
집 >데이터 베이스 >MySQL 튜토리얼 >MySQL 데이터베이스 단일 테이블 쿼리
MySQL 데이터베이스 단일 테이블 쿼리
- jacklove원래의
- 2018-06-11 23:13:124446검색
1. 단순 쿼리
1. Select 문
[고유] * | 필드 이름 1, 필드 이름 3을 선택합니다. . . } 表 from table name
[where 조건식 1]
[groupby 필드 이름 [조건식 2 포함]]
[orderby 필드 이름 [asc | desc]]
[limit [오프셋] 레코드 번호 ]
(1) Distinct는 쿼리 결과에서 중복 데이터를 제거하는 데 사용되는 선택적 매개 변수입니다.
(2) Group by는 지정된 필드에 따라 쿼리 결과를 그룹화하는 데 사용되는 선택적 매개 변수입니다. 그룹화된 결과
(3) Order by는 지정된 필드에 따라 쿼리 결과를 정렬하는 데 사용되는 선택적 매개변수입니다. 정렬 방법은 매개변수 ASC 또는 DESC에 의해 제어됩니다. 지정하지 않으면 기본값은 오름차순(ASC)입니다.
(4) Limit은 쿼리 결과 수를 제한하는 데 사용되는 선택적 매개 변수입니다. Limit 뒤에는 두 개의 매개 변수가 올 수 있습니다. 오프셋이 0인 경우 오프셋을 나타냅니다. 쿼리 결과, 오프셋이 n이면 쿼리 결과의 n+1번째 레코드부터 시작됩니다. 지정하지 않을 경우 기본값은 0이다. 두 번째 파라미터 '레코드 수'는 반환되는 쿼리 레코드 수를 나타낸다.
2. 모든 필드 쿼리
(1) select 문에 모든 필드 지정
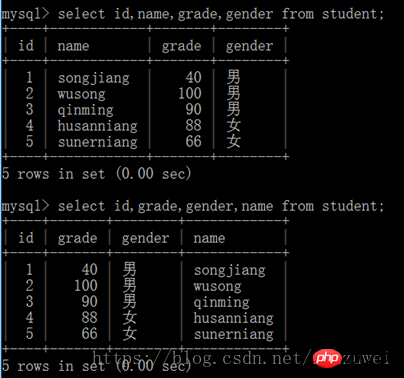 (2) 모든 필드를 바꾸려면 select 문에 * 와일드카드 문자를 사용하세요. 쿼리 결과는 다음 순서대로만 가능합니다. 테이블에 정의된 필드가 표시됩니다.
(2) 모든 필드를 바꾸려면 select 문에 * 와일드카드 문자를 사용하세요. 쿼리 결과는 다음 순서대로만 가능합니다. 테이블에 정의된 필드가 표시됩니다.
3. 지정된 필드를 쿼리합니다
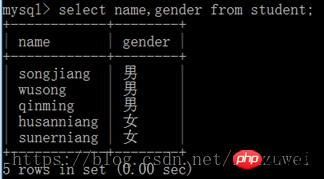
1. in 키워드로 쿼리: in 키워드를 사용하여 여부를 결정하는 데 사용됩니다. 특정 필드의 값이 지정된 세트에 있습니다.

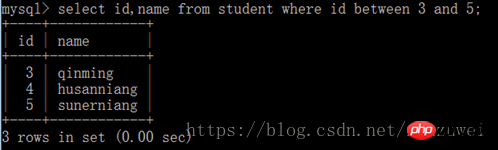
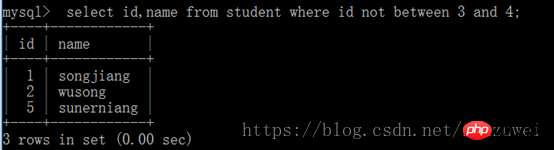
3. between 및 키워드로 쿼리: 특정 필드의 값이 지정된 범위 내에 있는지 확인하는 데 사용됩니다. 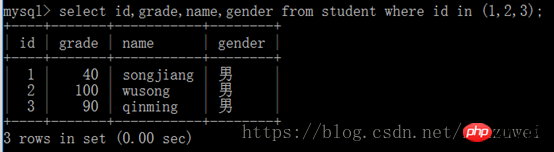
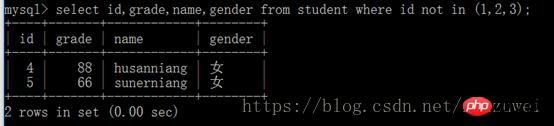
 5. 이후에 지정된 여러 필드의 값이 동일한 경우에만 중복 레코드로 간주됩니다.
