



일반적인 엑셀 기능 요약
첫 번째 범주: 텍스트 처리 기능#🎜 🎜 #
● 다듬기 기능: 기능: 단어 사이의 단일 공백을 제외하고 텍스트에서 모든 공백을 제거합니다. Syntax: TRIM(text), Text는 필수이며 공백을 제거하기 위한 텍스트입니다. ● 연결 기능: 기능: 두 개 이상의 텍스트 문자열을 하나의 문자열로 연결합니다. 구문: CONCATENATE(text1, [text2], ...), 최소 1개 항목 포함, 최대 255개 항목, 최대 8192자 지원, 항목은 텍스트 값, 숫자, 또는 셀 견적. 설명: 커넥터를 사용하여 동일한 기능을 달성할 수 있습니다. ● 바꾸기 기능: 함수: 특정 위치의 문자열을 다른 텍스트 문자로 바꿉니다. 구문: REPLACE(old_text, start_num, num_chars, new_text), old_text는 바꿔야 할 텍스트이고, start_num은 문자 위치를 바꾸고, num_chars는 new_text로 대체된 문자 수를 사용하고, new_text는 대체됩니다. old_text의 새 텍스트. ● 대체 함수: 함수: 특정 텍스트 문자열에서 지정된 텍스트를 대체 의 차이점 바꾸기: 대체는 텍스트 내용을 기반으로 합니다. 바꾸기, 바꾸기는 위치에 따라 문자를 바꿉니다. 구문: SUBSTITUTE(text, old_text, new_text, [instance_num]), text는 바꿔야 하는 텍스트를 포함하고, old_text는 바꿔야 하는 텍스트, new_text는 old_text를 바꾸는 텍스트입니다. , instance_num은 선택적 매개변수입니다. 숫자가 지정되면 해당 시퀀스의 old_text만 교체되고, 그렇지 않으면 모두 교체됩니다. ● 왼쪽 함수: 함수: 텍스트 문자열의 첫 번째 문자부터 시작하여 지정된 수의 문자를 반환합니다. LEFT(text, [num_chars]), text에는 추출할 문자가 포함되어 있으며, num_chars는 추출할 지정된 숫자이며 ≥ 0이어야 합니다. 텍스트 길이보다 큰 경우 , 전체 텍스트가 반환됩니다. 생략하면 해당 값이 1이라고 가정합니다. ● 오른쪽 기능: 오른쪽부터 시작하여 숫자를 취하는 방향이 반대라는 점을 제외하면 사용법은 Left와 동일합니다. ● Mid 기능: Function: 지정된 위치부터 특정 개수의 문자 추출 Syntax: MID(text, start_num, num_chars ), text에는 추출할 문자가 포함되며, start_num은 추출할 텍스트의 첫 번째 문자 위치, num_chars는 추출할 것으로 예상되는 문자 수입니다.관련글 추천
: 1.모든 수식의 엑셀 함수 요약
2. excel 금융 함수
3.excel 통계 함수
4.excel 문자열 함수
# 🎜🎜#
두 번째 범주: 정보 피드백 기능
● 정확한 기능:
기능: 두 가지 비교 텍스트 문자열이 동일하면 TRUE를 반환하고, 그렇지 않으면 FALSE를 반환합니다. EXACT 함수는 대소문자를 구분하지만 형식 차이를 무시합니다. 문서에 입력된 텍스트를 확인하려면 EXACT를 사용하세요.
구문: EXACT(text1, text2), text1 및 text2는 비교해야 하는 두 문자열입니다.
● Len 함수:
Function: 텍스트의 문자 수를 반환하며 일반적으로 다른 함수와 함께 사용됩니다.
구문: LEN(text), text는 길이를 쿼리해야 하는 텍스트이며 공백은 문자로 계산됩니다.
● IS 함수:
함수: 이 유형의 함수는 지정된 값을 확인하고 결과에 따라 TRUE 또는 FALSE를 반환할 수 있습니다. IS 함수를 사용하면 값에 대해 계산을 수행하거나 다른 작업을 수행하기 전에 값에 대한 정보를 얻을 수 있습니다.
문법: ISBLANK(값), ISERR(값), ISERROR(값), ISLOGICAL(값), ISNA(값), ISNONTEXT(값), ISNUMBER(값), ISREF(값), ISTEXT(값). value는 테스트할 값을 나타냅니다. 값 매개변수는 공백(빈 셀), 오류 값, 논리값, 텍스트, 숫자, 참조 값 또는 위의 테스트할 값을 참조하는 이름일 수 있습니다.
Category 3: 참조 함수 찾기
● Vlookup 기능:
Function: 표 영역 라인 누르기 해당 콘텐츠를 찾으세요.
구문: VLOOKUP(찾을 값, 값을 찾을 범위, 반환 값이 포함된 범위의 열 번호, 정확한 일치 또는 대략 일치 – 0/FALSE 또는 1/TRUE로 지정) .
