
javaweb의 테이블 쿼리에 대한 SQL 최적화 소개

- 不言앞으로
- 2018-10-12 14:35:282719검색
이 기사는 javaweb의 테이블 쿼리에 대한 SQL 최적화에 대한 소개를 제공합니다. 이는 특정 참조 가치가 있으므로 도움이 될 수 있습니다.
Background
이 SQL 최적화는 javaweb의 테이블 쿼리를 위한 것입니다.
네트워크 아키텍처 다이어그램의 일부
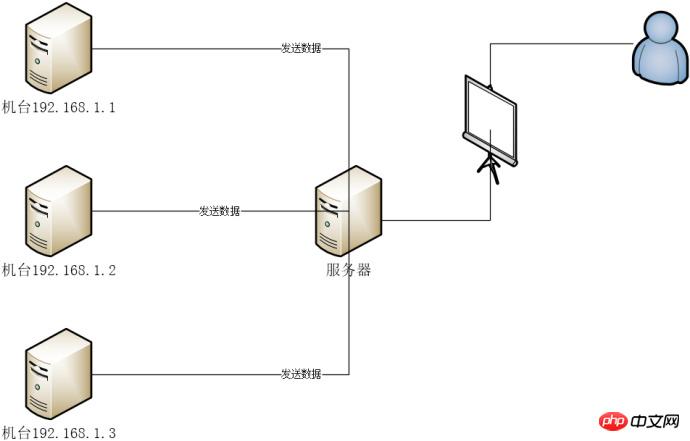
비즈니스에 대한 간단한 설명
N 머신은 비즈니스 데이터를 서버로 보내고, 서버 프로그램은 해당 데이터를 MySQL 데이터베이스에 저장합니다. 서버의 javaweb 프로그램은 사용자가 볼 수 있도록 웹 페이지에 데이터를 표시합니다.
원래 데이터베이스 설계
Windows 독립형 마스터-슬레이브 분리
테이블과 데이터베이스로 나누어져 있으며 연도별 데이터베이스, 일별 테이블로 나누어져 있습니다
-
각 테이블에는 약 200,000개의 데이터가 있습니다
원본 쿼리 효율성
3일 데이터 쿼리 70-80s
Target
3-5s
비즈니스 결함
SQL 페이징을 사용할 수 없으며 페이징에는 Java만 사용할 수 있습니다.
문제 해결
느린 프런트 데스크 또는 느린 백엔드
druid를 구성하면 druid 페이지에서 sql 실행 시간과 uri 요청 시간을 직접 볼 수 있습니다.
System.currentTimeMillis를 사용하여 시간 차이를 계산하세요. 배경 코드.
백그라운드도 느리고, SQL 쿼리도 느립니다
SQL의 문제점은 무엇인가요?
SQL 스플라이싱이 너무 길어서 3000줄에 달하고 일부는 심지어 대부분 8000줄에 달합니다. 그것들은 모든 작업을 통합하고 불필요한 중첩 쿼리와 불필요한 필드가 쿼리됩니다
실행 계획을 보려면 설명을 사용하세요. where 조건에서는 시간을 제외한 하나의 필드만 인덱스를 사용합니다
참고: 최적화 완료되었습니다. 이전 SQL은 정말 찾기 어렵습니다. 더 이상 여기서는 YY만 할 수 있습니다.
쿼리 최적화
불필요한 필드 제거
효과가 그다지 명확하지 않습니다
불필요한 중첩 쿼리 제거
효과가 그다지 명확하지 않습니다
Decompose sql
Union all의 연산을 분해합니다(예: Union all의 sql도 엄청 길어요)
select aa from bb_2018_10_01 left join ... on .. left join .. on .. where .. union all select aa from bb_2018_10_02 left join ... on .. left join .. on .. where .. union all select aa from bb_2018_10_03 left join ... on .. left join .. on .. where .. union all select aa from bb_2018_10_04 left join ... on .. left join .. on .. where ..
위 sql을 여러 sql로 분해해서 실행하고, 최종적으로 데이터를 요약하면 결국 20초정도 빨라집니다.
select aa from bb_2018_10_01 left join ... on .. left join .. on .. where ..
select aa from bb_2018_10_02 left join ... on .. left join .. on .. where ..
