
일반적인 Redis 인터뷰 질문 공유

- 藏色散人앞으로
- 2020-07-25 13:35:454311검색

소개: Redis는 ANSI C 언어로 작성된 오픈 소스 비관계형 비관계형 데이터베이스로, BSD 프로토콜을 준수하고 네트워크, 메모리 기반 및 영구 로그 유형, 키-값 데이터베이스를 지원하고 API를 제공합니다. 여러 언어로 된 데이터베이스.
주제 추천: 2020 redis 인터뷰 질문(최신)
전통적인 데이터베이스는 ACID 규칙을 따릅니다. Nosql(Not Only SQL의 약자, 기존 관계형 데이터베이스와 다른 데이터베이스 관리 시스템의 총칭)은 일반적으로 CAP 정리를 따르며 분산형은 일반적으로 CAP 정리를 따릅니다.
Github 소스 코드: https://github.com/antirez/redis
Redis 공식 웹사이트: https://redis.io/
권장: "redis 튜토리얼"
Redis는 어떤 데이터 유형을 수행합니까? 지원하다?
문자열 문자열:
형식: 키 값 설정
문자열 유형은 바이너리 안전합니다. 이는 redis 문자열에 모든 데이터가 포함될 수 있음을 의미합니다. 예를 들어 jpg 이미지 또는 직렬화된 개체입니다.
문자열 유형은 Redis의 가장 기본적인 데이터 유형입니다. 키는 최대 512MB까지 저장할 수 있습니다.
Hash(해시)
형식: hmset 이름 key1 value1 key2 value2
Redis 해시는 키-값(key=>value) 쌍의 집합입니다.
Redis 해시는 문자열 형식의 필드와 값을 매핑하는 테이블입니다. 특히 객체를 저장하는 데 적합합니다.
List(목록)
Redis 목록은 삽입 순서로 정렬된 간단한 문자열 목록입니다. 목록의 헤드(왼쪽) 또는 꼬리(오른쪽)에 요소를 추가할 수 있습니다
형식: lpush 이름 값
키에 해당하는 목록의 헤드에 문자열 요소 추가
형식: rpush 이름 값
key에 해당 목록 끝에 문자열 요소 추가
Format: lrem name index
key는 목록의 값과 동일한 count 요소 삭제에 해당
Format: llen name
길이를 반환 key
Set(set)
에 해당하는 목록 형식: sadd 이름 값
Redis의 Set은 순서가 지정되지 않은 문자열 유형의 모음입니다.
세트는 해시 테이블을 통해 구현되므로 추가, 삭제, 검색의 복잡성은 O(1)입니다.
zset (sorted set: ordered set)
Format: zadd name Score value
Redis zset도 set과 마찬가지로 문자열 형식 요소의 모음이며 중복 멤버는 허용되지 않습니다.
차이점은 각 요소가 이중 유형 점수와 연관되어 있다는 것입니다. Redis는 점수를 사용하여 컬렉션의 구성원을 작은 것부터 큰 것까지 정렬합니다.
zset의 멤버는 고유하지만 점수가 반복될 수 있습니다.
Redis 지속성이란 무엇인가요? Redis에는 어떤 지속성 방법이 있습니까? 장점과 단점은 무엇입니까?
지속성은 서비스가 다운될 때 메모리 데이터가 손실되는 것을 방지하기 위해 메모리 데이터를 디스크에 쓰는 것입니다.
Redis는 두 가지 지속성 방법을 제공합니다: RDB(기본값) 및 AOF
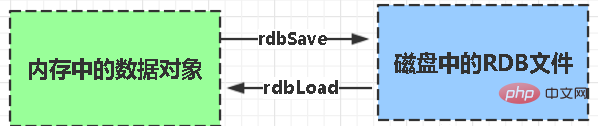
RDB:
rdb는 Redis DataBase의 약어입니다.
