개인 경우 각 ConsumerGroup의 소비 진행이 다르므로 별도로 저장해야 합니다.
방송(방송 소비)
방송 소비 메시지는 ConsumerGroup의 모든 Consumer에게 전송됩니다.
방송 소비 모드에서는 소비 진행 상황이 Consumer 측에서 유지됩니다.
소비 대기열 로드 알고리즘 및 재조정 메커니즘
소비 대기열 로드 알고리즘
우리는 클러스터 소비 모드에서 ConsumerGroup에 속한 모든 소비자가 공동으로 주제의 메시지를 소비하고 각 소비자가 N 대기열의 메시지 소비를 담당한다는 것을 알고 있습니다. 그럼 어떻게 할당되나요? 여기에는 소비 대기열 로드 알고리즘이 포함됩니다.
RocketMQ는 다양한 소비 대기열 로드 알고리즘을 제공하며, 그중 가장 일반적으로 사용되는 두 가지 알고리즘은 AllocateMessageQueueAveragely 및 AllocateMessageQueueAveragelyByCircle입니다. 두 알고리즘의 차이점을 살펴보겠습니다.
이제 하나의 주제에 q0~q15로 표시되는 16개의 대기열과 c0-c2로 표시되는 3개의 소비자가 있다고 가정합니다.
큐 로드 알고리즘을 소비하기 위해 AllocateMessageQueueAveragely를 사용한 결과는 다음과 같습니다.
- c0:q0 q1 q2 q3 q4 q5
- c1:q6 q7 q8 q9 q10
- c2:q11 q12 q13 q14 q15
사용 대기열 로드 알고리즘을 소비하기 위해 AllocateMessageQueueAveragelyByCircle 결과는 다음과 같습니다.
- c0: q0 q3 q6 q9 q12 q15
- c1: q1 q4 q7 q10 q13
- c2: q2 q5 q8 q11 q14
ConsumerGroup 아래의 모든 소비자는 소비합니다. 주제가 함께 있는 메시지인 경우 각 소비자는 N개의 대기열에서 메시지를 소비할 책임이 있지만 N개의 소비자가 동시에 대기열을 소비할 수는 없습니다.
당신이 똑똑하다면 Topic에 4개의 대기열과 5개의 Consumer만 있으면 한 명의 Consumer가 어떤 대기열에도 할당되지 않을 것이라고 생각했을 것입니다. 따라서 RocketMQ에서는 Topic 아래의 대기열 수가 직접적으로 결정됩니다. 최대 수는 Consumer를 추가하는 것만으로는 소비 속도를 높일 수 없음을 의미합니다.
Rebalancing
Topic을 생성할 때 Queue 수를 충분히 고려하는 것이 좋지만, 실제 상황은 Queue 수가 변하지 않더라도 Consumer 등 Consumer 수가 반드시 변하는 경우가 많습니다. 예를 들어 온라인 및 오프라인에서는 소비자가 전화를 끊거나 새 소비자가 추가됩니다. 대기열의 확장 및 축소와 소비자의 확장 및 축소는 재조정으로 이어집니다. 즉, 소비 대기열이 소비자에게 재분배됩니다.
RocketMQ에서는 Consumer가 Topic 대기열 수를 주기적으로 쿼리합니다. Consumer 수가 변경되면 재조정이 시작됩니다.
재조정은 RocketMQ에 의해 내부적으로 구현되므로 프로그래머는 신경 쓸 필요가 없습니다.
당길 것인가, 밀 것인가?
일반적으로 MQ에는 메시지를 가져오는 두 가지 방법이 있습니다.
- 풀: 소비자가 메시지를 적극적으로 가져옵니다. 장점은 소비자가 가져오는 메시지의 빈도와 수를 제어할 수 있다는 것입니다. 메시지 축적을 유발하는 것은 쉽지 않지만 실시간 성능이 그다지 좋지 않고 효율성도 상대적으로 낮습니다.
- 푸시: 브로커가 적극적으로 메시지를 보내므로 실시간이고 효율성이 높다는 장점이 있지만, 소비자에게 너무 많은 메시지를 보내면 브로커는 소비자의 소비력을 알 수 없습니다. 소비자 측의 메시지 수가 너무 크면 소비자 측에서 유휴 상태가 됩니다.
Pull이든 Pull이든 소비자는 항상 브로커와 상호 작용합니다. 상호 작용 방법에는 일반적으로 짧은 연결, 긴 연결 및 폴링이 포함됩니다.
RocketMQ는 Pull과 Push를 모두 지원하는 것처럼 보이지만 실제로 Push도 Pull을 사용하여 구현됩니다. 그러면 Consumer는 Broker와 어떻게 상호 작용합니까?
