
집 >데이터 베이스 >MySQL 튜토리얼 >MapReduce 기본 내용 소개(코드 포함)
MapReduce 기본 내용 소개(코드 포함)

- 不言앞으로
- 2019-02-12 11:42:412132검색
이 기사의 내용은 MapReduce의 기본 내용(코드 포함)에 대한 소개입니다. 도움이 필요한 친구들이 참고할 수 있기를 바랍니다. O1, WordCount 프로그램
1.1 Wordcount 소스 프로그램
import java.io.IOException;
import java.util.Iterator;
import java.util.StringTokenizer;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.util.GenericOptionsParser;
public class WordCount {
public WordCount() {
}
public static void main(String[] args) throws Exception {
Configuration conf = new Configuration();
String[] otherArgs = (new GenericOptionsParser(conf, args)).getRemainingArgs();
if(otherArgs.length < 2) {
System.err.println("Usage: wordcount <in> [<in>...] <out>");
System.exit(2);
}
Job job = Job.getInstance(conf, "word count");
job.setJarByClass(WordCount.class);
job.setMapperClass(WordCount.TokenizerMapper.class);
job.setCombinerClass(WordCount.IntSumReducer.class);
job.setReducerClass(WordCount.IntSumReducer.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
for(int i = 0; i < otherArgs.length - 1; ++i) {
FileInputFormat.addInputPath(job, new Path(otherArgs[i]));
}
FileOutputFormat.setOutputPath(job, new Path(otherArgs[otherArgs.length - 1]));
System.exit(job.waitForCompletion(true)?0:1);
}
public static class TokenizerMapper extends Mapper<Object, Text, Text, IntWritable> {
private static final IntWritable one = new IntWritable(1);
private Text word = new Text();
public TokenizerMapper() {
}
public void map(Object key, Text value, Mapper<Object, Text, Text, IntWritable>.Context context) throws IOException, InterruptedException {
StringTokenizer itr = new StringTokenizer(value.toString());
while(itr.hasMoreTokens()) {
this.word.set(itr.nextToken());
