
집 >운영 및 유지보수 >리눅스 운영 및 유지 관리 >Linux 가상 네트워크 장치 veth-pair에 대한 자세한 설명, 이 문서는 매우 유익합니다.
Linux 가상 네트워크 장치 veth-pair에 대한 자세한 설명, 이 문서는 매우 유익합니다.

- 若昕앞으로
- 2019-04-01 13:03:505994검색
이 글에서는 veth-pair와 해당 연결성, 그리고 두 네임스페이스 간의 연결성을 소개합니다.
01 veth-pair란 무엇입니까
이름에서 알 수 있듯이 veth-pair는 가상 장치 인터페이스 쌍이며, /tun 장치와의 차이점은 쌍으로 나타난다는 것입니다. 한쪽 끝은 프로토콜 스택에 연결되고 다른 쪽 끝은 서로 연결됩니다. 아래 그림과 같이

이 기능으로 인해 다양한 가상 네트워크 장치를 연결하는 브리지 역할을 하는 경우가 많습니다. 일반적인 예로는 "두 네임스페이스 간의 연결", "브리지와 OVS 간의 연결" 등이 있습니다. Docker 컨테이너', 'Docker 컨테이너 간 연결' 등을 통해 OpenStack Neutron과 같은 매우 복잡한 가상 네트워크 구조를 구축할 수 있습니다.
02 veth-pair 연결
위 그림에서 veth0과 veth1에 IP를 각각 10.1.1.2와 10.1.1.3으로 할당한 다음 veth0에서 veth1에 ping을 보냅니다. 이론적으로는 동일한 네트워크 세그먼트에 있고 성공적으로 ping할 수 있지만 결과적으로 ping이 실패합니다.
패키지를 잡고 tcpdump -nnt -i veth0tcpdump -nnt -i veth0
root@ubuntu:~# tcpdump -nnt -i veth0 tcpdump: verbose output suppressed, use -v or -vv for full protocol decode listening on veth0, link-type EN10MB (Ethernet), capture size 262144 bytes ARP, Request who-has 10.1.1.3 tell 10.1.1.2, length 28 ARP, Request who-has 10.1.1.3 tell 10.1.1.2, length 28
可以看到,由于 veth0 和 veth1 处于同一个网段,且是第一次连接,所以会事先发 ARP 包,但 veth1 并没有响应 ARP 包。
经查阅,这是由于我使用的 Ubuntu 系统内核中一些 ARP 相关的默认配置限制所导致的,需要修改一下配置项:
echo 1 > /proc/sys/net/ipv4/conf/veth1/accept_local echo 1 > /proc/sys/net/ipv4/conf/veth0/accept_local echo 0 > /proc/sys/net/ipv4/conf/all/rp_filter echo 0 > /proc/sys/net/ipv4/conf/veth0/rp_filter echo 0 > /proc/sys/net/ipv4/conf/veth1/rp_filter
完了再 ping 就行了。
root@ubuntu:~# ping -I veth0 10.1.1.3 -c 2 PING 10.1.1.3 (10.1.1.3) from 10.1.1.2 veth0: 56(84) bytes of data. 64 bytes from 10.1.1.3: icmp_seq=1 ttl=64 time=0.047 ms 64 bytes from 10.1.1.3: icmp_seq=2 ttl=64 time=0.064 ms --- 10.1.1.3 ping statistics --- 2 packets transmitted, 2 received, 0% packet loss, time 3008ms rtt min/avg/max/mdev = 0.047/0.072/0.113/0.025 ms
我们对这个通信过程比较感兴趣,可以抓包看看。
对于 veth0 口:
root@ubuntu:~# tcpdump -nnt -i veth0 tcpdump: verbose output suppressed, use -v or -vv for full protocol decode listening on veth0, link-type EN10MB (Ethernet), capture size 262144 bytes ARP, Request who-has 10.1.1.3 tell 10.1.1.2, length 28 ARP, Reply 10.1.1.3 is-at 5a:07:76:8e:fb:cd, length 28 IP 10.1.1.2 > 10.1.1.3: ICMP echo request, id 2189, seq 1, length 64 IP 10.1.1.2 > 10.1.1.3: ICMP echo request, id 2189, seq 2, length 64 IP 10.1.1.2 > 10.1.1.3: ICMP echo request, id 2189, seq 3, length 64 IP 10.1.1.2 > 10.1.1.3: ICMP echo request, id 2244, seq 1, length 64
