
집 >데이터 베이스 >MySQL 튜토리얼 >편집기는 SQL Server 인덱스의 원리에 대한 심층 분석을 안내합니다.
편집기는 SQL Server 인덱스의 원리에 대한 심층 분석을 안내합니다.

- 无忌哥哥원래의
- 2018-07-12 14:11:262476검색
사실 인덱스는 특별한 디렉터리로 이해할 수 있습니다. 다음 글에서는 주로 SQL Server 인덱스의 원리에 대한 관련 정보를 소개하고 있는데, 샘플 코드를 통해 자세히 소개하고 있어 모두의 학습에 큰 도움이 됩니다. 아니면 꼭 참고하고 학습할 가치가 있는 작품이 있다면 편집자를 따라가서 함께 배워보세요
Preface#🎜 🎜 #
이 기사는 관련 데이터베이스 지식을 논의하기 위한 시작점으로 색인을 사용하여 이전 노트를 편집한 것입니다(사람들이 더 쉽게 소화할 수 있도록 수정되었습니다). SQL Server를 처음 사용하는 친구는 다음Blue 글꼴을 읽으면 됩니다. 이는 간단하고 시간을 절약하는 데 유용합니다. 데이터베이스 기반이 좋은 친구라면 모두 읽고 환영할 것입니다. 토론하다.
인덱스의 개념
1. 클러스터형 인덱스와 비클러스터형 인덱스
인덱스는 다음과 같이 구분됩니다. 클러스터형 인덱스 및 비클러스터형 인덱스 비클러스터형 인덱스 1.1 클러스터형 인덱스
테이블의 데이터는 다음 위치에 저장됩니다. 데이터 페이지(데이터 페이지의 PageType이 1로 표시됨), SqlServer의 한 페이지는 8k이고, 한 페이지가 가득 차면 저장소의 다음 페이지가 열립니다.테이블에 클러스터형 인덱스가 있는 경우 물리적 데이터는 클러스터형 인덱스 필드의 크기에 따라 오름차순/내림차순으로 페이지에 하나씩 저장됩니다. 클러스터형 인덱스 필드가 업데이트되거나 중간에 데이터가 삽입/삭제되는 경우 오름차순/내림차순 정렬을 유지해야 하기 때문에 테이블 데이터가 이동됩니다(성능에 어느 정도 영향을 끼침).
#🎜🎜 #
페이징 및 인덱스 조각화를 줄이려면 항상 끝에 레코드를 추가하세요.
(B) 변경 불가
데이터 이동을 줄입니다.
(C). Uniqueness
Uniqueness는 모든 인덱스의 가장 이상적인 기능으로, 인덱스 키 값의 위치를 명확히 할 수 있습니다. 정렬 .
더 중요한 것은 인덱스 키가 고유한 경우 각 레코드의 소스 데이터 행 RID를 올바르게 가리킬 수 있다는 것입니다. 클러스터형 인덱스 키 값이 고유하지 않은 경우 SqlServer는 내부적으로 "키 값"의 고유성을 보장하기 위해 고유화자 열 조합을 클러스터형 키로 생성해야 하며, 비클러스터형 인덱스 키 값이 고유하지 않은 경우 RID 열( 클러스터형 인덱스 키 또는 힙 테이블)이 추가되어 "키 값"의 고유성을 보장합니다.
생각하기(건너뛸 수 있음): 인덱스 "키 값"은 리프가 아닌 노드에서도 고유함을 보장합니다. 그 이유는 인덱스 레코드의 위치를 명확히 하기 위한 것입니다. 리프가 아닌 노드. 예를 들어, 비클러스터형 인덱스 필드 Name2가 테이블에 Name2='a'인 레코드가 많으므로 현재 리프가 아닌 노드에 여러 인덱스 레코드(노드)가 있습니다. , Name2=' a' 레코드를 삽입하면 리프가 아닌 노드의 RID와 새 레코드의 RID를 기반으로 삽입할 인덱스 레코드(노드)를 빠르게 결정할 수 있습니다. , 모든 Name2='를 순회해야 합니다. a'의 리프 노드만 위치를 결정할 수 있습니다. 또한 Name2
"키 값" 고유성의 경우 클러스터형 인덱스의 경우 고유화자 열은 인덱스 값이 반복될 때만 증가됩니다. 비클러스터형 인덱스의 경우 인덱스 생성 시 고유성을 정의하지 않으면 인덱스 값이 고유하더라도 모든 레코드에서 RID가 증가합니다. 인덱스 생성 시 고유성이 정의되어 있으면 RID는 리프 수준에서만 증가합니다. , 즉, 북마크 찾기 작업에 사용됩니다.