context.write(this.word, one);
}
}
}
public static class IntSumReducer extends Reducer<Text, IntWritable, Text, IntWritable> {
private IntWritable result = new IntWritable();
public IntSumReducer() {
}
public void reduce(Text key, Iterable<IntWritable> values, Reducer<Text, IntWritable, Text, IntWritable>.Context context) throws IOException, InterruptedException {
int sum = 0;
IntWritable val;
for(Iterator i$ = values.iterator(); i$.hasNext(); sum += val.get()) {
val = (IntWritable)i$.next();
}
this.result.set(sum);
context.write(key, this.result);
}
}
}1.2 프로그램 실행, 실행 as-& gt; Java 애플리케이션
1.3 패킹 프로그램 컴파일, jar 파일 생성
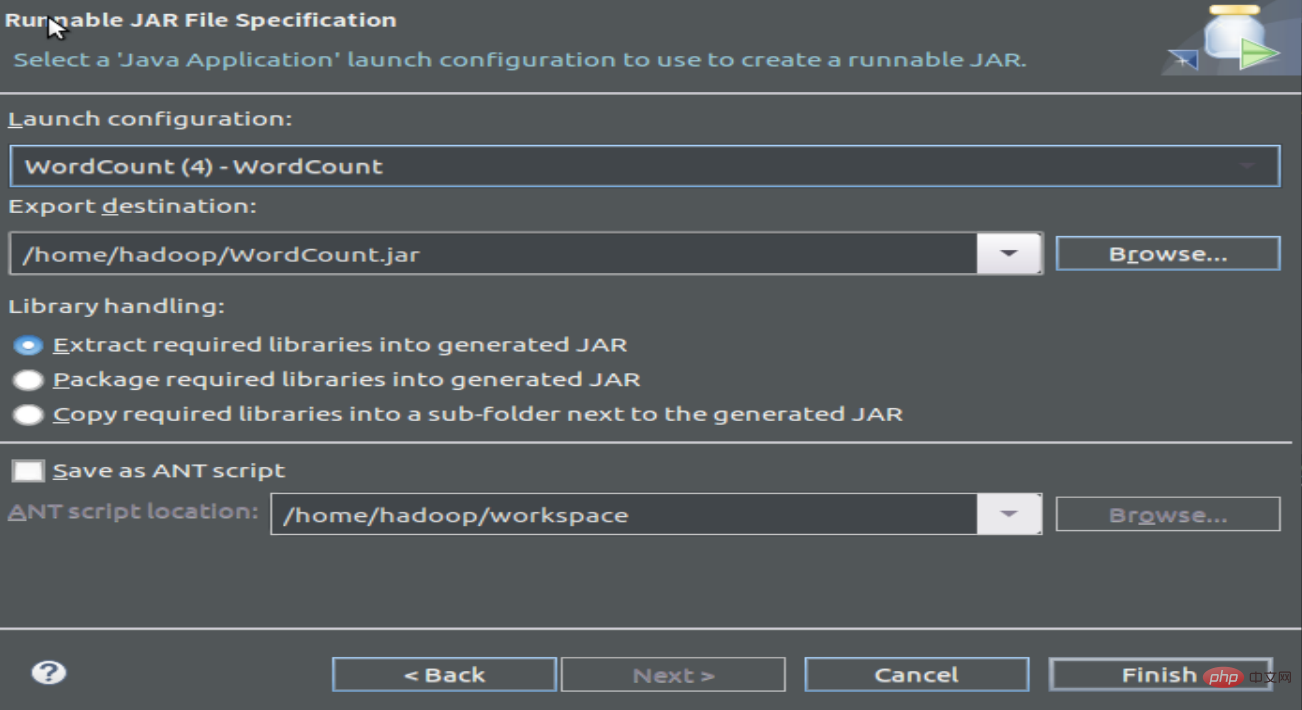 2 실행 프로그램
2 실행 프로그램
2.1 필수 텍스트 설정 단어 빈도를 계산하는 파일
wordfile1.txt
Spark Hadoop
Big Data
wordfile2.txt
Spark Hadoop
Big Cloud
2.2 hdfs를 시작하고 새 입력 폴더를 생성한 후 단어 빈도 파일을 업로드하세요
cd /usr /local/hadoop/
./sbin/start-dfs.sh
./bin/hadoop fs -mkdir 입력
./bin/hadoop fs -put /home/hadoop/wordfile1.txt 입력
./ bin/hadoop fs -put /home/hadoop/wordfile2.txt input
2.3 업로드된 단어 빈도 파일 보기:
hadoop@dblab-VirtualBox:/usr/local/hadoop$ ./bin/hadoop fs -ls .
2개 항목 발견drwxr-xr-x - hadoop 슈퍼 그룹 0 2019-02-11 15:40 input
-rw-r--r-- 1 hadoop 슈퍼 그룹 5 2019-02-10 20:22 테스트. txt
hadoop@ dblab-VirtualBox:/usr/local/hadoop$ ./bin/hadoop fs -ls ./input
2개 항목 발견
-rw-r--r-- 1 hadoop 슈퍼 그룹 27 2019-02-11 15 :40 입력/ wordfile1.txt
-rw-r--r-- 1 hadoop 슈퍼그룹 29 2019-02-11 15:40 입력/wordfile2.txt
2.4 WordCount
./bin/hadoop jar /home/ 실행 hadoop/WordCount.jar 입력 출력
화면에 많은 정보가 입력됩니다
그러면 실행 결과를 볼 수 있습니다:
hadoop@dblab-VirtualBox:/usr/local/hadoop$ ./bin/hadoop fs -cat 출력/*
Hadoop 2 Spark 2
위 내용은 MapReduce 기본 내용 소개(코드 포함)의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!