이것이 RocketMQ 디자인의 독창적인 부분입니다. 짧은 연결도, 긴 연결도, 폴링도 아닌 긴 폴링입니다.
Long polling
Consumer는 메시지 가져오기 요청을 시작합니다. 이는 두 가지 상황으로 나뉩니다.
- Message: Consumer가 메시지를 받은 후 연결이 끊어집니다.
- 메시지 없음: Borker 일정 시간 동안 연결을 유지(유지)합니다. 5초마다 메시지가 있는지 확인하여 메시지가 있으면 Consumer에게 전송되고 연결이 끊어집니다.
트랜잭션 메시지
RocketMQ는 트랜잭션 메시지를 지원합니다. 생산자가 트랜잭션 메시지를 브로커에게 보낸 후 브로커는 소비자가 이를 소비할 수 없도록 시스템 주제 RMQ_SYS_TRANS_HALF_TOPIC에 메시지를 저장합니다. 메시지. RMQ_SYS_TRANS_HALF_TOPIC,这样Consumer就无法消费到这条消息了。
Broker会有一个定时任务,消费RMQ_SYS_TRANS_HALF_TOPIC的消息,向Producer发起回查,回查的状态有三种:提交、回滚、未知。
- 如果回查的状态是提交,回滚,会触发消息的提交和回滚;
- 如果是未知,会等待下一次回查,RocketMQ可以设置一条消息的回查间隔与回查次数,超过一定的回查次数,消息会自动回滚。
延迟消息
延迟消息是指息发到Broker后,不能立刻被Consumer消费,需要等待一定的时间才可以被消费到,RocketMQ只支持特定的延迟时间:1s 5s 10s 30s 1m 2m 3m 4m 5m 6m 7m 8m 9m 10m 20m 30m 1h 2h
RMQ_SYS_TRANS_HALF_TOPIC 메시지를 소비하고 생산자에 대한 검토를 시작하는 예약된 작업을 갖게 됩니다. 검토 상태에는 제출됨, 롤백 및 알 수 없음이 있습니다.
리뷰 상태가 제출 또는 롤백인 경우 메시지 제출 및 롤백이 트리거됩니다.
알 수 없는 경우 RocketMQ는 리뷰 간격과 리뷰 수를 설정할 수 있습니다. 메시지의 경우 특정 횟수의 검토 후에 메시지가 자동으로 롤백됩니다.
지연된 메시지지연된 메시지는 정보가 브로커에 전송된 후 소비자가 즉시 사용할 수 없다는 것을 의미하며 일정 시간 동안 기다려야 합니다. RocketMQ는 특정 지연 시간(1s 5s 10s 30s 1m 2m 3m 4m 5m 6m 7m 8m 9m 10m 20m 30m 1h 2h)만 지원합니다. - 소비 형태
- RocketMQ는 동시 소비와 순차적 소비라는 두 가지 소비 형태를 지원합니다.
순차적으로 소비되는 경우 정렬된 메시지가 동일한 대기열에 있는지 확인해야 합니다. 전송할 대기열을 선택하는 방법 RocketMQ에는 메시지 전송을 위한 여러 오버로드가 있으며 그 중 하나는 대기열 선택을 지원합니다.
동기 플러싱, 비동기 플러싱
1s 5s 10s 30s 1m 2m 3m 4m 5m 6m 7m 8m 9m 10m 20m 30m 1h 2h)만 지원합니다. 생산자는 Borker에 메시지를 보냅니다. Borker는 메시지를 유지해야 합니다. RocketMQ는 두 가지 지속성 전략을 지원합니다.
- 동기 플러싱: Borker는 ACK가 생산자에게 전달된 후 반환됩니다. 메시지의 신뢰성은 높지만 효율성은 느립니다.
- 비동기 플러시: 브로커는 메시지를 PageCache에 쓰고 ACK를 생산자에게 반환합니다. 매우 효율적이라는 장점이 있지만 서버가 중단되면 메시지가 손실될 수 있습니다. RocketMQ 서비스만 중단되면 메시지는 손실되지 않습니다.
동기 복제, 비동기 복제
MQ의 안정성과 가용성을 보장하기 위해 프로덕션 환경에서는 일반적으로 팔로어 노드가 배포되며, 팔로어 노드는 마스터의 데이터를 복사합니다.
동기 복제: 마스터와 팔로어 모두 ACK를 생산자에게 반환하기 전에 메시지를 성공적으로 작성합니다. 신뢰성은 높지만 효율성은 느립니다. 🎜🎜비동기 복제: 마스터가 성공적으로 쓰는 한 ACK는 생산자에게 반환되므로 더 효율적이지만 메시지가 손실될 수 있습니다. 🎜🎜🎜"쓰기"가 PageCache에 기록되는지 아니면 하드 디스크에 기록되는지는 Follower Broker의 구성에 따라 다릅니다. 🎜🎜Producer에 대해 이야기해 보겠습니다🎜🎜RocketMQ는 메시지를 보내는 세 가지 방법을 제공합니다.🎜- oneway: 실행 후 삭제, 단방향 메시지. 즉, 메시지가 전송된 후 이 메서드에는 반환 값이 없습니다.
