
Java의 최종 구현 원칙에 대한 심층 분석(예제 포함)

- 不言앞으로
- 2018-11-27 16:56:014811검색
이 기사는 Java의 최종 구현 원칙에 대한 심층 분석을 제공합니다(예제 포함). 도움이 필요한 친구들이 참고할 수 있기를 바랍니다.
final은 멤버 변수, 메소드, 클래스 및 지역 변수를 선언할 수 있는 Java의 예약 키워드입니다.
참조 선언을 최종적으로 만들면 참조를 변경할 수 없습니다. 컴파일러는 코드를 확인합니다. 변수를 다시 초기화하려고 하면 컴파일러가 컴파일 오류를 보고합니다.
1. 최종 변수
최종 멤버 변수는 상수를 나타내며 한 번만 할당할 수 있습니다. 할당 후에는 값이 변경되지 않습니다. (final에서는 주소 값을 변경할 수 없습니다.)
final이 기본을 수정하는 경우 데이터 유형은 이 기본 데이터 유형의 값이 초기화되면 변경할 수 없음을 의미합니다. final이 참조 유형을 수정하면 초기화된 후에는 더 이상 다른 객체를 가리킬 수 없지만 참조가 가리키는 객체의 내용은 변경될 수 있습니다. 참조되는 값은 주소이고 final은 값, 즉 주소의 값이 변하지 않도록 요구하기 때문에 본질적으로 같은 것입니다.
final은 멤버 변수(속성)를 수정하며 명시적으로 초기화되어야 합니다. 초기화 방법에는 두 가지가 있는데, 하나는 변수 선언 시 초기화하는 방법이고, 두 번째 방법은 변수 선언 시 초기값을 할당하지 않고, 변수가 위치한 클래스의 모든 생성자에서 변수에 할당하는 것이다. . 초기값.
2. 최종 방법
최종 방법을 사용하는 이유는 두 가지입니다.
첫 번째 이유는 상속된 클래스가 의미를 수정하지 못하도록 메서드를 잠그고 재정의할 수 없다는 것입니다.
두 번째 이유는 효율성입니다. 최종 메서드는 컴파일 중에 이미 컴파일되기 때문입니다. 정적으로 바인딩되므로 런타임에 동적으로 바인딩할 필요가 없습니다.
(참고: 클래스의 프라이빗 메소드는 암시적으로 최종 메소드로 지정됩니다.)
3. 최종 클래스
클래스가 final로 수정되면 이 클래스를 상속할 수 없음을 나타냅니다.
final 클래스의 멤버 변수는 필요에 따라 final로 설정할 수 있지만 final 클래스의 모든 멤버 메서드는 암시적으로 final 메서드로 지정된다는 점에 유의하세요.
final을 사용하여 클래스를 수정할 때는 신중하게 선택해야 합니다. 이 클래스가 나중에 상속에 사용되지 않거나 보안상의 이유로 사용되지 않는 한 클래스를 final 클래스로 설계하지 마세요.
IV. 최종 사용 요약
최종 키워드의 이점:
(1) 최종 키워드는 성능을 향상시킵니다. JVM과 Java 애플리케이션 모두 최종 변수를 캐시합니다.
(2) 추가 동기화 오버헤드 없이 멀티 스레드 환경에서 최종 변수를 안전하게 공유할 수 있습니다.
(3) JVM은 final 키워드를 사용하여 메서드, 변수 및 클래스를 최적화합니다.
final에 대한 중요 지식 포인트
1. final 키워드는 멤버 변수, 지역 변수, 메소드 및 클래스에 사용할 수 있습니다.
2. 생성자에서 선언하거나 초기화할 때 최종 멤버 변수를 초기화해야 합니다. 그렇지 않으면 컴파일 오류가 보고됩니다.
3. 최종 변수에 값을 다시 할당할 수 없습니다.
4. 지역 변수는 선언 시 값을 할당받아야 합니다.
5. 익명 클래스의 모든 변수는 최종 변수여야 합니다.
6. 최종 메서드는 재정의될 수 없습니다.
7. 최종 클래스는 상속할 수 없습니다.
8. final 키워드는 예외 처리에 사용되는 finally 키워드와 다릅니다.
9. final 키워드는 finalize() 메소드와 혼동되기 쉽습니다. 후자는 Object 클래스에 정의된 메소드이며 가비지 수집 전에 JVM에 의해 호출됩니다.
10. 인터페이스에 선언된 모든 변수는 최종 변수입니다.
11. final과 abstract 두 키워드는 상관 관계가 없으며 final 클래스는 abstract가 될 수 없습니다.
12. 최종 메서드는 컴파일 단계에서 바인딩되며 이를 정적 바인딩이라고 합니다.
