
PHP7의 혁신과 성능 최적화에 대해 알아보세요

- coldplay.xixi앞으로
- 2020-06-24 17:26:103283검색

PHP는 20년의 역사를 거쳤습니다. PHP7은 이전 PHP5 시리즈에 비해 특히 성능 면에서 비약적인 발전을 이룬 획기적인 혁신이라고 할 수 있습니다. PHP는 전 세계적으로 널리 사용되는 웹 개발 언어입니다. PHP7의 혁신은 확실히 이러한 웹 서비스에 더욱 근본적인 변화를 가져올 것입니다.
다음은 Bird Brother의 PPT 차트에서 인용한 것입니다(웹 사이트의 82%가 PHP를 개발 언어로 사용합니다).
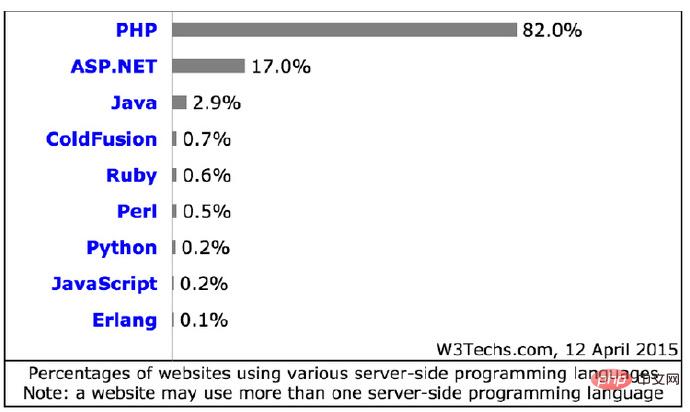
(참고: 웹 사이트는 여러 언어를 개발 언어로 사용할 수 있습니다. )
(참고: 이 기사에는 Niao 형제의 PPT 스크린샷이 많이 포함되어 있으며 사진의 저작권은 Niao 형제에게 있습니다.)
먼저 두 가지 흥미로운 성능 테스트 결과 사진을 살펴보겠습니다
PHP7 성능 테스트 결과, 성능 스트레스 테스트 결과, 시간 소모가 2.991에서 1.186으로 60%나 대폭 감소했습니다.
WordPress QPS 스트레스 테스트(PPT 사진): 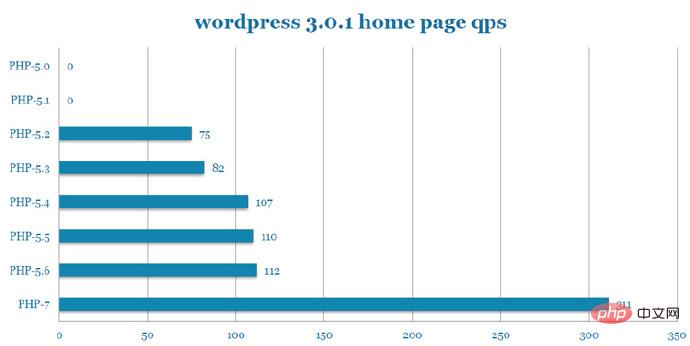
WordPress 프로젝트에서 PHP7은 PHP5.6에 비해 QPS가 2.77배 증가했습니다.
흥미로운 성능 테스트 결과 비교를 읽은 후 본론으로 들어가겠습니다. PHP7에는 많은 새로운 기능이 있지만 주요 변경 사항에 더 중점을 둘 것입니다.
1. 새로운 기능 및 변경 사항
1. 스칼라 유형 선언 및 스칼라 유형 선언
PHP 언어의 매우 중요한 기능은 PHP 프로그램을 작성하기가 매우 쉬워졌습니다. PHP를 처음 접하는 사람들도 빠르게 시작할 수 있지만, 약간의 논란도 따릅니다. 변수 유형 정의를 지원하는 것은 혁신적인 변화라고 할 수 있습니다. PHP는 선택적인 방식으로 유형 정의를 지원하기 시작했습니다. 또한, 전환 명령 선언(strict_type=1)도 도입되었습니다. 이 명령이 활성화되면 현재 파일의 프로그램이 엄격한 함수 매개변수 전송 유형 및 반환 유형을 따르도록 합니다.