(D). 작은 필드 길이
클러스터형 인덱스 키 길이가 작을수록 하나의 인덱스 페이지는 더 많은 인덱스 레코드를 수용할 수 있으므로 인덱스 B-트리 구조의 깊이가 줄어듭니다. 예를 들어, 수백만 개의 레코드가 있는 테이블에는 int 클러스터형 인덱스가 있으며 3레벨 B-트리 구조만 필요할 수 있습니다. 클러스터형 인덱스가 더 넓은 열에 정의된 경우(예: Uniqueidentifier 열에는 16바이트가 필요함) 인덱스 깊이는 4단계로 증가합니다. 모든 클러스터형 인덱스 조회에는 3개의 I/O 작업이 아닌 4개의 I/O 작업(정확히 말하면 4개의 논리적 읽기)이 필요합니다.
마찬가지로 비클러스터형 인덱스에는 클러스터형 인덱스 키 값이 포함됩니다. 클러스터형 인덱스 키 길이가 작을수록 하나의 인덱스 페이지는 더 많은 인덱스 레코드를 수용할 수 있습니다.
1.2 비클러스터형 인덱스
도 페이지에 저장됩니다(PageType 2로 표시된 페이지를 인덱스 페이지라고 함). 예를 들어 테이블 T는 비클러스터형 인덱스 Index_A를 설정했습니다. 테이블 T에 100개의 데이터가 있으면 인덱스 Index_A에도 100개의 데이터(정확히 말하면 100개의 리프 노드 데이터)가 있습니다. 인덱스는 B입니다. - 트리 구조의 경우, 높이가 0보다 크면 루트 노드 페이지 또는 중간 노드 페이지 데이터가 있고 이때 인덱스 데이터가 100을 초과하는 경우) 테이블 T에도 비클러스터형 인덱스 Index_B가 있는 경우 그러면 Index_B에도 최소 100개의 데이터가 있으므로 인덱스를 구축하는 데 드는 오버헤드가 커집니다.
인덱스 필드 업데이트, 데이터 삽입 또는 데이터 삭제는 인덱스 유지 관리를 유발하고 성능에 일정한 영향을 미칩니다. 상황에 따라 성능에 미치는 영향도 다릅니다. 예를 들어, 클러스터형 인덱스의 경우 삽입된 데이터가 모두 끝에 있으므로 데이터 이동이 거의 발생하지 않으며 영향이 적습니다. 삽입된 데이터가 중간에 있으면 일반적으로 데이터 이동이 발생하고 발생할 수 있습니다. 페이징 및 페이징이 발생하면 영향이 약간 더 커집니다. (삽입된 중간 페이지에 삽입된 데이터를 수용할 수 있는 공간이 충분하고 위치가 페이지 끝에 있으면 데이터 이동이 발생하지 않습니다.)
2. 인덱스 구조
SqlServer의 인덱스는 B-트리 구조라고 하는데(B-트리 구조에 대해 어느 정도 이해하고 있다고 가정) 어떻게 생겼나요? SQL 문을 사용하여 논리적 표현을 볼 수 있습니다.
새 쿼리 실행 구문: DBCC IND(Test,OrderBo,-1) --테스트 라이브러리의 OrderBo 테이블에는 10,000개의 데이터 조각이 있고 클러스터형 인덱스 ID 기본 키 필드가 있습니다
( 테이블을 직접 클러스터링 인덱스 필드에 10,000개의 테이블 데이터를 삽입한 후 이 구문을 실행해 보면 많은 이득을 얻을 수 있으므로 한 번 보는 것이 좋습니다)
실행 결과:
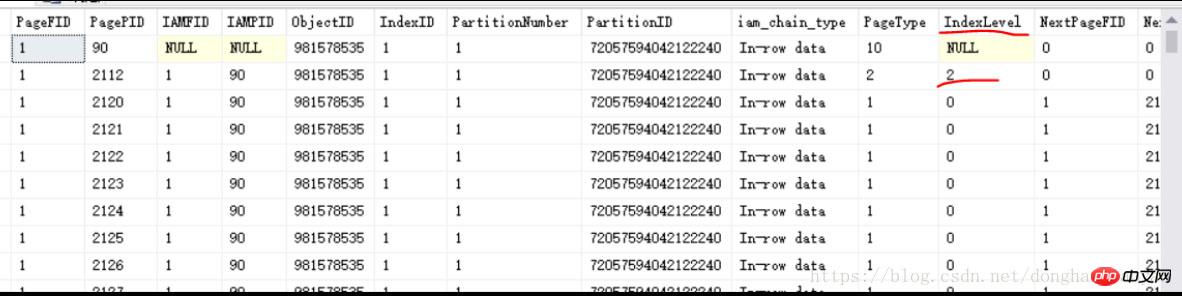
위와 같이 , IndexLevel=2 2112인 인덱스 페이지가 표시됩니다(여기서는 B-트리의 루트 노드입니다. 가장 큰 IndexLevel은 루트 노드이고 아래에는 하위 수준, 하위 하위 수준...이 있습니다. B-트리 구조의 액세스 진입점으로 하나의 루트 페이지만 있음) 이는 IndexLevel=1 인덱스 페이지 및 IndexLevel=0 리프 페이지가 있어야 함을 나타냅니다. Clustered Index이기 때문에 IndexLevel=0일 때의 리프 페이지는 물리적인 데이터를 하나씩 저장하는 데이터 페이지이다. 위 그림에서 볼 수 있듯이 IndexLevel=0인 행의 PageType은 1이며, 이는 위의 1.1장에서 클러스터형 인덱스에 대해 말할 때 PageType=1도 언급됩니다. 비클러스터형 인덱스이고 IndexLevel=0 인 리프 페이지이고 PageType은 2와 동일하며 여전히 인덱스 페이지입니다.
