
Python 웹 크롤러--간단한 시뮬레이션 로그인 정보

- 不言원래의
- 2018-06-02 14:18:071750검색
오늘의 글은 주로 Python 웹 크롤러에 대한 내용을 소개하고 있는데, 이는 참고할만한 가치가 있습니다. 이제 도움이 필요한 친구들이 참고할 수 있도록 하겠습니다.
웹페이지에서 정보를 얻는 것과는 다릅니다. 시뮬레이션된 로그인을 원하면 계정 번호, 비밀번호 등과 같은 일부 정보를 서버로 보내야 합니다.
웹사이트 로그인 시뮬레이션은 대략 다음 단계로 나뉩니다.
1. 먼저 로그인 웹사이트의 숨겨진 정보를 찾아 해당 내용을 먼저 저장합니다. (여기서 로그인한 웹사이트에는 추가 정보가 없으므로) , 그래서 여기에는 정보 필터링 및 저장이 없습니다)
2. 정보 제출
3. 로그인 후 정보 가져오기
먼저 소스 코드를 제공하세요
<span style="font-size: 14px;"># -*- coding: utf-8 -*-
import requests
def login():
session = requests.session()
# res = session.get('http://my.its.csu.edu.cn/').content
login_data = {
'userName': '3903150327',
'passWord': '136510',
'enter': 'true'
}
session.post('http://my.its.csu.edu.cn//', data=login_data)
res = session.get('http://my.its.csu.edu.cn/Home/Default')
print(res.text)
login()</span>
1. 숨겨진 정보 가져오기
개발자 도구에 들어가서(F12 누르기) 네트워크를 찾고 수동으로 로그인한 다음 헤더 하단에 데이터 세그먼트가 있습니다. 로그인. 숨겨진 정보를 수정하고 싶다면
먼저 웹페이지 HTML
res = session.get('http://my.its.csu.edu.cn/').content
의 내용을 가져온 다음 정규식으로 내용을 필터링하세요
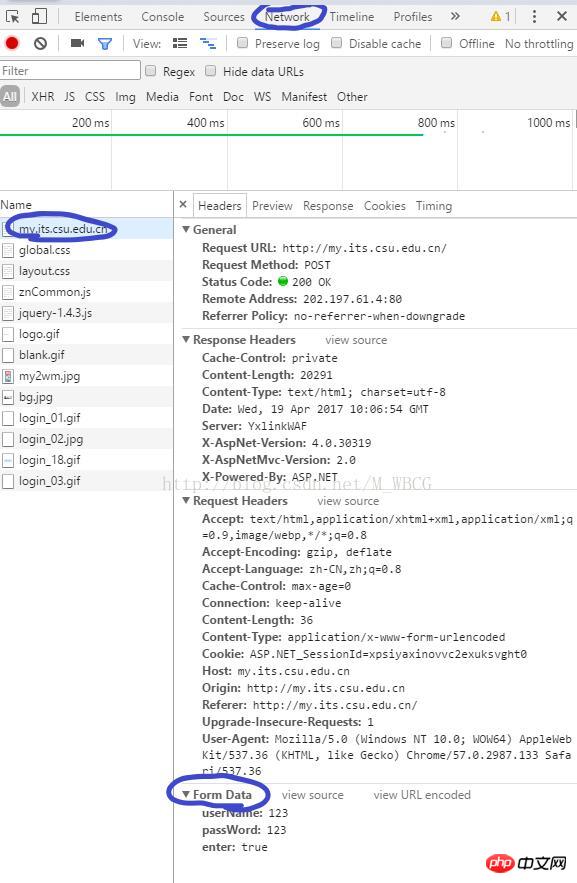
두 번째, 정보를 제출하세요
찾기 소스 코드 양식 제출에 필요한 조치 및 방법
사용
session.post('http://my.its.csu.edu.cn/(这里就是提交的action)', data=login_data)
이 방법은 정보를 제출합니다.
3. 로그인 후 정보 가져오기
정보가 제출된 후 시뮬레이션된 로그인 성공
Connect 로그인 후 정보를 얻을 수 있습니다
res = session.get('http://my.its.csu.edu.cn/Home/Default').content
관련 권장 사항:
프록시 IP를 잡아 가용성을 확인하는 Python 크롤러 인스턴스
위 내용은 Python 웹 크롤러--간단한 시뮬레이션 로그인 정보의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!