5. 이후에 지정된 여러 필드의 값이 동일한 경우에만 중복 레코드로 간주됩니다.
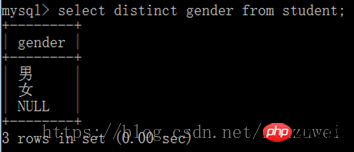
6. like 키워드를 사용한 쿼리: like 키워드는 두 문자열이 일치하는지 여부를 결정할 수 있습니다. 형식은 다음과 같습니다.
~ * | 선택: 빈 문자열을 포함하여 모든 길이의 문자열과 일치합니다.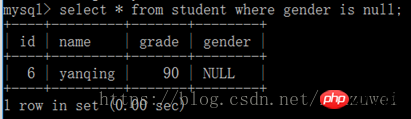
 여러 % 와일드카드를 사용하거나 not
여러 % 와일드카드를 사용하거나 not
과 함께 사용할 수 있습니다.
(2) 밑줄(_) 와일드카드: 여러 문자를 일치시키려면 여러 개의 밑줄 와일드카드를 사용하여 여러 연속 문자를 일치시켜야 합니다. 밑줄. 예를 들어 'M__QL' 중간에 공백이 있으면 'My SQL'만 일치할 수 있고 'MySQL'은 일치하지 않습니다.
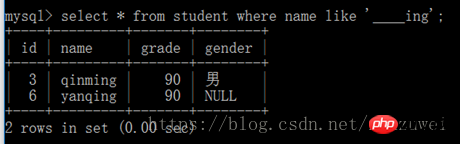
(3) 쿼리 작업에 백분율 기호와 밑줄 와일드카드를 사용하세요.
참고: 문자열에서 백분율 기호와 밑줄을 일치시키려면 청동 문자열에서 백분율 기호 대신 ''를 사용해야 합니다. 백분율 기호 리터럴과 일치하도록 '%'와 같은 밑줄을 사용하여 이스케이프합니다.
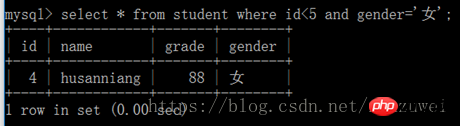
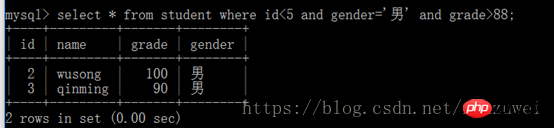
7. 및 키워드를 사용한 다중 조건 쿼리: 두 개 이상의 쿼리 조건을 연결하려면 및 키워드를 사용하여 모든 조건을 충족하는 레코드만 반환합니다. 각 추가 쿼리 조건에 대해 키워드를 하나 더 추가합니다.
8. 또는 키워드가 포함된 다중 조건 쿼리: 하나의 조건이 충족되는 한 레코드가 반환됩니다.