핵심 기능 rdbSave(RDB 파일 생성) 및 rdbLoad(파일에서 메모리 로드) 함수
AOF:
Aof는 Append-only file
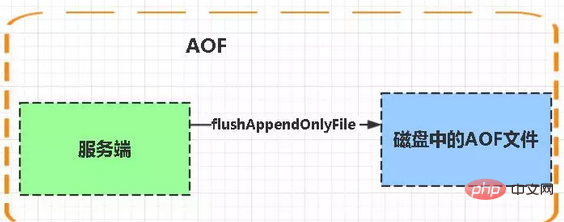
의 약자입니다. flashAppendOnlyFile 함수는 서버(예약된) 작업이나 함수가 실행될 때마다 호출됩니다. 이 함수는 다음 두 가지 작업을 수행합니다.
aof 쓰기 저장:
WRITE: 조건에 따라 aof_buf의 캐시를 AOF 파일에 씁니다.
SAVE: 조건에 따라 fsync 또는 fdatasync 함수를 호출하여 AOF 파일을 디스크에 저장합니다.
저장 구조:
내용은 RESP(Redis Communication Protocol) 형식의 명령 텍스트 저장소입니다.
비교:
1. AOF 파일은 RDB보다 더 자주 업데이트되므로 먼저 데이터를 복원하려면 aof를 사용하세요.
2. AOF는 RDB보다 더 안전하고 큽니다
3. RDB는 AOF
4보다 성능이 더 좋습니다. 둘 다 구성되면 AOF가 먼저 로드됩니다
위에서 방금 Redis 통신 프로토콜(RESP)을 언급했습니다. RESP가 무엇인지 설명해 주시겠어요? 특징은 무엇입니까? (많은 인터뷰가 실제로 질문의 연속이라는 것을 알 수 있습니다. 면접관은 실제로 이 점에 대한 답변을 기다리고 있습니다. 질문에 답변하면 평가에 또 다른 포인트가 추가됩니다.)
RESP는 Redis 클라이언트이며 service 클라이언트가 이전에 사용했던 통신 프로토콜
RESP의 특징: 간단한 구현, 빠른 구문 분석 및 우수한 가독성
단순 문자열의 경우 응답의 첫 번째 바이트는 "+"입니다. Reply
오류의 경우 첫 번째 바이트입니다. 응답은 "-"입니다. Error
정수의 경우 응답의 첫 번째 바이트는 ":"입니다. 정수
대량 문자열의 경우 응답의 첫 번째 바이트는 "$"입니다. 문자열
배열의 경우 응답의 첫 번째 바이트는 " * "Array
Redis에는 어떤 아키텍처 패턴이 있나요? 각각의 특성에 대해 이야기해 보세요
독립형 버전
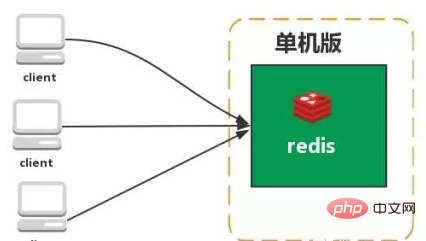
특징: 단순
문제:
1. 제한된 메모리 용량 2. 제한된 처리 능력 3. 고가용성 불가능.
마스터-슬레이브 복제
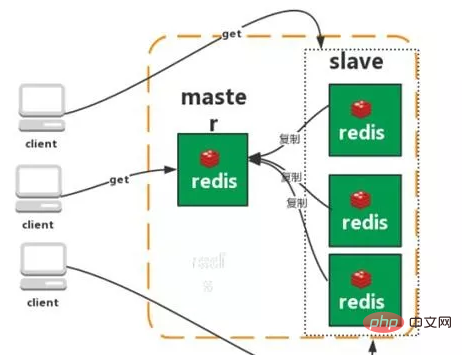
Redis의 복제 기능을 사용하면 복제된 서버가 마스터 서버(마스터)인 Redis 서버를 기반으로 서버의 복제본을 얼마든지 생성할 수 있습니다. 복제를 통해 생성된 서버 복제본은 슬레이브입니다. 마스터 서버와 슬레이브 서버 간의 네트워크 연결이 정상이라면 마스터 서버와 슬레이브 서버는 동일한 데이터를 갖게 되며, 마스터 서버는 자체적으로 발생하는 데이터 업데이트를 슬레이브 서버와 항상 동기화하여 데이터가 마스터 서버와 슬레이브 서버는 항상 동일합니다.
