
PHP html_entity_decode 함수를 사용하는 방법

- 青灯夜游원래의
- 2019-05-27 10:06:332758검색
html_entity_decode() 함수는 HTML 엔터티를 문자로 변환하는 데 사용됩니다. 구문은 html_entity_decode(string, flags, char-set)입니다.
php html_entity_decode() 함수를 사용하는 방법은 무엇입니까?
html_entity_decode() 함수는 HTML 엔터티를 문자로 변환합니다.
Syntax
html_entity_decode(string,flags,character-set)
매개변수:
1. 문자열: 필수입니다. 디코딩할 문자열을 지정합니다.
2. 플래그: 선택 사항입니다. 따옴표 처리 방법과 사용되는 문서 유형을 지정합니다.
사용 가능한 견적 유형:
● ENT_COMPAT - 기본값. 큰따옴표만 디코딩됩니다.
● ENT_QUOTES - 큰따옴표와 작은따옴표를 디코딩합니다.
● ENT_NOQUOTES - 따옴표를 해독하지 마세요.
사용된 문서 유형을 지정하는 추가 플래그:
● ENT_HTML401 - 기본값. HTML 4.01로 처리된 코드.
● ENT_HTML5 - 코드를 HTML 5로 처리합니다.
● ENT_XML1 - XML 1 처리 코드.
● ENT_XHTML - XHTML 처리 코드.
3. 문자 집합: 선택 사항입니다. 사용할 문자 집합을 지정하는 문자열 값입니다. 허용되는 값:
● UTF-8 - 기본값. ASCII 호환 멀티바이트 8비트 유니코드
● ISO-8859-1 - 서유럽
● ISO-8859-15 - 서유럽(유로 기호 추가 + ISO-8859-1에서 누락된 프랑스어 및 핀란드 문자)
● cp866 - DOS 전용 키릴 문자 집합
● cp1251 - Windows 전용 키릴 문자 집합
● cp1252 - Windows 전용 서유럽 문자 집합
● KOI8-R - 러시아어
● BIG5 - 주로 중국어 번체 대만에서 사용됨
● GB2312 - 중국어 간체, 국가 표준 문자 집합
● BIG5-HKSCS - 홍콩 확장이 포함된 Big5
● Shift_JIS - 일본어
● EUC-JP - 일본어
● MacRoman - 다음에서 사용되는 문자 집합 Mac 운영 체제
참고: PHP 5.4 이전 버전에서는 인식할 수 없는 문자 집합이 무시되고 ISO-8859-1로 대체됩니다. PHP 5.4부터 인식할 수 없는 문자 세트는 무시되고 UTF-8로 대체됩니다.
반환값 : 변환된 문자열을 반환
예제를 통해 php strstr() 함수의 사용법을 살펴보겠습니다.
예 1: HTML 엔터티를 문자로 변환
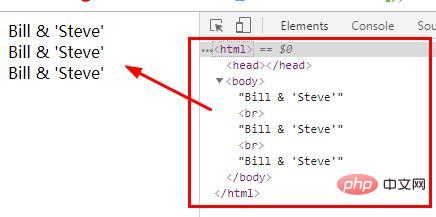
<?php $str = "Bill & 'Steve'"; echo html_entity_decode($str, ENT_COMPAT); // 只转换双引号 echo "<br>"; echo html_entity_decode($str, ENT_QUOTES); // 转换双引号和单引号 echo "<br>"; echo html_entity_decode($str, ENT_NOQUOTES); // 不转换任何引号 ?>
출력:
예 2: 서유럽 문자 세트를 사용하여 HTML 엔터티를 문자로 변환
<?php $str = "My name is Øyvind Åsane. I'm Norwegian."; echo html_entity_decode($str, ENT_QUOTES, "ISO-8859-1"); ?>
위 코드의 HTML 출력( 보기 소스 코드):
<!DOCTYPE html> <html> <body> My name is ?yvind ?sane. I'm Norwegian. </body> </html>
위 코드의 브라우저 출력:
My name is ?yvind ?sane. I'm Norwegian.
위 내용은 PHP html_entity_decode 함수를 사용하는 방법의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!