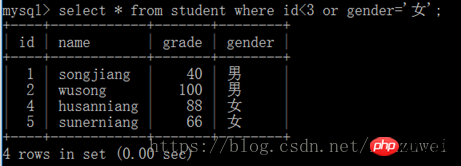
9. Or와 키워드가 함께 사용되는 상황: and보다 우선순위가 높습니다. and 양쪽의 조건식이 먼저 평가되어야 하며, or 양쪽의 조건식이 나중에 평가되어야 합니다.
3. 고급 쿼리
1. 집계 함수: count(), sum(), avg(), max() 및 min()
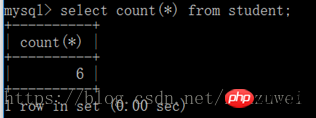
(1) count() 함수는 다음과 같이 사용됩니다. count records 항목 수: selectcount(*) from table name
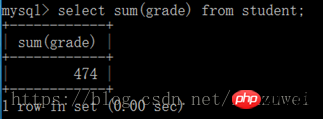
(2) sum() 함수는 테이블에 있는 필드의 모든 값의 합계를 찾는 데 사용됩니다: select sum(필드 이름) from table name
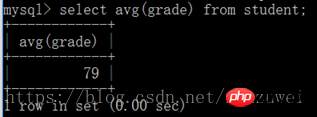
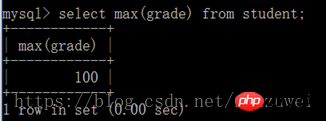
(3) avg() 함수는 필드에 있는 모든 값의 평균을 구하는 데 사용됩니다. select avg(field name) from table name; max() 함수는 필드의 최대값을 구하는 함수입니다. 테이블명에서 max(필드명)을 선택하세요.
(5) min() 함수는 최소값을 찾는 함수입니다: 테이블 이름에서 selectmin(필드 이름)
2 쿼리 결과를 정렬합니다.
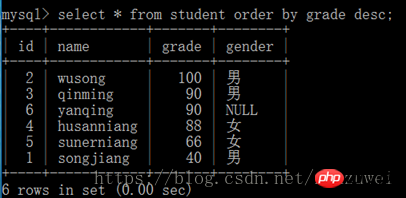
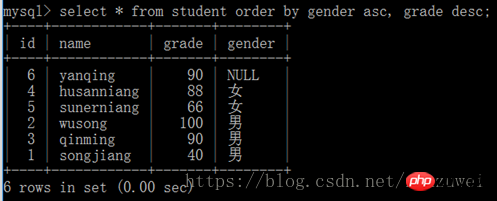
필드 이름 1, 필드 이름을 선택합니다. 2,… 테이블 이름에서 필드 이름 1 [ASC | DESC], 필드 이름 2 [ASC | DESC]…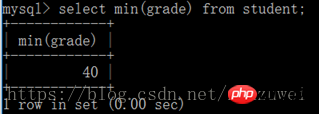
 3.그룹 쿼리
3.그룹 쿼리
필드 선택 name 2,… 테이블에서 Name 그룹을 필드 이름 1, 필드 이름 2,... [조건식 있음];
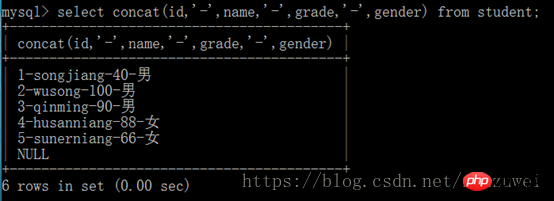
(2) Group by는 집계 함수와 함께 사용됩니다

(3) Group by는 had 키워드와 함께 사용됩니다
Having 키워드와 키워드가 동일한 효과를 갖는 경우 둘 다 사용됩니다. 조건식 설정 수식을 사용하여 쿼리 결과를 필터링합니다. 둘 사이의 차이점은 had 키워드 뒤에 집계 함수가 올 수 있지만 where 키워드는 올 수 없다는 것입니다. 일반적으로 갖는 키워드는 그룹화된 결과를 필터링하기 위해 그룹화 기준과 함께 사용됩니다. 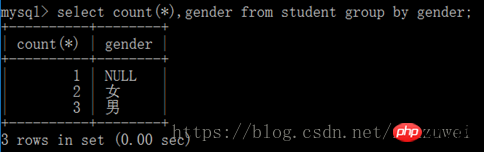
4. 쿼리 결과 수를 제한하려면 LIMIT를 사용하세요. 쿼리 결과가 시작되는 레코드와 쿼리되는 정보의 총 개수를 지정하세요.