마찬가지로 SQL 명령 DBCC PAGE를 사용하여 살펴봅니다.
-- DBCC TRACEON(3604,-1) DBCC PAGE(Test,1,2112,3) --根节点2112,可以查出它的两个子节点2280和2448,然后对这两个子节点再作DBCC PAGE查询 DBCC PAGE(Test,1,2280,3) DBCC PAGE(Test,1,2448,3)

위에 표시된 것처럼 IndexLevel=2인 페이지 2112에는 IndexLevel=1인 두 개의 하위 노드 2280 및 2448이 있습니다. 노드 아래에는 하위 노드가 있으며 각 노드는 서로 다른 인덱스 키 값의 범위를 담당합니다(즉, 위 그림의 "Id(키)" 필드에서 첫 번째 행 값은 Null을 나타냅니다. 최소값 또는 최대값을 역순으로). 이러한 계층적 관계는 B-트리 구조이며, 여기서 IndexLevel은 실제로 B-트리 구조의 높이입니다.
SQLServer는 인덱스에서 특정 레코드를 검색할 때 루트 노드부터 아래쪽으로 리프 노드를 찾습니다. 모든 데이터 주소에 리프 노드가 있기 때문입니다. 이는 실제로 B+ 트리의 특성 중 하나입니다. tree는 리프가 아닌 노드에서 값을 검색하면 직접 반환될 수 있다는 것입니다. 분명히 SqlServer는 이를 확인하기 위해 통계를 활성화하도록 설정한 다음 다음을 선택할 수 있습니다. 논리적 읽기 수를 참조하세요).
리프 노드는 반드시 발견되므로 열을 포함하는 인덱스는 리프 노드에만 기록하면 됩니다. 즉, 리프가 아닌 노드에 대한 포함 열은 기록되지 않습니다. "열을 포함하는 인덱스"에 대해서는 아래 3장을 참조하세요. ".
B+ 트리(모든 데이터 주소에 리프 노드가 있음)의 이 기능은 value1과 value2(리프 노드에서)를 찾은 다음 이를 함께 연결하는 한 value1과 value2 사이의 간격 쿼리에도 도움이 됩니다. 원하는 결과를 얻을 것입니다.
SqlServer의 인덱스 구조는 B+ 트리에 더 가깝습니다. 이는 궁극적으로 B-트리와 B+-트리의 하이브리드 버전이며 데이터 구조는 반드시 순수한 B-트리이거나 아닐 수도 있습니다. 순수한 B+ 트리.
3. 인덱스에 열 포함 및 북마크 검색
인덱스에 관해 SqlServer2005에 추가된 또 다른 "인덱스에 열 포함" 기능이 있는데 이는 매우 실용적입니다.
예를 들어 대규모 보고서의 데이터를 쿼리할 때 where 조건은 인덱스 필드 Name2를 사용하지만 선택할 필드는 Name1입니다. 이때 "인덱스 포함 열"을 사용하여 Name1을 보고서에 포함할 수 있습니다. 인덱스 필드 Name2는 쿼리 성능을 크게 향상시킵니다.
구문: Create [UNIQUE] Nonclustered/Clustered Index IndexName On dbo.Table1(Name2) include(Name1);
다음으로 인덱스 포함 열이 성능을 크게 향상시킬 수 있는 이유를 분석하세요. 계속해서 DBCC PAGE 명령을 사용하여 포함된 열이 있는 비클러스터형 인덱스의 인덱스 데이터를 봅니다.