참고: 찾으려는 값은 항상 범위의 첫 번째 열에 있어야 합니다
● Hlookup 기능:
기능: 누르기 해당 내용을 찾으려면 테이블 열을 사용하세요.
구문: HLOOKUP(lookup_value, table_array, row_index_num, [range_lookup]), 매개변수는 VLOOKUP에 해당하고, 세 번째 매개변수는 행 번호, VLOOKUP의 세 번째 매개변수는 열 번호입니다.
● 인덱스 함수:
함수: 테이블이나 범위의 값 또는 값 참조를 반환합니다.
구문: INDEX(array, row_num, [ column_num]), 배열 셀 범위 또는 배열 상수, row_num은 배열의 행이고, column_num은 배열의 열입니다. 또한, 인용 양식도 있습니다. 관심이 있는 경우 Baidu를 사용하거나 Microsoft 도움말을 사용할 수 있습니다.
참고: row_num 및 column_num 매개변수를 사용하면 INDEX 함수는 행 번호와 열 번호가 교차하는 셀의 값을 반환하고, row_num을 0으로 설정하면 전체 열 값의 값을 반환합니다. , 이는 열에도 적용됩니다. 배열 수식을 입력하려면 수식을 입력한 후 Ctrl + Shift + Enter를 눌러야 합니다.
● 일치 기능:
기능: 범위 셀에서 특정 항목을 검색한 다음 이 영역에서 항목의 상대적 위치를 반환합니다.
Syntax: MATCH(lookup_value,lookup_array, [match_type]),lookup_value에서 찾을 값,lookup_arrary 셀 범위,match_type=1 또는 생략,최대값 찾기 ≤lookup_value,lookup_array에 필요 =0이면 lookup_value와 정확히 동일한 첫 번째 값을 검색합니다. =-1이면 최소값 ≥ lookup_value를 검색하고, lookup_array를 내림차순으로 정렬해야 합니다.
참고: MATCH는 대문자와 소문자를 구분하지 않습니다. Lookup_value와 함께 사용할 수 있나요? 또는*,? 모든 단일 문자와 일치하고, *는 모든 문자열과 일치합니다. 실제 물음표나 별표를 찾으려면 문자 앞에 ~를 추가해야 합니다.
● 검색 기능:
기능: 이 함수는 두 번째 텍스트 문자열에서 첫 번째 텍스트 문자열을 찾아 첫 번째 텍스트 문자열의 시작점을 반환할 수 있습니다. 두 번째 텍스트 문자열의 첫 번째 문자부터 시작됩니다.
구문: SEARCH(find_text,within_text,[start_num]), find_text는 찾을 텍스트이고, with_text는 찾을 텍스트를 포함하며, start_num은 검색을 시작할 문자 번호입니다.
참고: SEARCH는 대소문자를 구분하지 않으며 FIND 함수는 대소문자를 구분합니다. SEARCH는 와일드카드 사용을 지원합니까? 및 *는 FIND가 지원하지 않습니다.
● 찾기 기능:
FIND 기능은 대소문자를 구분하며 와일드카드를 사용할 수 없습니다. 다른 사용법은 SEARCH 기능과 동일합니다.
● 기능 선택:
Function: 매개변수를 기반으로 숫자 매개변수 목록의 값을 반환합니다.
구문: CHOOSE(index_num, value1, [value2], ...), index_num은 1에서 254 사이의 선택된 숫자 매개변수를 나타냅니다. index_num이 1이면 value1이 반환되고 2이면 Value1이 반환됩니다. 반환 값2...
예: SUM(CHOOSE(2,A1:A10,B1:B10,C1:C10))=SUM(B1:B10)
● 행/열 함수:
ROW([참조])는 참조된 행 번호를 반환하고, COLUMN([참조])는 참조된 열 번호를 반환하며, 참조가 생략된 경우 함수가 있는 행을 반환합니다. /열 번호.
● 오프셋 함수:
함수: 셀 또는 셀 범위에서 지정된 행과 열 수의 범위에 대한 참조를 반환합니다.
구문: OFFSET(reference,rows,cols,[height],[width]), reference는 오프셋의 기준 위치, 행별 오프셋 행 수, 오프셋 열 수 열, 높이 및 너비로 반환된 행 높이와 열 너비를 지정합니다.
참고: 참조 위치는 워크시트의 가장자리를 초과할 수 없습니다. 높이와 너비가 생략된 경우 높이와 너비는 참조와 동일합니다.
● 간접 함수:
함수: 텍스트 문자열로 지정된 참조를 반환합니다.
구문: INDIRECT(ref_text, [a1]), ref_text 쌍 셀에 대한 참조입니다. 참조가 다른 통합 문서에 대한 것이라면 참조된 통합 문서가 열려 있어야 합니다. a1이 true이거나 생략되면 A1 스타일이고, 그렇지 않으면 R1C1 스타일입니다.