예를 들어 추가 기능과 유형 정의를 다음과 같이 작성할 수 있습니다. 
필수 유형 전환 명령과 결합하면 다음과 같이 될 수 있습니다.
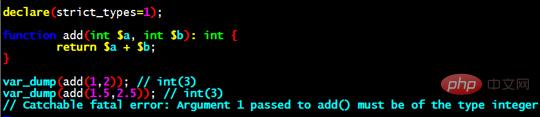
strict_type이 켜져 있지 않으면 PHP는 이를 필요한 유형으로 변환하려고 시도합니다. 이 옵션을 켠 후에는 PHP가 변경되고 유형이 일치하지 않으면 오류가 발생합니다. 던져진다. 이는 "강력한 형식의" 언어를 좋아하는 학생들에게 좋은 소식입니다.
자세한 소개: PHP7 스칼라 유형 선언 RFC [번역]
2. 더 많은 오류를 포착할 수 있게 되었습니다. 예외
PHP7은 전역 발생 가능 인터페이스를 구현하며, 원래 예외 및 일부 오류는 이 인터페이스가 구현되고 예외 상속 구조입니다. 인터페이스 형태로 정의됩니다. 결과적으로 PHP7에서는 더 많은 오류가 포착 가능한 예외가 되어 개발자에게 반환됩니다. 포착되지 않으면 오류가 되어 프로그램 내에서 처리할 수 있습니다. 이러한 포착 가능한 오류는 일반적으로 존재하지 않는 기능과 같이 프로그램에 치명적인 손상을 일으키지 않는 오류입니다. PHP7은 개발자의 처리를 더욱 용이하게 하고 개발자가 프로그램을 더 잘 제어할 수 있도록 해줍니다. 기본적으로 오류는 프로그램을 직접 중단시키고 PHP7은 이를 캡처하고 처리하는 기능을 제공하여 프로그램이 계속 실행되도록 하여 프로그래머에게 보다 유연한 선택을 제공합니다.
예를 들어 존재 여부를 알 수 없는 함수를 실행하려면 PHP5 호환 방식은 함수 호출 전에 function_exist 판단을 추가하는 반면, PHP7에서는 Exception을 잡는 방식을 지원합니다.
아래 그림과 같이(스크린샷은 PPT에서 발췌): 
3. AST(Abstract Syntax Tree, 추상 구문 트리)
AST는 PHP 컴파일 과정에서 미들웨어 역할을 합니다. 원래의 직접 교체 인터프리터에서 opcode를 뱉어내는 방식은 인터프리터(파서)와 컴파일러(컴파일러)를 분리하므로 일부 Hack 코드를 줄일 수 있는 동시에 구현을 더 쉽게 이해하고 유지 관리할 수 있습니다.
PHP5: 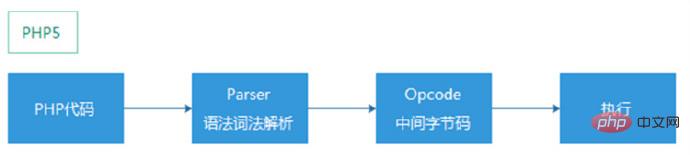
PHP7: 
추가 AST 정보: https://wiki.php.net/rfc/abstract_syntax_tree
4. 네이티브 TLS(네이티브 스레드 로컬 저장소, 네이티브 스레드 로컬 저장소)
PHP는 다중 스레드 모드(예: 웹 서버 Apache의 Waker 및 이벤트 모드는 다중 스레드임)의 "스레드 안전성"(TS, Thread Safe) 문제를 해결해야 합니다. 따라서 각 스레드 자체는 다른 스레드와의 상호 오염을 피하기 위해 자신의 개인 데이터를 저장하기 위해 어떤 방식으로든 개인 공간을 구축해야 합니다. PHP5에서 채택한 방법은 대규모 전역 배열을 유지하고 각 스레드에 독립적인 저장 공간을 할당하는 것입니다. 스레드는 자체 키 값을 통해 이 전역 데이터 그룹에 액세스합니다.
