
PHP를 사용하여 문서의 이미지를 구문 분석하는 방법

- 不言원래의
- 2018-07-10 11:22:441989검색
이 글은 주로 PHP에서 단어를 파싱하고 문서에서 그림을 얻는 것에 대해 소개합니다. 이제 특정 참조 가치가 있습니다. 필요한 친구들이 참조할 수 있습니다.
Background
몇 가지 기능을 작성하고 있었습니다. 얼마 전: 기본 PHP를 사용하여 단어로 된 콘텐츠를 얻고 웹사이트 시스템으로 가져옵니다. 문서에는 수식, 그림, 표 등이 있기 때문에 글쓰기가 더 번거롭습니다.
Idea
일반적인 아이디어는 먼저 Word의 doc 형식의 문서를 docx로 변환하고, 전처리 프로그램을 사용하여 문서의 수식을 swf 이미지 형식으로 변환하고, word를 xml 형식으로 변환한 다음, 콘텐츠는 json 형식으로 변환됩니다.
사전 지식
1. xml의 기본 이해
Xml은 확장 가능한 마크업 언어이며, 프로그래밍 언어와 상관없이 인터넷 플랫폼 전반에 걸쳐 XML을 구현할 수 있습니다. 운영 체제는 인터넷의 최고 수준의 패스를 갖춘 데이터 매체라고 할 수 있습니다.
xml은 구조화된 문서 정보를 처리하는 최신 기술입니다. 서버 간 구조화된 발행을 도와 개발자가 데이터의 저장 및 전송을 보다 편리하게 제어할 수 있습니다.
xml은 전자 문서를 표시하여 구조화된 마크업 언어로 만듭니다. 데이터를 표시하고 데이터 유형을 정의하는 데 사용할 수 있는 마크업 언어를 사용자가 직접 정의할 수 있는 소스 언어입니다. 이는 표준 범용 언어의 하위 집합이며 웹 전송에 매우 적합합니다.
2. 워드 문서의 두 가지 저장 방법
워드 문서의 두 가지 저장 형식: doc 및 docx
doc: 관습적으로 워드라고 하며, 데이터를 저장하기 위해 바이너리를 사용합니다.
docx: 즉, Word2007은 xml을 사용하여 저장합니다. data
그럼 접미사는 당연히 docx 형식인데 왜 xml 형식인가요?
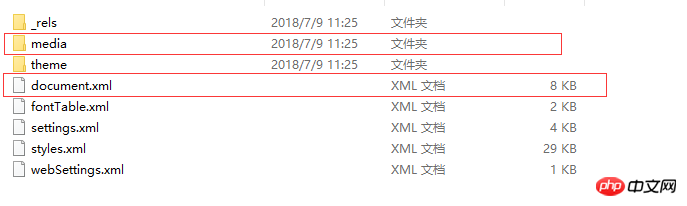
test.docx를 선택하고 접미사 이름을 .zip으로 변경한 후 압축을 풀어 다음 디렉터리 구조를 얻습니다.

그래서 여러분이 생각하는 docx 문서는 실제로 압축 파일입니다~
3. DOM 및 PHP 이해하기 DOM XML 구문 분석
DOM은 html 및 xml 문서에 대한 표준 개체 세트는 물론 이러한 문서에 액세스하고 조작하기 위한 표준 인터페이스를 제공합니다. XML DOM은 문서의 표준을 정의하는 개체 집합입니다. PHP DOM 확장을 사용하면 PHP로 DOM 트리에 일련의 작업을 구현할 수 있습니다.