● 주소 함수:
Function: 지정된 행 번호와 열 번호를 기반으로 워크시트의 셀 주소를 가져옵니다(예: ADDRESS(2,3) 반환). $C$2.
구문: ADDRESS(row_num, column_num, [abs_num], [a1], [sheet_text]), row_num은 행 번호, column_num은 열 번호, abs_num은 반환된 참조를 지정하는 데 사용할 수 있습니다. 유형, = 1 또는 생략은 절대값을 반환하고, =2는 절대 행 번호와 상대 열 번호를 반환하고, =3은 상대 행 번호와 절대 열 번호를 반환합니다. a1의 사용은 INDIRECT 함수의 매개변수 소개와 동일합니다. sheet_text는 외부에서 참조되는 워크시트의 이름을 지정하는 데 사용됩니다.
카테고리 4: 논리연산 함수
● If 함수:
함수: 값과 기대값 쌍 수행 논리 비교
구문: IF(logical_test, value_if_true, [value_if_false]), logic_test가 성립하면 value_if_true를 반환하고, logic_test가 성립되지 않으면 value_if_false를 반환합니다. IF 함수는 최대 64번까지 중첩될 수 있습니다.
● Iferror 함수:
Function: 수식의 계산 결과가 틀리면 지정한 값을 반환하고, 그렇지 않으면 수식의 결과를 반환합니다. IFERROR 함수를 사용하여 수식의 오류를 포착하고 처리합니다.
Syntax: IFERROR(value, value_if_error), value는 확인할 값, value_if_error는 value가 오류일 때 반환되는 값, 오류 유형은 다음과 같습니다: #N/A, #VALUE!, # REF !, #DIV/0!, #NUM!, #NAME? 또는 #NULL!.
● Ifna 함수:
Function: 수식이 오류 값 #N/A를 반환하면 결과는 사용자가 지정한 값을 반환합니다. 그렇지 않으면 수식의 결과는 다음과 같습니다. 돌아왔다.
구문: IFNA(value, value_if_na), 확인된 오류 값 범위가 다르다는 점을 제외하면 IFERROR와 구문은 동일합니다.
● 그리고 기능:
은 테스트의 모든 조건이 TRUE인지 확인하는 데 사용됩니다.
● 또는 함수:
은 테스트의 조건이 TRUE인지 확인하는 데 사용됩니다.
● 기능 없음:
매개변수의 논리적 부정.
다섯 번째 카테고리: 수학적 통계 함수
● 합계 함수:
기능: 단일 값을 결합할 수 있습니다. , 셀 참조가 추가되거나 범위가 추가되거나 세 가지의 조합이 추가됩니다.
구문: SUM(숫자1,[숫자2],...)
● Sumif 함수:
기능: 조건에 맞는 값을 합산합니다. 예를 들어 B2~B25 셀에서 5보다 큰 값을 합산하려면 =SUMIF(B2:B25,">5")
수식을 사용하면 됩니다.구문: SUMIF(범위, 기준,[합_범위]), 범위는 계산할 영역이고 문자 수는 255자를 초과할 수 없습니다. 기준 합계 조건에 와일드카드를 사용할 수 있나요? * sun_range는 실제 합산 영역을 지정하는 선택적 조건입니다.
동영상: Microsoft SUMIF 함수 교육 과정
● Sumifs 함수:
함수: 여러 조건을 충족하는 모든 매개변수의 총량을 계산하는 데 사용됩니다.
구문: SUMIFS(sum_range, 기준_범위1, 기준1, [criteria_range2, 기준2], ...), sum_range에는 합산된 영역이 필요하고, 기준_범위1은 조건 영역 1이고, 기준1은 영역 1을 제한하는 조건 1이며, 다음 매개변수 등.
● Sumproduct 함수:
함수: 주어진 배열 세트에서 배열 사이의 해당 요소를 곱하고 곱의 합계를 반환합니다.
구문: SUMPRODUCT(array1, [array2], [array3], ...), array1 / array2...는 해당 요소를 곱하고 합하는 여러 배열 매개변수 세트입니다. 배열 매개변수는 동일한 차원을 가져야 합니다. , 숫자가 아닌 배열 요소는 0으로 처리됩니다.
● 카운트 기능:
기능: 숫자가 포함된 셀의 개수와 매개변수 목록에 있는 숫자의 개수를 셉니다.
구문: COUNT(value1, [value2], ...), value1은 숫자 수를 계산하는 첫 번째 항목, 셀 응용 프로그램 또는 영역이며, value2는 선택적 매개 변수이며 value1과 동일한 기능을 갖습니다.