특징:
1. 마스터/슬레이브 역할
2. 마스터/슬레이브 데이터가 동일합니다.
3. 슬레이브 라이브러리로 전송할 때 마스터의 읽기 부담을 줄입니다.
문제:
높음을 보장할 수 없습니다. Availability
마스터 쓰기에 대한 솔루션은 없습니다. Pressure
Sentinel
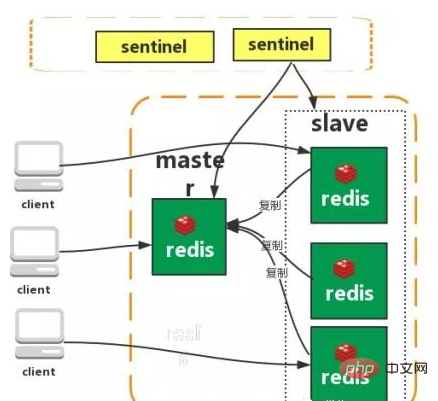
Redis sentinel은 Redis 마스터 및 슬레이브 서버를 모니터링하고 마스터 서버가 오프라인이 되면 자동으로 장애 조치를 수행하는 분산 시스템입니다. 세 가지 기능:
모니터링: Sentinel은 마스터 서버와 슬레이브 서버가 정상적으로 작동하는지 지속적으로 확인합니다.
알림: 모니터링되는 Redis 서버에 문제가 있는 경우 Sentinel은 API를 통해 관리자나 다른 애플리케이션에 알림을 보낼 수 있습니다.
자동 장애 조치: 메인 서버가 제대로 작동하지 않으면 Sentinel이 자동 장애 조치 작업을 시작합니다.
특징:
1. 고가용성 보장
2. 각 노드 모니터링
3. 자동 오류 마이그레이션
단점: 마스터-슬레이브 모드, 전환하는 데 시간이 걸림
마스터 쓰기의 부담을 해결하지 못함
클러스터(프록시 유형):
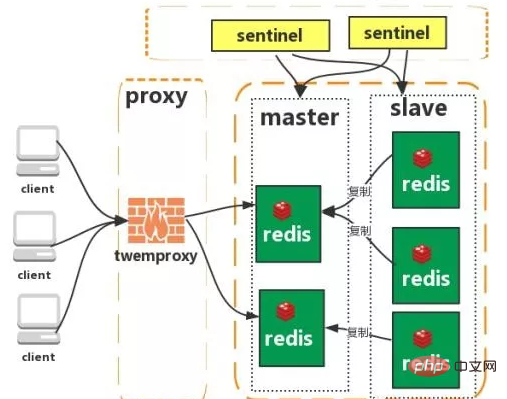
Twemproxy는 Twitter 오픈 소스 Redis이며 Memcache의 빠르고 가벼운 프록시 서버입니다. Twemproxy는 Memcached ASCII 프로토콜과 Redis를 지원하는 빠른 단일 스레드 프록시 프로그램입니다. 규약.
기능: 1. 다중 해시 알고리즘: MD5, CRC16, CRC32, CRC32a, hsieh, murmur, Jenkins
2. 실패한 노드의 자동 삭제 지원
3 백엔드 샤딩 샤딩 로직은 비즈니스에 투명합니다. 비즈니스 측면 읽기 및 쓰기 방법은 단일 Redis를 운영하는 것과 동일합니다
단점: 새로운 프록시가 추가되고 고가용성을 유지해야 합니다.
장애 조치 논리는 자동 오류 전송을 지원하지 않으며 확장성이 좋지 않습니다.
