
가을 채용을 위한 몇 가지 일반적인 Java 인터뷰 질문 분석

- 青灯夜游앞으로
- 2018-10-23 16:44:152559검색
이 기사에서는 가을 채용을 위한 몇 가지 일반적인 Java 면접 질문에 대한 분석을 제공합니다. 도움이 필요한 친구들이 참고할 수 있기를 바랍니다.
머리말
대머리만이 강해질 수 있다
Redis는 여전히 자, 오늘은 제가 가을 채용에서 본(만난) 면접질문(비교적 흔한) 몇 가지를 공유해보겠습니다
0, 최종 키워드 #🎜🎜 ## 🎜🎜# final을 사용하여 수정할 수 있는 키워드에 대해 간단히 이야기해 보겠습니다.
실제 인터뷰에서 이 질문을 접했는데 당시에는 잘 대답하지 못했습니다.
final은 클래스, 메소드, 멤버 변수를 수정할 수 있습니다
- final이 클래스를 수정하면 해당 클래스를 상속할 수 없다는 의미입니다#🎜 🎜#
- final이 메소드를 수정하면 해당 메소드를 재정의할 수 없음을 의미합니다
- #🎜 🎜# 초기에는
-
final이 멤버 변수를 수정할 때 두 가지 상황이 있습니다.
수정이 기본형이라면 이 변수가 나타내는 값은 절대로 변경(재할당)할 수 없다는 뜻이에요!
- 수정이 참조형인 경우 변수의 참조는 변경할 수 없으나, 참조로 표현되는 객체의 내용은 가변입니다!
-
다음 사항을 언급할 가치가 있습니다.
은 final에 의해 수정된 멤버 변수가 반드시 컴파일 타임 상수 임을 의미하지는 않습니다. 예를 들어, 다음과 같은 코드를 작성할 수 있습니다:
- 최종 수정된 메서드를 사용할 수 있으며 컴파일러에서 이러한 메서드에 대한 모든 호출은 인라인 호출로 변환되어 효율성이 향상됩니다(그러나 지금은 일반적으로 이 문제에 대해 신경 쓰지 않습니다. 컴파일러와 JVM이 점점 더 똑똑해지고 있습니다)
그런 프로그래밍 경험이 있습니까? 컴파일러로 코드를 작성할 때 특정 시나리오에서는 변수를 final로 선언해야 합니다. 그렇지 않으면 컴파일이 실패할 수 있습니다. . 왜 이렇게 설계되었나요? 익명 내부 클래스를 작성할 때 이런 일이 발생할 수 있습니다. private final int java3y = new Randon().nextInt(20);
# 🎜🎜#
- 메서드 또는 범위 내의 지역 변수
- 메서드의 매개변수
- # 🎜🎜#
class Outer { // string:外部类的实例变量 String string = ""; //ch:方法的参数 void outerTest(final char ch) { // integer:方法内局部变量 final Integer integer = 1; new Inner() { void innerTest() { System.out.println(string); System.out.println(ch); System.out.println(integer); } }; } public static void main(String[] args) { new Outer().outerTest(' '); } class Inner { } }우리는 메소드나 범위 내의 지역 변수와 메소드 매개변수가 최종 키워드 - (jdk1.7에서)를 사용하여 수정되도록 표시되어야 함을 볼 수 있습니다!