참고: 숫자, 날짜, 숫자를 나타내는 텍스트(예: "1"), 논리값 및 매개변수 목록에 직접 입력한 숫자인 매개변수가 계산됩니다.
● Countif 함수:
함수: 특정 조건을 만족하는 셀의 개수를 세는 데 사용
문법: COUNTIF(범위, 기준), SUMIF와 유사 기본 사용법
● Countifs 함수:
함수: 결합 조건은 여러 범위의 셀에 적용되고 모든 조건이 충족되는 횟수를 계산합니다.
구문: COUNTIFS(criteria_range1, 기준1, [criteria_range2, 기준2],…), 기준_범위1은 조건 영역 1이고, 기준1은 기준_범위1에 대해 지정된 제한 조건 1입니다.
● 카운트 기능:
기능: 비어 있지 않은 셀의 개수를 셉니다.
구문: COUNTA(value1, [value2], ...), value1은 계산할 영역을 나타내고 value2는 선택적 매개 변수이며 해당 기능은 value1과 동일합니다.
● Countblank 기능:
COUNTBLANK(range)는 선택한 범위에서 빈 셀의 개수를 셉니다.
● 최대/최소 기능:
MAX(number1, [number2], ...), MIN(number1, [number2], ...) 선택한 영역의 최대값과 최소값을 계산합니다.
● 순위 함수:
함수: 숫자 열의 숫자 순위를 반환합니다. 숫자 순위는 목록의 다른 값과 관련된 크기입니다.
구문: RANK(number,ref,[order]), number는 순위가 지정되어야 합니다. ref는 숫자 배열의 선택적 매개변수입니다. =0이거나 내림차순을 생략합니다. =는 0이 아니며 오름차순입니다.
● 랜드 함수:
함수: 0보다 크거나 같고 1보다 작은 균일하게 분포된 임의의 실수를 반환합니다. 워크시트가 계산될 때마다 새로운 임의의 실수가 반환됩니다.
구문: RAND(), a와 b 사이의 임의의 실수를 생성하려면 공식 RAND()*(b-a)+a를 사용할 수 있습니다.
● Randbetween 함수:
함수: 사이의 값을 반환합니다. 두 개의 지정된 숫자 임의의 정수. 워크시트가 계산될 때마다 새로운 임의의 정수가 반환됩니다.
구문: RANDBETWEEN(bottom, top), Bottom은 가장 작은 정수를 반환하고, Top은 가장 큰 정수를 반환합니다. 예를 들어 RANDBETWEEN(1,100)=RAND()*99+1은 1-100 사이의 임의의 숫자를 반환합니다.
● 평균 함수:
함수: 매개변수의 평균값(산술 평균)을 반환합니다.
구문: AVERAGE(숫자1, [숫자2], ...), 숫자1은 평균 면적, 숫자2는 선택적 매개변수이며 해당 기능은 숫자1과 동일합니다.
● 소계 함수:
함수: 목록이나 데이터베이스의 소계를 반환합니다.
구문: SUBTOTAL(function_num,ref1,[ref2],...), function_num은 부분합에 사용할 함수를 지정하는 데 사용되는 숫자 1-11 또는 101-111입니다. 1-11을 사용하면 수동으로 숨겨진 행이 포함되고, 101-111을 사용하면 수동으로 숨겨진 행이 제외되고 필터링된 셀은 항상 제외됩니다.
카테고리 6: 날짜 및 시간 함수
● Datedif 함수:
함수: 나이 계산 공식에 자주 사용되는 두 날짜 사이의 연, 월, 일 수를 계산합니다.
구문: DATEDIF(start_date,end_date,unit), start_date는 시작 날짜를 나타내고, end_date는 종료 날짜를 나타냅니다. 날짜 값은 인용된 텍스트 문자열(예: "2001/1/30"), 일련 번호(예: 36921, 상용 1900 날짜 시스템을 사용할 때 2001년 1월 30일을 의미) 등 다양한 방법으로 입력할 수 있습니다. , 또는 기타 수식 또는 함수의 결과(예: DATEVALUE("2001/1/30")).
설명: 날짜는 계산에 사용할 수 있는 일련 번호로 저장됩니다. 기본적으로 1899년 12월 31일의 일련번호는 1이고, 2008년 1월 1일의 일련번호는 1900년 1월 1일부터 39448일이므로 39448입니다.
● Networkdays 함수:
NETWORKDAYS(start_date, end_date, [holidays])는 두 날짜 사이의 영업일 수를 반환합니다.
● 현재 기능:
함수: 현재 날짜와 시간을 반환하며, 워크시트를 열 때마다 시간이 업데이트됩니다.
구문: NOW(), 매개변수 없음.
