
JDK 스레드 풀의 분석 및 사용을 이해하는 데 도움이 되는 기사입니다.

- 无忌哥哥원래의
- 2018-07-20 10:24:121531검색
1. 스레드 풀을 사용하는 이유
멀티 스레드 프로그래밍에서 매우 중요한 기능은 작업을 실행하는 방법이 많습니다. 스레드 풀을 사용해야 하는 이유는 무엇입니까? 아래에서는 소켓 프로그래밍 기능을 사용하여 요청을 처리하고 작업 수행의 각 방법을 분석합니다.
1.1 작업의 직렬 실행
소켓은 클라이언트에 연결이 있는지 모니터링할 때 handlerSocket 메서드를 통해 각 클라이언트 연결을 순차적으로 처리합니다. 처리가 완료되면 계속해서 대기합니다. 코드는 다음과 같습니다.
ServerSocket serverSocket = new ServerSocket();
SocketAddress endpoint = new InetSocketAddress(host, port);
serverSocket.bind(endpoint,1023);
while (!isStop) {
Socket socket = serverSocket.accept();
handleSocket(socket);
}이 방법의 단점은 매우 분명합니다. 여러 클라이언트 요청이 있을 때 서버가 하나의 요청을 처리하는 동안 다른 요청은 이전 요청이 처리될 때까지 기다려야 합니다. 동시성이 높은 상황에서는 거의 사용할 수 없습니다.
1.2 각 작업에 대한 스레드 만들기
위 문제 최적화: 요청을 처리하기 위해 각 클라이언트 요청에 대한 스레드를 만듭니다. 메인 스레드는 스레드를 생성한 후 계속해서 클라이언트 요청을 처리하면 됩니다. 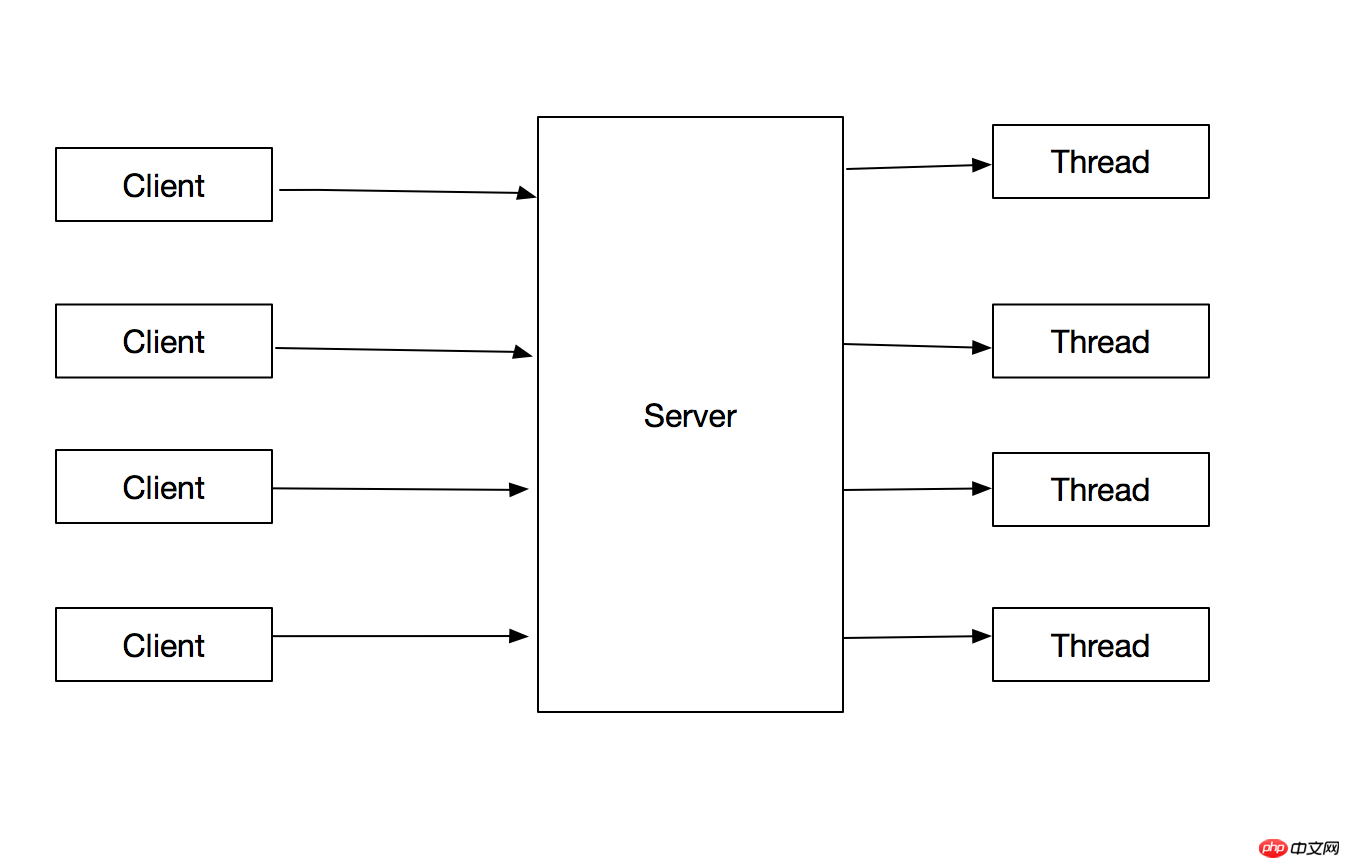
코드는 다음과 같습니다.
