
집 >데이터 베이스 >MySQL 튜토리얼 >MySQL이 존재하지 않는 것과 인덱스 사이의 관계
MySQL이 존재하지 않는 것과 인덱스 사이의 관계

- coldplay.xixi원래의
- 2020-09-01 17:30:242713검색

일부 비즈니스 시나리오에서는 반환된 데이터가 특정 컬렉션에 존재하지 않는지 확인하기 위해 NOT EXISTS 문이 사용됩니다. 일부 동료는 일부 시나리오에서 NOT EXISTS의 성능이 좋지 않다는 것을 알게 됩니다. 온라인에서 "NOT EXISTS는 인덱싱을 사용하지 않습니다 "라는 소문도 있지만 NOT EXISTS 문을 어떻게 최적화합니까?
오늘의 최적화된 SQL을 예로 들어보겠습니다. 최적화 전 SQL은
SELECT count(1) FROM t_monitor m WHERE NOT exists ( SELECT 1 FROM t_alarm_realtime AS a WHERE a.resource_id=m.resource_id AND a.resource_type=m.resource_type AND a.monitor_name=m.monitor_name)
LEFT JOIN 방법을 사용하여 최적화합니다.
SELECT count(1) FROM t_monitor m LEFT JOIN t_alarm_realtime AS a ON a.resource_id=m.resource_id AND a.resource_type=m.resource_type AND a.monitor_name=m.monitor_name WHERE a.resource_id is NULL
최적화 효과:
최적화 전 실행 시간은 다음과 같습니다. 29초 이상, 최적화 1.2초 후 최적화가 25배 증가했습니다.
존재하지 않음 정말 색인이 생성되지 않았나요?
두 SQL의 실행 계획을 확인해보세요!
NOT EXIST 메소드를 사용한 실행 계획:
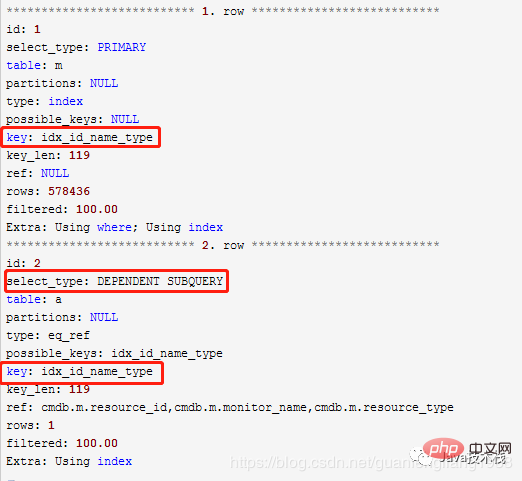
LEFT JOIN 메소드를 사용한 실행 계획:

실행 계획에서 두 테이블 모두 인덱스를 사용합니다, 차이점은 NOT EXISTS는 " DEPENDENT SUBQUERY" 방법을 사용하는 반면 LEFT JOIN은 일반적인 테이블 연결 방법을 사용합니다.
읽기 추천: 인덱스가 쿼리 속도를 향상시킬 수 있는 이유는 무엇입니까?
두 메소드의 실행 과정을 보려면 MySQL에서 제공하는 Profiling 메소드를 사용하세요.
NOT EXIST 메소드를 사용한 실행 프로세스:

LEFT JOIN 방식을 사용한 실행 프로세스:

실행 프로세스 측면에서 LEFT JOIN 방식은 보내는 데이터 항목(1.2s)에서 주로 소비되고, NOT EXISTS 방식은 주로 소비됩니다. 데이터의 실행 및 전송에 있어서 프로파일링은 100행의 레코드만 저장하도록 제한됩니다.
프로파일링에서는 "데이터 실행 및 전송"의 조합이 47개만 표시됩니다(각 조합은 약 50us). 실행 계획을 보면 부정확한 통계를 무시하고 외부 t_monitor의 데이터 양이 578436행임을 알 수 있습니다. 아래에서 NOT EXISTS 메서드를 사용하면 총 소비 시간 =50μs*578436=28921800us=28.92s와 함께 "데이터 실행 및 전송"의 578436개 조합이 생성됩니다.
위의 실행 프로세스에서 추론할 수 있습니다.
NOT EXISTS 메서드를 사용한 실행 성능은 NOT EXISTS 하위 쿼리의 실행 횟수, 즉 외부 쿼리 결과의 데이터 양에 따라 크게 달라집니다. 세트.
외부 쿼리 결과 집합의 데이터 볼륨 N이 작을 때 실행 성능이 더 좋습니다. N=10이면 실행 시간은 50μs*10=500us=0.005s이고 약간의 추가 소비가 발생합니다. 실행 결과는 0.01초 또는 10밀리초 범위일 수도 있으며 이는 대부분의 애플리케이션에 허용됩니다.
외부 Chengxun 결과 집합의 데이터 볼륨 N이 크거나 심지어 수천만 개의 데이터인 경우 NOT EXISTS의 쿼리 성능이 매우 나빠지고 서버 IO 및 CPU 리소스도 많이 소모합니다. 다른 사업에 영향을 미치는 것은 정상적으로 운영되고 있습니다.
위 문제 외에도 최적화 과정에서 동일한 데이터를 저장해야 하는 resources_id 컬럼이 두 테이블에서 다르게 정의되어 한 테이블은 VARCHAR이고 다른 테이블은 BIGINT인 것을 발견했습니다. 외부 결과 집합의 필드 유형 NOT EXIST 단어 테이블의 다양한 필드 유형은 NOT EXISTS 하위 쿼리에서 인덱스 사용을 방지하여 하위 쿼리 성능이 저하되고 궁극적으로 전체 쿼리의 실행 성능에 영향을 미칩니다.
Jingdong Mall에서도 비슷한 사례가 많이 보였습니다. 일부 테이블은 VARCHAR를 사용하여 주문 번호를 저장하고 다른 테이블은 BIGINT를 사용하여 두 테이블을 관리할 때 성능이 매우 나쁩니다. 이것을 경고로 받아들이십시오. 공개 계정인 Java Technology Stack을 팔로우하고 m36에 회신하여 MySQL R&D 군사 규정 사본을 받으세요.
관련 학습 권장사항: mysql 비디오 튜토리얼
위 내용은 MySQL이 존재하지 않는 것과 인덱스 사이의 관계의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!