jdk1.8 컴파일 환경으로 전환하면 ~
을 통해 컴파일할 수 있습니다. #🎜🎜 # 먼저 디스플레이 선언이 최종인 이유에 대해 이야기해 보겠습니다. 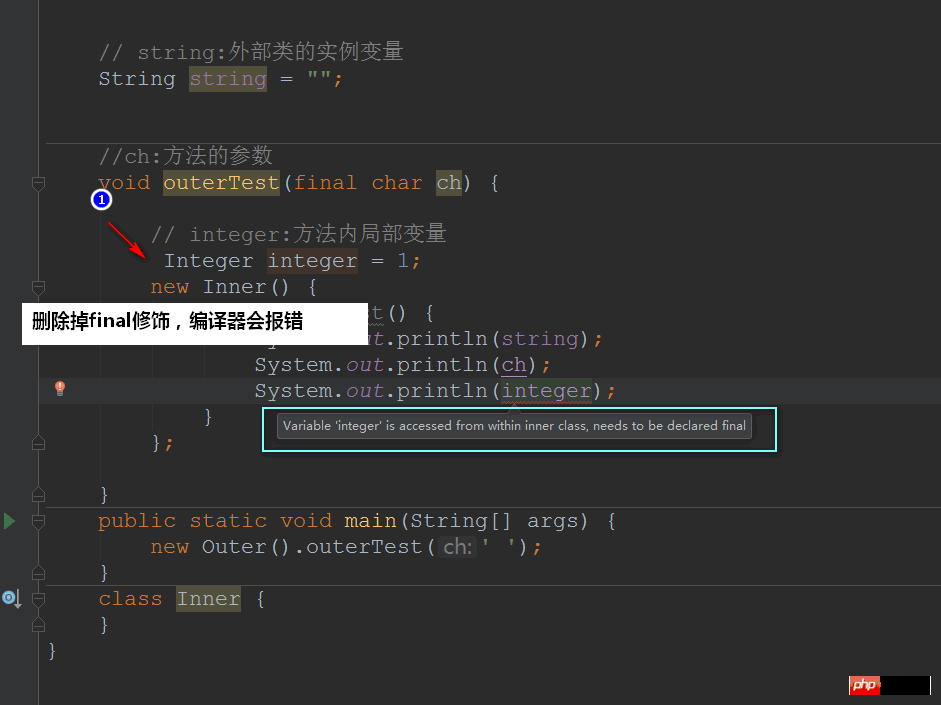 내부 및 외부 데이터의 일관성을 유지하기 위해
내부 및 외부 데이터의 일관성을 유지하기 위해
Java 값별 캡처 형식으로 클로저를 구현합니다. 즉, 익명 함수는  자유 변수
자유 변수
내부 및 외부 데이터 일관성의 목적을 달성하려면
- 두 개의 변수만 변경하지 않고 유지
- 하면 됩니다. JDK8 이전에는 최종 수정을 사용해야 했습니다. JDK8은 더 똑똑하고 효과적으로 최종 메서드를 사용할 수 있습니다.
왜 최종을 메서드의 매개변수로만 제한하고 속성에 액세스합니까? 내부 클래스는 외부 클래스의 인스턴스를 가리키는 참조
를 저장합니다. 이 참조를 통해. -
참조된 데이터는 내부 클래스에서 수정되었으며, 외부 클래스 에서 얻은 데이터는
을 얻었을 때와 동일합니다!
표면적으로 은 성공한 것처럼 보이지만 은 실제로 외부 변수
에 영향을 주지 않습니다. 따라서 Java는 너무 이상하게 보이는 것을 방지하기 위해 이러한 최종 제한 사항을 추가했습니다.- Reference:
java 익명 내부 클래스의 매개변수 참조가 최종적인 이유는 무엇입니까? https://www.zhihu.com/question/21395848
1의 차이점#. 🎜 🎜#
- char은 고정 길이이고, varchar는 가변 길이입니다. varchar:
- 원래 저장소 위치가 저장소 요구 사항을 충족할 수 없는 경우
, 일부 추가 작업이 필요합니다. 저장소 엔진에 따라 일부는
분할 메커니즘 을 사용합니다.