필드 이름 1, 필드 이름 2,… 테이블 이름 제한에서 [오프셋,] 레코드 번호
5. 함수(목록)
수학적 함수
| 함수 | |
Abs(x) |
x의 절대값을 반환합니다 |
Sqrt(x) |
x |
| 모드( x ,y) |
x를 y |
Ceiling(x) |
x보다 작지 않은 가장 작은 정수를 반환합니다 |
Floor(x ) | x |
Round(x,y) |
x를 반올림하고 소수점 이하 y자리를 남겨둡니다 |
Runcate(x,y ) |
| Function name
Function |
Length(str) |
문자열 str의 길이를 반환합니다
| or를 반환합니다. 여러 문자열을 연결하여 생성된 새 문자열 | |
| 문자열 양쪽의 공백을 제거합니다 |
|
| 문자열 s2를 사용하여 문자열 str | |
| 문자열의 하위 문자열을 반환합니다. str, 시작 위치는 n, 길이는 len | |
| 문자열 반전 결과를 반환합니다. | |
| 시작 위치를 반환합니다. 문자열 str의 하위 문자열 s1 | |
| 날짜 및 시간 함수 | |
| Function |
현재 날짜를 가져옵니다. the system
| 현재 시스템 시간을 가져옵니다 | |
| 현재 시스템 날짜와 시간을 가져옵니다 | |
| 반환은 시간을 초로 변환합니다. | |
| 날짜의 더하기 연산을 수행합니다. | |
| 뺄셈 연산을 수행합니다. 날짜 | |
| 형식 날짜 및 시간 값 출력 | |
조건부 판단 함수 |
함수 이름 |
함수 |
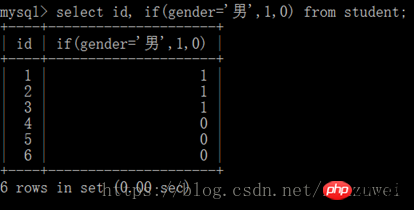
If(expr, v1, v2) |
if expr 표현식이 true이면 v1이 반환되고, 그렇지 않으면 v2이면 r2가 반환됩니다.] [else rn] end
암호화 함수 |
|
함수 이름 |
Function |
Md5 (str) |
MD5 문자열 str |
En code(str, pwd_str) |
pwd를 비밀번호로 사용하여 문자열 str |
Decode(str, pwd_str)
|
을 해독하려면 pwd를 비밀번호로 사용하세요.
(1) Concat(str1,str2,…)은 연결 매개변수에 의해 생성된 문자열을 반환합니다. 매개변수가 null이면 반환 값은 null입니다.
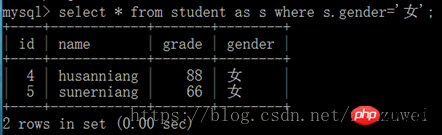
IV. 테이블 및 필드의 이름 1. 테이블의 별칭 이름: 테이블 이름에서 * 선택 [as] 별칭 다음 예에서 s.gender는 학생 테이블의 성별 필드를 나타냅니다
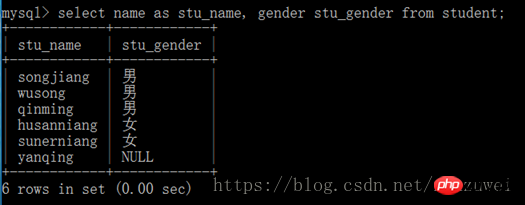
2. 필드 별칭 이름: 테이블 이름에서 필드 이름 [AS] 별칭 [, 필드 이름 [as] 별칭,...]을 선택합니다.
이 문서에서는 MySQL 데이터베이스 단일 테이블 쿼리에 대해 설명합니다. 관련 내용은 PHP 중국어 웹사이트를 주의 깊게 살펴보시기 바랍니다. 관련 권장 사항: $ 선택기 - DOM을 jquery 객체로 캡슐화하는 방법 |
위 내용은 MySQL 데이터베이스 단일 테이블 쿼리의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!