
Java를 사용하여 P2P 시드 검색 기능을 구현하는 방법

- 不言앞으로
- 2019-04-15 10:20:394173검색
이 기사의 내용은 Java를 사용하여 P2P 시드 검색 기능을 구현하는 방법에 대한 것입니다. 이는 특정 참고 가치가 있으므로 도움이 될 수 있습니다.
수년 전부터 P2P에 많은 관심을 갖고 있었지만 그것은 모두 이론적인 것에 불과했고 실제로 실천해 볼 기회가 없었습니다. 최근에 이 일을 구현했는데, 처음부터 지금까지 공유할 수 있는 부분이 있다고 생각합니다. 본론으로 들어가죠
기본 개념
p2p에 대해 이야기하기 전에 파일 다운로드 방법에 대해 이야기하고 싶습니다. 파일을 다운로드하는 여러 가지 방법을 나열해 보겠습니다.
1. 다운로드하려면 http 프로토콜을 사용하세요. 가장 일반적으로 사용되는 방법은 브라우저를 통해 파일을 다운로드하는 것입니다.
2. FTP에는 두 가지 모드가 있습니다. 하나는 포트(활성) 모드입니다. 이 모드에서는 클라이언트가 로컬로 포트 N(>1023)을 열어 FTP 연결을 설정합니다. to ftp server N. +1 리스닝 포트는 데이터 전송에 사용됩니다. 방화벽이 있거나 클라이언트가 NAT인 경우 다운로드할 수 없습니다. 또 다른 방법은 수동 모드입니다. 이 모드에서는 FTP 서버가 포트 21 외에도 1023보다 큰 다른 포트를 엽니다. 즉, FTP 서버가 있는 한 클라이언트는 FTP 연결과 데이터 전송 연결을 적극적으로 시작합니다. 이 포트에는 문제가 없습니다.
위의 두 가지 방법을 합쳐서 cs 아키텍처라고 할 수 있습니다. 이 아키텍처에서는 리소스가 특정 수준에 도달하면 문제가 발생합니다. 이 문제를 해결하기 위해 분산형 분산화를 생각할 수 있는데, p2p는 P2P(Peer to Peer) 아키텍처입니다.
p2p 아키텍처
리소스가 각 노드에 저장되면 리소스를 다운로드할 때 이 파일을 다운로드할 수 있는 컴퓨터를 어떻게 알 수 있을까?
초기 p2p 아키텍처에는 파일의 메타데이터 정보를 저장하는 역할을 담당하는 트래커 역할이 있었습니다. 이제 파일은 각 피어에 저장되고 파일 정보는 추적기를 통해 획득됩니다.
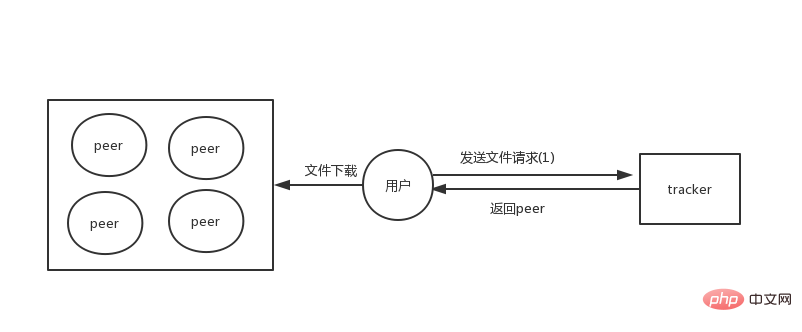
이 아키텍처에서는 모든 파일이 배포되지만 트래커는 모든 파일의 메타데이터 정보를 저장하는 역할을 담당하므로 트래커는 소량의 데이터만 저장하면 되며 이는 기존 파일보다 상대적으로 쉽습니다. .
그러나 트래커 서버가 정지되거나 서비스를 사용할 수 없게 되면 완전히 분산되지 않기 때문에 모든 파일이 다운로드되지 않습니다. 완전한 분산화를 위해 나중에 트래커 없는 아키텍처가 개발될 예정입니다.
이런 것은 없습니다. 더 이상 추적기로 사용되며 메타데이터 정보를 포함한 모든 파일은 분산 방식으로 저장됩니다.
DHT
DHT(분산 해시 테이블) 추적기를 대체하는 데 사용되는 분산 해시 테이블입니다. Kademlia 알고리즘 등 dht를 구현하는 많은 알고리즘이 있습니다.
몇 가지 개념:
1.nodeid dht 네트워크의 각 노드 ID는 160비트입니다
2.XOR 두 노드 사이의 거리는 XOR을 사용하여 계산됩니다
3.라우팅 테이블 라우팅 테이블
여기서 단어는 구현에 집중하겠습니다. 부분이므로 인터넷에 많은 정보가 있습니다.
구현 방법
시드 검색을 구현하는 데는 두 단계가 있습니다. 첫 번째 단계는 크롤러이며, 이는 크롤러에서 시드 정보를 크롤링하는 데 사용됩니다. 인터넷. 두 번째 단계는 검색에 참여하는 것입니다.
다음 지식이 필요합니다: 씨앗, 비트토렌트 dht 프로토콜, 벤코드
p2p에 관해서는 .torrent의 결과인 파일 종류인 씨앗을 언급해야 합니다. bt를 사용했을 수도 있습니다. 파일을 다운로드하려면 비트토렌트 프로토콜을 사용하세요. 그렇다면 인터넷에서 씨앗을 수집하는 방법은 무엇입니까?
