
Python 소켓 네트워크 프로그래밍의 고정 패킷 문제에 대한 자세한 설명

- 不言원래의
- 2018-04-28 13:36:002617검색
이 글은 주로 Python 소켓 네트워크 프로그래밍의 끈적한 문제에 대한 자세한 설명을 소개하고 있습니다. 같이 보러오세요
1. 끈적이는 문제의 상세
1. TCP만 패킷 고착이 있고, UDP는 절대 고착되지 않습니다.
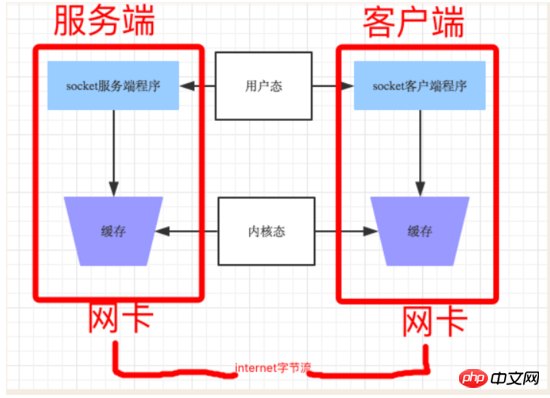
실제로 프로그램에 권한이 없습니다. 네트워크 카드의 경우, 네트워크 카드를 작동할 때 운영 체제를 통해 사용자 프로그램에 노출된 인터페이스를 사용하므로 프로그램이 원격 위치로 데이터를 보내려고 할 때마다 실제로 사용자로부터 데이터를 복사합니다. 이 작업은 리소스와 시간 측면에서 시간이 많이 걸리므로 커널 상태와 사용자 상태 간의 빈번한 데이터 교환으로 인해 전송 효율성이 저하될 수 있습니다. 소켓의 효율성 때문에 발신자는 상대방에게 데이터를 보내기 전에 충분한 데이터를 수집해야 하는 경우가 많습니다. 연속해서 여러 번 전송해야 하는 데이터가 매우 작은 경우 일반적으로 TCP 소켓은 최적화 알고리즘에 따라 데이터를 TCP 세그먼트로 결합하여 한 번에 전송하여 수신자가 고정 패킷 데이터를 수신하도록 합니다. .
2 먼저 소켓을 통해 메시지를 보내고 받는 원리를 익혀야 합니다.
발신자는 1k 또는 1k의 데이터를 보낼 수 있지만 수신 응용 프로그램은 2k 또는 2k의 데이터를 추출할 수 있습니다. 3k 이상의 데이터를 추출하는 것도 가능합니다. 즉, 애플리케이션이 보이지 않으므로 TCP 프로토콜은 해당 스트림에 대한 프로토콜이며 이는 끈적한 패킷이 발생하기 쉬운 이유이기도 합니다. UDP 연결 없는 프로토콜이며 각 UDP 세그먼트는 메시지입니다. 응용 프로그램은 메시지 단위로 데이터를 추출해야 하며 한 번에 한 바이트의 데이터도 추출할 수 없습니다. 메시지를 어떻게 정의하나요? 상대방이 한 번에 작성/전송한 데이터는 메시지라고 간주됩니다. 알아야 할 것은 상대방이 메시지를 보낼 때 Dingcheng이 메시지를 어떻게 조각화하더라도 TCP 프로토콜 계층에서 데이터를 정렬한다는 것입니다. 커널 버퍼에 나타나기 전에 전체 메시지를 구성하는 세그먼트입니다.
예를 들어 TCP 기반 소켓 클라이언트는 파일을 서버에 업로드할 때 파일 내용이 바이트 스트림으로 전송되므로 수신자가 파일의 바이트 스트림이 어디에 있는지 알 수 없게 됩니다. , 여기서 끝납니다.