그리고 이 고유 키 값은 PHP5에서 전역 변수를 사용해야 하는 모든 함수에 전달되어야 합니다. PHP7은 이 전달 방법이 친숙하지 않고 몇 가지 문제가 있다고 생각합니다. 따라서 전역 스레드별 변수를 사용하여 이 키 값을 저장해 보세요.
관련 네이티브 TLS 문제:
https://wiki.php.net/rfc/native-tls
5. 기타 새로운 기능
PHP7에는 많은 새로운 기능과 변경 사항이 있으므로 여기서는 자세히 설명하지 않습니다.
(1) Int64 지원, 다양한 플랫폼에서 정수 길이를 통합하고 2GB보다 큰 문자열 및 파일 업로드를 지원합니다.
(2) 균일한 변수 구문.
(3) 일관된 foreach 동작
(4) 새로운 연산자 <=>, ??
(5) 유니코드 문자 형식 지원(u{xxxxx})
(6) 익명 클래스 지원(익명 클래스)
… …
2. 도약적인 성능 혁신: 전속력으로 앞서
1. JIT 및 성능
Just In Time(Just In Time 컴파일)은 실행 시간을 의미하는 소프트웨어 최적화 기술입니다. 그래야만 바이트코드가 기계어 코드로 컴파일됩니다. 직관적인 관점에서 볼 때 기계어 코드는 컴퓨터가 직접 인식하고 실행할 수 있다고 생각하기 쉬우며, Opcode를 하나씩 읽어서 실행하는 것이 Zend보다 효율적입니다. 그 중 HHVM(HipHop Virtual Machine, HHVM은 페이스북 오픈소스 PHP 가상머신)은 JIT를 사용하는데, 이는 PHP 성능 테스트를 몇 배로 향상시키며 충격적인 테스트 결과를 내놓고 있어 직관적으로 JIT가 강력하다고 생각하게 만든다. 돌을 금으로 바꾸는 기술.
실제로 2013년에 Niao 형제와 Dmitry(PHP 언어 핵심 개발자 중 한 명)가 PHP5.5 버전에서 JIT를 시도한 적이 있습니다(출시되지 않았습니다). PHP5.5의 원래 실행 프로세스는 어휘 및 구문 분석(형식은 어셈블리와 다소 유사)을 통해 PHP 코드를 opcode 바이트코드로 컴파일하는 것입니다. 그런 다음 Zend 엔진은 이러한 opcode 명령어를 읽고 하나씩 구문 분석하고 실행합니다.

그리고 opcode 링크 뒤에 유형 추론(TypeInf)을 도입한 다음 실행하기 전에 JIT를 통해 ByteCode를 생성했습니다. 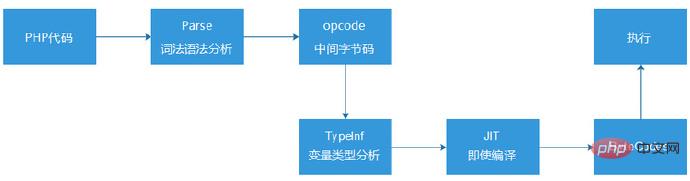
그래서 JIT를 구현한 후 벤치마크(테스트 프로그램)에서 흥미로운 결과를 얻었습니다. PHP5.5에 비해 성능이 8배 향상되었습니다. 하지만 이 최적화를 실제 프로젝트인 워드프레스(오픈소스 블로그 프로젝트)에 적용해 보니 성능 향상이 거의 보이지 않아 아리송한 테스트 결과를 얻었습니다.
그래서 그들은 Linux에서 프로파일 유형의 도구를 사용하여 프로그램 실행의 CPU 시간 소비를 분석했습니다.
워드프레스 100회 실행 시 CPU 소모 분포(PPT 스크린샷): 
참고:
21%의 CPU 시간이 메모리 관리에 소요됩니다.
CPU 시간의 12%는 주로 PHP 배열 추가, 삭제, 수정 및 확인과 같은 해시 테이블 작업에 사용됩니다.
