
집 >데이터 베이스 >MySQL 튜토리얼 >데이터베이스 최적화를 설명하는 예
데이터베이스 최적화를 설명하는 예

- angryTom앞으로
- 2019-11-27 13:36:022940검색
인터넷에서 데이터베이스 최적화를 검색하면 기본적으로 SQL 수준에서 최적화가 이루어지며 데이터베이스 자체의 인스턴스 최적화에 대해서는 거의 언급되지 않습니다. 있다고 하더라도 이는 모두 특정 데이터베이스의 인스턴스 최적화를 기반으로 합니다. 이 기사에서는 현재 시중에 나와 있는 모든 주류 데이터베이스(Oralce, MySQL, POSTGRES, Dameng)의 인스턴스 최적화를 다루고 있습니다. 위의 데이터베이스 성능의 80% 이상을 사용하십시오.

데이터베이스 최적화 방법론
이 부분은 이론적 지식이므로 관심이 없는 학생은 나중에 매개변수 구성 부분으로 바로 이동할 수 있습니다.
데이터베이스 최적화 목표
권장 "mysql 비디오 튜토리얼"
다양한 역할에 따라 데이터베이스 최적화는 다음 목표로 구분됩니다.
비즈니스 관점(주요 사용자):
사용자 페이지 응답 시간 단축
데이터베이스 관점(개발):
데이터베이스 SQL 응답 시간 단축
데이터베이스 서버 관점(운영 및 유지 관리):
데이터베이스 서버의 물리적 자원을 최대한 활용
데이터베이스 서버 CPU 사용량 감소
데이터베이스 서버 IO 사용량 감소
데이터베이스 서버 메모리 사용량 감소
지표
1. 최적화 전 : 평균 데이터베이스 응답 시간은 500ms
b입니다. 최적화 목표: 평균 데이터베이스 응답 시간은 200ms
2입니다. 최적화 전: 데이터베이스 피크 기간 CPU 사용량은 70%
입니다.b. 최적화 목표 : 데이터베이스 피크 기간 동안의 CPU 사용률은 50%
3. 데이터베이스 서버 IO 사용률이 낮아집니다
a. 최적화 전: 데이터베이스 IO WAIT는 30%
b입니다. 대상: 데이터베이스 IO WAIT가 10% 미만입니다
데이터베이스 최적화 오해데이터베이스를 최적화할 때 다음과 같은 오해가 있을 수 있습니다. 1 최적화하기 전에 데이터베이스의 내부 원리를 깊이 이해해야 합니다
최적화에는 "루틴"이 있습니다. 이 "루틴"을 따르세요. 데이터베이스 최적화도 아주 잘 완료될 수 있습니다
2. 데이터베이스 매개변수를 지속적으로 조정하면 궁극적으로 최적화를 달성할 수 있습니다
때때로 매개변수를 어떻게 조정하더라도 디자인이 비합리적일 수 있습니다. , 작동하지 않습니다
3. 운영 체제 매개변수를 지속적으로 조정하면 궁극적으로 최적화를 달성할 수 있습니다
위와 동일
4. 데이터베이스 성능은 애플리케이션 및 데이터베이스 아키텍처에 의해 결정되며 애플리케이션 개발과 거의 관련이 없습니다. 반대로 애플리케이션 개발과 관련이 많습니다
5. 읽기와 쓰기는 분리되어야 하고, 데이터베이스와 테이블은 분리되어야 합니다
데이터 크기가 일정 비율에 도달한 경우에만 읽기와 쓰기를 분리해야 하며, 그리고 별도의 테이블과 데이터베이스를 사용하면 복잡성만 증가합니다. 일반적으로 Oracle의 단일 테이블 크기는 1억에 도달할 수 있고, MySQL의 단일 테이블 크기는 1천만~2천만에 도달할 수 있습니다
데이터베이스 최적화 프로세스전체 데이터베이스 최적화 프로세스는 다음과 같습니다.
먼저 모두 최적화 문제를 최대한 이해하고 문제 기간 동안 시스템 정보를 수집하여 보관해야 합니다. 현재 시스템 문제 성능을 기반으로 최적화 목표를 개발하고 고객과 소통하여 목표에 대한 합의를 도출합니다. 일련의 도구를 통해 시스템 문제를 분석하고 최적화 계획을 수립합니다. 계획 검토가 완료되면 각 담당자가 이를 구현합니다. 최적화 목표가 달성되면 최적화 보고서가 작성되고, 그렇지 않으면 최적화 계획을 다시 작성해야 합니다.
데이터베이스 인스턴스 최적화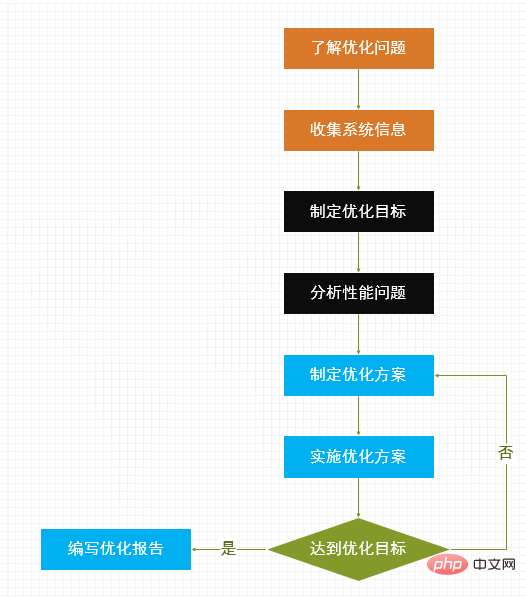
데이터베이스 인스턴스 최적화는 세 가지 원칙을 따릅니다.