- 동기화: 메시지가 전송된 후 Borker의 응답을 동기적으로 기다립니다.
- 비동기: 메시지가 전송된 후 Boker의 응답을 받은 후 즉시 반환됩니다.
실제 개발에서는 일반적으로 RocketMQ의 성능을 향상시키려면 Borker 측에서 매개변수, 특히 디스크 브러싱 전략과 복제 전략을 수정하는 경우가 많습니다.
메시지 전송 재시도
메시지 전송 시 MessageQueueSelector를 사용하면 메시지 전송 재시도 메커니즘이 유효하지 않게 됩니다.
메시지 전송에 대한 응답은 다음 네 가지일 수 있습니다.
public enum SendStatus {
SEND_OK,
FLUSH_DISK_TIMEOUT,
FLUSH_SLAVE_TIMEOUT,
SLAVE_NOT_AVAILABLE,
}复制代码
첫 번째 상황을 제외하고 다른 상황에서는 문제가 발생합니다. 메시지가 손실되지 않도록 하려면 Producer 매개변수를 설정해야 합니다. >RetryAnotherBrokerWhenNotStoreOK를 true로 설정합니다. RetryAnotherBrokerWhenNotStoreOK为true。
故障规避机制
如果消息发送失败了,重试的时候,还是发送给这个Borker,那么大概率发送还是失败的,RockteMQ设计精巧之处在于,重试的时候,会自动避开这个Borker,而选择其他Borker,但是目前为止,异步发送没有那么智能,只会在一个Borker上重试,所以强烈建议选择同步发送方式。
RocketMQ提供了两种故障规避机制。用参数SendLatencyFaultEnable来控制。
- false:默认值,只有在重试的时候,才会启用故障规避机制,比如发送消息给BorkerA失败了,重试的时候,会选择BorkerB,但是下次发送消息,还是会选择发送给BorkerA。
- true:开启延迟退避机制,一旦消息发送给BorkerA失败,就会悲观的认为在一段时间内,BorkerA不可用,在将来的一段时间内,不会再向BorkerA发送消息。
延迟退避机制看起来很好用,但是一般来说Borker端繁忙,导致Borker不可用或者网络不可用只是一瞬间的事情,马上就可以恢复,如果开启了延迟退避机制,本来可用的Borker在一段时间内却被规避了,其他Borker更加繁忙,那可能情况更糟糕。
再谈谈Consumer
Consumer线程注意事项
Consumer有两个参数,可以消费的并行度,即ConsumeThreadMin、ConsumeThreadMax,看起来给人的感觉是,如果Consumer端堆积消息比较少,消费线程数为ConsumeThreadMin;如果Consumer端堆积消息比较多,就自动开启新的线程来消费,直到消费线程数为ConsumeThreadMax。但是并不是这样,Consumer内部持有一个线程池,选用的是无界队列,也就是ConsumeThreadMax参数是无效的,所以在实际开发中,ConsumeThreadMin、ConsumeThreadMax往往设置成一样。
ConsumeFromWhere
如果查询不到消费进度的时候,Consumer从哪里开始消费,RocketMQ支持从最新消息、最早消息、指定时间戳这三种方式进行消费。
消费消息重试
RocketMQ会为每个ConsumerGroup都设置一个Topic名称为%RETRY%+consumerGroup的重试队列,用来保存需要给ConsumerGroup重试的消息,但是重试需要一定的延时时间,RocketMQ对于重试消息的处理是先保存至Topic名称为SCHEDULE_TOPIC_XXXX的延迟队列中,后台定时任务按照对应的时间进行Delay后重新保存至%RETRY%+consumerGroup
오류 방지 메커니즘
메시지 전송에 실패하고 재시도 시 여전히 Borker로 전송되는 경우 전송이 여전히 실패할 가능성이 높습니다. RockteMQ는 재시도할 때 자동으로 이 Borker를 피하고 다른 Borker를 선택한다는 점이 정교합니다. 동기 전송 방식. RocketMQ는 두 가지 오류 방지 메커니즘을 제공합니다. 제어하려면SendLatencyFaultEnable 매개변수를 사용하세요. - false: 기본값, 재시도할 때만 오류 방지 메커니즘이 활성화됩니다. 예를 들어 BorkerA에 메시지를 보내는 데 실패하면 재시도할 때 BorkerB가 선택되지만 다음에 메시지를 보낼 때는 여전히 선택됩니다. BorkerA로 전송되었습니다.
