
중복 주문 접수 방지 전략 및 방법

- 藏色散人앞으로
- 2019-05-14 09:17:275798검색
Background
비즈니스 개발 과정에서 반복 요청을 방지하는 문제에 직면하는 경우가 많습니다. 요청에 대한 서버의 응답에 데이터 수정이나 상태 변경이 포함되면 큰 해를 끼칠 수 있습니다. 반복적인 요청의 결과는 거래 시스템, 판매 후 권리 보호 및 결제 시스템에서 특히 심각합니다.
프런트엔드 작업의 지터, 빠른 작업, 네트워크 통신 또는 느린 백엔드 응답은 백엔드에서 반복 처리될 가능성을 높입니다. 프런트엔드 작업을 디바운싱하고 빠른 작업을 방지하기 위한 조치를 취하기 위해 먼저 프런트엔드의 제어 계층을 생각합니다. 프런트 엔드가 작업을 트리거하면 확인 인터페이스가 팝업되거나 항목이 비활성화되고 카운트다운 등이 여기에 자세히 설명되지 않을 수 있습니다. 그러나 프런트엔드 제한은 문제의 일부만을 해결할 수 있을 뿐이고 백엔드 자체의 복제 방지 조치는 필수적이고 의무적입니다.
인터페이스 구현에서는 반복되는 요청 중 하나만 유효하도록 인터페이스가 멱등성을 충족해야 하는 경우가 많습니다.
쿼리 클래스의 인터페이스는 거의 항상 멱등성을 갖지만 데이터 삽입 및 다중 모듈 데이터 업데이트가 포함된 경우 멱등성을 달성하기가 더 어려워지며, 특히 높은 동시성 중 멱등성 요구 사항이 더욱 그렇습니다. 예를 들어, 제3자 결제 프런트 엔드 콜백 및 백그라운드 콜백, 제3자 결제 일괄 콜백, 느린 비즈니스 로직(예: 환불 신청을 제출하는 사용자, 반품/환불에 동의하는 판매자 등) 또는 느린 네트워크 환경은 높은 반복 처리에 대한 위험 시나리오.
Try
다음은 시도된 중복 방지 처리 방법의 효과를 설명하기 위해 "사용자가 환불 신청서를 제출하는" 예입니다. 백엔드에서 중복을 방지하기 위해 세 가지 방법을 시도했습니다.
(1) DB의 환불 주문 상태를 기반으로 확인
이 방법은 간단하고 직관적이며, DB에서 쿼리되는 환불 내역(상태 포함)이 종종 쿼리됩니다. 또한 반복되는 요청을 처리하기 위해 특별히 추가 작업을 수행하지 않고도 후속 논리에서 사용할 수 있습니다.
상태를 쿼리한 후 확인하는 이 논리는 코드가 온라인 상태가 된 이후 상태를 포함하는 모든 비즈니스 논리 처리에 존재했으며 필수적입니다. 그러나 중복 방지 처리의 효과는 좋지 않습니다. 프런트 엔드에 중복 방지 제출을 추가하기 전에는 평균 개수가 주당 25개였지만 프런트 엔드 최적화 후에는 주당 7개로 떨어졌습니다. 이는 전체 환불 신청 건수의 3%에 해당하는 수치로 아직까지 받아들일 수 없는 수준이다.
이론적으로 데이터 상태가 업데이트되기 전에 모든 요청이 쿼리 작업을 완료하는 한 비즈니스 로직의 반복 처리가 발생합니다. 아래 그림과 같습니다. 최적화 방향은 쿼리와 업데이트 사이의 비즈니스 처리 시간을 줄여 공백 기간이 동시성에 미치는 영향을 줄이는 것입니다. 극단적인 경우, 쿼리와 업데이트가 원자적 작업이 된다면 현재 문제는 존재하지 않을 것입니다.