지침: 1.Excel에서는 계산에 사용할 수 있도록 날짜를 일련 번호로 저장할 수 있습니다. 기본적으로 1900년 1월 1일은 일련번호가 1이고, 2008년 1월 1일은 1900년 1월 1일로부터 39,447일 전이므로 일련번호는 39,448입니다. 2. 일련번호 소수점 오른쪽의 숫자는 시간, 왼쪽의 숫자는 날짜를 나타냅니다. 예를 들어, 시퀀스 번호 0.5는 시간이 정오 12시임을 나타냅니다. 3.NOW 함수의 결과는 워크시트를 계산하거나 함수가 포함된 매크로를 실행할 때만 변경됩니다.
● 오늘 기능:
기능: 현재 날짜 반환, 통합 문서를 열 때 날짜 자동 업데이트, 나이 계산 등에 자주 사용됩니다.
구문: TODAY(), 매개변수 없음.
● Weekday 함수:
Function: 해당 요일을 반환
Syntax: WEEKDAY(serial_number,[return_type]), Serial_number A 조회가 시도된 날짜를 나타내는 일련 번호입니다. 날짜는 DATE 함수를 사용하거나 다른 수식이나 함수의 결과로 입력해야 합니다. 예를 들어, DATE(2008,5,23) 함수를 사용하여 2008년 5월 23일을 입력합니다. Return_type 선택적 매개변수, 반환 값 유형을 결정하는 데 사용되는 숫자입니다.
● Weeknum 함수:
Function: 해당 날짜의 주 번호를 반환합니다.
Syntax: WEEKNUM(serial_number,[return_type]), Serial_number는 다음과 같습니다. 필수의. 요일을 나타냅니다. 날짜는 DATE 함수를 사용하거나 다른 수식이나 함수의 결과로 입력해야 합니다. 예를 들어, DATE(2008,5,23) 함수를 사용하여 2008년 5월 23일을 입력합니다. Return_type 선택적 매개변수는 주가 시작되는 날짜를 결정합니다. 기본값은 1입니다.
● 날짜 함수:
함수: 세 개의 독립적인 값을 하나의 날짜로 결합
구문: DATE(년,월,일) , 연, 월, 일
● 연/월/일 기능:
매개변수는 날짜이며 각각 연, 월, 일 정보를 얻을 수 있습니다.
● 시/분/초 기능:
매개변수는 시간이며 각각 시, 분, 초를 얻을 수 있습니다.
● 시간 함수:
DATE 함수와 유사하게 세 개의 독립적인 값을 하나의 시간으로 결합합니다.
카테고리 7: 형식 표시 기능
● 텍스트 기능:
기능: 지정된 방식으로 숫자 변경 표시는 특정 형식으로 값을 표시해야 하는 텍스트 값 병합과 같은 다른 기능과 함께 사용되는 경우가 많습니다. 이 경우 TEXT 기능을 사용할 수 있습니다.
구문: TEXT(서식을 지정하려는 값, "적용하려는 코드 서식 지정")
● 상위/하위 기능:
UPPER (text)와 LOWER(text)는 각각 대문자와 소문자로 텍스트를 출력할 수 있습니다.
● 적합한 기능:
텍스트 문자열의 첫 글자를 대문자로, 나머지 글자를 소문자로 변환합니다.
● Roud 함수:
함수: 숫자를 지정된 자릿수로 반올림합니다.
구문: ROUND(number, num_digits), number는 반올림할 숫자, num_digits는 반올림할 자릿수, >0은 지정된 소수 자릿수로 반올림되며, =0은 가장 가까운 정수로 반올림되고
● Roudup 함수:
RANDUP 구문은 숫자가 반올림 대신 반올림된다는 점을 제외하면 RAND와 동일합니다.
● Rouddown 함수:
RANDDOWN 구문은 숫자가 반올림 대신 반내림된다는 점을 제외하면 RAND와 동일합니다.
● Rept 기능:
기능: 텍스트를 지정된 횟수만큼 반복합니다. 일반적으로 셀의 텍스트 문자열을 채우는 데 사용됩니다.
구문: REPT(text, number_times), 텍스트를 반복해서 표시해야 하고, number_times를 횟수만큼 반복해야 합니다.
● 고정 기능:
기능: 마침표와 쉼표를 사용하여 숫자를 지정된 소수 자릿수로 반올림하고, 숫자를 소수 형식으로 지정하고, 결과를 반환합니다. 텍스트로.
구문: FIXED(number, [decimals], [no_commas]), 숫자는 반올림하여 이 글의 숫자로 변환해야 하며, 소수(선택 사항) 소수점 이하 자릿수 , no_commas(선택 사항) 논리 값 TRUE이면 FIXED에서 반환된 텍스트에 쉼표가 포함되지 않습니다.
소수점이 음수인 경우 해당 자릿수만큼 소수점 왼쪽으로 반올림됩니다.
소수점을 생략하면 그 값은 2로 간주됩니다.
더 많은 Excel 관련 튜토리얼을 보려면 Excel 기본 튜토리얼 컬럼을 방문하세요!
위 내용은 엑셀에서 자주 사용하는 함수 요약의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!

