
Pandas 데이터 처리 기본 사항: 지정된 행 또는 지정된 열의 데이터 필터링

- 不言원래의
- 2018-05-03 13:31:4222225검색
이 글은 주로 pandas 데이터 처리의 기본 사항과 지정된 행 또는 지정된 열의 데이터 필터링에 대한 관련 정보를 소개합니다. 도움이 필요한 친구들이 참고할 수 있습니다.
pandas의 두 가지 주요 데이터 구조는 다음과 같습니다. 데이터 구조의 열)) 및 DataFrame(여러 행과 열이 있는 표 형식 데이터 구조와 동일).
이해의 편의를 위해 이번 글에서는 Excel이나 SQL의 행이나 열을 연산하는 방식으로 비유하겠습니다
1. Reindex: reindex 및 ix
이전 글에서 소개한 것처럼 데이터 뒤의 기본 행 인덱스 판독값은 0,1,2,3...이러한 일련 번호입니다. 열 인덱스는 필드 이름(예: 데이터의 첫 번째 행)과 동일합니다. 여기서 다시 인덱싱하면 기본 인덱스를 원하는 대로 다시 수정할 수 있습니다.
1.1 Series
예: data=Series([4,5,6],index=['a','b','c']), 행 인덱스는 a,b,c입니다.
data.reindex(['a','c','d','e'])를 사용하여 인덱스를 수정한 후 출력은 다음과 같습니다.
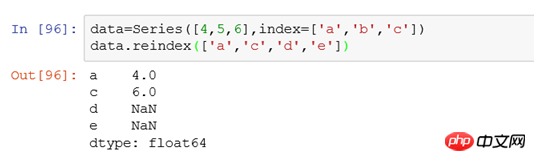
reindex를 사용한 후의 결과는 다음과 같습니다. 인덱스에 따라 인덱스를 설정하려면 원본 데이터로 이동하여 해당 값과 일치하지 않는 값은 NaN입니다.
1.2 DataFrame
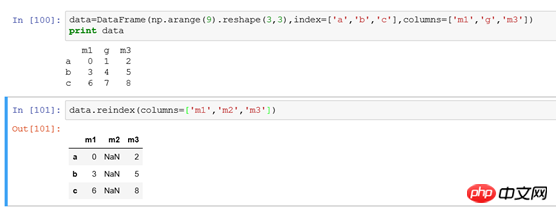
(1) 행 인덱스 수정: DataFrame 행 인덱스는 Series
와 동일합니다. (2) 열 인덱스 수정: 열 인덱스는 reindex(columns=['m1','m2','m3']를 사용합니다. ), 매개변수 열을 사용하여 열 인덱스의 수정을 지정합니다. 논리를 수정하는 것은 새 열 인덱스를 사용하여 원본 데이터와 일치하는 것과 유사합니다. 일치하는 항목이 없으면 NaN
을 설정합니다. 예:
(3) 행을 수정하려면 동시에 열 인덱스를 사용하려면
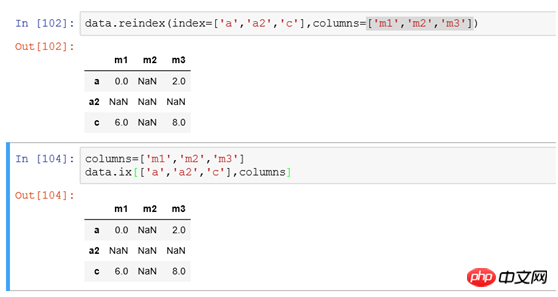
2을(를) 사용할 수 있습니다. 지정된 축에 열을 삭제합니다(일반 용어로 행 또는 열 삭제). drop
삭제할 행 또는 열을 선택하세요. index
data.drop(['a ','c'])는 xid='a' 또는 xid='c'data.drop(['a','c']) 相当于delete table a where xid='a' or xid='c'
data.drop('m1',axis=1)相当于delete table a where yid='m1'
3.选取和过滤(通俗的说就是sql中按照条件筛选查询)
python中因为有行列索引,在做数据的筛选会比较方便
3.1 Series
(1)按照行索引进行选择如
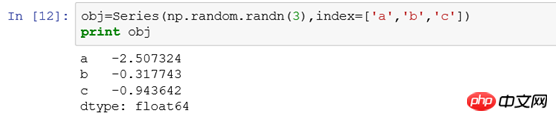
obj['b']相当于select * from tb where xid='b'obj['b','a','c']相当于select * from tb where xid in ('a','b','c')
data인 테이블 a를 삭제하는 것과 동일합니다. drop('m1',axis=1)은 yid='m1'
 3인 테이블 a 삭제와 동일합니다. 선택 및 필터링(일반 용어로는 SQL의 조건에 따라 쿼리를 필터링하는 것을 의미합니다)
3인 테이블 a 삭제와 동일합니다. 선택 및 필터링(일반 용어로는 SQL의 조건에 따라 쿼리를 필터링하는 것을 의미합니다)
파이썬에는 행과 열 인덱스가 있으므로 데이터 필터링이 더 편리합니다. 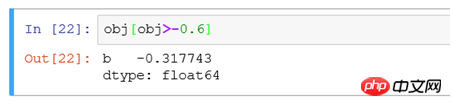
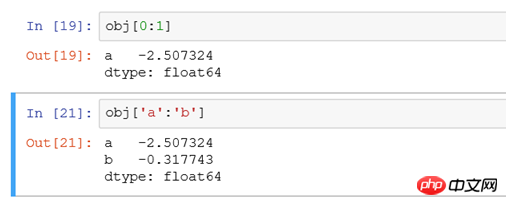
 obj['b']는
obj['b']는 select * from tb where xid와 동일합니다. ='b'obj['b','a','c']는 select * from tb where xid in ('a','b','c')와 동일합니다. code>이고 b, a, c의 순서로 결과가 표시됩니다. sql obj[0:1]과 obj['a':'b']의 차이점은 다음과 같습니다. <p style="max-width:90%"><img src="/static/imghwm/default1.png" data-src="https://img.php.cn/upload/article/000/153/291/ff487022b133390591d3854a505916ff-6.png" class="lazy" alt=""># 전자는 끝을 포함하지 않고, 후자는 끝을 포함합니다 </p>
