
WeChat 공개 계정의 과거 메시지를 얻는 방법
- 墨辰丷원래의
- 2018-05-17 09:43:054236검색
위챗 공개 계정 글에서 수집된 응모 내역 메시지 페이지에서 정보를 얻는 방법을 설명하겠습니다. 도움이 필요한 친구는 이 내용을 참고할 수 있습니다.
WeChat 기사 수집은 웹사이트 콘텐츠 수집과 동일합니다. 목록 페이지에서 시작해야 합니다. WeChat 기사 목록 페이지는 공식 계정의 조회 기록 메시지 페이지입니다. 현재 인터넷상의 많은 다른 WeChat 수집가는 Sogou를 사용하여 검색합니다. 수집 방법은 훨씬 간단하지만 내용은 불완전합니다. 따라서 우리는 여전히 가장 표준적이고 포괄적인 공개 계정 내역 메시지 페이지에서 이를 수집해야 합니다.
WeChat의 제한으로 인해 복사할 수 있는 링크가 불완전하며 브라우저에서 열어 콘텐츠를 볼 수 없습니다. 따라서 이전 기사에서 소개한 방법을 통해 전체 WeChat 공개 계정 내역 메시지 페이지의 링크 주소를 얻으려면 anyproxy를 사용해야 합니다. ㅋㅋㅋ 67343bef610edd80c9e1bfda66c2b62751511f7cc091a33a029709e94f0d1604e11220fc099 a27b2e2d29db75cc0849d4bf&devicetype=android-17&version=26031c34&lang=zh_CN& nettype=WIFI &ascene=3&pass_ticket=Iox5ZdpRhrSxGYEeopVJwTBP7kZj51GYyEL24AT5Zyx%2BBoEMdPDBtOun1F%2F9ENSz&wx_header= 1
이전 글에서 언급했듯이 biz 매개변수는 공식 계정의 ID이고, uin은 사용자의 ID입니다. 현재 uin은 모든 공식 계정 중에서 고유합니다. 다른 두 가지 중요한 매개변수인 key와 pass_ticket은 WeChat 클라이언트의 보충 매개변수입니다.
이 주소가 만료되기 전에 브라우저로 원본 텍스트를 보면 과거 메시지의 기사 목록을 얻을 수 있습니다. 콘텐츠를 자동으로 분석하려면 키와 pass_ticket을 사용하여 이 주소를 변환하는 프로그램을 만들 수도 있습니다. 아직 만료되지 않은 링크 주소를 제출한 다음, 예를 들어 PHP 프로그램을 통해 기사 목록을 얻으세요.
최근 한 친구가 수집 대상이 단일 공개 계정이라고 하더군요. 이렇게 하면 이전 글에서 설명한 일괄 수집 방법을 사용할 필요가 없을 것 같습니다. 그럼 이력 메시지 페이지에서 기사 목록을 가져오는 방법을 살펴보겠습니다. 기사 목록을 분석하면 이 공개 계정의 모든 콘텐츠 링크 주소를 얻을 수 있으며, 이후 콘텐츠를 수집할 수 있습니다.
anyproxy 웹 인터페이스에서 인증서가 올바르게 구성되면 https 콘텐츠가 표시될 수 있습니다. 웹 인터페이스의 주소는 http://localhost:8002입니다. 여기서 localhost는 자신의 IP 주소나 도메인 이름으로 바꿀 수 있습니다. 목록에서 getmasssendmsg로 시작하는 레코드를 찾으세요. 클릭하면 이 레코드의 세부 정보가 오른쪽에 표시됩니다.