. char的存储方式是:英文字符占1个字节,汉字占用2个字节;varchar的存储方式是:英文和汉字都占用2个字节,两者的存储数据都非unicode的字符数据。 char是固定长度,长度不够的情况下,用空格代替。varchar表示的是实际长度的数据类型 选用考量: 如果字段长度较短和字符间长度相近甚至是相同的长度,会采用char字符类型 二、多个线程顺序打印问题 原博主给出了4种方式,我认为信号量这种方式比较简单和容易理解,我这里粘贴一下(具体的可到原博主下学习).. 作者:cheergoivan 链接:https://www.jianshu.com/p/40078ed436b4 來源:简书 2018年9月14日18:15:36 yy笔试题就出了.. 三、生产者和消费者 在不少的面经都能看到它的身影哈~~~基本都是要求能够手写代码的。 其实逻辑并不难,概括起来就两句话: 如果生产者的队列满了(while循环判断是否满),则等待。如果生产者的队列没满,则生产数据并唤醒消费者进行消费。 如果消费者的队列空了(while循环判断是否空),则等待。如果消费者的队列没空,则消费数据并唤醒生产者进行生产。 基于原作者的代码,我修改了部分并给上我认为合适的注释(下面附上了原作者出处,感兴趣的同学可到原文学习) 生产者: 消费者: Main方法测试: 作者:我没有三颗心脏 链接:https://www.jianshu.com/p/3f0cd7af370d 來源:简书 另外,上面原文中也说了可以使用阻塞队列来实现消费者和生产者。这就不用我们手动去写 使用阻塞队列解决生产者-消费者问题:https://www.cnblogs.com/chenpi/p/5553325.html 四、算法[1] 解决方案: 使用一个min变量来记住最小值,每次push的时候,看看是否需要更新min。 如果被pop出去的是min,第二次pop的时候,只能遍历一下栈内元素,重新找到最小值。 总结:pop的时间复杂度是O(n),push是O(1),空间是O(1) 使用辅助栈来存储最小值。如果当前要push的值比辅助栈的min值要小,那在辅助栈push的值是最小值 总结:push和pop的时间复杂度都是O(1),空间是O(n)。典型以空间换时间的例子。 继续优化: 栈为空的时候,返回-1很可能会带来歧义(万一人家push进去的值就有-1呢?),这边我们可以使用Java Exception来进行优化 算法的空间优化:上面的代码我们可以发现:data栈和mins栈的元素个数总是相等的,mins栈中存储几乎都是最小的值(此部分是重复的!) 所以我们可以这样做:当push的时候,如果比min栈的值要小的,才放进mins栈。同理,当pop的时候,如果pop的值是mins的最小值,mins才出栈,否则mins不出栈! 上述做法可以一定避免mins辅助栈有相同的元素! 但是,如果一直push的值是最小值,那我们的mins辅助栈还是会有大量的重复元素,此时我们可以使用索引(mins辅助栈存储的是最小值索引,非具体的值)! 最终代码: 参考资料: 【인터뷰 현장】최소값을 얻을 수 있는 스택을 어떻게 구현하나요? 작성자: channingbreeze 출처: Internet Reconnaissance 5. 멀티 스레딩 하의 HashMap 우리 모두 알고 있듯이 HashMap은 스레드로부터 안전한 클래스가 아닙니다. 하지만 인터뷰 중에 다음과 같은 질문을 받을 수도 있습니다. HashMap을 멀티 스레드 환경에서 사용하면 어떻게 되나요? ? 결론: 6. Spring과 Springboot의 차이점
1. SpringBoot는 독립적인 Spring 애플리케이션을 생성할 수 있습니다 Spring Boot 프로젝트는 지루한 구성 문제를 해결하고 구성보다 관례를 극대화하는 것입니다( 다른 작업을 즉시 사용할 수 있도록 일련의 종속성 패키지를 제공합니다. 여기에는 프로젝트 구성을 고도로 캡슐화하고 프로젝트 구성 구성을 크게 단순화하는 'Starter POM'이 내장되어 있습니다. 7. G1 및 CMS G1은 메모리 정리 프로세스가 있고 많은 메모리 조각을 생성하지 않습니다 G1의 STW(Stop The World)는 더 쉽게 제어할 수 있으며 G1은 예측 메커니즘을 추가합니다. 일시 중지 시간 , 사용자는 원하는 일시 중지 시간을 지정 8. 