对于 veth1 口:
root@ubuntu:~# tcpdump -nnt -i veth1 tcpdump: verbose output suppressed, use -v or -vv for full protocol decode listening on veth1, link-type EN10MB (Ethernet), capture size 262144 bytes ARP, Request who-has 10.1.1.3 tell 10.1.1.2, length 28 ARP, Reply 10.1.1.3 is-at 5a:07:76:8e:fb:cd, length 28 IP 10.1.1.2 > 10.1.1.3: ICMP echo request, id 2189, seq 1, length 64 IP 10.1.1.2 > 10.1.1.3: ICMP echo request, id 2189, seq 2, length 64 IP 10.1.1.2 > 10.1.1.3: ICMP echo request, id 2189, seq 3, length 64 IP 10.1.1.2 > 10.1.1.3: ICMP echo request, id 2244, seq 1, length 64
奇怪,我们并没有看到 ICMP 的 echo reply 包,那它是怎么 ping 通的?
其实这里 echo reply 走的是 localback 口,不信抓个包看看:
root@ubuntu:~# tcpdump -nnt -i lo tcpdump: verbose output suppressed, use -v or -vv for full protocol decode listening on lo, link-type EN10MB (Ethernet), capture size 262144 bytes IP 10.1.1.3 > 10.1.1.2: ICMP echo reply, id 2244, seq 1, length 64 IP 10.1.1.3 > 10.1.1.2: ICMP echo reply, id 2244, seq 2, length 64 IP 10.1.1.3 > 10.1.1.2: ICMP echo reply, id 2244, seq 3, length 64 IP 10.1.1.3 > 10.1.1.2: ICMP echo reply, id 2244, seq 4, length 64
为什么?
我们看下整个通信流程就明白了。
- 首先 ping 程序构造 ICMP
echo request,通过 socket 发给协议栈。 - 由于 ping 指定了走 veth0 口,如果是第一次,则需要发 ARP 请求,否则协议栈直接将数据包交给 veth0。
- 由于 veth0 连着 veth1,所以 ICMP request 直接发给 veth1。
- veth1 收到请求后,交给另一端的协议栈。
- 协议栈看本地有 10.1.1.3 这个 IP,于是构造 ICMP reply 包,查看路由表,发现回给 10.1.1.0 网段的数据包应该走 localback 口,于是将 reply 包交给 lo 口(会优先查看路由表的 0 号表,
ip route show table 0# 创建 namespace ip netns a ns1 ip netns a ns2 # 创建一对 veth-pair veth0 veth1 ip l a veth0 type veth peer name veth1 # 将 veth0 veth1 分别加入两个 ns ip l s veth0 netns ns1 ip l s veth1 netns ns2 # 给两个 veth0 veth1 配上 IP 并启用 ip netns exec ns1 ip a a 10.1.1.2/24 dev veth0 ip netns exec ns1 ip l s veth0 up ip netns exec ns2 ip a a 10.1.1.3/24 dev veth1 ip netns exec ns2 ip l s veth1 up # 从 veth0 ping veth1 [root@localhost ~]# ip netns exec ns1 ping 10.1.1.3 PING 10.1.1.3 (10.1.1.3) 56(84) bytes of data. 64 bytes from 10.1.1.3: icmp_seq=1 ttl=64 time=0.073 ms 64 bytes from 10.1.1.3: icmp_seq=2 ttl=64 time=0.068 ms --- 10.1.1.3 ping statistics --- 15 packets transmitted, 15 received, 0% packet loss, time 14000ms rtt min/avg/max/mdev = 0.068/0.084/0.201/0.032 ms
을 살펴보세요. veth0과 veth1은 동일한 네트워크 세그먼트에 있고 처음으로 연결되므로 ARP는 미리 패킷을 보냈으나 veth1이 ARP 패킷에 응답하지 않았습니다. - 확인 결과 이는 제가 사용하고 있는 Ubuntu 시스템 커널의 일부 ARP 관련 기본 구성 제한으로 인해 발생합니다. 구성 항목을 수정해야 합니다.