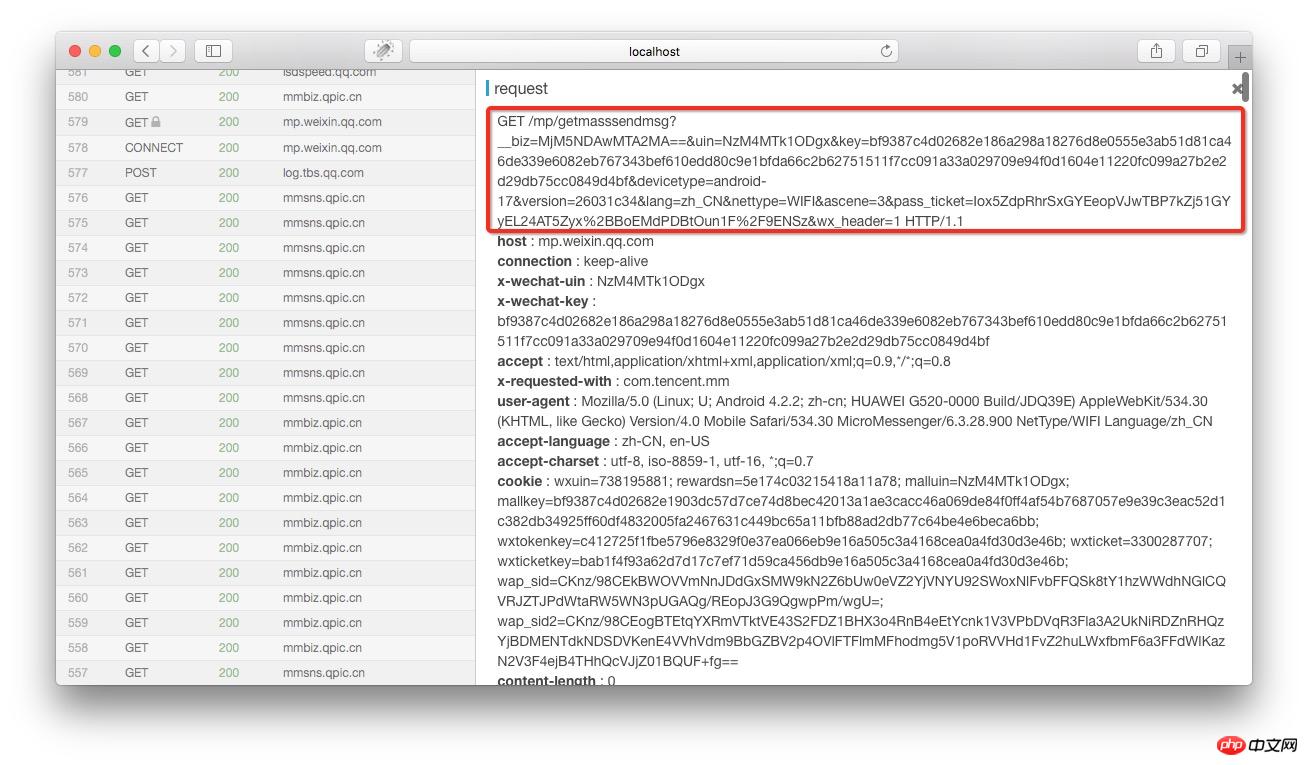 빨간색 상자는 WeChat 공개 플랫폼의 도메인 이름을 연결한 후의 전체 링크 주소입니다. 앞에는 브라우저에서 열 수 있습니다.
빨간색 상자는 WeChat 공개 플랫폼의 도메인 이름을 연결한 후의 전체 링크 주소입니다. 앞에는 브라우저에서 열 수 있습니다.
그런 다음 페이지를 HTML 콘텐츠 끝까지 끌어내리면 json 변수가 기록 메시지의 기사 목록임을 알 수 있습니다.