대용량 데이터 솔루션 적용 범위: 데이터의 양이 많고 반복 횟수가 많지만 데이터의 종류가 작아 메모리에 담을 수 있음 분산 처리 mapreduce 적용 범위: 데이터는 크지만 데이터의 종류는 작아서 메모리에 담을 수 있다 메모리 자세한 내용은 원문을 참고하세요: 10가지 대용량 데이터 처리 면접 질문과 10가지 방법 요약 : https://blog.csdn.net/v_JULY_v/article/details/6279498 Nine, idempotence 9.1 HTTP idempotence 시험 문제, HTTP의 고전적인 单纯以HTTP协议规范来说,可能我们之前总结出的 参考资料: GET和POST有什么区别?及为什么网上的多数答案都是错的。http://www.cnblogs.com/nankezhishi/archive/2012/06/09/getandpost.html 其中也学习到了幂等性这么一个概念,于是也做做笔记吧~~~ 从定义上看,HTTP方法的幂等性是指一次和多次请求某一个资源应该具有同样的副作用。 这里简单说一下“副作用”的意思:指当你发送完一个请求以后,网站上的资源状态没有发生修改,即认为这个请求是无副作用的 HTTP的 比如我想要获得订单ID为2的订单: 比如我想要删除或者更新ID为2的订单: 比如我想要创建一个名称叫3y的订单: For 예를 들어, 주문 ID를 주문 2: 정보를 확인해보면 많은 블로그에서 인터페이스 의 멱등성에 대해 이야기하는 것을 볼 수 있습니다. 위에서 그렇게 말했지만 인터페이스를 멱등성으로 디자인하면 어떤 이점이 있나요? ? ? ? 비멱등성의 단점 예: 3y 신입생 때 체육 수업을 들어야 했는데, 그런데 학교 수업 잡기 시스템이 형편없어요(레이턴시가 너무 높음). 수업을 듣고 싶어서 10개 이상의 Chrome 탭을 열어서 수강했습니다(Chrome 탭 하나가 충돌하더라도 여전히 다른 Chrome 탭을 사용할 수 있었습니다). 탁구공이나 배드민턴공을 잡고 싶어요. 수업 시간이 되면 잡고 싶은 탁구나 배드민턴을 차례로 클릭합니다. 시스템이 제대로 설계되지 않았고 요청이 멱등성이 아니며(또는 트랜잭션이 제대로 제어되지 않고) 손 속도가 충분히 빠르고 네트워크가 충분히 좋다면 탁구나 배드민턴 레슨을 여러 번 받았을 수도 있습니다. (이건 무리입니다. 한 사람이 한 과목만 선택할 수 있는데 여러 과목 또는 반복 과목을 수강했습니다.) 상점 적용 시나리오는 다음과 같습니다. 사용자 여러 중복 주문 내 클래스 가져오기 인터페이스가 멱등적이라면 이 문제는 발생하지 않습니다. 멱등성은 리소스에 대한 여러 요청이 동일한 부작용을 가져야 함을 의미하기 때문입니다. 반복 제출을 방지하는 것 (데이터베이스에 여러 중복 데이터)입니다! 토큰 테이블 + 고유 제약 조건(간단한 권장 사항) ---->멱등성 인터페이스 구현 방법# 🎜🎜 # 인터페이스 멱등성 요약 https://www.jianshu.com/p/6eba27f8fb03 데이터베이스 고유 키를 사용하여 트랜잭션 멱등성 평등 구현 http:// www.caosh.me/be-tech/idempotence-using-unique-key/ API 인터페이스 비멱등성 문제 및 redis 사용 간단한 분산 잠금 구현 https: //blog.csdn.net/rariki/article/details/50783819 Finally三个线程分别打印A,B,C,要求这三个线程一起运行,打印n次,输出形如“ABCABCABC....”的字符串。
public class PrintABCUsingSemaphore {
private int times;
private Semaphore semaphoreA = new Semaphore(1);
private Semaphore semaphoreB = new Semaphore(0);
private Semaphore semaphoreC = new Semaphore(0);
public PrintABCUsingSemaphore(int times) {
this.times = times;
}
public static void main(String[] args) {
PrintABCUsingSemaphore printABC = new PrintABCUsingSemaphore(10);
// 非静态方法引用 x::toString 和() -> x.toString() 是等价的!