PHP DOM을 사용하여 XML 문서 읽기:
test.xml:
2aaf03e419584feed0654e5769a6311a5f2b62dd45854a241b02c0e88071fa06eae70f81f7ceb6e15d3307d0fcbf32c3 8a11bc632ea32a57b3e3693c7987c420php dom testdf406f776eecbaf16b62325323196f14 48fe722b397613e801e59f453d6c9330test-one069b8d673ec8f2ad312c1b3588acdb707d69b0364ce0178ed42ed498fb3f0eb8eae70f81f7ceb6e15d3307d0fcbf32c3 b2386ffb911b14667cb8f0f91ea547a7php dom test 26e916e0f7d1e588d4f442bf645aedb2f 48fe722b397613e801e59f453d6c9330test-two069b8d673ec8f2ad312c1b3588acdb707d69b0364ce0178ed42ed498fb3f0eb8c9cf1940f1608be1d86487a1d136ab67
test.php:
<?php $doc = new DOMDocument();
$doc->load("test.xml"); //获取标签对象
$book=$doc->getElementsByTagName("test"); //输出第一个中的值
echo $book->item(0)->nodeValue;
echo "<br>----------------<br>";
$title=$doc->getElementsByTagName("name");
echo $title->item(0)->nodeValue;
echo "<br>----------------<br>"; //遍历所有book标签中的内容
foreach ($book as $note)
{
echo $note->nodeValue;
echo "<br>";
}결과:

4 xml의 정의 형식은 단어
입니다. word 데이터는 어떻게 정의되나요? ?
두 개의 파일/폴더만 소개하겠습니다:
한 파일은 전체 단어 문서의 내용을 정의하는 word/document.xml입니다.
또 다른 폴더는 word/media입니다. 이 폴더에는 문서의 멀티미디어 콘텐츠가 저장됩니다. 즉, 문서의 모든 사진, 오디오 및 비디오가 이 폴더에 저장됩니다.
document.ml의 전체 구조 정의:
30d62aeab593692457df6e48e31325f9 e4ea90d088e5c3d39154b2b9bfcd44c2 1cd73415ec6d15389d18b3b1f8dcba73 c40f7c91b7c20fc0eee95738e8d6cdff 5ad83e1c1232860a66f65a2e251f9221 e84b923c826a7c196bcb2565b9319b06 935b03d7bdfa227b85704d808f41fdda e8680000f363cb82b7f2c930f58633dc 4a2ba5a38d84be8c24b4e12ff061a6d7 6a7c515d155c69f94eafd9ac6ebf31a8 5daa03b38a0771a1fb69d9fff2858b67 2120a1776e013bfe32d8a05445dece29 5c04078d4c1cc5dc421de8f564ce6d1a 43f64d12e97790c1029480f923dbbb83 6a2483cbb124097fbc34371f16c0467f ce59d359290a70215a50ffa4f0fbbbd2 96ed9439c659e8e450875c49b8df9adc a17c39f82718fecc9dbbff60be677f0f 63065aaf547c6c6b49aca55a3f6a9397 be7e9f989cd506ea9ad858af9502dea9 b639aab6f233ca2658a121ea5cd71fb1 567cc2e2e2ff9e9f13cfa6106a0f1fda e919aea4579131530d90ded08e57a82a 05f489e411da99fbc1416db39abdfef1
문서 단락 내용:
1cd73415ec6d15389d18b3b1f8dcba73 c40f7c91b7c20fc0eee95738e8d6cdff 5ad83e1c1232860a66f65a2e251f9221 e84b923c826a7c196bcb2565b9319b06 935b03d7bdfa227b85704d808f41fdda e8680000f363cb82b7f2c930f58633dc 4a2ba5a38d84be8c24b4e12ff061a6d7 6a7c515d155c69f94eafd9ac6ebf31a8 5daa03b38a0771a1fb69d9fff2858b67 2120a1776e013bfe32d8a05445dece29 5c04078d4c1cc5dc421de8f564ce6d1a 43f64d12e97790c1029480f923dbbb83 6a2483cbb124097fbc34371f16c0467f ce59d359290a70215a50ffa4f0fbbbd2 