ServerSocket serverSocket = new ServerSocket();
SocketAddress endpoint = new InetSocketAddress(host, port);
serverSocket.bind(endpoint,1023);
while (!isStop) {
Socket socket = serverSocket.accept();
new SocketHandler(socket, THREAD_NAME_PREFIX + threadIndex++).start();
}이 방법에는 다음과 같은 장점이 있습니다.
1.메인 스레드에서 클라이언트 연결 처리 작업을 분리하여 메인 루프가 다음 요청에 더 빠르게 응답할 수 있습니다. .
2. 클라이언트 연결 처리 작업은 병렬이므로 프로그램 처리량이 향상됩니다.
그러나 이 방법에는 다음과 같은 단점이 있습니다.
1. 요청을 처리하는 스레드는 스레드로부터 안전해야 합니다.
2 스레드 생성 및 소멸에는 많은 수의 스레드가 생성될 때 많은 양의 오버헤드가 필요합니다. 컴퓨터 리소스가 소모됩니다
3. 사용 가능한 CPU 수가 실행 가능한 스레드 수보다 적으면 추가 스레드가 메모리 리소스를 차지하고 가비지 수집에 부담을 주며 많은 수의 스레드가 발생하면 큰 영향을 미칩니다. 스레드는 CPU 리소스를 놓고 경쟁합니다.
4. JVM에서 생성할 수 있는 스레드 수에는 상한이 있으며, 이 상한은 플랫폼에 따라 다르며 시작 매개변수를 포함한 여러 요인에 의해 제한됩니다. JVM, 각 스레드가 차지하는 메모리 크기 등. 이러한 제한을 초과하면 OOM 예외가 발생합니다.
1.3 스레드 풀을 사용하여 클라이언트 요청 처리
1.2의 문제에 대해 가장 좋은 해결책은 스레드 풀을 사용하여 작업을 실행하는 것입니다. 이렇게 하면 생성되는 총 스레드 수를 제한하고 1.2의 문제를 피할 수 있습니다. 흐름도는 다음과 같습니다. 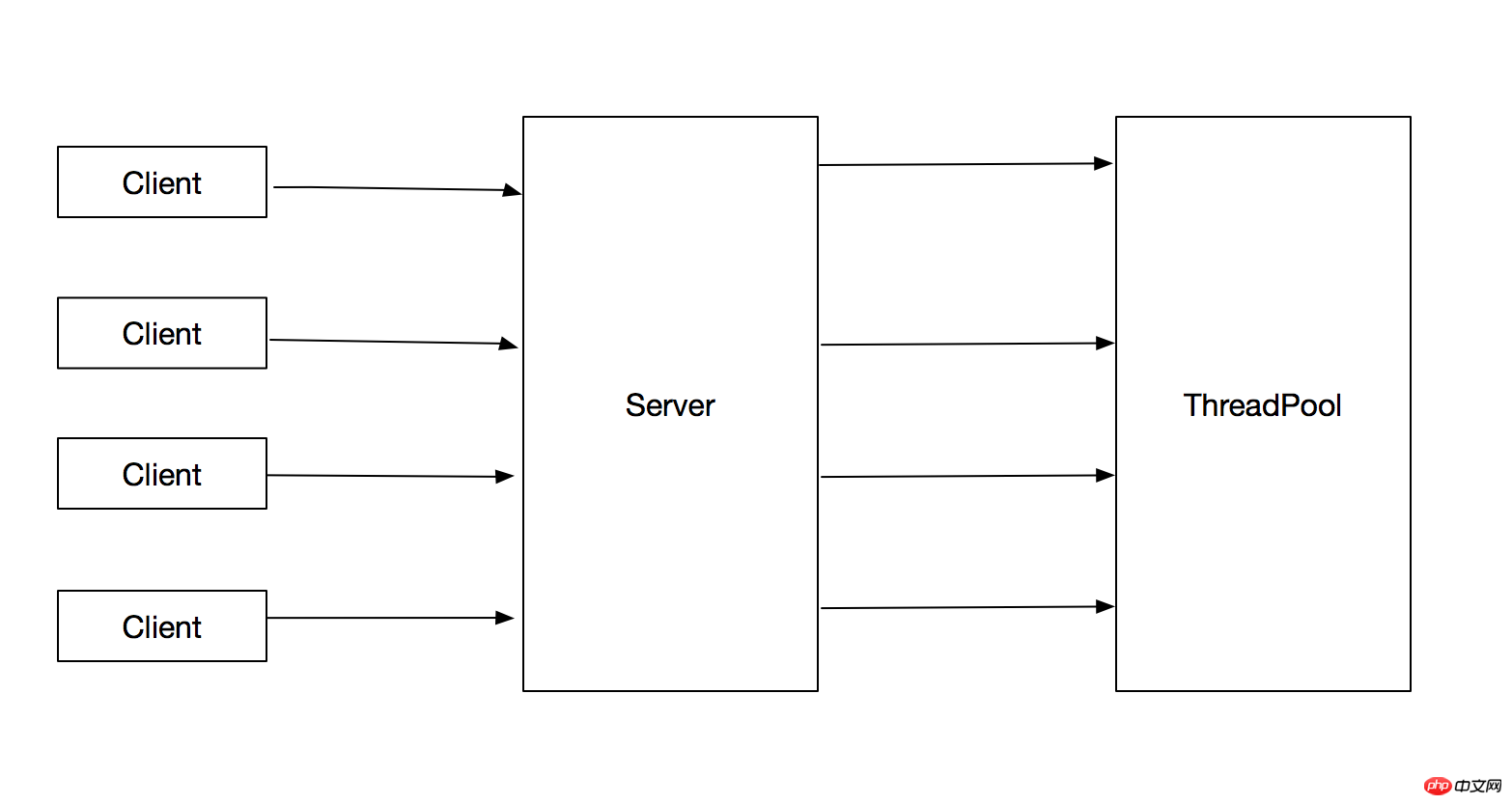
