
PHP는 바이너리 힙을 사용하여 TopK 알고리즘을 구현합니다.
- 墨辰丷원래의
- 2018-05-23 15:06:171500검색
이 글은 주로 PHP를 사용하여 바이너리 힙을 사용하여 TopK 알고리즘을 구현하는 방법을 소개합니다. 글의 소개는 매우 자세하며 필요한 모든 사람을 위한 특정 참조 및 학습 가치가 있습니다. 함께.
머리말
과거에 일하거나 면접할 때 종종 문제에 직면했습니다. 대규모 TopN을 달성하는 방법은 매우 큰 결과 집합에서 가장 큰 상위 10위 또는 상위 100위 숫자를 빠르게 찾는 것입니다. 시간 메모리와 속도 효율성을 보장하기 위해 첫 번째 아이디어는 정렬을 사용한 다음 상위 10개 또는 100개를 가로채는 것입니다. 정렬은 양이 특별히 크지 않을 때는 문제가 없지만 양이 매우 크면 정렬은 문제가 됩니다. 예를 들어 배열이나 텍스트 파일에 수억 개의 숫자가 있는 경우 이를 모두 메모리로 읽어들이는 것은 불가능하므로 이 문제를 해결하기 위해 정렬을 사용하는 것은 최선이 아니므로 여기에서는 이 작업을 완료하는 것이 불가능합니다. 이 문제를 해결하기 위해 PHP를 사용합니다.
바이너리 힙
바이너리 힙은 완전한 이진 트리 또는 대략적인 이진 트리 두 가지가 있습니다. 이진 힙 유형, 최대 힙 및 최소 힙: 상위 노드의 키 값은 항상 하위 노드의 키 값보다 크거나 같습니다. 상위 노드의 키 값은 항상 작습니다. 모든 하위 노드의 키 값과 같거나

small丁Heap - (인터넷에서 가져온 그림)
바이너리 힙은 일반적으로 배열로 표시됩니다(위 그림 참조). 배열의 루트 노드는 0이고 n번째 위치의 하위 노드는 각각 2n+1과 2n +2에 있습니다. 따라서 위치 0의 하위 노드는 1과 2에 있고 1의 하위 노드는 3에 있습니다. 및 4 등. 이 저장 방법을 사용하면 상위 노드와 하위 노드를 더 쉽게 찾을 수 있습니다.
여기서 구체적인 개념적 문제에 대해서는 자세히 다루지 않겠습니다. 바이너리 힙에 대해 궁금한 점이 있으면 이 데이터 구조를 잘 이해할 수 있습니다. 다음으로 위의 topN을 구현하고 해결하기 위해 PHP 코드를 사용하겠습니다. 차이점을 확인하려면 여기에서 정렬 방법을 사용하여 구현하고 작동 방식을 확인하세요.
빠른 정렬 알고리즘을 사용하여 TopN 구현
//为了测试运行内存调大一点
ini_set('memory_limit', '2024M');
//实现一个快速排序函数
function quick_sort(array $array){
$length = count($array);
$left_array = array();
$right_array = array();
if($length <= 1){
return $array;
}
$key = $array[0];
for($i=1;$i<$length;$i++){
if($array[$i] > $key){
$right_array[] = $array[$i];
}else{
$left_array[] = $array[$i];
}
}
$left_array = quick_sort($left_array);
$right_array = quick_sort($right_array);
return array_merge($right_array,array($key),$left_array);
}
//构造500w不重复数
for($i=0;$i<5000000;$i++){
$numArr[] = $i;
}
//打乱它们
shuffle($numArr);
//现在我们从里面找到top10最大的数
var_dump(time());
print_r(array_slice(quick_sort($all),0,10));
var_dump(time());

실행 후 결과
위에 상위 10개의 결과가 출력되고, 실행시간이 출력되는 것을 볼 수 있습니다 , 대략 99s 정도이지만 이는 500만 개의 숫자를 메모리에 로드할 수 있는 경우에만 해당됩니다. 5kw 또는 5억 개의 숫자가 있는 파일이 있으면 확실히 몇 가지 문제가 있습니다.
바이너리 힙 알고리즘을 사용하면 문제가 발생합니다. TopN
구현 프로세스는 다음과 같습니다.
1. 먼저 10개 또는 100개의 숫자를 배열로 읽어옵니다. 이것이 topN 숫자입니다.
2. 함수를 호출하여 작은 상단을 생성합니다. heap, and put 이 배열은 이때 작은 상단 힙 구조를 생성합니다.
3. 파일이나 배열의 나머지 숫자를 모두 순서대로 탐색합니다. 순회하면 힙의 맨 위에 있는 요소가 옵니다. 크기를 비교하여 힙의 맨 위 요소보다 작으면 버리고, 힙의 맨 위 요소보다 크면 교체합니다.