96ed9439c659e8e450875c49b8df9adc a17c39f82718fecc9dbbff60be677f0f 63065aaf547c6c6b49aca55a3f6a9397 be7e9f989cd506ea9ad858af9502dea9 b639aab6f233ca2658a121ea5cd71fb1 567cc2e2e2ff9e9f13cfa6106a0f1fda e919aea4579131530d90ded08e57a82a 05f489e411da99fbc1416db39abdfef1 73df4e15f25b21cddc06e6cda5b77ade 73389815fe15e18235e4a05d06404a4b c9b65e209bc0d1e767d43c26b8ed832c ba0b29a083f458e453efe56a6be4f669 b57dd4d9cd374504bf5ceeec04527221 7dad62032a64d4af59db0f2491b761e0 e4b2c9b67897f745d21b20ef39352a11 b5b013232cdc3f01d8d21978ce7935e7 fce2809517fbd180cb62f9e6581144f1 377e20077303a61974ea8a8d644f3e0c d0d62db2ea7aee96ea4d87f3c2e46160 7af433e0a9c902263bd5fbd5c86eefb3 91a6045fcd7a6179028b6c4c461ec5e4 e5c87018381bba5f884dd35592cc2986 0eb30ced7ecbd0716fe8dc54ce343561 e8f607ae0f4850aa3576e2e254f34727 ba0b29a083f458e453efe56a6be4f669 ba1ee891a533d9683d9b38533400e609 0fe0f1fb9eb7a3dac789acb4a70b2d28 d7c531b1416166352b3f693a25619702 166634fe8d1388f900439ffb8657dbe0 206a91743cf9d008bd6f9e34b33547c4 c0d0d8aafb565380c0c31df9f981293e 2631240fe01283848323e5f9b73e3834 e4b2c9b67897f745d21b20ef39352a11 b5b013232cdc3f01d8d21978ce7935e7 fce2809517fbd180cb62f9e6581144f1 377e20077303a61974ea8a8d644f3e0c d0d62db2ea7aee96ea4d87f3c2e46160 7af433e0a9c902263bd5fbd5c86eefb3 91a6045fcd7a6179028b6c4c461ec5e4 e5c87018381bba5f884dd35592cc2986 0eb30ced7ecbd0716fe8dc54ce343561 e8f607ae0f4850aa3576e2e254f34727 ba0b29a083f458e453efe56a6be4f669 ba1ee891a533d9683d9b38533400e609 0fe0f1fb9eb7a3dac789acb4a70b2d28 d7c531b1416166352b3f693a25619702 166634fe8d1388f900439ffb8657dbe0 2425b69ea0d5675c89ef2d87c266b6d5 a6404c91941ab243c3e2acf77a6c1ddf 73df4e15f25b21cddc06e6cda5b77ade 73389815fe15e18235e4a05d06404a4b 206a91743cf9d008bd6f9e34b33547c4 a6c5b28f669f1bd5d83a87716f82bb27 作者: Test 84fcc76c32527fcfce5a40543da17a12 875eefd8ce6290d581339ced7c38c2a2 5d154b7604550fdd28d5dcb7a20784b6
이미지 내용 정의:
2631240fe01283848323e5f9b73e3834 e4b2c9b67897f745d21b20ef39352a11 b5b013232cdc3f01d8d21978ce7935e7 fce2809517fbd180cb62f9e6581144f1 377e20077303a61974ea8a8d644f3e0c d0d62db2ea7aee96ea4d87f3c2e46160 7af433e0a9c902263bd5fbd5c86eefb3 91a6045fcd7a6179028b6c4c461ec5e4 e5c87018381bba5f884dd35592cc2986 0eb30ced7ecbd0716fe8dc54ce343561 e8f607ae0f4850aa3576e2e254f34727 ba0b29a083f458e453efe56a6be4f669 ba1ee891a533d9683d9b38533400e609 0fe0f1fb9eb7a3dac789acb4a70b2d28 d7c531b1416166352b3f693a25619702 166634fe8d1388f900439ffb8657dbe0 2425b69ea0d5675c89ef2d87c266b6d5 a6404c91941ab243c3e2acf77a6c1ddf 