위 그림에서 볼 수 있듯이 포함된 열 Name1도 인덱스 데이터에 저장됩니다. 따라서 데이터베이스가 인덱스 필드 Name2를 사용하여 검색할 특정 행을 찾을 때 RID를 기반으로 데이터 페이지에서 찾을 필요 없이 Name1의 값을 직접 반환할 수 있습니다(위 그림은 [HEAP RID( Key)] 열) 값을 얻으려면 북마크 검색을 줄여야 합니다. 물론 쿼리에서 데이터가 1개만 반환되고 북마크 검색이 1개만 반환되는 경우에는 문제가 되지 않습니다. 쿼리에서 반환되는 데이터가 큰 경우에는 데이터 페이지로 이동하여 해당 데이터를 찾아 가져와야 합니다. 레코드는 1,000번의 북마크 검색을 의미합니다. 성능 소모가 매우 크다는 것을 상상할 수 있습니다. 이때 "인덱스에 열이 포함되어 있습니다"라는 값이 크게 반영됩니다.
북마크 검색의 경우 테이블에 클러스터형 인덱스(예: Id)가 있는 경우 클러스터형 인덱스 키 Id를 사용하여 Id=1인 Table1에서 Select Name1을 실행하여 검색하는 것과 유사합니다(검색 방법은 인덱스 Id의 B-트리 구조 검색, 클러스터형 인덱스가 없는 테이블의 경우 데이터 행 포인터("파일 번호 2byte: 페이지 번호 4byte: 슬롯 번호 2byte"로 구성)를 기준으로 검색합니다. 클러스터형 인덱스 키와 행 포인터는 일반적으로 RID(행 ID) 포인터라고 합니다. 여기서 우리는 다음과 같이 생각할 수 있습니다. 테이블에 좋은 클러스터형 인덱스 필드가 없으면 자체 성장하는 Id 필드를 클러스터형 인덱스의 기본 키로 사용하는 것이 좋습니다(중복 Id 필드도 허용됨). 자체 성장, 불변, 고유성과 일치하는 작은 길이 특성은 클러스터형 인덱스에 적합한 선택입니다.
자체 증가 ID는 대부분의 경우에 적용 가능하며 특별한 경우에는 특정 요구 사항에 따라 다릅니다. 자체 증가하는 ID에도 고려해야 할 결함이 있습니다. 테이블에 많은 양의 데이터가 포함된 레코드를 동시에 삽입할 경우 각 스레드가 마지막 페이지까지 삽입해야 하며 경쟁과 대기가 발생할 수 있습니다. 이러한 상황을 해결하기 위해 고유 식별자 유형 필드(16바이트, 사용을 권장하지 않음) 또는 해시 파티셔닝(즉, 하나의 테이블을 여러 테이블로 나누는 것, 빅데이터 처리에서는 데이터베이스와 테이블을 나누는 것이 일반적임)을 사용할 수 있습니다. , 등. 그러나 간단하고 안정적이며 효율적인 자체 증가 ID 방법을 유지하기 위해 먼저 삽입 효율성을 최적화하고(삽입 성능 자체가 매우 빠릅니다) 초당 동시 삽입 수가 프로덕션 환경을 충족하는지 테스트하는 것이 좋습니다.
자체 증가 ID가 반드시 데이터베이스에서 제공하는 자체 증가 ID를 사용한다는 의미는 아닙니다. 동시 상황에서도 고유한 ID를 생성하는 자체 알고리즘을 작성할 수도 있습니다(이 경우 일반적인 길이는 다음과 같습니다). bitint, 8바이트 정수) 이 경우 적합한 시나리오는 분산 데이터베이스에서 마스터-슬레이브 복제 중에 Id 필드가 실수해서는 안 되는 상황입니다(마스터-슬레이브 복제의 일반 모드에서는 마스터 데이터베이스의 Id). 마스터 데이터베이스에 따라 증가하고 슬레이브 데이터베이스의 ID도 슬레이브 데이터베이스 자체에 따라 증가합니다. 마스터-슬레이브 복제가 동기화되지 않는 교착 상태 또는 기타 이유가 있는 경우 해당 ID의 ID는 다음과 같습니다. 슬레이브 라이브러리는 증가하므로 메인 라이브러리의 ID와 일치하지 않습니다. 자체 증가 ID가 중복 기본 키인 경우 마스터-슬레이브 데이터베이스 ID가 숫자와 일치하지 않아도 아무런 영향을 미치지 않습니다.
그리고 위 그림의 마지막 열 [Row Size]도 인덱스 열의 크기나 열이 포함된 인덱스의 크기가 너무 길면 안 된다는 점을 알려줍니다. 그렇지 않으면 한 페이지에 여러 개의 레코드를 수용할 수 없기 때문에 인덱스 페이지 수가 늘어나고 인덱스 데이터가 차지하는 공간도 크게 늘어났습니다.
위 내용은 편집기는 SQL Server 인덱스의 원리에 대한 심층 분석을 안내합니다.의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!