분해된 SQL을 비동기적으로 실행
Java 비동기 프로그래밍의 연산을 이용하여 분해된 SQL을 비동기적으로 실행하고 최종적으로 데이터를 요약합니다. 여기서는 CountDownLatch와 ExecutorService를 사용했습니다.
// 获取时间段所有天数
List<String> days = MyDateUtils.getDays(requestParams.getStartTime(), requestParams.getEndTime());
// 天数长度
int length = days.size();
// 初始化合并集合,并指定大小,防止数组越界
List<你想要的数据类型> list = Lists.newArrayListWithCapacity(length);
// 初始化线程池
ExecutorService pool = Executors.newFixedThreadPool(length);
// 初始化计数器
CountDownLatch latch = new CountDownLatch(length);
// 查询每天的时间并合并
for (String day : days) {
Map<String, Object> param = Maps.newHashMap();
// param 组装查询条件
pool.submit(new Runnable() {
@Override
public void run() {
try {
// mybatis查询sql
// 将结果汇总
list.addAll(查询结果);
} catch (Exception e) {
logger.error("getTime异常", e);
} finally {
latch.countDown();
}
}
});
}
try {
// 等待所有查询结束
latch.await();
} catch (InterruptedException e) {
e.printStackTrace();
}
// list为汇总集合
// 如果有必要,可以组装下你想要的业务数据,计算什么的,如果没有就没了
결과는 20~30초 빨라졌습니다
MySQL 구성 최적화
다음은 제 구성 예입니다. 4~5초 더 빠른 이름 건너뛰기 해결을 추가했습니다. 기타 구성은 직접 결정
[client] port=3306 [mysql] no-beep default-character-set=utf8 [mysqld] server-id=2 relay-log-index=slave-relay-bin.index relay-log=slave-relay-bin slave-skip-errors=all #跳过所有错误 skip-name-resolve port=3306 datadir="D:/mysql-slave/data" character-set-server=utf8 default-storage-engine=INNODB sql-mode="STRICT_TRANS_TABLES,NO_AUTO_CREATE_USER,NO_ENGINE_SUBSTITUTION" log-output=FILE general-log=0 general_log_file="WINDOWS-8E8V2OD.log" slow-query-log=1 slow_query_log_file="WINDOWS-8E8V2OD-slow.log" long_query_time=10 # Binary Logging. # log-bin # Error Logging. log-error="WINDOWS-8E8V2OD.err" # 整个数据库最大连接(用户)数 max_connections=1000 # 每个客户端连接最大的错误允许数量 max_connect_errors=100 # 表描述符缓存大小,可减少文件打开/关闭次数 table_open_cache=2000 # 服务所能处理的请求包的最大大小以及服务所能处理的最大的请求大小(当与大的BLOB字段一起工作时相当必要) # 每个连接独立的大小.大小动态增加 max_allowed_packet=64M # 在排序发生时由每个线程分配 sort_buffer_size=8M # 当全联合发生时,在每个线程中分配 join_buffer_size=8M # cache中保留多少线程用于重用 thread_cache_size=128 # 此允许应用程序给予线程系统一个提示在同一时间给予渴望被运行的线程的数量. thread_concurrency=64 # 查询缓存 query_cache_size=128M # 只有小于此设定值的结果才会被缓冲 # 此设置用来保护查询缓冲,防止一个极大的结果集将其他所有的查询结果都覆盖 query_cache_limit=2M # InnoDB使用一个缓冲池来保存索引和原始数据 # 这里你设置越大,你在存取表里面数据时所需要的磁盘I/O越少. # 