 Excel의 중간 공식 - 실제 예Apr 11, 2025 pm 12:08 PM
Excel의 중간 공식 - 실제 예Apr 11, 2025 pm 12:08 PM이 튜토리얼은 중간 기능을 사용하여 Excel에서 수치 데이터의 중앙값을 계산하는 방법을 설명합니다. 중앙 경향의 주요 척도 인 중앙값은 데이터 세트의 중간 값을 식별하여 Central Tenden의보다 강력한 표현을 제공합니다.
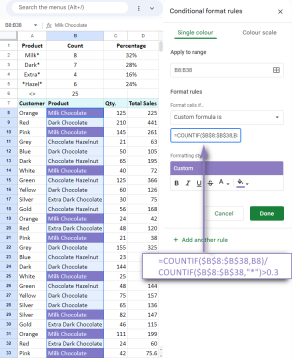 Google 스프레드 시트 Countif 기능은 공식 예제와 함께합니다Apr 11, 2025 pm 12:03 PM
Google 스프레드 시트 Countif 기능은 공식 예제와 함께합니다Apr 11, 2025 pm 12:03 PM마스터 Google Sheets Countif : 포괄적 인 가이드 이 안내서는 Google 시트의 다목적 카운티프 기능을 탐색하여 간단한 셀 카운팅 이외의 응용 프로그램을 보여줍니다. 우리는 정확하고 부분적인 경기에서 Han에 이르기까지 다양한 시나리오를 다룰 것입니다.
 Excel 공유 통합 문서 : 여러 사용자를위한 Excel 파일을 공유하는 방법Apr 11, 2025 am 11:58 AM
Excel 공유 통합 문서 : 여러 사용자를위한 Excel 파일을 공유하는 방법Apr 11, 2025 am 11:58 AM이 튜토리얼은 다양한 방법, 액세스 제어 및 갈등 해결을 다루는 Excel 통합 문서 공유에 대한 포괄적 인 안내서를 제공합니다. Modern Excel 버전 (2010, 2013, 2016 및 이후) 협업 편집을 단순화하여 M에 대한 필요성을 제거합니다.
 Excel을 JPG로 변환하는 방법 - 이미지 파일로 .xls 또는 .xlsx를 저장Apr 11, 2025 am 11:31 AM
Excel을 JPG로 변환하는 방법 - 이미지 파일로 .xls 또는 .xlsx를 저장Apr 11, 2025 am 11:31 AM이 자습서는 .xls 파일을 .jpg 이미지로 변환하는 다양한 방법을 탐색하여 내장 된 Windows 도구와 무료 온라인 변환기를 모두 포함합니다. 프레젠테이션을 만들거나 스프레드 시트 데이터를 단단히 공유하거나 문서를 디자인해야합니까? YO를 변환합니다
 Excel 이름 및 명명 범위 : 공식에서 정의 및 사용 방법Apr 11, 2025 am 11:13 AM
Excel 이름 및 명명 범위 : 공식에서 정의 및 사용 방법Apr 11, 2025 am 11:13 AM이 튜토리얼은 Excel 이름의 기능을 명확히하고 셀, 범위, 상수 또는 공식의 이름을 정의하는 방법을 보여줍니다. 또한 정의 된 이름을 편집, 필터링 및 삭제하는 것도 다룹니다. Excel 이름은 엄청나게 유용하지만 종종 오버로입니다