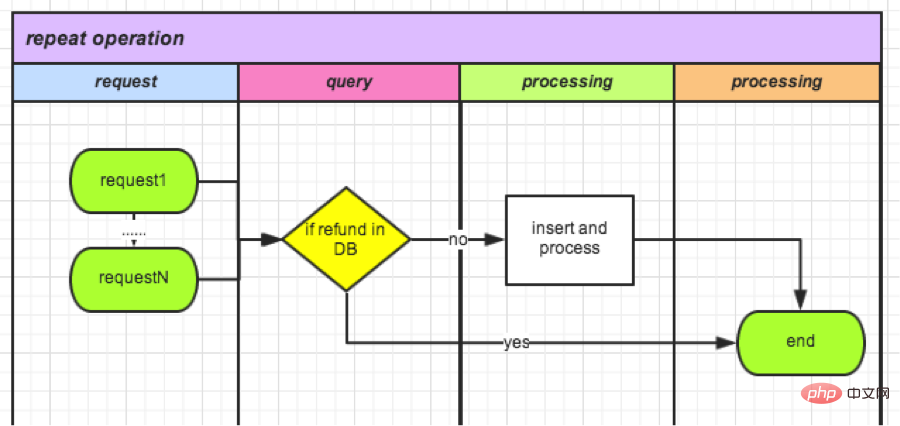
(2) 캐시된 데이터 상태에 따른 검증
Redis 저장소 쿼리는 가볍고 빠릅니다. 요청이 들어오면 먼저 캐시에 기록할 수 있습니다. 이후에 들어오는 요청은 매번 확인됩니다. 전체 프로세스가 완료되고 캐시가 삭제됩니다. 환불을 예로 들어보겠습니다.
- I. 환불 신청이 시작될 때마다 캐시에 orderId가 포함된 값이 있는지 확인합니다.
- II. 그렇지 않으면 orderId가 포함된 값을 캐시에 씁니다. 캐시
- III. 그렇다면 주문에 대한 환불이 진행 중이라는 의미입니다.
- IV. 작업 후 캐시를 지우거나 캐시가 저장될 때 수명주기를 설정합니다.
1) 발급에 비해 데이터베이스가 더 빠른 응답을 가진 캐시로 대체됩니다. 그러나 여전히 원자적 작업은 아닙니다. 캐시를 삽입하고 읽는 사이에는 여전히 시간 간격이 있습니다. 극단적인 경우에는 계속해서 수술을 반복하기도 합니다. 이 방법이 최적화된 후에는 일주일에 한 번씩 작업이 반복됩니다.
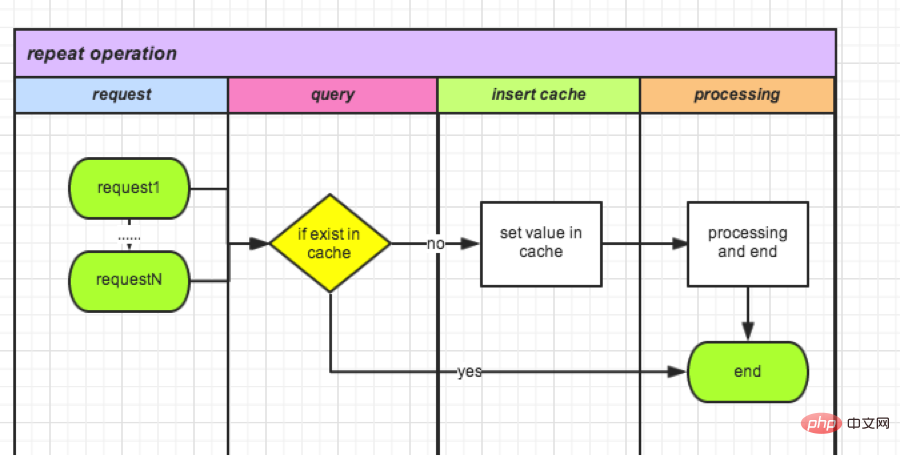
(3) 고유 인덱스 메커니즘을 사용한 검증
은 원자적 연산이 필요하며, 데이터베이스의 고유 인덱스가 떠오릅니다. 새 TradeLock 테이블 생성:
CREATE TABLE `TradeLock` ( `id` int(11) unsigned NOT NULL AUTO_INCREMENT, `type` int(11) NOT NULL COMMENT '锁类型', `lockId` int(11) NOT NULL DEFAULT '0' COMMENT '业务ID', `status` int(11) NOT NULL DEFAULT '0' COMMENT '锁状态', PRIMARY KEY (`id`) ) ENGINE=InnoDB AUTO_INCREMENT=1 DEFAULT CHARSET=utf8 COMMENT='Trade锁机制';
● 요청이 들어올 때마다 테이블에 데이터 삽입:
成功,则可以继续操作(相当于获取锁); 失败,则说明有操作在进行。
● 작업이 완료된 후 이 레코드를 삭제하세요. (잠금을 해제하는 것과 동일)
현재 온라인 상태이며 다음 주 데이터 통계를 기다리고 있습니다.