처리 방법은 다음과 같습니다.
ServerSocket serverSocket = new ServerSocket();
SocketAddress endpoint = new InetSocketAddress(host, port);
serverSocket.bind(endpoint,1023);
while (!isStop) {
Socket socket = serverSocket.accept();
executorService.execute(new SocketHandler(socket, THREAD_NAME_PREFIX + threadIndex++));
}이 방법의 장점은 다음과 같습니다.
1. 작업 제출과 작업 실행이 분리됩니다
2. 재사용되어 스레드 생성 및 소멸 오버헤드를 줄이는 동시에 작업이 도착하면 생성된 스레드를 직접 사용하여 작업을 실행할 수 있으므로 프로그램의 응답 속도도 향상됩니다.
2. Java의 스레드 풀 소개
Java의 스레드 풀 구현은 생산자-소비자 모델을 기반으로 합니다. 스레드 풀의 기능은 작업 제출 프로세스를 분리합니다. 생산자이고, 작업을 실행하는 과정이 소비 과정입니다. 구체적인 분석은 소스 코드 분석을 참조하세요. Java 스레드 풀의 최상위 인터페이스는 Executor입니다. 소스 코드는 다음과 같습니다.
public interface Executor {
void execute(Runnable command);
}이 인터페이스는 모든 스레드 풀에서 구현되는 최상위 인터페이스이며 허용되는 작업 유형은 Runnable 구현 클래스라고 규정합니다. 그러나 작업의 특정 실행 논리는 스레드 풀에 의해 구현됩니다. 예를 들어 클래스를 직접 정의하세요.
메인 스레드를 사용하여 작업을 순차적으로 실행할 수 있습니다.
각 작업에 대해 새 스레드를 생성할 수도 있습니다.
스레드 풀의 실행 전략에는 주로 다음과 같은 측면이 포함됩니다.
1. task
2. 작업 실행 순서(FIFO, LIFO, 우선 순위?)