로그는 작을 수 없고 캐시는 충분히 커야 하며 연결은 충분해야 합니다.데이터베이스 트랜잭션이 제출된 후에는 데이터의 내구성을 보장하기 위해 트랜잭션에 의한 데이터 페이지 수정 사항을 디스크에 플러시(fsync)해야 합니다. 이 디스크 플러시는 성능이 낮은 무작위 쓰기이므로 트랜잭션이 제출될 때마다 디스크를 플러시하면 데이터베이스 성능에 큰 영향을 미칩니다. 데이터베이스는 아키텍처 설계에서 다음 두 가지 최적화 방법을 채택합니다.
a. 먼저 로그 파일 RedoLog(WAL)에 트랜잭션을 쓰고, 무작위 쓰기를 순차 쓰기로 최적화합니다. b에 캐시 구조 레이어를 추가합니다. 쓰기가 순차 쓰기로 최적화될 때마다 변환
따라서 로그와 캐시는 데이터베이스 인스턴스에 특히 중요합니다. 연결 수가 충분하지 않으면 데이터베이스에서 직접 예외가 발생하고 시스템에 액세스할 수 없게 됩니다.
데이터베이스 매개변수 최적화
주요 데이터베이스 아키텍처에는 모두 다음과 같은 공통점이 있습니다.
데이터 캐시 SQL 구문 분석 영역 메모리 정렬REDO 및 UNDO
잠금, LATCH, MUTEX
수신 및 연결
파일 읽기 및 쓰기 성능
다음으로, 데이터베이스의 최상의 성능을 달성하기 위해 다양한 데이터베이스에 따라 매개변수를 조정합니다.ORACLE
| 매개변수 분류 | 매개변수 이름 | 매개변수 값 | Remarks |
|---|---|---|---|
| 데이터 캐시 | SGA_TAGET, MEMORY_TARGET | 물리적 메모리 70-80% | 클수록 좋습니다 |
| 데이터 캐시 | DB_CACHE_SIZE | 물리적 메모리 70~80% | 클수록 좋습니다 |
| SQL 구문 분석 | SHARED_POOL_SIZE | 4-16G | 너무 크게 설정하지 않는 것이 좋습니다 |
| 듣고 연결하기 | PROCESSES, SESSIONS, OPEN_CURSORS | 비즈니스 요구에 따라 설정 | 일반적으로 예상 비즈니스 연결 수의 120% |
| 기타 | SESSION_CACHED_CURSORS | 200개 이상 | 소프트 분석 |
MYSQL( INNODB )
| 매개변수 분류 | 매개변수 이름 | 매개변수 값 | Remarks |
|---|---|---|---|
| 데이터 캐시 | INNODB_BUFFER_POOL_SIZE | 물리적 메모리 5 0-80% | 일반적으로 말하면 클수록 좋습니다. 성능 |
| 로그 관련 | Innodb_log_buffer_size | 16-32M | 작동 조건에 따라 조정 |
| 로그 관련 | sync_binlog | 1, 100, 0 | 1 최고의 보안을 자랑합니다 |
| 모니터링 및 연결 | max_connections | 비즈니스 상황에 따라 상황 조정 | 값의 일부를 예약할 수 있습니다 |
| 파일 읽기 및 쓰기 성능 | innodb_flush_log_at_trx_commit | 2 | 보안 및 성능 저하 고려 사항 |
| 기타 | wait_timeout, Interactive_timeout | 28800 | 앱 연결 방지 예약된 인터럽트 |
POSGRES
| 매개변수 분류 | 매개변수 이름 | 매개변수 값 | 비고 |
|---|---|---|---|
| 데이터 캐시 | SHARED_BUFFERS | 물리적 메모리 10-25% |
|
| 데이터 캐시 | CACHE_BUFFER_SIZE | 물리적 메모리 50-60% | |
| 로그 관련 | wal_buffer | 8-64M | 아닙니다 너무 크게 설정하는 것이 좋습니다. 작게 |
| 모니터링 및 연결 NMax_connections | 비즈니스 상황에 따라 조정하세요. 일반적으로 비즈니스 연결 수의 120% | 기타 | |
| 512M 이상 |
Work_mem |
||
| 원래 구성 1M이 너무 작습니다 | Others | checkpoint_segments | |
|
Dameng 데이터베이스 |
매개변수 분류
매개변수 이름| Remarks | 데이터 캐시 | ||
|---|---|---|---|
| 데이터 캐시 |
BUFFER | ||
| 데이터 캐시 | 데이터 캐시 | MAX_BUFFER | |
| 최대 데이터 캐시 | 모니터링 및 연결 | max_sessions | |
| 일반적으로 120% 예상 비즈니스 연결 수 | 요약 |
이 기사는 PHP 중국어 웹사이트, mysql tutorial 칼럼에서 가져온 것입니다. 배우신 것을 환영합니다!
위 내용은 데이터베이스 최적화를 설명하는 예의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!