73df4e15f25b21cddc06e6cda5b77ade 73389815fe15e18235e4a05d06404a4b 206a91743cf9d008bd6f9e34b33547c4 2f1bd8167d633807671a2ebd53e0748c ed73879f4eec7bacba27f82cfff7a884 e622c0055287012ad1d06c9e3c46532f ae023d86a419a18fd24b2d50f3af5239 76798d30975e8fb2288a431b53bd8d4d fc585e894391f877485e7361d7236bd0 aeaa65628bf0c4a3def5a14a7988c1e6 fd7d1cff4ef8857ca9f75c920f409a13 43ba7d3da3e84a2c9732fd8b2afbd149 25e0a02ef41c2c94030f334b9922ff4f 5f6f4c96f4cd149834df6c58fb325c91 bb881ec15a06ba925d40484506d01e4c d447baf070845f0527c98ba353c81199 6406e760d3a8e4c5442ee41c596ac5e1 adc09985359478aef59a64ef8e5d25dd 14b93225c3e87c8c36443e74e8a4f761 2dd332b5b8c7292c9c1849b97e60c9c9 2a2aac47dd68dbc81fa12a10e201b3ec 28136e6fdc182844d18bc36c95a3f753 b72baa4f585df6cda9287f0b98e99588 12ea31b367e74e4d56848c78b93bf9b0 cf46531cc89ba0dd47269c9b95b20213 004002e582d7f8698b2e0c8f954aaca8 f1f3cff7c99aac51f998ac1409da3381 9e6acf6613235edb80ef1f7280339341 e92a8dc3d47a1b08cf9b312fb6063035 98f90394c28be5fa14019c82ce0ed684 de804f3e9e111ff0903befb2c391ae68 f78134bd20986e39d7646414873438b1 1b51e0be50c29fe6a40a123f66b45068 21b3578f6e93fb23adb74ec24f5f62dc ce9a65951d680fc72386e0d97583fa2d e53c1b01c775e255360cea99c60c3f86 7cac5f8862635b73e9bb85c465424a97 9cf60189a627ac1e49661c31d0dc108f aeed961f5585b4a42d515216acb68900 bad74176c3e461b8dc8de9541a5f5094 d4b4ce3fef058a7eba28a6cfd6e59032 1bb3eeab69df875ac92e8428eb167557 611ade5a87841a884119f7eaec502cb2 43bc92e64aab8aa9677cfe9d4f4ef16a 960159f8049ef2692c80fbf2b850b9e9 e2a5dc931c639599976cf22abca1d4ca 98bda0a5def2268f8477d6386de06afe 9c9300fbe2fb0a0f8a2fe8c46e0ef116 e2a5dc931c639599976cf22abca1d4ca 98bda0a5def2268f8477d6386de06afe 9dbda594f5587c3bc54d029a07d08d33 21994f0048728f4e00f962321258d6bf e385c128d23a97a4e87fe1b8348181af ddb9e1cb53994ed3161f247f01734c5a 4136914b9788fa90e03086cffd803037 892961627f03d7692d68e414096d777e b289ceb1fb2cd9605f6cd9cd02cd8963 875eefd8ce6290d581339ced7c38c2a2
결론:
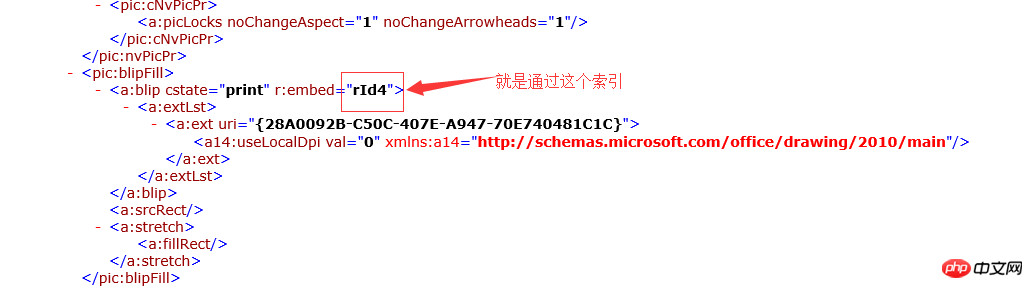
c1288db3edc33ea81d8279cf3b3389b0 定义整个文档的开始 e4ea90d088e5c3d39154b2b9bfcd44c2 document的子节点,文档的主体内容 1cd73415ec6d15389d18b3b1f8dcba73 body的子节点,一个段落,就是word文档中的段落 2631240fe01283848323e5f9b73e3834 p元素的子节点,一个Run定义了段落中具有相同格式的一段内容 a6c5b28f669f1bd5d83a87716f82bb27 Run元素节点的子节点,就是文档的内容 2f1bd8167d633807671a2ebd53e0748c run元素的子节点,定义了一张图片 c21d2efe537efcf091b2cd661d85da6e drawing子节点,具体应用没有研究 b497ea7e5ff41fded60ec12afe67378a 定义了图片内容 f1f3cff7c99aac51f998ac1409da3381 graphic文档的子节点,定义了图片内容的索引.
