
Python 크롤러 기술은 무엇을 할 수 있나요?

- silencement원래의
- 2019-06-25 13:51:343811검색
먼저 크롤러가 무엇인지 알아야 합니다! 크롤러라는 단어를 처음 들었을 때는 기어다니는 벌레인 줄 알았어요.

웹 크롤러(웹 스파이더, 웹 로봇으로도 알려짐, FOAF 커뮤니티에서는 웹 체이서라고도 함)는 특정 규칙에 따라 World Wide Web의 정보를 자동으로 크롤링하는 프로그램입니다. 또는 스크립트. 덜 일반적으로 사용되는 다른 이름으로는 개미, 자동 인덱서, 에뮬레이터 또는 웜이 있습니다.
크롤러는 무엇을 할 수 있나요?
브라우저를 시뮬레이트하여 웹 페이지를 열고 웹 페이지에서 원하는 데이터 부분을 가져옵니다.
기술적인 관점에서 본 프로그램은 사이트를 요청하는 브라우저의 동작을 시뮬레이션하고 사이트에서 반환된 HTML 코드/JSON 데이터/바이너리 데이터(사진, 비디오)를 로컬로 크롤링한 다음 필요한 데이터를 추출하고 사용하기 위해 저장합니다.
자세히 관찰해 보면, 점점 더 많은 사람들이 크롤러를 이해하고 배우고 있는 것을 발견할 수 있습니다. 한편으로는 프로그래밍 언어를 통해 점점 더 많은 데이터를 얻을 수 있습니다. Python과 같이 우수한 도구가 많을수록 크롤러를 사용하는 것이 더 쉬워집니다.
크롤러를 사용하면 많은 양의 귀중한 데이터를 얻을 수 있으며 이를 통해 다음과 같은 지각 지식을 통해 얻을 수 없는 정보를 얻을 수 있습니다.
Zhihu: 고품질 답변을 크롤링하고 각 주제에 대한 최고의 콘텐츠를 가려냅니다.
Taobao, JD.com: 제품, 댓글, 판매 데이터를 수집하고 다양한 제품과 사용자 소비 시나리오를 분석합니다.
Anjuke 및 Lianjia: 부동산 매매 및 임대 정보를 캡처하고, 주택 가격 동향을 분석하고, 다양한 지역의 주택 가격 분석을 수행합니다.
Lagou.com 및 Zhaopin: 다양한 직업 정보를 크롤링하고 다양한 업계의 인재 수요와 급여 수준을 분석합니다.
Snowball Network: Snowball 고수익 사용자의 행동을 포착하고 주식 시장을 분석 및 예측하는 등
크롤러의 원리는 무엇인가요? G 요청 보내기 & gt; 콘텐츠 분석 & gt; 데이터 저장
데이터를 크롤링할 때 이 프로세스가 간단합니까? 따라서 사용자가 보는 브라우저 결과는 HTML 코드로 구성되어 있습니다. 우리 크롤러는 HTML 코드를 분석하고 필터링하여 원하는 리소스를 얻는 것입니다. 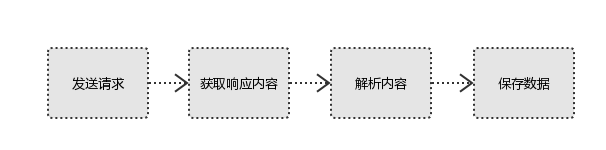
위 내용은 Python 크롤러 기술은 무엇을 할 수 있나요?의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!