- true: 지연된 백오프 메커니즘을 활성화합니다. 메시지가 BorkerA로 전송되지 않으면 BorkerA는 일정 기간 동안 사용할 수 없으며 일정 기간 동안 더 이상 메시지가 BorkerA로 전송되지 않을 것이라고 비관적으로 생각합니다. 미래에.
- 지연된 백오프 메커니즘은 매우 유용한 것 같지만 일반적으로 Borker 측이 사용 중이므로 Borker를 사용할 수 없거나 네트워크를 사용할 수 없게 됩니다. 지연된 경우 즉시 복원할 수 있습니다. 백오프 메커니즘이 켜지면 원래 사용 가능한 Borker가 일정 기간 우회되었고 다른 Borker는 더 바빠서 상황이 더 악화될 수 있습니다.
Consumer에 대해 이야기합시다
Consumer 스레드 고려 사항
Consumer에는 사용할 수 있는 병렬 처리 수준이라는 두 가지 매개변수가 있습니다. ConsumeThreadMin,ConsumeThreadMax인 경우 소비자 측에 누적된 메시지가 상대적으로 적은 경우 소비자 스레드 수는 ConsumeThreadMin인 것 같습니다. 소비자 측에 누적된 메시지가 적습니다. 메시지가 많으면 소비 스레드 수가 ConsumeThreadMax에 도달할 때까지 소비를 위해 새 스레드가 자동으로 열립니다. 그러나 이는 그렇지 않습니다. 소비자는 내부적으로 스레드 풀을 보유하고 제한되지 않은 대기열을 사용합니다. 즉, ConsumeThreadMax 매개변수가 유효하지 않으므로 실제 개발에서는 ConsumeThreadMin이 ConsumeThreadMax는 동일한 값으로 설정되는 경우가 많습니다. ConsumeFromWhere
소비 진행 상황을 쿼리할 수 없는 경우 소비자는 어디에서 소비를 시작합니까? RocketMQ는 최신 메시지, 가장 빠른 메시지 및 지정된 타임스탬프의 소비를 지원합니다.소비자 메시지 재시도RocketMQ는 필요한 메시지를 저장하기 위해 각 ConsumerGroup에 대해 주제 이름이
%RETRY%+consumerGroup인 재시도 대기열을 설정합니다. ConsumerGroup이 재시도하려면 특정 지연 시간이 필요합니다. RocketMQ는 먼저 재시도 메시지를SCHEDULE_TOPIC_XXXX주제 이름으로 지연 대기열에 저장하여 처리합니다. 그런 다음%RETRY%+consumerGroup의 재시도 대기열에 다시 저장하세요. 메시지가 쌓여 소비 용량이 부족할 경우 어떻게 해야 하나요? 소비 진행률을 높이는 것이 가장 좋은 방법입니다. 🎜🎜대기열을 추가하고 소비자를 추가하세요. 🎜🎜원래 Consumer는 특정 규칙에 따라 메시지를 여러 개의 새 주제로 "이동"한 후 여러 ConsumerGroup을 열어 다양한 주제를 소비하는 역할을 합니다. 🎜🎜소비를 위해 새로운 ConsumerGroup을 엽니다. 즉, 두 개의 ConsumerGroup이 동시에 Topic을 소비하지만 오프셋 판단에 주의해야 합니다. 예를 들어 ConsumerGroup은 홀수 메시지를 소비하고 ConsumerGroup은 소비합니다. 짝수가 포함된 메시지입니다. 🎜🎜🎜원래 문해력 텍스트를 쓰면 원활하게 쓸 수 있을 거라 생각했는데, 그래도 문해력 텍스트이기 때문에 RocketMQ와 많이 접촉하지 않은 친구들을 대상으로 한 것이지만 RocketMQ는 그렇습니다. 단 한 사람만으로는 불가능하다는 단순함? RocketMQ에 대해 많이 접하지 못한 친구들도 원활하게 시작할 수 있도록 하는 블로그이기 때문에 블로그를 쓰면서 '이게 중요하고 꼭 필요한가?'라는 생각을 하게 되었습니다. 이 글은 기본적으로 다양한 개념을 소개하고 있고 일단 API가 포함되면 추정되기 때문에 API 수준에 거의 포함되지 않는다고 볼 수 있습니다. 2주 안에 완료되지 않을 거라고요. 🎜🎜End🎜🎜🎜🎜관련 무료 학습 권장사항: 🎜🎜🎜java 기본 튜토리얼🎜🎜🎜
위 내용은 드디어 왔습니다...RocketMQ 활용 능력 장의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!