CPU 시간의 30%가 strlen과 같은 내장 함수에 사용됩니다.
25% CPU 시간이 VM(Zend Engine)에서 소비됩니다.
분석 결과 두 가지 결론에 도달했습니다.
(1) JIT에서 생성된 ByteCode가 너무 크면 CPU 캐시 적중률이 감소합니다(CPU Cache Miss)
PHP5.5 코드에서 , 명백한 유형 정의가 없기 때문에 유형 추론에만 의존할 수 있습니다. 추론 가능한 변수 유형을 최대한 정의한 후 유형 추론과 결합하여 이 유형이 아닌 분기 코드를 제거하여 직접 실행 가능한 기계어 코드를 생성합니다. 하지만 타입 추론은 모든 타입을 유추할 수는 없습니다. 워드프레스에서는 유추할 수 있는 타입 정보가 30% 미만으로 제한되어 있으며, 축소할 수 있는 브랜치 코드도 제한되어 있습니다. 결과적으로 JIT 이후에는 기계어 코드가 직접 생성되는데, 생성된 ByteCode가 너무 커서 결국 CPU 캐시 적중(CPU Cache Miss)이 크게 감소하게 됩니다.
CPU 캐시 적중이란 CPU가 명령을 읽고 실행할 때 CPU의 1차 캐시(L1)에서 필요한 데이터를 읽을 수 없는 경우 아래쪽으로 2차 캐시( L2)와 3단계 캐시(L3)는 결국 메모리 영역에서 필요한 명령 데이터를 찾으려고 시도하며, 메모리와 CPU 캐시 간의 읽기 시간 차이는 100배에 달할 수 있습니다. 따라서 ByteCode가 너무 크고, 실행되는 명령의 개수가 너무 많으면 다중 레벨 캐시는 그렇게 많은 데이터를 수용할 수 없으며, 일부 명령은 메모리 영역에 저장되어야 합니다. 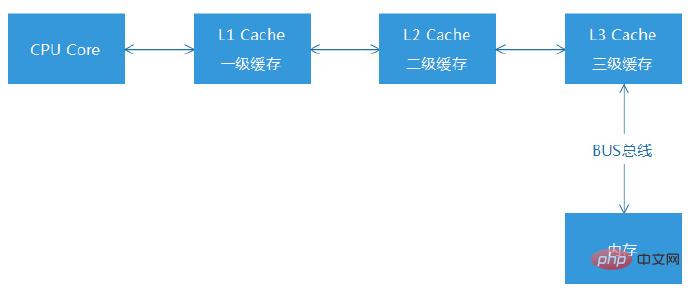
CPU의 모든 수준에서 캐시 크기도 제한되어 있습니다. 다음 그림은 Intel i7 920의 구성 정보입니다. 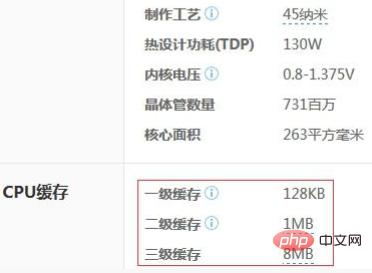
따라서 CPU 캐시 적중률이 감소하면 On 시간이 크게 증가합니다. 반면에 JIT는 성능 향상을 가져올 것입니다.
JIT를 통해 VM의 오버헤드를 줄이는 동시에 명령어 최적화를 통해 메모리 할당 횟수를 줄일 수 있어 메모리 관리 개발을 간접적으로 줄일 수 있습니다. 그러나 실제 WordPress 프로젝트의 경우 CPU 시간의 25%만이 VM에 소비되며, 주요 문제와 병목 현상은 실제로 VM에 있지 않습니다. 따라서 이 버전의 PHP7 기능에는 JIT 최적화 계획이 포함되지 않았습니다. 하지만 이후 버전에서는 구현될 가능성이 높으니 기대해볼만한 가치가 있습니다.