在一个独立使用的数据库服务器上,你可以设置这个变量到服务器物理内存大小的80% # 不要设置过大,否则,由于物理内存的竞争可能导致操作系统的换页颠簸. innodb_buffer_pool_size=1G # 用来同步IO操作的IO线程的数量 # 此值在Unix下被硬编码为4,但是在Windows磁盘I/O可能在一个大数值下表现的更好. innodb_read_io_threads=16 innodb_write_io_threads=16 # 在InnoDb核心内的允许线程数量. # 最优值依赖于应用程序,硬件以及操作系统的调度方式. # 过高的值可能导致线程的互斥颠簸. innodb_thread_concurrency=9 # 0代表日志只大约每秒写入日志文件并且日志文件刷新到磁盘. # 1 ,InnoDB会在每次提交后刷新(fsync)事务日志到磁盘上 # 2代表日志写入日志文件在每次提交后,但是日志文件只有大约每秒才会刷新到磁盘上 innodb_flush_log_at_trx_commit=2 # 用来缓冲日志数据的缓冲区的大小. innodb_log_buffer_size=16M # 在日志组中每个日志文件的大小. innodb_log_file_size=48M # 在日志组中的文件总数. innodb_log_files_in_group=3 # 在被回滚前,一个InnoDB的事务应该等待一个锁被批准多久. # InnoDB在其拥有的锁表中自动检测事务死锁并且回滚事务. # 如果你使用 LOCK TABLES 指令, 或者在同样事务中使用除了InnoDB以外的其他事务安全的存储引擎 # 那么一个死锁可能发生而InnoDB无法注意到. # 这种情况下这个timeout值对于解决这种问题就非常有帮助. innodb_lock_wait_timeout=30 # 开启定时 event_scheduler=ON
비즈니스에 따라 필터 조건 추가
빠른 4-5s
시간 조건을 제외한 where 조건의 필드에 대한 공동 인덱스 생성
효과는 없음 너무 당연한
replace where 조건의 인덱스 조건이 내부 조인 방식을 사용하여 연관되어 있습니다
이 점에 매우 놀랐습니다. 원본 SQL, b는 인덱스
select aa from bb_2018_10_02 left join ... on .. left join .. on .. where b = 'xxx'
입니다. 이전에 Union all이 있어야 하며, Union All이 하나씩 실행되어 최종 요약 결과가 얻어집니다.
select aa from bb_2018_10_02 left join ... on .. left join .. on .. inner join
(
select 'xxx1' as b2
union all
select 'xxx2' as b2
union all
select 'xxx3' as b2
union all
select 'xxx3' as b2
) t on b = t.b2
로 수정됨 결과는 3~4초 빨라졌습니다
성능 병목 현상
위 작업에 따르면 쿼리 효율성은 3일 만에 약 8초에 도달했으며 더 이상 더 빠를 수 없습니다. MySQL의 CPU 사용량과 메모리 사용량은 그리 높지 않습니다. 쿼리가 왜 이렇게 느린가요? 3일에 최대 데이터 수는 600,000개인데, 일부 사전 테이블과 관련된 데이터이므로 이렇지는 않습니다. 인터넷에서 제공되는 정보에 계속 의존하여 일련의 섹시한 작업은 기본적으로 쓸모가 없으며 방법이 없습니다.
환경 비교
SQL 최적화를 분석해 보니 이미 괜찮습니다. 디스크 읽기 및 쓰기 문제라면 상상해 보세요. 다양한 현장 환경에 최적화된 프로그램을 배포합니다. 하나는 ssd가 있고 하나는 ssd가 없습니다. 쿼리 효율성이 매우 다른 것으로 나타났습니다. 소프트웨어로 테스트한 결과 SSD의 읽기 및 쓰기 속도는 700-800M/s이고 일반 기계식 하드 디스크의 읽기 및 쓰기 속도는 70-80M/s인 것으로 나타났습니다.
최적화 결과 및 결론
최적화 결과: 기대에 부응합니다.
최적화 결론: SQL 최적화는 SQL 자체의 최적화일 뿐만 아니라 자체 하드웨어 조건, 다른 애플리케이션의 영향, 자체 코드 최적화에 따라 달라집니다.
위 내용은 이 기사의 전체 내용입니다. Java에 대한 더 흥미로운 정보를 보려면 PHP 중국어 웹사이트의 Java Video Tutorial 및 Java Development Tutorial 칼럼을 참조하세요. ! !
위 내용은 javaweb의 테이블 쿼리에 대한 SQL 최적화 소개의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!