# 首先创建 bridge br0 ip l a br0 type bridge ip l s br0 up # 然后创建两对 veth-pair ip l a veth0 type veth peer name br-veth0 ip l a veth1 type veth peer name br-veth1 # 分别将两对 veth-pair 加入两个 ns 和 br0 ip l s veth0 netns ns1 ip l s br-veth0 master br0 ip l s br-veth0 up ip l s veth1 netns ns2 ip l s br-veth1 master br0 ip l s br-veth1 up # 给两个 ns 中的 veth 配置 IP 并启用 ip netns exec ns1 ip a a 10.1.1.2/24 dev veth0 ip netns exec ns1 ip l s veth0 up ip netns exec ns2 ip a a 10.1.1.3/24 dev veth1 ip netns exec ns2 ip l s veth1 up # veth0 ping veth1 [root@localhost ~]# ip netns exec ns1 ping 10.1.1.3 PING 10.1.1.3 (10.1.1.3) 56(84) bytes of data. 64 bytes from 10.1.1.3: icmp_seq=1 ttl=64 time=0.060 ms 64 bytes from 10.1.1.3: icmp_seq=2 ttl=64 time=0.105 ms --- 10.1.1.3 ping statistics --- 2 packets transmitted, 2 received, 0% packet loss, time 999ms rtt min/avg/max/mdev = 0.060/0.082/0.105/0.024 ms
완료 후 다시 핑하면 됩니다. # 用 ovs 提供的命令创建一个 ovs bridge ovs-vsctl add-br ovs-br # 创建两对 veth-pair ip l a veth0 type veth peer name ovs-veth0 ip l a veth1 type veth peer name ovs-veth1 # 将 veth-pair 两端分别加入到 ns 和 ovs bridge 中 ip l s veth0 netns ns1 ovs-vsctl add-port ovs-br ovs-veth0 ip l s ovs-veth0 up ip l s veth1 netns ns2 ovs-vsctl add-port ovs-br ovs-veth1 ip l s ovs-veth1 up # 给 ns 中的 veth 配置 IP 并启用 ip netns exec ns1 ip a a 10.1.1.2/24 dev veth0 ip netns exec ns1 ip l s veth0 up ip netns exec ns2 ip a a 10.1.1.3/24 dev veth1 ip netns exec ns2 ip l s veth1 up # veth0 ping veth1 [root@localhost ~]# ip netns exec ns1 ping 10.1.1.3 PING 10.1.1.3 (10.1.1.3) 56(84) bytes of data. 64 bytes from 10.1.1.3: icmp_seq=1 ttl=64 time=0.311 ms 64 bytes from 10.1.1.3: icmp_seq=2 ttl=64 time=0.087 ms ^C --- 10.1.1.3 ping statistics --- 2 packets transmitted, 2 received, 0% packet loss, time 999ms rtt min/avg/max/mdev = 0.087/0.199/0.311/0.112 ms
우리는 이 통신 과정에 더 관심이 있고 패킷을 캡처하여 볼 수 있습니다.
veth0 포트의 경우:
rrreeeveth1 포트의 경우:  rrreee
rrreee
echo reply 패킷을 볼 수 없었는데 어떻게 ping이 성공적으로 이루어졌나요?
사실 여기 echo reply는 로컬백 포트를 사용합니다. 믿을 수 없다면 패키지를 가져와서 살펴보세요. rrreee
왜요? 전체적인 커뮤니케이션 과정을 살펴보신 후 이해해드리겠습니다.