(2) JIT 성능 개선 효과는 프로젝트의 실제 병목 현상에 따라 달라집니다
JIT는 코드 양이 상대적으로 적고 최종 생성된 ByteCode도 상대적으로 적으며 주요 오버헤드가 VM에 있기 때문에 벤치마크에서 크게 개선되었습니다. 그러나 실제 WordPress 프로젝트에서는 WordPress의 코드량이 벤치마크에 비해 훨씬 크기 때문에 뚜렷한 성능 향상이 없습니다. ByteCode는 오버헤드가 너무 커서 결국 개선되지 않습니다.
프로젝트 유형에 따라 CPU 오버헤드 비율이 다르며 실제 프로젝트가 없는 성능 테스트는 그리 대표성이 없습니다.
2. Zval의 변경 사항
사실 PHP에서 다양한 유형의 변수를 저장하는 실제 저장소는 Zval이며 이는 허용 오차와 허용 오차가 특징입니다. 본질적으로 C언어로 구현한 구조체(struct)이다. PHP를 작성하는 학생들의 경우 대략적으로 배열과 유사한 것으로 이해할 수 있습니다.
PHP5의 Zval, 메모리가 24바이트를 차지 (PPP 스크린샷): 
PHP7의 Zval, 메모리가 16바이트를 차지 (PPT 스크린샷): 
Zval이 24바이트에서 16워드로 줄었습니다. 섹션, 왜 줄어들고 있나요? 여기에 C에 익숙하지 않은 학생들의 이해를 돕기 위해 약간의 C 언어 기초를 추가해야 합니다. struct와 Union(union)에는 약간의 차이가 있습니다. Struct의 각 멤버 변수는 독립적인 메모리 공간을 차지하는 반면, Union의 멤버 변수는 메모리 공간을 공유합니다. public space는 수정 후에는 다른 멤버 변수에 대한 기록이 없습니다. 따라서 멤버 변수가 훨씬 많아 보이지만 실제로 차지하는 메모리 공간은 줄어들었다.
또한 분명히 변경된 기능도 있으며 일부 단순 유형은 더 이상 참조를 사용하지 않습니다.
Zval 구조 다이어그램(PPT에서): 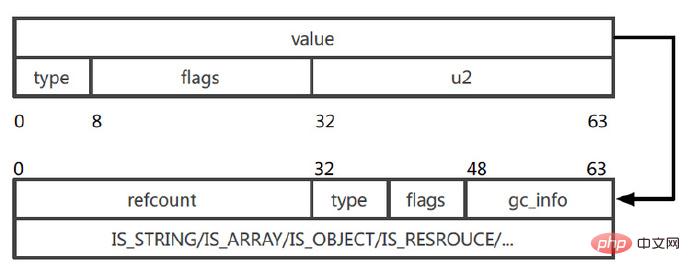
그림의 Zval은 64비트 두 개로 구성됩니다(1바이트 = 8비트, 비트는 "비트"). 변수 유형이 long 또는 bealoon인 경우 길이는 64비트를 초과하지 않습니다. , 값에 직접 저장되며 후속 참조가 없습니다. 변수 유형이 64비트를 초과하는 배열, 객체, 문자열 등인 경우 저장되는 값은 실제 저장 구조 주소를 가리키는 포인터입니다.
간단한 변수 유형의 경우 Zval 저장소는 매우 간단하고 효율적입니다.
참조가 필요하지 않은 유형: NULL, Boolean, Long, Double
참조가 필요한 유형: String, Array, Object, Resource, Reference
3 내부 유형 zend_string
Zend_string은 실제로 문자열을 저장하는 구조체입니다. 실제 내용은 val(char, 문자형)에 저장되며, val은 길이가 1인 char 배열입니다(멤버 변수 점유에 편리함). 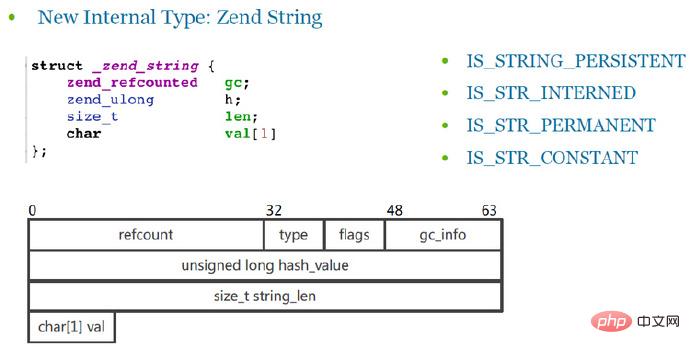
구조체의 마지막 멤버 변수는 char* 대신 char 배열을 사용합니다. 다음은 CPU의 캐시 누락을 줄일 수 있는 작은 최적화 트릭입니다.