new Thread(printABC::printA).start();
new Thread(printABC::printB).start();
new Thread(printABC::printC).start();
/*new Thread(() -> printABC.printA()).start();
new Thread(() -> printABC.printB()).start();
new Thread(() -> printABC.printC()).start();
*/
}
public void printA() {
try {
print("A", semaphoreA, semaphoreB);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
public void printB() {
try {
print("B", semaphoreB, semaphoreC);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
public void printC() {
try {
print("C", semaphoreC, semaphoreA);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
private void print(String name, Semaphore current, Semaphore next)
throws InterruptedException {
for (int i = 0; i < times; i++) {
current.acquire();
System.out.print(name);
next.release();
}
}
}
import java.util.Random;
import java.util.Vector;
import java.util.concurrent.atomic.AtomicInteger;
public class Producer implements Runnable {
// true--->生产者一直执行,false--->停掉生产者
private volatile boolean isRunning = true;
// 公共资源
private final Vector sharedQueue;
// 公共资源的最大数量
private final int SIZE;
// 生产数据
private static AtomicInteger count = new AtomicInteger();
public Producer(Vector sharedQueue, int SIZE) {
this.sharedQueue = sharedQueue;
this.SIZE = SIZE;
}
@Override
public void run() {
int data;
Random r = new Random();
System.out.println("start producer id = " + Thread.currentThread().getId());
try {
while (isRunning) {
// 模拟延迟
Thread.sleep(r.nextInt(1000));
// 当队列满时阻塞等待
while (sharedQueue.size() == SIZE) {
synchronized (sharedQueue) {
System.out.println("Queue is full, producer " + Thread.currentThread().getId()
+ " is waiting, size:" + sharedQueue.size());
sharedQueue.wait();
}
}
// 队列不满时持续创造新元素
synchronized (sharedQueue) {
// 生产数据
data = count.incrementAndGet();
sharedQueue.add(data);
System.out.println("producer create data:" + data + ", size:" + sharedQueue.size());
sharedQueue.notifyAll();
}
}
} catch (InterruptedException e) {
e.printStackTrace();
Thread.currentThread().interrupted();
}
}
public void stop() {
isRunning = false;
}
}import java.util.Random;
import java.util.Vector;
public class Consumer implements Runnable {
// 公共资源
private final Vector sharedQueue;
public Consumer(Vector sharedQueue) {
this.sharedQueue = sharedQueue;
}
@Override
public void run() {
Random r = new Random();
System.out.println("start consumer id = " + Thread.currentThread().getId());
try {
while (true) {
// 模拟延迟
Thread.sleep(r.nextInt(1000));
// 当队列空时阻塞等待
while (sharedQueue.isEmpty()) {
synchronized (sharedQueue) {
System.out.println("Queue is empty, consumer " + Thread.currentThread().getId()
+ " is waiting, size:" + sharedQueue.size());
sharedQueue.wait();
}
}
// 队列不空时持续消费元素
synchronized (sharedQueue) {
System.out.println("consumer consume data:" + sharedQueue.remove(0) + ", size:" + sharedQueue.size());
sharedQueue.notifyAll();
}
}
} catch (InterruptedException e) {
e.printStackTrace();
Thread.currentThread().interrupt();
}
}
}import java.util.Vector;
import java.util.concurrent.ExecutorService;
import java.util.concurrent.Executors;
public class Test2 {
public static void main(String[] args) throws InterruptedException {
// 1.构建内存缓冲区
Vector sharedQueue = new Vector();
int size = 4;
// 2.建立线程池和线程
ExecutorService service = Executors.newCachedThreadPool();