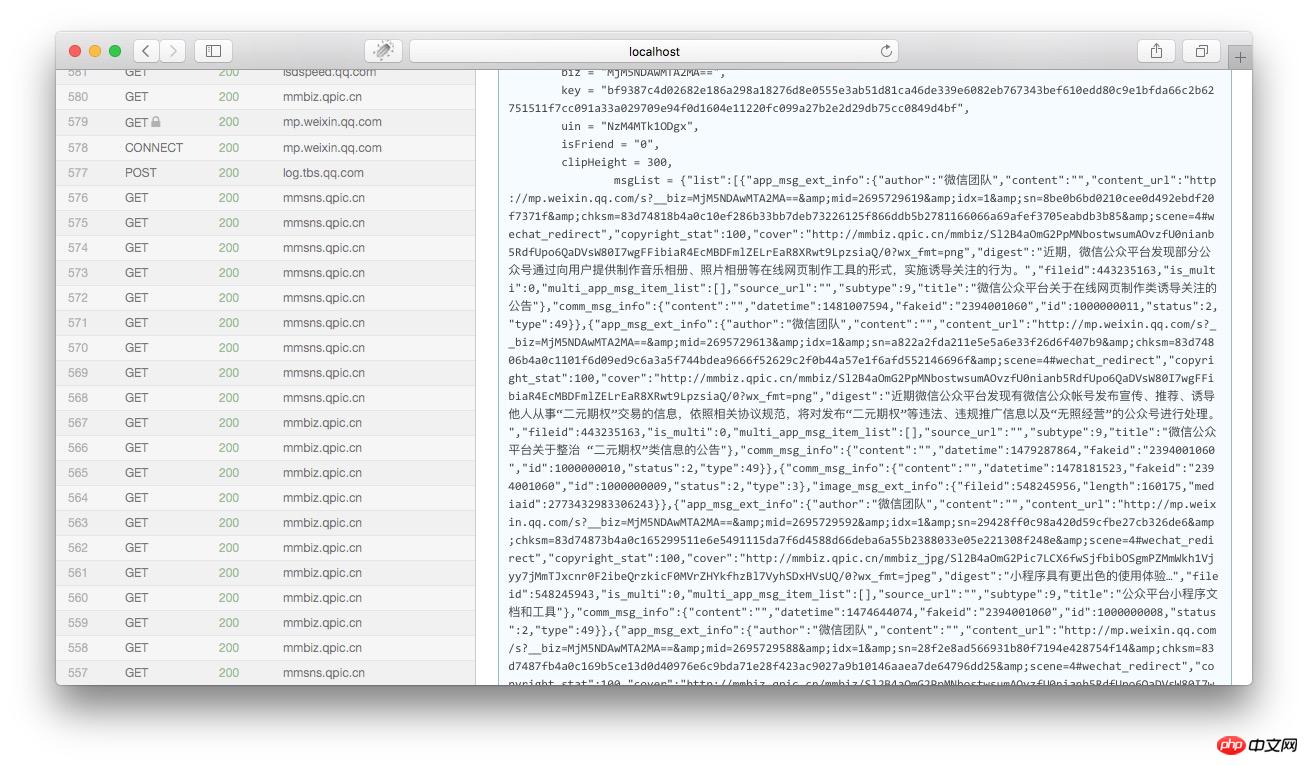 msgList의 변수 값을 복사하고 json 형식 지정 도구를 사용합니다. 분석해 보면 이 json의 구조는 다음과 같은 것을 알 수 있습니다.
msgList의 변수 값을 복사하고 json 형식 지정 도구를 사용합니다. 분석해 보면 이 json의 구조는 다음과 같은 것을 알 수 있습니다.
{
"list": [
{
"app_msg_ext_info": {
"author": "",
"content": "",
"content_url": "http://mp.weixin.qq.com/s?__biz=MzA5MzEzNDg3MQ==&mid=2652767427&idx=1&sn=37da0d7208283bf90e9a4a536e0af0ea&chksm=8b882dbbbcffa4ad2f0b8a141cc988d16bace564274018e68e5c53ee6f354f8ad56c9b98bade&scene=4#wechat_redirect",
"copyright_stat": 100,
"cover": "http://mmbiz.qpic.cn/mmbiz/MofBAcBsJ6X0xGrQ2XK5yQjzwb2eswxkRNBTgLtcqGziaFqwibzvtZAHCDkMeJU1fGZHpjoeibanPJ8rziaq68Akkg/0?wx_fmt=jpeg",
"digest": "擦亮双眼,远离谣言。",
"fileid": 505283695,
"is_multi": 1,
"multi_app_msg_item_list": [
{
"author": "",
"content": "",
"content_url": "http://mp.weixin.qq.com/s?__biz=MzA5MzEzNDg3MQ==&mid=2652767427&idx=2&sn=449ef1a874a37fed2429e14f724b56ef&chksm=8b882dbbbcffa4ade48a7932cda4263687e34fca8ea3a5a6233d2589d448b9f6130d3890ce93&scene=4#wechat_redirect",
"copyright_stat": 100,
"cover": "http://mmbiz.qpic.cn/mmbiz_png/MofBAcBsJ6XyaIn0qEDSSicBUBZbMYHYrhibia89ZnksCsUiaia2TLI1fyqjclibGa1hw3icP6oXeSpaWMjiabaghHl7yw/0?wx_fmt=png",
"digest": "12月28日,广州亚运城综合体育馆,内附购票入口~",
"fileid": 0,
"source_url": "http://wechat.show.wepiao.com/detail/ff764b0731b7465db03b56b998e1f2b8?detailReferrer=1&from=groupmessage&isappinstalled=0",
"title": "2017微信公开课Pro版即将召开"
},
...//循环被省略
],
"source_url": "",
"subtype": 9,
"title": "谣言热榜 | 十一月朋友圈十大谣言"
},
"comm_msg_info": {
"content": "",
"datetime": 1480933315,
"fakeid": "3093134871",
"id": 1000000010,
"status": 2,
"type": 49 //类型为49的时候是图文消息
}
},
...//循环被省略
]
}
이 json을 간략하게 분석합니다(여기서는 몇 가지 중요한 정보만 소개하고 기타 정보는 생략합니다).