3. 예 동시에 실행할 수 있는 작업 수
4. 대기열에서 실행을 대기할 수 있는 최대 작업 수
5. 대기 대기열이 최대값에 도달하면 새로 제출된 작업을 거부하는 방법
6. 작업 실행 전이나 후에 어떤 작업을 수행해야 합니까?
특정 사업에 따라 다양한 실행 전략을 선택해야 합니다. Executors 도구 클래스는 기본 전략 스레드 풀을 사용하기 위해 Java 클래스 라이브러리에 제공됩니다. 주로 다음과 같은 인터페이스가 있습니다:
public static ExecutorService newFixedThreadPool(int nThreads) 将会创建一个固定大小的线程池,每当有新任务提交的时候,当线程总数没有达到核心线程数的时候,为每个任务创建一个新线程,当线程的个数到达最大值后,重用之前创建的线程,当线程因为未知异常而停止时候,将会重现创建一个线程作为补充。 public static ExecutorService newCachedThreadPool() 根据需求创建线程的个数,当线程数大于任务数的时候,将会注销多余的线程 public static ExecutorService newSingleThreadExecutor() 创建一个单线程的线程池 public static ScheduledExecutorService newScheduledThreadPool(int corePoolSize) 创建一个可执行定时任务的线程池
위의 예에서 제출된 모든 작업의 실행 상태는 스레드 풀에 제출된 후에 보이지 않습니다. 즉, 메인 스레드는 제출된 작업이 실행을 완료했는지 또는 실행을 완료했는지 알 수 없습니다. 결과. 이 문제를 해결하기 위해 Java는 데이터를 반환할 수 있는 작업 인터페이스 Future 및 Callable 인터페이스를 제공합니다.
Callable 인터페이스는 작업에서 데이터를 반환하고 예외를 발생시키는 기능을 제공하며 다음과 같이 정의됩니다.
public interface Callable<V> {
V call() throws Exception;
}ExecutorService의 모든 제출 메서드는 Future 객체를 반환하며 해당 인터페이스는 다음과 같이 정의됩니다.
public interface Future<V> {
取消任务执行,当mayInterruptIfRunning为true,interruptedthisthread
boolean cancel(boolean mayInterruptIfRunning);
返回此任务是否在执行完毕之前被取消执行
boolean isCancelled();
返回此任务是否已经完成,包括正常结束,异常结束以及被cancel
boolean isDone();
返回执行结果,当任务没有执行结束的时候,等待
V get() throws InterruptedException, ExecutionException;
}3.使用线程池可能出现的问题
1.线程饥饿死锁
在单线程的Executor中,如果Executor中执行的一个任务中,再次提交任务到同一个Executor中,并且等待这个任务执行完毕,那么就会发生死锁问题。如下demo中所示:
public class ThreadDeadLock {
private static final ExecutorService EXECUTOR_SERVICE = Executors.newSingleThreadExecutor();
public static void main(String[] args) throws Exception {
System.out.println("Main Thread start.");
EXECUTOR_SERVICE.submit(new DeadLockThread());
System.out.println("Main Thread finished.");
}
private static class DeadLockThread extends Thread{
@Override
public void run() {
try {
System.out.println("DeadLockThread start.");
Future future = EXECUTOR_SERVICE.submit(new DeadLockThread2());
future.get();
System.out.println("DeadLockThread finished.");
} catch (Exception e) {
}
}
}
private static class DeadLockThread2 extends Thread {
@Override
public void run() {
try {
System.out.println("DeadLockThread2 start.");
Thread.sleep(1000 * 10);
System.out.println("DeadLockThread2 finished.");
} catch (Exception e) {
}
}
}
}输出结果为:
Main Thread start. Main Thread finished. DeadLockThread start.
