
JavaScript_Basic 지식으로 DOM 노드에 접근, 생성, 수정, 삭제

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWB원래의
- 2016-05-16 15:32:111666검색
돔
DOM은 Document Object Model의 약자입니다. 문서 객체 모델은 XML이나 HTML을 트리 노드 형태로 표현한 문서이다. DOM 메서드와 속성을 사용하면 페이지의 모든 요소에 액세스하고 수정하고 삭제할 수 있으며 요소를 추가할 수도 있습니다. DOM은 Javascript를 포함한 모든 언어로 구현될 수 있는 언어 독립적인 API입니다
아래 텍스트 중 하나를 살펴보십시오.
<!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Strict//EN" "http://www.w3.org/TR/xhtml1/DTD/xhtml1-strict.dtd"> <html> <head> <title>My page</title> </head> <body> <p class="opener">first paragraph</p> <p><em>second</em> paragraph</p> <p id="closer">final</p> </body> </html>
두 번째 문단을 살펴보겠습니다
<p><em>second</em> paragraph</p>
P태그임을 알 수 있습니다. body 태그에 포함되어 있습니다. 따라서 body는 p의 부모 노드이고 p는 자식 노드입니다. 첫 번째와 세 번째 단락도 본문의 하위 노드입니다. 이들은 모두 두 번째 단락의 형제 노드입니다. 이 em 태그는 두 번째 세그먼트 p의 하위 노드입니다. 따라서 p는 상위 노드입니다. 부모-자식 노드 관계는 나무와 같은 관계를 묘사할 수 있습니다. 그래서 DOM 트리라고 부릅니다.
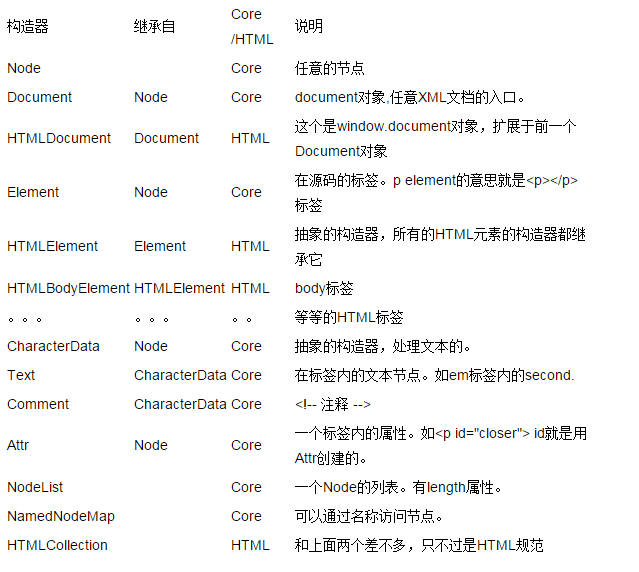
핵심 DOM과 HTML DOM
우리는 DOM이 HTML 및 XML 문서를 묘사할 수 있다는 것을 이미 알고 있습니다. 실제로 HTML 문서는 XML 문서이지만 더 표준화되어 있습니다. 따라서 DOM 레벨 1의 일부로 Core DOM 사양은 모든 XML 문서에 적용되고 HTML DOM 사양은 Core DOM을 확장합니다. 물론 HTML DOM은 HTML 문서에만 적용됩니다. Core DOM과 HTML DOM의 생성자를 살펴보겠습니다.
시공자 관계
DOM 노드 액세스
양식의 유효성을 검사하거나 이미지를 변경하기 전에 요소(element.)에 액세스하는 방법을 알아야 합니다. 요소를 얻는 방법에는 여러 가지가 있습니다.
문서 노드
문서를 통해 현재 문서에 접근할 수 있습니다. Firebug(Firefox 플러그인)를 사용하여 문서의 속성과 메서드를 볼 수 있습니다.
모든 노드에는 nodeType, nodeName, nodeValue 속성이 있습니다. 문서의 nodeType을 살펴보겠습니다
document.nodeType;//9
총 12가지 노드 유형이 있습니다. 문서는 9입니다. 일반적으로 사용되는 것은 요소(element: 1), 속성(attribute: 2), 텍스트(text: 3)입니다.
노드에도 이름이 있습니다. HTML 태그의 경우. 노드 이름은 레이블 이름입니다. 텍스트 노드(text)의 이름은 #text입니다. 문서 노드(document)의 이름은 #document입니다.
노드에도 값이 있습니다. 텍스트 노드의 경우 값은 텍스트입니다. 문서 값이 null입니다
문서 요소
XML에는 문서를 래핑하기 위한 ROOT 노드가 있습니다. HTML 문서의 경우. ROOT 노드는 html 태그입니다. 루트 노드에 액세스합니다. documentElement의 속성을 사용할 수 있습니다.
document.documentElement;//<html> document.documentElement.nodeType;//1 document.documentElement.nodeName;//HTML document.documentElement.tagName;//对于element,nodeName和tagName相同
하위 노드
하위 노드가 포함되어 있는지 확인하려면 다음 방법을 사용할 수 있습니다
document.documentElement.hasChildNodes();//true
HTML에는 두 개의 하위 노드가 있습니다.
document.documentElement.childNodes.length;//2 document.documentElement.childNodes[0];//<head> document.documentElement.childNodes[1];//<body>
자식 노드를 통해서도 부모 노드에 접근할 수 있습니다
document.documentElement.childNodes[1].parentNode;//<html>
body 참조를 변수
에 할당합니다.var bd = document.documentElement.childNodes[1]; bd.childNodes.length;//9
신체의 구조를 살펴보겠습니다
<body> <p class="opener">first paragraph</p> <p><em>second</em> paragraph</p> <p id="closer">final</p> <!-- and that's about it --> </body>
하위 노드 수가 9개인 이유는 무엇입니까?
먼저 P 4개와 코멘트 총 4개가 있습니다.
4개의 노드에는 3개의 빈 노드가 포함됩니다. 7이에요.
본문과 첫 번째 p 사이의 8번째 공백 노드입니다.
아홉 번째는 주석과