char 배열을 사용하는 경우 위 구조의 메모리에 malloc을 적용할 때 동일한 영역에 적용되며, 일반적으로 길이는 sizeof(_zend_string) + 실제 char 저장 공간입니다. 그러나 char*를 사용하면 이 위치에 저장되는 것은 포인터일 뿐이고, 실제 저장되는 곳은 또 다른 독립된 메모리 영역이다.
char[1]과 char*를 사용한 메모리 할당 비교: 
로직 구현의 관점에서 보면 둘 사이에는 실제로 큰 차이가 없으며 효과도 매우 유사합니다. 실제로 이러한 메모리 블록이 CPU에 로드되면 매우 다르게 보입니다. 전자는 지속적으로 함께 할당된 동일한 메모리 조각이기 때문에 일반적으로 CPU가 읽을 때 함께 얻을 수 있습니다(같은 레벨 캐시에 있기 때문입니다). 후자는 두 메모리의 데이터를 포함하기 때문에 CPU가 첫 번째 메모리를 읽을 때 두 번째 메모리 데이터가 동일한 레벨 캐시에 없을 가능성이 높으므로 CPU는 L2(보조 캐시) 아래를 검색해야 합니다. 원하는 두 번째 메모리 데이터가 메모리 영역에서 발견되었습니다. 이로 인해 CPU Cache Miss가 발생하며 둘 사이의 시간 소모 차이는 최대 100배에 이를 수 있습니다.
또한 문자열을 복사할 때 참조 할당을 사용하면 zend_string은 메모리 복사를 피할 수 있습니다.
6. PHP 배열의 변경 사항(HashTable 및 Zend Array)
PHP 프로그램을 작성하는 과정에서 가장 많이 사용되는 유형은 배열이며, PHP5의 배열은 HashTable을 사용하여 구현됩니다. 대략적으로 요약하자면, 이중 연결 목록을 지원하는 HashTable입니다. 배열 키를 통해 요소에 액세스하는 해시 매핑을 지원할 뿐만 아니라 foreach를 통해 이중 연결 목록에 액세스하여 배열 요소를 순회할 수도 있습니다.
PHP5 HashTable(PPT의 스크린샷): 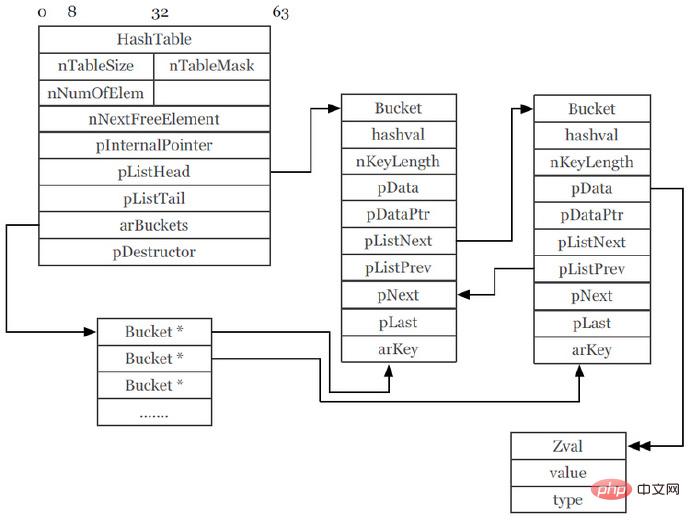
이 그림은 다양한 포인터가 뛰어다니는 등 매우 복잡해 보입니다. 키 값을 통해 요소의 콘텐츠에 액세스할 때 필요한 항목을 찾으려면 3번의 포인터 점프가 필요한 경우가 있습니다. 콘텐츠. 가장 중요한 점은 이러한 배열 요소의 저장이 서로 다른 메모리 영역에 분산되어 있다는 것입니다. 마찬가지로 CPU가 읽을 때 동일한 수준의 캐시에 있지 않을 가능성이 높기 때문에 CPU는 하위 수준의 캐시나 심지어 메모리 영역까지 검색해야 하므로 CPU 캐시 적중률이 감소하게 됩니다. 소비 시간이 늘어납니다.