对于多个线程的线程池,如果所有正在执行的线程都因为等待处于工作队列中的任务执行而阻塞,那么就会发生线程饥饿死锁。
当往线程池中提交有依赖的任务时,应清楚的知道可能会出现的线程饥饿死锁风险。==应考虑是否将依赖的task提交到不同的线程池中==
或者使用无界的线程池。
==只有当任务相对独立时,设置线程池大小和工作队列的大小才是合理的,否则有可能会出现线程饥饿死锁==
2.任务运行时间过长
任务执行时间过长会影响线程池的响应时间,当运行时间长的任务远大于线程池线程的个数时,会出现所有线程都在执行运行时间长的任务,从而影响对其他任务的响应。
解决办法:
1.通过限定任务等待的时长,而不要无限期等待下去,当等待超时的时候,可以将任务标记为失败,或者重新放到线程池中。
2.当线程池中阻塞任务过多的时,应该考虑扩大线程池的大小
4.线程池大小的设置
线程池的大小依赖于提交任务的类型以及服务器的可用资源,线程池的大小应该避免设置过大或者过小,当线程设置过打的时候可能会有资源耗尽的风险,线程池设置过小会有可用cpu空闲从而影响系统吞吐量。
影响线程池大小的资源有很多,比如CPU、内存、数据库链接池等,只需要计算资源可用总资源 / 每个任务需要的资源,取最小值,即可得出线程池的上限。
线程池的最小值应该大于可用的CPU数量。
4.java中常用线程池源码分析-ThreadPoolExecutor
ThreadPoolExecutor线程池是比较常用的一个线程池实现类,通过Executors工具类创建的线程池中,其具体实现类是ThreadPoolExecutor。首先我们可以看下ThreadPoolExecutor的构造函数如下:
public ThreadPoolExecutor(
int corePoolSize,
int maximumPoolSize,
long keepAliveTime,
TimeUnit unit,
BlockingQueue<Runnable> workQueue,
ThreadFactory threadFactory,
RejectedExecutionHandler handler)下面分别对构造函数中的各个参数对应的策略进行分析:
1.线程的创建与销毁
首先构造函数中corePoolSize、maximumPoolSize、keepAliveTime和unit参数影响线程的创建和销毁。其中corePoolSize为核心线程数,当第一次提交任务的时候如果正在执行的线程数小于corePoolSize,则新建一个线程执行task,如果已经超过corePoolSize,则将任务放到任务队列中等待执行。当任务队列的个数到达上限的时候,并且工作线程数量小于maximumPoolSize,则继续创建线程执行工作队列中的任务。当任务的个数小于maximumPoolSize的时候,将会把空闲的线程标记为可回收的垃圾线程。对于以下代码段测试此功能:
public class ThreadPoolTest {
private static ThreadPoolExecutor executorService = new ThreadPoolExecutor(3, 6,100, TimeUnit.SECONDS, new LinkedBlockingQueue<>(3));
public static void main(String[] args) throws Exception {
for (int i = 0; i< 9; i++) {
executorService.submit(new Task());
System.out.println("Active thread:" + executorService.getActiveCount() + ".Task count:" + executorService.getTaskCount() + ".TaskQueue size:" + executorService.getQueue().size());
}
}
private static class Task extends Thread {
@Override
public void run() {
try {
Thread.sleep(1000 * 100);
} catch (Exception e) {
}
}
}
}输出结果为:
Active thread:1.Task count:1.TaskQueue size:0 Active thread:2.Task count:2.TaskQueue size:0 Active thread:3.Task count:3.TaskQueue size:0 Active thread:3.Task count:4.TaskQueue size:1 Active thread:3.Task count:5.TaskQueue size:2 Active thread:3.Task count:6.TaskQueue size:3 Active thread:4.Task count:7.TaskQueue size:3 Active thread:5.Task count:8.TaskQueue size:3 Active thread:6.Task count:9.TaskQueue size:3
2.任务队列
在ThreadPoolExecutor的构造函数中可以传入保存任务的队列,当新提交的任务没有空闲线程执行时候,会将task保存到此队列中。保存的顺序是根据插入的顺序或者Comparator来排序的。
3.饱和策略
ThreadPoolExecutor.AbortPolicy 抛出RejectedExecutionException ThreadPoolExecutor.CallerRunsPolicy 将任务的执行交给调用者,即将本该异步执行的任务变成同步执行。
4.线程工厂
当线程池需要创建线程的时候,默认是使用线程工厂方法来创建线程的,通常情况下我们通过指定线程工厂的方式来为线程命名,便于出现线程安全问题时候来定位问题。
5.线程池最佳实现
1.项目中所有的线程应该都有线程池来提供,不允许自行创建线程
2.尽量不要用Executors来创建线程,而是使用ThreadPoolExecutor来创建
Executors有以下问题:
1)FixedThreadPool 和 SingleThreadPool: 允许的请求队列长度为 Integer.MAX_VALUE,可能会堆积大量的请求,从而导致 OOM。 2)CachedThreadPool 和 ScheduledThreadPool: 允许的创建线程数量为 Integer.MAX_VALUE,可能会创建大量的线程,从而导致 OOM。
위 내용은 JDK 스레드 풀의 분석 및 사용을 이해하는 데 도움이 되는 기사입니다.의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!