Producer prodThread1 = new Producer(sharedQueue, size);
Producer prodThread2 = new Producer(sharedQueue, size);
Producer prodThread3 = new Producer(sharedQueue, size);
Consumer consThread1 = new Consumer(sharedQueue);
Consumer consThread2 = new Consumer(sharedQueue);
Consumer consThread3 = new Consumer(sharedQueue);
service.execute(prodThread1);
service.execute(prodThread2);
service.execute(prodThread3);
service.execute(consThread1);
service.execute(consThread2);
service.execute(consThread3);
// 3.睡一会儿然后尝试停止生产者(结束循环)
Thread.sleep(10 * 1000);
prodThread1.stop();
prodThread2.stop();
prodThread3.stop();
// 4.再睡一会儿关闭线程池
Thread.sleep(3000);
// 5.shutdown()等待任务执行完才中断线程(因为消费者一直在运行的,所以会发现程序无法结束)
service.shutdown();
}
}
wait/notify的代码了,会简单一丢丢。可以参考:我现在需要实现一个栈,这个栈除了可以进行普通的push、pop操作以外,还可以进行getMin的操作,getMin方法被调用后,会返回当前栈的最小值,你会怎么做呢?你可以假设栈里面存的都是int整数
import java.util.ArrayList;
import java.util.List;
public class MinStack {
private List<Integer> data = new ArrayList<Integer>();
private List<Integer> mins = new ArrayList<Integer>();
public void push(int num) {
data.add(num);
if (mins.size() == 0) {
// 初始化mins
mins.add(num);
} else {
// 辅助栈mins每次push当时最小值
int min = getMin();
if (num >= min) {
mins.add(min);
} else {
mins.add(num);
}
}
}
public int pop() {
// 栈空,异常,返回-1
if (data.size() == 0) {
return -1;
}
// pop时两栈同步pop
mins.remove(mins.size() - 1);
return data.remove(data.size() - 1);
}
public int getMin() {
// 栈空,异常,返回-1
if (mins.size() == 0) {
return -1;
}
// 返回mins栈顶元素
return mins.get(mins.size() - 1);
}
}
import java.util.ArrayList;
import java.util.List;
public class MinStack {
private List<Integer> data = new ArrayList<Integer>();
private List<Integer> mins = new ArrayList<Integer>();
public void push(int num) throws Exception {
data.add(num);
if(mins.size() == 0) {
// 初始化mins
mins.add(0);
} else {
// 辅助栈mins push最小值的索引
int min = getMin();
if (num < min) {
mins.add(data.size() - 1);
}
}
}
public int pop() throws Exception {
// 栈空,抛出异常
if(data.size() == 0) {
throw new Exception("栈为空");
}
// pop时先获取索引
int popIndex = data.size() - 1;
// 获取mins栈顶元素,它是最小值索引
int minIndex = mins.get(mins.size() - 1);
// 如果pop出去的索引就是最小值索引,mins才出栈
if(popIndex == minIndex) {
mins.remove(mins.size() - 1);
}
return data.remove(data.size() - 1);
}
public int getMin() throws Exception {
// 栈空,抛出异常
if(data.size() == 0) {
throw new Exception("栈为空");
}
// 获取mins栈顶元素,它是最小值索引
int minIndex = mins.get(mins.size() - 1);
return data.get(minIndex);
}
}
fail-fast 메커니즘, 현재 HashMap을 동시에 삭제/수정하면 오류가 발생합니다. ConcurrentModificationException 예외 put()put()的时候导致的多线程数据不一致(丢失数据)resize()
jdk1.8은 연결 문제를 해결했습니다(두 쌍의 포인터 선언 및 두 개의 연결된 목록 유지)resize() 작업으로 인해 발생한 멀티 스레드 데이터 불일치(데이터 손실)로 인해 순환 링크가 발생합니다. list
jdk1.8 hashmap 다중 스레드 넣기는 원인을 발생시키지 않습니다. 무한 루프: https: //blog.csdn.net/qq_27007251/article/details/71403647
3. 내장형 Tomcat, Jetty 컨테이너, WAR 패키지 배포 필요 없음 ).
더 읽어보기:
get/post 사이의 차이점. 오늘 돌아와서 검색해보니 이전에 이해했던 것과 조금 다르다는 것을 알게 되었습니다get/post的区别。今天回来搜了一下,发现跟之前的理解有点出入。如果一个人一开始就做Web开发,很可能把HTML对HTTP协议的使用方式,当成HTTP协议的唯一的合理使用方式。从而犯了以偏概全的错误
GET/POST区别就没用了。(但通读完整篇文章,我个人认为:如果面试中有GET/POST区别,还是默认以Web开发场景下来回答较好,这也许是面试官想要的答案)Methods can also have the property of “idempotence” in that (aside from error or expiration issues) the side-effects of N > 0 identical requests is the same as for a single request.