- 먼저 ping 프로그램은 ICMP
에코 요청을 구성하고 이를 소켓을 통해 프로토콜 스택으로 보냅니다. ping은 veth0 포트를 지정하므로 처음이라면 ARP 요청을 보내야 하며, 그렇지 않으면 프로토콜 스택이 데이터 패킷을 veth0에 직접 넘겨줍니다. veth0이 veth1에 연결되어 있으므로 ICMP 요청이 veth1에 직접 전송됩니다.
veth1 요청을 받은 후 상대방의 프로토콜 스택으로 전달됩니다. 프로토콜 스택은 로컬에서 10.1.1.3이라는 IP 주소가 있음을 확인하여 ICMP 응답 패킷을 구성하고 라우팅 테이블을 확인한 후 10.1.1.0 네트워크 세그먼트로 다시 전송되는 데이터 패킷이 다음을 거쳐야 함을 찾습니다. localback 포트에 응답 패킷을 lo 포트로 전달합니다(라우팅 테이블의 View table 0, 보기 위해서는ip Route show table 0의 우선순위를 갖습니다). 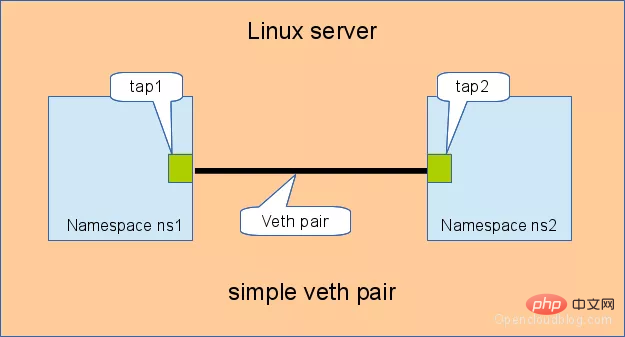 lo 프로토콜 스택에서 응답 패킷을 받은 후 그는 아무것도 하지 않고 손을 바꿔서 프로토콜 스택에 반환했습니다.
lo 프로토콜 스택에서 응답 패킷을 받은 후 그는 아무것도 하지 않고 손을 바꿔서 프로토콜 스택에 반환했습니다.
응답 패킷을 받은 후 프로토콜 스택은 해당 패킷을 기다리는 소켓이 있음을 발견하고 해당 패킷을 해당 소켓에 전달했습니다.
소켓이 반환되어 ICMP 응답 패킷이 수신되는 것을 찾기 위해 사용자 모드에서 ping 프로그램을 기다리는 중입니다.
전체 프로세스는 아래 그림과 같습니다.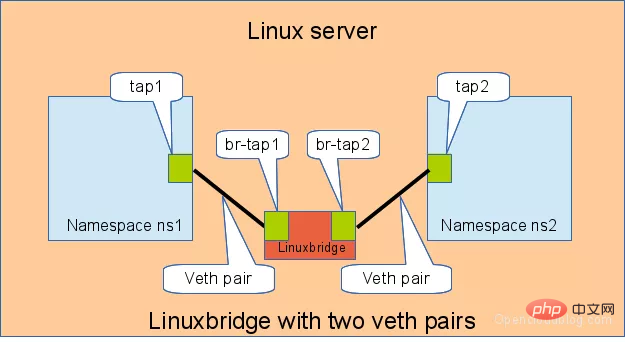
03 두 네임스페이스 간의 연결
네임스페이스는 Linux 2.6.x 커널 버전에서 지원하는 기능으로 주로 리소스 격리에 사용됩니다. 네임스페이스를 사용하면 Linux 시스템은 여러 네트워크 하위 시스템을 추상화할 수 있습니다. 각 하위 시스템은 서로 영향을 주지 않고 자체 네트워크 장비, 프로토콜 스택 등을 갖습니다.