PHP7용 Zend 배열(PPT 스크린샷): 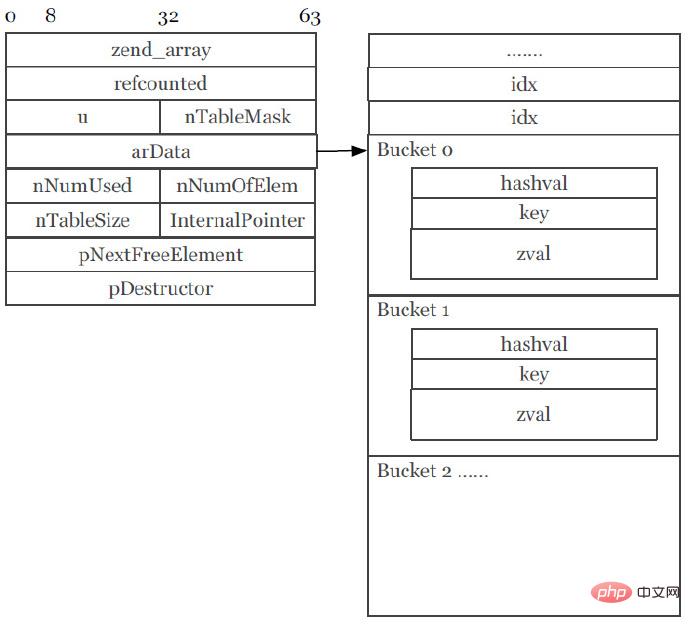
새 버전의 배열 구조는 매우 간단하고 눈길을 끕니다. 가장 큰 특징은 전체 배열 요소와 해시 매핑 테이블이 모두 함께 연결되어 동일한 메모리에 할당된다는 점입니다. 단순한 유형의 정수 배열을 순회하는 경우 배열 요소(Bucket) 자체가 동일한 메모리에 지속적으로 할당되고 배열 요소의 zval이 내부적으로 정수 요소를 저장하고 저장되므로 효율성이 매우 빠릅니다. 포인터 외부 링크도 있고 모든 데이터는 현재 메모리 영역에 저장됩니다. 물론 가장 중요한 것은 CPU Cache Miss(CPU 캐시 적중률 감소)를 방지할 수 있다는 점입니다.
Zend 배열 변경 사항:
(1) 배열 값의 기본값은 zval입니다.
(2) HashTable의 크기가 72바이트에서 56바이트로 22% 감소했습니다.
(3) 버킷 크기가 72바이트에서 32바이트로 50% 감소했습니다.
(4) 배열 요소 버킷의 메모리 공간은 함께 할당됩니다.
(5) 배열 요소(Bucket.key)의 키는 zend_string을 가리킵니다.
(6) 배열 요소의 값은 버킷에 포함됩니다.
(7) CPU 캐시 누락을 줄입니다.
7. 함수 호출 규칙
PHP7은 매개변수 전송 프로세스를 최적화하여 일부 명령을 줄이고 실행 효율성을 향상시킵니다.