"list": [ //最外层的键名;只出现一次,所有内容都被它包含。
{//这个大阔号之内是一条多图文或单图文消息,通俗的说就是一天的群发都在这里
"app_msg_ext_info":{//图文消息的扩展信息
"content_url": "图文消息的链接地址",
"cover": "封面图片",
"digest": "摘要",
"is_multi": "是否多图文,值为1和0",
"multi_app_msg_item_list": [//这里面包含的是从第二条开始的图文消息,如果is_multi=0,这里将为空
{
"content_url": "图文消息的链接地址",
"cover": "封面图片",
"digest": ""摘要"",
"source_url": "阅读原文的地址",
"title": "子内容标题"
},
...//循环被省略
],
"source_url": "阅读原文的地址",
"title": "头条标题"
},
"comm_msg_info":{//图文消息的基本信息
"datetime": '发布时间,值为unix时间戳',
"type": 49 //类型为49的时候是图文消息
}
},
...//循环被省略
]
또 다른 요점 여기서 언급하는 것은 더 긴 시간의 기록 메시지 내용을 얻으려면 휴대폰이나 시뮬레이터에서 페이지를 아래로 당겨야 한다는 것입니다. 페이지를 맨 아래로 당기면 WeChat이 자동으로 다음 페이지를 읽습니다. 다음 페이지의 링크 주소와 기록 메시지 페이지의 링크 주소도 getmasssendmsg로 시작하는 주소입니다. 하지만 내용은 html이 아닌 json일 뿐입니다. json을 직접 구문 분석하면 됩니다.
이때, 이전 글에서 소개한 방법을 이용하면 anyproxy를 이용하여 정기적으로 msgList 변수 값을 매칭하고, 이를 비동기적으로 서버에 제출한 후, 서버에서 php의 json_decode를 이용하여 json을 배열로 파싱할 수 있습니다. 그런 다음 배열을 반복합니다. 각 기사의 제목과 링크 주소를 얻을 수 있습니다.
단일 공식 계정의 콘텐츠만 수집해야 하는 경우, 매일 대량 전송 후 anyproxy를 통해 key와 pass_ticket으로 전체 링크 주소를 얻을 수 있습니다. 그런 다음 프로그램을 직접 만들고 주소를 프로그램에 수동으로 제출하세요. php와 같은 언어를 사용하여 msgList를 정기적으로 일치시킨 다음 json을 구문 분석합니다. 이렇게 하면 anyproxy의 규칙을 수정할 필요가 없고, 컬렉션 큐와 점프 페이지를 생성할 필요도 없습니다.
관련 권장 사항:
php WeChat 공용 계정은 현금 빨간 봉투 기능을 무작위로 배포합니다. PHP+cURL을 사용하여 WeChat 공용 계정 액세스_토큰 단계 분석을 얻습니다. vue 모바일 WeChat 공용 계정을 구현하는 세부 단계위 내용은 WeChat 공개 계정의 과거 메시지를 얻는 방법의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!