클러스터(직접 연결 유형):
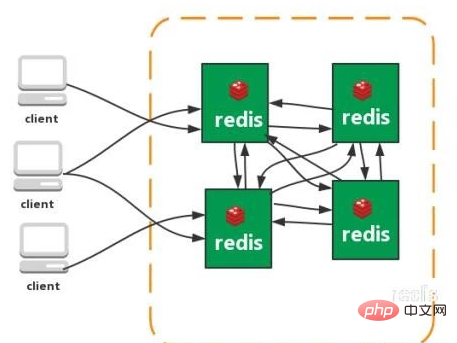
redis 3.0 이후 버전에서는 redis-cluster 클러스터를 지원합니다. Redis-Cluster는 센터리스 구조를 채택합니다. 각 노드는 데이터와 전체 클러스터 상태를 저장하고 각 노드는 다른 모든 노드와 연결됩니다.
기능:
1. 중앙 아키텍처가 없으며(노드가 성능 병목 현상에 영향을 주지 않음), 프록시 레이어가 없습니다.
2. 데이터는 슬롯에 따라 여러 노드에 저장되고 배포됩니다. 데이터는 노드 간에 공유되며 데이터 배포는 동적으로 조정될 수 있습니다.
3. 확장성, 1000개 노드까지 선형 확장이 가능하며, 노드를 동적으로 추가하거나 삭제할 수 있습니다.
4. 고가용성, 일부 노드를 사용할 수 없을 때에도 클러스터를 계속 사용할 수 있습니다. 백업 데이터 복사본을 만들기 위해 슬레이브를 추가하면
5 노드가 가십 프로토콜을 통해 상태 정보를 교환하고 투표 메커니즘을 사용하여 슬레이브에서 마스터로의 역할 승격을 완료합니다.
단점:
1. 자원 고립성이 좋지 않아 상호 영향이 발생하기 쉽습니다.
2. 데이터는 비동기식으로 복사되며 데이터의 강력한 일관성이 보장되지 않습니다.
일관된 해시 알고리즘이란 무엇인가요? 해시 슬롯이란 무엇입니까?
Redis에서 자주 사용하는 명령어는?
Keys 패턴
*은 비트로 시작하는
모두 일치함을 의미합니다.
Exists 키가 존재하는지 확인합니다.
Set
키에 해당하는 값을 문자열 형식 값으로 설정합니다.
setnx
key에 해당하는 값을 string형의 값으로 설정합니다. 키가 이미 존재하면 0을 반환하고 nx는 존재하지 않음을 의미합니다.
키 삭제
처음 1을 반환 삭제하고 두 번째 0을 반환
Expire 만료 시간(초 단위) 설정
TTL 남은 시간 확인
음수가 반환되는 경우 , 해당 키는 유효하지 않으며 키는 더 이상 존재하지 않습니다.
Setex
키에 해당하는 값을 문자열 형식의 값으로 설정하고, 이 키 값에 해당하는 유효 기간을 지정합니다.
Mset
여러 키의 값을 동시에 설정합니다. 성공하면 ok를 반환하면 모든 값이 설정된다는 의미이고, 실패하면 0을 반환하면 값이 설정되지 않는다는 의미입니다.
Getset
키 값을 설정하고 키의 이전 값을 반환합니다.
Mget
한 번에 여러 키의 값을 가져옵니다. 해당 키가 없으면 그에 따라 nil이 반환됩니다.
Incr
은 키 값에 대해 증분 연산을 수행하고 새 값을 반환합니다. incr이 int가 아닌 값인 경우 오류가 반환됩니다. incr이 존재하지 않는 키인 경우 해당 키를 1
incrby
로 설정합니다. 키가 없으면 키가 설정되고 원래 값이 고려됩니다. 0
Decr
은 키 값에 대한 빼기 작업을 수행합니다. decr이 없으면 키를 -1
Decrby로 설정합니다.
decr과 동일하며 지정된 값을 뺍니다.