GET/POST/DELETE/PUT方法幂等的情况:
: 인터뷰에서 GET是幂等的,无副作用http://localhost/order/2,使用GET多次获取,这个ID为2的订单(资源)是不会发生变化的!DELETE/PUT是幂等的,有副作用http://localhost/order/2,使用PUT/DELETE多次请求,这个ID为2的订单(资源)只会发生一次变化(是有副作用的)!但继续多次刷新请求,订单ID为2的最终状态都是一致的POST是非幂等的,有副作用的
개인적으로는 생각http://localhost/order,使用POST. 사람이 처음부터 웹 개발을 한다면 HTML이 HTTP 프로토콜을 사용하는 방식이 HTTP 프로토콜의 유일한 합리적인 사용으로 간주될 가능성이 매우 높습니다. 따라서 우리는 과도하게 일반화하는 실수를 저질렀습니다 GET/POST 구분은 쓸모가 없을 수 있습니다. (근데 기사를 다 읽어보니 GET/POST의 차이가 있다면 기본적으로 웹 개발 시나리오에서 답변하는 게 나을 것 같다. 면접관이 원하는 답변) 참고:
GET과 POST의 차이점은 무엇인가요? 그리고 왜 인터넷에 있는 대부분의 답변이 틀렸는가? http://www.cnblogs.com/nankezhishi/archive/2012/06/09/getandpost.html멱등성 개념도 배워서 메모도 했어요~~
방법도 가능해요 (오류 또는 만료 문제를 제외하고) N > 0 동일한 요청의 부작용은 단일 요청의 경우와 동일하다는 점에서 "멱등성" 속성입니다.정의에 따르면, HTTP 메서드 평등의 힘은 리소스에 대한 여러 요청에는 동일한 부작용이 있어야 합니다.
GET/POST/DELETE/PUT 메서드는 멱등성을 갖습니다.
GET은 멱등성이 있고 부작용이 없습니다
http://localhost/order/2로 가져오고 싶습니다. GET를 사용하여 이 주문(리소스 ) ID 2는발생하지 않습니다. 변경! DELETE/PUT은 멱등성이 있고 부작용이 있습니다🎜🎜🎜🎜🎜예를 들어 ID가 2인 주문을 삭제하거나 업데이트하고 싶습니다: http://localhost/ order /2, PUT/DELETE를 사용하여 여러 번 요청🎜하면 ID 2의 순서(리소스)는 한 번만 변경됩니다🎜(부작용이 있음)! 그러나 요청을 여러 번 계속 새로 고치십시오. 🎜주문 ID 2의 최종 상태는 일관됩니다🎜🎜🎜🎜🎜🎜POST는 멱등성이 아니며 부작용이 있습니다🎜🎜🎜🎜🎜예를 들어, 원하는 것 3y라는 주문을 생성합니다: http://localhost/order, POST를 사용하여 여러 요청을 할 수 있습니다. 이때 3y라는 주문이 여러 개 생성될 수 있습니다. 🎜 이 주문(리소스)은 여러 번 변경됩니다. 🎜요청된 리소스 상태는 매번 변경됩니다🎜! 🎜🎜🎜🎜🎜다툼: 🎜🎜HTTP 프로토콜 자체는 🎜리소스 지향 애플리케이션 계층 프로토콜🎜이지만 실제로 HTTP 프로토콜을 사용하는 방법에는 두 가지가 있습니다. 하나는 🎜RESTful🎜으로, HTTP를 애플리케이션 계층 프로토콜로 처리합니다. HTTP 프로토콜의 다양한 규정을 더욱 충실하게 준수합니다(🎜 HTTP 메소드를 최대한 활용합니다 🎜). 또 다른 🎜는 SOA 🎜로 HTTP를 애플리케이션 계층 프로토콜로 완전히 간주하지 않지만 HTTP 프로토콜을 전송 수단으로 사용합니다. HTTP🎜🎜참조: 🎜🎜🎜🎜HTTP 멱등성 이해 http://www.cnblogs.com/weidagang2046/archive/ 2011/06/04/2063696.html# !comments🎜🎜🎜🎜RESTful의 멱등성을 이해하는 방법 http://blog.720ui.com/2016/restful_idempotent/🎜🎜🎜🎜HTTP에서 Get과 Post의 차이점에 대한 간략한 토론 http://www.cnblogs .com/hyddd/archive/2009/03/31/1426026.html🎜🎜🎜🎜HTTP 요청에서 POST와 GET 요청의 차이점은 무엇인가요? https://www.zhihu.com/question/27622127/answer/37676304🎜🎜🎜🎜🎜🎜9.2 인터페이스 멱등성🎜🎜🎜POST方法是非幂等的。但我们可以通过一些手段来令POST 메서드의 인터페이스가 멱등원이 되는 것을 볼 수 있습니다.
직설적으로 말하면 멱등성 인터페이스를 설계하는 목적은
분산 시스템 인터페이스 멱등성 http://blog.brucefeng.info/post/ api-idempotent
위 내용은 가을 채용을 위한 몇 가지 일반적인 Java 인터뷰 질문 분석의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!