특히 Java를 사용하는 경우 XWPF는 docx 문서를 다음과 같이 구문 분석합니다. XML 문서 구문 분석을 수행하고 모든 노드를 얻은 다음 이를 보다 유용한 속성으로 변환하여 사용할 API를 제공합니다. Java에서 POI는 이 이름을 기반으로 이미지에 해당하는 리소스를 얻을 수 있으며 이미지 위치를 얻는 키는 여기에 있습니다. .
하지만 아쉽게도 저는 php를 사용하고 있습니다~~그래서 php의 관련 인터페이스를 통해 이미지 획득을 수동으로 구현해야 합니다.
제 구체적인 아이디어에 대해 이야기하겠습니다. PHP에 내장된 DOMDocument 인터페이스는 docx 문서의 xml 노드를 획득하고 xml 노드를 탐색하여 이미지를 저장하는 노드 요소를 찾은 다음 이미지 노드를 탐색하여 r:embed 인덱스 값까지 이동합니다. docx 문서는 압축된 패키지 형식이기 때문에 docx 문서는 PHP 내장 인터페이스 ZipArchive 인터페이스를 통해 탐색되고(본질적으로 .zip 압축 패키지 탐색) 해당 이미지는 인덱스를 통해 찾아 바이너리 데이터로 변환되며, 그런 다음 img 태그 표시 형식으로 접합한 것은 base64 이미지 데이터입니다.
xml로 변환:
private $rels_xml;
private $doc_xml;
private function readZipPart($filename) {
$zip = new ZipArchive();
$_xml = 'word/document.xml';
$_xml_rels = 'word/_rels/document.xml.rels';
if (true === $zip->open($filename)) {
if (($index = $zip->locateName($_xml)) !== false) {
$xml = $zip->getFromIndex($index);
}
$zip->close();
} else die('non zip file');
if (true === $zip->open($filename)) {
if (($index = $zip->locateName($_xml_rels)) !== false) {
$xml_rels = $zip->getFromIndex($index);
}
$zip->close();
} else die('non zip file');
$this->doc_xml = new DOMDocument();
$this->doc_xml->encoding = mb_detect_encoding($xml);
$this->doc_xml->preserveWhiteSpace = false;
$this->doc_xml->formatOutput = true;
$this->doc_xml->loadXML($xml);
$this->doc_xml->saveXML();
$this->rels_xml = new DOMDocument();
$this->rels_xml->encoding = mb_detect_encoding($xml);
$this->rels_xml->preserveWhiteSpace = false;
$this->rels_xml->formatOutput = true;
$this->rels_xml->loadXML($xml_rels);
$this->rels_xml->saveXML();
}
사진 노드인지 확인:
if($paragraph->name === 'w:drawing') {
(strstr($ts,'…封…') != false || strstr($ts,'…线…') != false) ? $t .= '' : $t .= $this->analysisDrawing($paragraph);
}
사진 인덱스 가져오기:
private function analysisDrawing(&$drawingXml) {
while($drawingXml->read()) {
if ($drawingXml->nodeType == XMLREADER::ELEMENT && $drawingXml->name === 'a:blip') {
$rId = $drawingXml->getAttribute('r:embed');
$rIdIndex = substr($rId,3);
return $this->checkImageFormating($rIdIndex);
}
}
}
압축된 패키지에 있는 사진 파일 표시:
private function checkImageFormating($rIdIndex) {
$imgname = 'word/media/image'.($rIdIndex-8);
$zipfileName = __DIR__.DIRECTORY_SEPARATOR.'b'.DIRECTORY_SEPARATOR.'test.docx';
$zip=zip_open($zipfileName);
while($zip_entry = zip_read($zip)) {//读依次读取包中的文件
$file_name=zip_entry_name($zip_entry);//获取zip中的文件名
if(strstr($file_name,$imgname) != '' ) {
$a = ($rIdIndex-8 b13a7ec521d12190d2804798bdb3ee93', $ext, base64_encode($content));//利用base64_encode函数转换读取到的二进制数据并输入输出到页面中
}
zip_entry_close($zip_entry); //关闭zip中打开的项目
}
}
zip_close($zip);//关闭zip文件
}
以上就是本文的全部内容,希望对大家的学习有所帮助,更多相关内容请关注PHP中文网!
相关推荐:
위 내용은 PHP를 사용하여 문서의 이미지를 구문 분석하는 방법의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!