BT 시드에 포함된 주요 필드: https://segmentfault.com/a/1190000000681331
dht에서 얻은 시드는 추적기 없는 토렌트라고 합니다. 알림 속성은 없지만 대신 노드 속성이 있습니다. router.bittorrent.com을 시드에 추가하거나 라우팅 테이블에 추가하지 않는 것이 공식적으로 권장됩니다.
1.dht에서 시드를 얻는 방법
시드 정보를 얻으려면 DHT 프로토콜에 대한 깊은 이해가 있어야 합니다. bep_0005는 DHT 프로토콜을 설명합니다.
자세한 내용은 여기를 클릭하세요. /www.bittorrent.org/beps/bep_0005.html
라우팅 테이블 구현 방법:
라우팅 테이블은 0부터 2까지 160승까지의 모든 노드 ID를 포함합니다. 라우팅 테이블은 버킷으로 구성될 수 있으며 각 버킷은 모든 노드의 일부를 포함합니다.
처음에는 라우팅 테이블에 모든 노드 ID를 포함하는 버킷이 하나만 있습니다. 각 버킷은 최대 K개의 노드만 보유할 수 있습니다. 현재 K 값은 8입니다. 버킷이 가득 차고 그 안의 모든 노드가 양호하며 자체 nodeid가 이 버킷에 없으면 원래 버킷은 각각 0..2159 및 2159를 포함하는 두 개의 새 버킷으로 나뉩니다. ..2160.
버킷이 가득 차면 새 노드가 쉽게 삭제됩니다. 버킷에 있는 노드가 오프라인 상태가 되면 교체됩니다. 지난 15분 동안 노드가 핑되지 않은 경우 해당 노드를 핑합니다. 응답이 반환되지 않으면 해당 노드도 교체됩니다.
각 버킷에는 이 버킷의 활동을 나타내는 마지막 변경 속성이 있어야 합니다. 이 필드는 다음 상황에서 업데이트됩니다.
1. 버킷의 노드가 ping되고 응답이 있습니다.
2. 이 버킷에 노드가 추가됩니다.
3. 버킷의 노드가 교체됩니다. 15입니다. 이 필드가 몇 분 내에 업데이트되지 않으면 버킷 범위 내의 ID가 무작위로 선택되고 find_node 작업이 수행됩니다.
KRPC 프로토콜
DHT 네트워크는 KRPC 프로토콜을 사용하여 메시지를 전달합니다.
1.pingping 쿼리는 주로 하트비트 확인에 사용됩니다.
2.find_node노드를 찾기 위해 상대방은 자신의 라우팅 테이블에서 가장 가까운 N개 노드를 쿼리하여 반환합니다. 일반적으로 8
3.get_peersinfohash를 기반으로 infohash를 소유한 피어를 찾습니다. 피어가 발견되면 노드를 반환하고, 찾을 수 없으면 노드를 반환합니다.
4.announce_peer다른 피어에게 다음과 같이 알립니다. 그들은 또한 infohash를 소유하고 있습니다.
위 4개는 라우팅 테이블을 새로 고치는 점에 유의하세요처음에는 라우팅 테이블에 노드가 없으므로 슈퍼 노드(예:
, 등), 반환된 노드는 Perform find_node에 있습니다.dht.transmissionbt.com제가 직접 구현한 라우팅 테이블은 위에서 설명한 것과 조금 다릅니다.
dht 네트워크는 데이터 전송에 udp를 사용하므로 upd 포트를 열고 지속적으로 find_node 요청을 보내 라우팅 테이블을 설정한 다음 get_peers 및 Announce_peer를 통해 시드의 infohash를 얻으면 됩니다. dht 네트워크에 가입하면 위에서 소개한 네 가지 방법을 통해서만 시드 파일의 infohash를 얻을 수 있으므로 infohash를 통해 시드를 다운로드해야 합니다. 자세한 내용은 bep_009http://를 참조하세요. www.bittorrent.org/beps /bep_0009.html
우리는 주로 bep_009를 사용하여 시드의 이름 필드를 얻은 후 이름과 infohash를 기반으로 색인을 생성하여 검색을 제공할 수 있습니다. (
여기서 주요 목적은 마그넷 링크를 구축하는 것입니다. 마그넷 링크를 사용하면 Thunder, Baidu Netdisk 등으로 이동하여 리소스를 다운로드할 수 있습니다)대부분의 마그넷 링크 형식: Magnet:?xt=urn:btih:infohash
위에서 소개한 방법은 infohash를 획득하여 마그넷 링크를 구축한 다음 타사 소프트웨어의 도움을 받아 다운로드하는 것입니다. 물론 관심이 있는 경우 BitTorrent 프로토콜을 통해 직접 다운로드할 수도 있습니다. 스스로요.
알겠습니다. 위에서는 몇 가지 구현 단계를 간략하게 소개했을 뿐입니다. 많은 세부 사항과 구체적인 구현은 언급되지 않았습니다. 제 말로는 일부 github dht 프로젝트를 참조하여 직접 구현한 것입니다. https: / /github.com/mistletoe9527/dht-spider
위 내용은 Java를 사용하여 P2P 시드 검색 기능을 구현하는 방법의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!