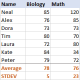 표준 편차 Excel : 기능 및 공식 예제Apr 11, 2025 am 11:01 AM
표준 편차 Excel : 기능 및 공식 예제Apr 11, 2025 am 11:01 AM이 튜토리얼은 표준 편차와 평균의 표준 오차의 차이점을 명확히하여 표준 편차 계산을위한 최적의 Excel 함수를 안내합니다. 설명 통계에서 평균 및 표준 편차는 Intrinsi입니다.
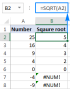 Excel의 제곱근 : SQRT 기능 및 기타 방법Apr 11, 2025 am 10:34 AM
Excel의 제곱근 : SQRT 기능 및 기타 방법Apr 11, 2025 am 10:34 AM이 Excel 튜토리얼은 정사각형 뿌리와 Nth 뿌리를 계산하는 방법을 보여줍니다. 제곱근을 찾는 것은 일반적인 수학적 작동이며 Excel은 몇 가지 방법을 제공합니다. Excel에서 사각형 뿌리를 계산하는 방법 : SQRT 기능 사용 : the
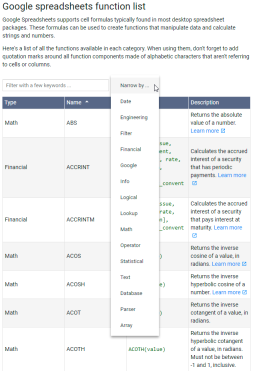 Google Sheets Basics : Google 스프레드 시트에서 작업하는 방법을 배우십시오.Apr 11, 2025 am 10:23 AM
Google Sheets Basics : Google 스프레드 시트에서 작업하는 방법을 배우십시오.Apr 11, 2025 am 10:23 AMGoogle Sheets : 초보자 가이드의 힘을 잠금 해제하십시오 이 튜토리얼은 MS Excel에 대한 강력하고 다양한 대안 인 Google Sheets의 기본 사항을 소개합니다. 스프레드 시트를 쉽게 관리하고, 주요 기능을 활용하며, 협업하는 방법에 대해 알아보십시오.


핫 AI 도구

Undresser.AI Undress
사실적인 누드 사진을 만들기 위한 AI 기반 앱

AI Clothes Remover
사진에서 옷을 제거하는 온라인 AI 도구입니다.

Undress AI Tool
무료로 이미지를 벗다

Clothoff.io
AI 옷 제거제

AI Hentai Generator
AI Hentai를 무료로 생성하십시오.

인기 기사
뜨거운 도구

VSCode Windows 64비트 다운로드
Microsoft에서 출시한 강력한 무료 IDE 편집기

드림위버 CS6
시각적 웹 개발 도구

WebStorm Mac 버전
유용한 JavaScript 개발 도구

안전한 시험 브라우저
안전한 시험 브라우저는 온라인 시험을 안전하게 치르기 위한 보안 브라우저 환경입니다. 이 소프트웨어는 모든 컴퓨터를 안전한 워크스테이션으로 바꿔줍니다. 이는 모든 유틸리티에 대한 액세스를 제어하고 학생들이 승인되지 않은 리소스를 사용하는 것을 방지합니다.

스튜디오 13.0.1 보내기
강력한 PHP 통합 개발 환경