PHP5의 함수 호출 메커니즘(PPT 스크린샷): 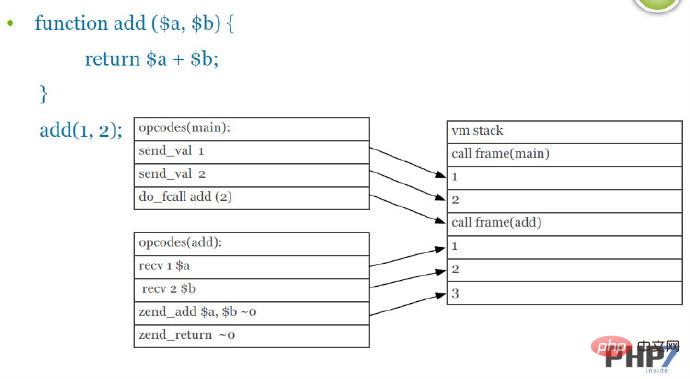
그림에서 vm 스택의 send_val 및 recv 매개변수 명령은 이 두 가지 중복을 줄여 함수 호출 메커니즘을 개선합니다. 레벨 최적화.
PHP7의 함수 호출 메커니즘(PPT의 스크린샷): 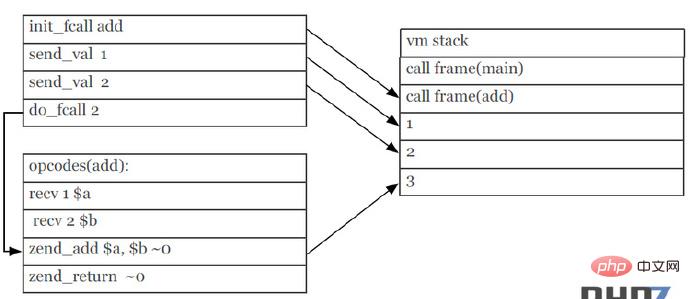
8. 매크로 정의 및 인라인 함수(인라인)를 통해 컴파일러는 작업의 일부를 미리 완료할 수 있습니다.
C 언어 매크로 정의는 전처리됩니다. 단계) 실행, 작업의 일부가 미리 완료되고 프로그램이 실행될 때 메모리를 할당할 필요가 없으며 함수와 유사한 기능을 달성할 수 있지만 함수 호출에 대한 스택 푸시 및 팝 오버헤드가 없으며 효율성이 높습니다. 상대적으로 높을 겁니다. 인라인 함수의 경우에도 마찬가지입니다. 전처리 단계에서는 프로그램의 함수가 함수 본문으로 대체됩니다. 여기서 실제 실행되는 프로그램이 실행되면 함수 호출에 따른 오버헤드가 발생하지 않습니다.
PHP7은 이 부분에서 많은 최적화를 했고, 실행 단계에서 수행해야 할 많은 작업을 컴파일 단계에 넣었습니다. 예를 들어, 매개변수 유형 판단(Parameters Parsing)은 관련된 모든 것이 고정된 문자 상수이기 때문에 컴파일 단계에서 완료될 수 있어 후속 실행 효율성이 향상됩니다.
예를 들어 전달되는 매개변수의 종류를 처리하는 방식은 왼쪽의 쓰기 방식부터 오른쪽의 매크로 쓰기 방식까지 최적화되어 있습니다.
3. 요약
Niao 형제의 PPT는 WordPress가 PHP5.6에서 100번 70억 번의 CPU 명령어 실행을 생성하는 반면, PHP7에서는 64.2로 줄어든 25억 번만 실행한다는 비교 데이터 세트를 공개했습니다. %, 충격적인 수치입니다.
Niao 형제의 전체 공유에서 저에게 준 가장 심오한 요점은 세부 사항에 주의를 기울이고 많은 작은 최적화를 계속해서 조금씩 축적하고 작은 양을 합산하여 마침내 놀라운 결과로 수렴된다는 것입니다. 하루에 9명이 산을 쌓는다는 것은 불가능한 일이 아닐까 싶습니다.
PHP7이 성능 면에서 비약적인 향상을 이루었다는 것은 의심할 여지가 없습니다. 이러한 결과를 PHP의 웹 시스템에 적용할 수 있다면 요청량이 많은 서비스를 지원하는 데 더 적은 수의 시스템만 필요할 것입니다. PHP7 공식 버전의 출시는 끝없는 기대로 가득 차 있습니다.
추천 튜토리얼: "php 비디오 튜토리얼"
위 내용은 PHP7의 혁신과 성능 최적화에 대해 알아보세요의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!