Append
지정된 키의 문자열 값에 값을 추가하고 새 문자열 값의 길이를 반환합니다.
Strlen
지정된 키 값의 길이를 가져옵니다.
persist xxx(만료 시간 취소)
데이터베이스 선택(0-15 데이터베이스)
0 선택 //데이터베이스 선택
age 1 이동//age 1을 데이터베이스로 이동
Randomkey가 무작위로 키를 반환합니다
Rename Rename
반환 데이터 유형 입력
08
Redis 분산 잠금을 사용해 본 적이 있나요? 어떻게 구현되나요?
먼저 setnx를 사용하여 잠금을 잡은 후, 만료를 사용하여 잠금 해제를 잊어버리지 않도록 잠금에 만료 시간을 추가하세요.
setnx 후 만료를 실행하기 전에 프로세스가 예기치 않게 충돌하거나 유지 관리를 위해 다시 시작해야 하는 경우 어떻게 되나요?
set 명령어에는 매우 복잡한 매개변수가 있습니다. 이는 setnx를 결합하고 동시에 하나의 명령어로 만료될 수 있어야 합니다.
09
Redis를 비동기 대기열로 사용해 본 적이 있나요? 단점은 무엇입니까?
일반적으로 목록 구조는 대기열로 사용되며 rpush는 메시지를 생성하고 lpop은 메시지를 소비합니다. lpop에서 아무런 메시지도 나오지 않을 경우, 잠시 잠을 자고 다시 시도해 보세요.
단점:
소비자가 오프라인이 되면 생성된 메시지가 손실되므로 Rabbitmq 등과 같은 전문적인 메시지 대기열을 사용해야 합니다.
한 번 생산하고 여러 번 소비할 수 있나요?
pub/sub 주제 구독자 모델을 사용하면 1:N 메시지 대기열을 달성할 수 있습니다.
10
캐시 침투란 무엇인가요? 그것을 피하는 방법? 캐시 눈사태란 무엇입니까? 그것을 피하는 방법?
캐시 침투
일반 캐시 시스템에서는 키를 기준으로 쿼리를 캐싱합니다. 해당 값이 없으면 백엔드 시스템(예: DB)에서 검색해야 합니다. 일부 악의적인 요청은 존재하지 않는 키를 의도적으로 쿼리합니다. 요청량이 많으면 백엔드 시스템에 많은 부담을 줍니다. 이를 캐시 침투라고 합니다.
어떻게 피하나요?
1: 쿼리 결과는 비어 있을 때도 캐시됩니다. 캐시 시간을 더 짧게 설정하거나 키에 해당하는 데이터가 삽입된 후 캐시를 지워야 합니다.
2: 존재해서는 안 되는 필터 키입니다. 가능한 모든 키를 큰 비트맵에 넣고 쿼리할 때 비트맵을 통해 필터링할 수 있습니다.
Cache Avalanche
캐시 서버가 다시 시작되거나 일정 기간 동안 많은 수의 캐시가 실패하는 경우, 실패 시 백엔드 시스템에 많은 부담을 주게 됩니다. 시스템 충돌을 일으킵니다.
어떻게 피하나요?
1: 캐시가 만료된 후 잠금 또는 대기열을 통해 데이터베이스를 읽고 캐시를 쓰는 스레드 수를 제어합니다. 예를 들어, 하나의 스레드만 데이터를 쿼리하고 특정 키에 대한 캐시를 쓸 수 있으며 다른 스레드는 대기합니다.
2: 두 번째 수준 캐시를 만듭니다. A1은 원본 캐시, A2는 복사 캐시, A1이 만료되면 A2에 액세스할 수 있으며 A1 캐시 만료 시간은 단기로 설정되고 A2는 장기로 설정됩니다. 용어
3: 다른 키, 다른 만료 시간을 설정하여 캐시 무효화 시간이 최대한 균일하도록 합니다.
위 내용은 일반적인 Redis 인터뷰 질문 공유의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!