13. 선언 시 초기화되지 않은 최종 변수를 빈 최종 변수라고 합니다. 생성자에서 초기화하거나 this()를 호출하여 초기화해야 합니다. 이렇게 하지 않으면 컴파일러는 "최종 변수(변수 이름)를 초기화해야 합니다."라는 오류를 보고합니다.
14. 클래스, 메소드, 변수를 final로 선언하면 성능이 향상되므로 JVM이 추정하고 최적화할 수 있습니다.
15. Java 코딩 규칙에 따르면 최종 변수는 상수이며 상수 이름은 일반적으로 대문자입니다.
16. 컬렉션 개체를 최종으로 선언한다는 것은 참조를 변경할 수 없지만 콘텐츠를 추가, 삭제 또는 변경할 수 있음을 의미합니다.
5. 최종 원칙
Java 메모리 모델을 먼저 이해하는 것이 가장 좋습니다. Java 동시성(2): Java 메모리 모델
최종 필드의 경우 컴파일러와 프로세서는 두 가지 재정렬 규칙을 준수해야 합니다.
1. 생성자 최종 필드에 쓴 다음 생성된 개체에 대한 참조를 참조 변수에 할당하는 작업은 재정렬될 수 없습니다.
(최종 변수를 먼저 작성한 다음 객체 참조 호출)
이유: 컴파일러는 최종 필드를 작성한 후 StoreStore 장벽을 삽입합니다
2. 최종 필드를 포함하는 객체에 대한 참조의 첫 번째 읽기와 최종 필드의 후속 첫 번째 읽기는 이 두 작업 사이에서 재정렬될 수 없습니다.
(객체의 참조를 먼저 읽은 다음 최종 변수를 읽습니다.)
컴파일러는 최종 필드 읽기 작업 앞에 LoadLoad 장벽을 삽입합니다.
# 🎜🎜#예 1:
public class FinalExample {
int i; // 普通变量
final int j; // final 变量
static FinalExample obj;
public void FinalExample() { // 构造函数
i = 1; // 写普通域
j = 2; // 写 final 域
}
public static void writer() { // 写线程 A 执行
obj = new FinalExample();
}
public static void reader() { // 读线程 B 执行
FinalExample object = obj; // 读对象引用
int a = object.i; // 读普通域 a=1或者a=0或者直接报错i没有初始化
int b = object.j; // 读 final域 b=2
}
}
첫 번째 경우: 일반 필드를 작성하는 작업은 생성자 외부의 컴파일러에 의해 재정렬됩니다
최종 필드 작성 작업은 생성자 내에서 최종 필드 작성 순서 변경 규칙에 따라 "제한"됩니다. 스레드 B를 읽으면 초기화 후 최종 변수의 값을 올바르게 읽습니다. 최종 필드에 대한 재정렬 규칙을 작성하면 객체 참조가 모든 스레드에 표시되기 전에 객체의 최종 필드가 올바르게 초기화되었는지 확인할 수 있지만 일반 필드에는 이러한 보장이 없습니다.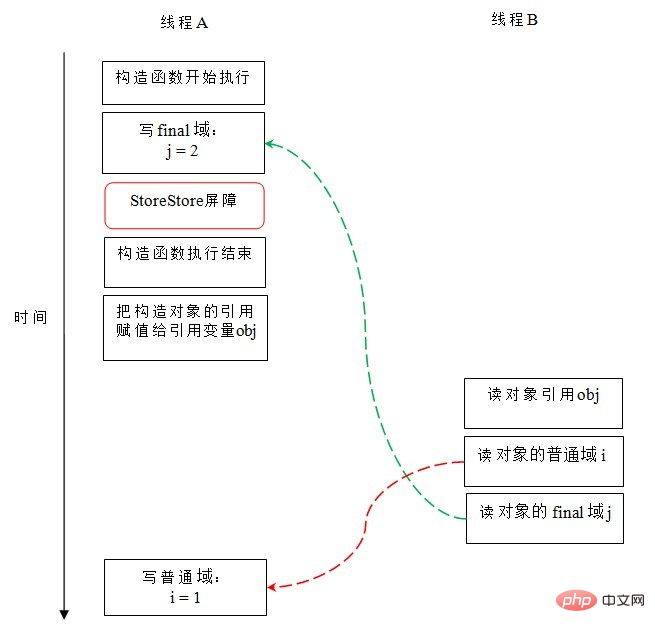
두 번째 경우: 객체 참조를 읽기 전에 프로세서에 의해 객체의 일반 필드를 읽는 작업이 재정렬됩니다#🎜 🎜## 🎜🎜#최종 필드 읽기에 대한 재정렬 규칙은 객체 참조를 읽은 후 객체의 최종 필드를 읽는 작업을 "제한"합니다. 이때 최종 필드는 A에 의해 초기화되었습니다. 스레드입니다. 올바른 읽기입니다.