5. 힙의 최상위 요소를 교체한 후 작은 최상위 힙을 생성하는 함수를 호출하여 계속해서 작은 최상위 힙을 생성해야 하기 때문에 가장 작은 것으로 나옵니다.
6. 위의 4~5단계를 반복하면 모든 순회가 완료된 후 작은 상위 힙에서 가장 큰 topN이 가장 큰 상위 힙이 됩니다. 왜냐하면 작은 상위 힙은 항상 가장 큰 상위 힙과 속도를 제외하기 때문입니다. 작은 상단 힙을 조정하는 것도 매우 빠릅니다. 상대적인 조정을 하고 루트 노드가 왼쪽 및 오른쪽 노드보다 작은지 확인하세요.
7. 알고리즘 복잡성 측면에서 최악의 경우 10위입니다. 경우에는 1개를 순회하는 것인데, 숫자를 힙의 맨 위로 바꾸면 10번을 조정해야 하는데, 이는 정렬보다 빠르며, 모든 내용을 메모리에 읽어들이는 것은 아니라는 점을 이해할 수 있습니다. 성취도는 선형 순회입니다.
//生成小顶堆函数
function Heap(&$arr,$idx){
$left = ($idx << 1) + 1;
$right = ($idx << 1) + 2;
if (!$arr[$left]){
return;
}
if($arr[$right] && $arr[$right] < $arr[$left]){
$l = $right;
}else{
$l = $left;
}
if ($arr[$idx] > $arr[$l]){
$tmp = $arr[$idx];
$arr[$idx] = $arr[$l];
$arr[$l] = $tmp;
Heap($arr,$l);
}
}
//这里为了保证跟上面一致,也构造500w不重复数
/*
当然这个数据集并不一定全放在内存,也可以在
文件里面,因为我们并不是全部加载到内存去进
行排序
*/
for($i=0;$i<5000000;$i++){
$numArr[] = $i;
}
//打乱它们
shuffle($numArr);
//先取出10个到数组
$topArr = array_slice($numArr,0,10);
//获取最后一个有子节点的索引位置
//因为在构造小顶堆的时候是从最后一个有左或右节点的位置
//开始从下往上不断的进行移动构造(具体可看上面的图去理解)
$idx = floor(count($topArr) / 2) - 1;
//生成小顶堆
for($i=$idx;$i>=0;$i--){
Heap($topArr,$i);
}
var_dump(time());
//这里可以看到,就是开始遍历剩下的所有元素
for($i = count($topArr); $i < count($numArr); $i++){
//每遍历一个则跟堆顶元素进行比较大小
if ($numArr[$i] > $topArr[0]){
//如果大于堆顶元素则替换
$topArr[0] = $numArr[$i];
/*
重新调用生成小顶堆函数进行维护,只不过这次是从堆顶
的索引位置开始自上往下进行维护,因为我们只是把堆顶
的元素给替换掉了而其余的还是按照根节点小于左右节点
的顺序摆放这也就是我们上面说的,只是相对调整下,并
不是全部调整一遍
*/
Heap($topArr,0);
}
}
var_dump(time());
실행 후의 결과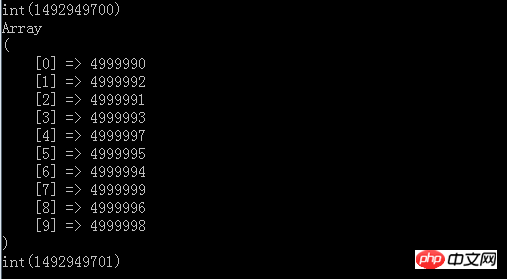
최종 결과도 top10임을 알 수 있는데 1초 정도 밖에 걸리지 않고, 메모리와 시간 효율성이 모두 충족됩니다. 우리의 요구 사항이며 정렬의 가장 좋은 점은 정렬할 필요가 없기 때문에 모든 데이터 세트를 메모리로 읽을 필요가 없다는 것입니다. 위의 내용은 데모용이므로 500만 개의 요소가 메모리에 직접 구성됩니다. 그러나 우리는 이 모든 것을 파일로 전송한 다음 한 줄씩 읽고 비교할 수 있습니다. 왜냐하면 우리 데이터 구조의 핵심은 선형 순회를 메모리의 매우 작은 최상위 힙 구조와 비교하고 최종적으로 TopN을 얻는 것이기 때문입니다. .
위 내용은 이 글의 전체 내용입니다. 모든 분들의 공부에 도움이 되었으면 좋겠습니다.
관련 권장 사항:
Linux_php 팁에서 redis 및 phpredis를 컴파일하는 방법
PHPMysqli 사용 완벽을 달성하기 위한 클래스 라이브러리 페이지 매김 방법 effect_php 실력
위 내용은 PHP는 바이너리 힙을 사용하여 TopK 알고리즘을 구현합니다.의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!