<p></p>
<p></p> (2) 필터 obj[obj> -0.6]은 obj 데이터에서 -0.6보다 큰 값을 가진 레코드를 찾아 표시하는 것과 같습니다. <p style="text-align: center"><img src="/static/imghwm/default1.png" data-src="https://img.php.cn/upload/article/000/153/291/ff487022b133390591d3854a505916ff-7.png" class="lazy" alt=""></p>
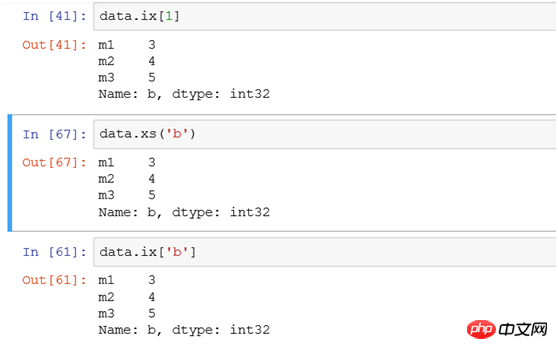
<p></p>3.2 DataFrame<p></p> (1) ix 또는 xs를 사용하여 단일 행을 선택합니다. <p></p>예를 들어 인덱스 b로 행을 필터링합니다. 다음 세 가지 방법을 사용하여 <p></p>
<p style="text-align: center"><img src="/static/imghwm/default1.png" data-src="https://img.php.cn/upload/article/000/153/291/459082f593ea9661345e54836f951281-8.png" class="lazy" alt=""></p>을 기록합니다. (2) 여러 개 선택 행: <p></p>인덱스 a와 b를 사용하여 두 행 레코드를 필터링합니다<p></p>
<p style="text-align: center"><img src="/static/imghwm/default1.png" data-src="https://img.php.cn/upload/article/000/153/291/459082f593ea9661345e54836f951281-9.png" class="lazy" alt=""></p>#위의 내용은 data[['a', 'b']]<p></p>data[0:2]가 레코드를 나타내므로 직접 쓸 수 없습니다. 첫 번째 행부터 두 번째 행까지. 첫 번째 줄은 기본적으로 끝의 2를 제외하고 0부터 계산되기 시작합니다. [ :,['m1','m2']] 앞:은 모든 행이 필터링됨을 의미합니다. <p></p>(5) 값 크기 조건을 기준으로 행 또는 열 필터링<p></p>예를 들어, 열 값이 4보다 큰 모든 레코드를 필터링하는 것은 열 이름 > 4인 tb에서 *를 선택하는 것과 같습니다🎜<p style="max-width:90%"><img src="/static/imghwm/default1.png" data-src="https://img.php.cn/upload/article/000/153/291/459082f593ea9661345e54836f951281-10.png" class="lazy" alt=""></p>
<p>(6) 열 값이 4보다 큰 모든 레코드를 필터링하고 일부 열만 표시해야 하는 경우</p>
<p style="text-align: center"><img src="/static/imghwm/default1.png" data-src="https://img.php.cn/upload/article/000/153/291/bd4f746a0f8f46d364b95e800a51be77-11.png" class="lazy" alt=""></p>
<p>행은 조건으로 필터링되고 열은 [0,2]로 필터링되어 첫 번째 열과 세 번째 열의 데이터를 필터링합니다</p>
<p>관련 권장 사항:<br></p>
<p><a href="http://www.php.cn/python-tutorials-393609.html" target="_self">pandas 데이터 샘플을 기반으로 행과 열을 선택하는 방법</a></p>
<p><a href="http://www.php.cn/python-tutorials-393603.html" target="_self">python3 pandas MySQL 데이터를 읽고 삽입</a></p>
<p></p>
<p class="clearfix"><span class="jbTestPos"></span></p>위 내용은 Pandas 데이터 처리 기본 사항: 지정된 행 또는 지정된 열의 데이터 필터링의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!