최종 필드 읽기에 대한 재정렬 규칙은 객체의 최종 필드를 읽기 전에 최종 필드를 포함하는 객체에 대한 참조를 먼저 읽어야 함을 보장합니다. 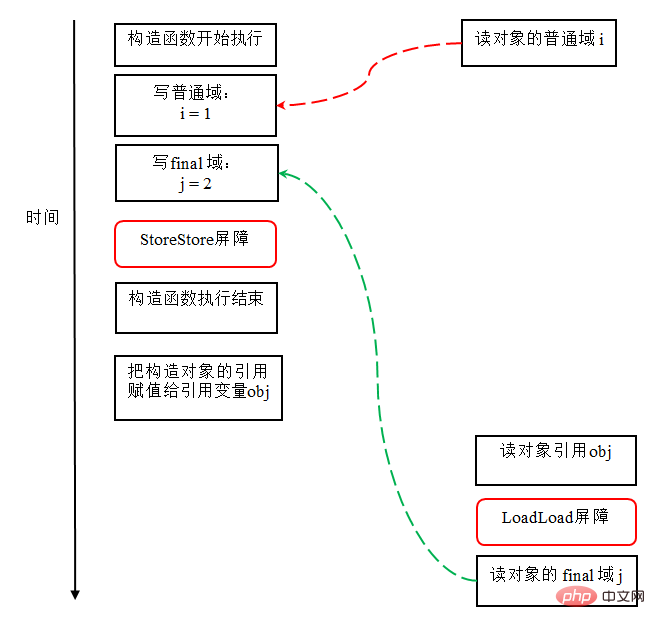
예 2: 마지막 필드가 참조 유형인 경우
#🎜🎜 ## 🎜🎜#참조 유형의 경우 최종 필드 작성을 위한 재정렬 규칙은 컴파일러와 프로세서에 다음 제약 조건을 추가합니다.생성자 내에서 최종 참조 객체의 멤버 필드에 쓰기 및 이후 생성된 객체에 대한 참조를 생성자 외부의 참조 변수에 할당합니다. 이 두 작업은 순서를 바꿀 수 없습니다.
public class FinalReferenceExample {
final int[] intArray; // final 是引用类型
static FinalReferenceExample obj;
public FinalReferenceExample() { // 构造函数
intArray = new int[1]; // 1
intArray[0] = 1; // 2
}
public static void writerOne() { // 写线程 A 执行
obj = new FinalReferenceExample(); // 3
}
public static void writerTwo() { // 写线程 B 执行
obj.intArray[0] = 2; // 4
}
public static void reader() { // 读线程 C 执行
if (obj != null) { // 5
int temp1 = obj.intArray[0]; // 6 temp1=1或者temp1=2,不可能等于0
}
}
} 첫 번째 스레드 A가writerOne() 메서드를 실행하고, 실행 후 스레드 B가 WriterTwo() 메서드를 실행하고, 실행 후 스레드 C가 reader() 메서드를 실행한다고 가정합니다.
위 그림에서 1은 final 필드에 대한 쓰기, 2는 final 필드에 대한 참조입니다. field 객체 3의 멤버 필드를 작성하는 것은 생성된 객체의 참조를 참조 변수에 할당하는 것입니다. 앞서 언급한 1은 3과 함께 재정렬할 수 없으며, 2와 3도 재정렬할 수 없습니다.  JMM은 읽기 스레드 C가 적어도 생성자의 쓰기 스레드 A에 의해 최종 참조 개체의 멤버 필드 쓰기를 볼 수 있도록 보장할 수 있습니다. 즉, C는 적어도 배열 인덱스 0의 값이 1이라는 것을 알 수 있습니다. 스레드 B를 작성하여 배열 요소를 쓰는 것은 스레드 C를 읽는 데 표시될 수도 있고 표시되지 않을 수도 있습니다. JMM은 스레드 B 쓰기와 스레드 C 읽기 사이에 데이터 경쟁이 있고 이때 실행 결과를 예측할 수 없기 때문에 스레드 B의 쓰기가 읽기 스레드 C에 표시된다는 것을 보장하지 않습니다.
JMM은 읽기 스레드 C가 적어도 생성자의 쓰기 스레드 A에 의해 최종 참조 개체의 멤버 필드 쓰기를 볼 수 있도록 보장할 수 있습니다. 즉, C는 적어도 배열 인덱스 0의 값이 1이라는 것을 알 수 있습니다. 스레드 B를 작성하여 배열 요소를 쓰는 것은 스레드 C를 읽는 데 표시될 수도 있고 표시되지 않을 수도 있습니다. JMM은 스레드 B 쓰기와 스레드 C 읽기 사이에 데이터 경쟁이 있고 이때 실행 결과를 예측할 수 없기 때문에 스레드 B의 쓰기가 읽기 스레드 C에 표시된다는 것을 보장하지 않습니다.
위 내용은 Java의 최종 구현 원칙에 대한 심층 분석(예제 포함)의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!