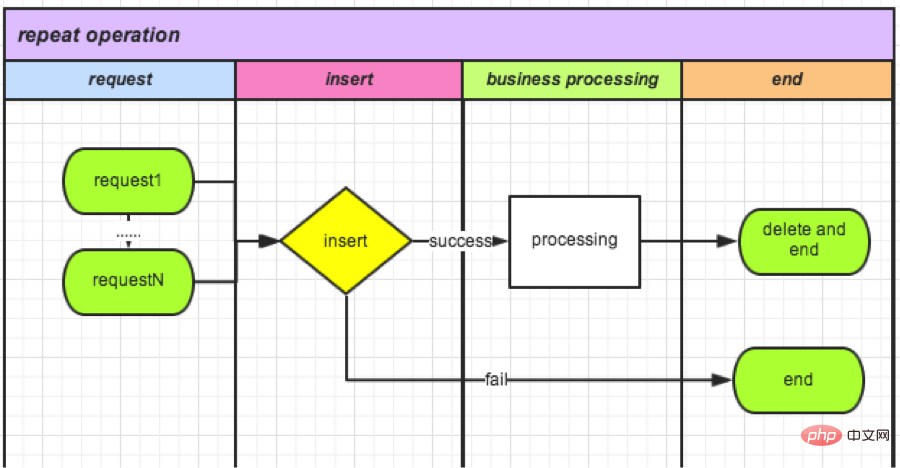
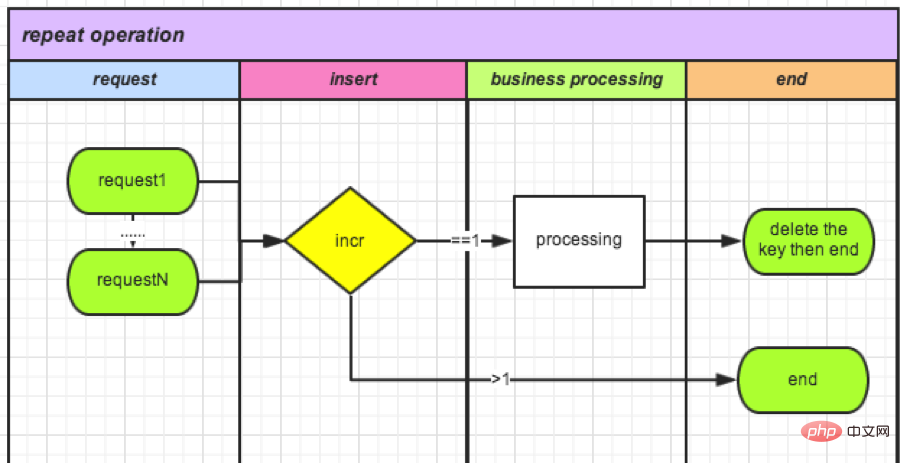
(4) 캐시 기반 카운터 검증
데이터베이스 작업은 성능을 소비하므로 Redis 카운터도 원자적 작업임을 배웠습니다. 카운터를 과감하게 사용하세요. 성능을 향상시킬 수 있을 뿐만 아니라 스토리지의 필요성도 없애고 최대 QPS를 늘릴 수 있습니다.
주문 환불을 예로 들어보겠습니다.
● 요청이 들어올 때마다 orderId를 키로 하는 새 카운터가 생성된 후 +1합니다.
如果>1(不能获得锁): 说明有操作在进行,删除。 如果=1(获得锁): 可以操作。
● 작업 종료(잠금 삭제): 이 카운터를 삭제합니다.
要了解计数器,可以参考:http://www.redis.cn/commands/incr.html
总结:
PHP语言自身没有提供进程互斥和锁定机制。因此才有了我们上面的尝试。网上也有文件锁机制,但是考虑到我们的分布式部署,建议还是用缓存。在大并发的情况下,程序各种情况的发生。特别是涉及到金额操作,不能有一分一毫的差距。所以在大并发要互斥的情况下可以考虑3、4两种方案。
爱迪生尝试了1600多种材料选择了钨丝发明了灯泡,实践出真知。遇到问题,和问题斗争,最后解决问题是一个最大提升自我的过程,不但加宽自己的知识广度,更加深了自己的技能深度。达到目标之后的成就感更是不言而喻。
위 내용은 중복 주문 접수 방지 전략 및 방법의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!