네임스페이스 간 통신이 필요한 경우 어떻게 해야 할까요? 정답은 veth-pair를 브리지로 사용하는 것입니다. 연결 방식과 규모에 따라 '직접 연결', '브릿지를 통한 연결', 'OVS를 통한 연결'로 나눌 수 있습니다.3.1 직접 연결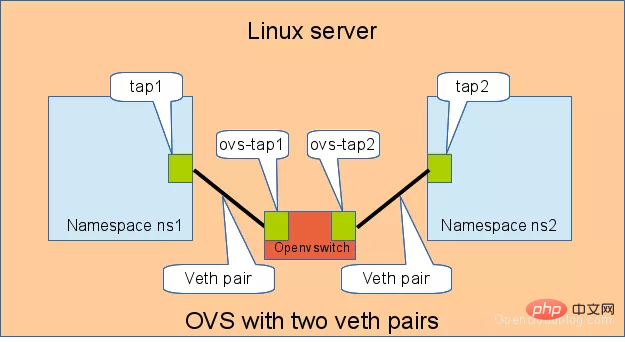
직접 연결은 가장 간단한 방법으로, 아래 그림과 같이 한 쌍의 veth-pair가 두 개의 네임스페이스를 직접 연결합니다.
🎜🎜🎜🎜veth-pair를 위한 IP 구성 및 연결 테스트: 🎜rrreee🎜3.2 Bridge를 통해 연결 🎜🎜Linux Bridge는 스위치와 동일하며 두 네임스페이스의 트래픽을 전달할 수 있습니다. 그.어떤 역할. 🎜🎜아래와 같이 두 쌍의 veth-pair가 두 개의 네임스페이스를 Bridge에 연결합니다. 🎜🎜🎜🎜🎜veth-pair에 대한 IP를 유사하게 구성하고 연결성을 테스트합니다. 🎜rrreee🎜🎜3.3 OVS를 통해 연결 🎜🎜🎜OVS는 Linux Bridge보다 더 강력한 기능을 갖춘 타사 오픈 소스 브리지입니다. OVS를 사용하여 효과가 무엇인지 살펴보겠습니다. 🎜🎜아래 그림과 같이: 🎜🎜🎜🎜🎜 또한 두 네임스페이스 간의 연결을 테스트합니다. 🎜# 用 ovs 提供的命令创建一个 ovs bridge ovs-vsctl add-br ovs-br # 创建两对 veth-pair ip l a veth0 type veth peer name ovs-veth0 ip l a veth1 type veth peer name ovs-veth1 # 将 veth-pair 两端分别加入到 ns 和 ovs bridge 中 ip l s veth0 netns ns1 ovs-vsctl add-port ovs-br ovs-veth0 ip l s ovs-veth0 up ip l s veth1 netns ns2 ovs-vsctl add-port ovs-br ovs-veth1 ip l s ovs-veth1 up # 给 ns 中的 veth 配置 IP 并启用 ip netns exec ns1 ip a a 10.1.1.2/24 dev veth0 ip netns exec ns1 ip l s veth0 up ip netns exec ns2 ip a a 10.1.1.3/24 dev veth1 ip netns exec ns2 ip l s veth1 up # veth0 ping veth1 [root@localhost ~]# ip netns exec ns1 ping 10.1.1.3 PING 10.1.1.3 (10.1.1.3) 56(84) bytes of data. 64 bytes from 10.1.1.3: icmp_seq=1 ttl=64 time=0.311 ms 64 bytes from 10.1.1.3: icmp_seq=2 ttl=64 time=0.087 ms ^C --- 10.1.1.3 ping statistics --- 2 packets transmitted, 2 received, 0% packet loss, time 999ms rtt min/avg/max/mdev = 0.087/0.199/0.311/0.112 ms
相关课程推荐:Linux视频教程
总结
veth-pair 在虚拟网络中充当着桥梁的角色,连接多种网络设备构成复杂的网络。
veth-pair 的三个经典实验,直接相连、通过 Bridge 相连和通过 OVS 相连。
参考
http://www.opencloudblog.com/?p=66
https://segmentfault.com/a/1190000009251098
위 내용은 Linux 가상 네트워크 장치 veth-pair에 대한 자세한 설명, 이 문서는 매우 유익합니다.의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!