3. 끈적한 패킷의 이유
3-1 직접적인 이유
소위 끈적한 패킷 문제는 주로 수신자가 메시지 사이의 경계를 모르고 한 번에 몇 바이트의 데이터를 추출할지 모르기 때문에 발생합니다. time
3-2 근본 원인
발신자에 의해 발생하는 끈적한 패킷은 TCP 프로토콜 자체에 의해 발생합니다. TCP의 전송 효율성을 높이기 위해 발신자는 TCP 세그먼트를 보내기 전에 충분한 데이터를 수집해야 하는 경우가 많습니다. 연속해서 여러 번 전송해야 하는 데이터가 매우 작은 경우 일반적으로 TCP는 최적화 알고리즘에 따라 데이터를 하나의 TCP 세그먼트로 결합하여 한 번에 전송하므로 수신자가 고정 데이터를 수신할 수 있습니다.
3-3 요약
TCP(Transport Control Protocol)는 연결 지향, 스트림 지향으로 신뢰성이 높은 서비스를 제공합니다. 송신단과 수신단(클라이언트와 서버) 모두 한 쌍의 소켓을 가져야 합니다. 따라서 여러 패킷을 수신단에 보다 효율적으로 보내기 위해 송신단에서는 여러 데이터를 소규모로 결합하는 최적화 방법을 사용합니다. 간격과 작은 데이터 볼륨을 하나의 큰 데이터 블록으로 묶은 다음 패키징합니다. 이런 방식으로 수신측에서는 구별이 어려우므로 과학적인 언패킹 메커니즘을 제공해야 합니다. 즉, 스트림 지향 통신에는 메시지 보호 경계가 없습니다.
UDP(사용자 데이터그램 프로토콜)는 연결이 없고 메시지 지향적이며 고효율 서비스를 제공합니다. 블록 병합 최적화 알고리즘은 사용되지 않습니다. UDP는 일대다 모드를 지원하므로 수신측의 skbuff(소켓 버퍼)는 도착하는 각 UDP 패킷을 기록하는 체인 구조를 채택합니다. 메시지 소스 주소, 포트, 기타 정보)를 패키지에 담아 수신측에서 쉽게 구별하고 처리할 수 있도록 합니다. 즉, 메시지 중심 커뮤니케이션에는 메시지 보호 경계가 있습니다.
tcp는 데이터 흐름을 기반으로 하므로 보내고 받는 메시지가 비어 있을 수 없습니다. 이를 위해서는 프로그램이 중단되는 것을 방지하기 위해 클라이언트와 서버 모두에 빈 메시지 처리 메커니즘을 추가해야 하지만 udp는 데이터 흐름을 기반으로 합니다. 빈 내용을 입력하더라도(Enter를 누르기만 하면) udp 프로토콜은 메시지 헤더를 캡슐화하는 데 도움이 됩니다. x 바이트의 데이터를 수신한 후 유일한 sendinto(y)가 완료됩니다. y> 패킷이 수신되지 않으면 마지막으로 계속 수신됩니다. ack를 받으면 항상 버퍼 내용을 지웁니다. 데이터는 신뢰할 수 있지만 끈적거릴 수 있습니다.
두 번째, 끈적끈적한 가방은 두 가지 상황에서 발생합니다.
1. 전송 측에서는 전송하기 전에 로컬 시스템의 버퍼가 가득 찰 때까지 기다려야 하므로 끈적한 패킷이 발생합니다(데이터 전송 시간 간격이 매우 짧고 데이터가 매우 작습니다. Python은 최적화 알고리즘을 사용하여 결합합니다).
Client
#_*_coding:utf-8_*_ import socket BUFSIZE=1024 ip_port=('127.0.0.1',8080) s=socket.socket(socket.AF_INET,socket.SOCK_STREAM) res=s.connect_ex(ip_port) s.send('hello'.encode('utf-8')) s.send('feng'.encode('utf-8'))
Server
#_*_coding:utf-8_*_ from socket import * ip_port=('127.0.0.1',8080) tcp_socket_server=socket(AF_INET,SOCK_STREAM) tcp_socket_server.bind(ip_port) tcp_socket_server.listen(5) conn,addr=tcp_socket_server.accept() data1=conn.recv(10) data2=conn.recv(10) print('----->',data1.decode('utf-8')) print('----->',data2.decode('utf-8')) conn.close()
2, 수신측에서 시간 내에 버퍼에 있는 패킷을 수락하지 않아 여러 패킷이 수락됩니다(클라이언트가 데이터 조각을 보내고, 서버는 아주 작은 부분만 받아서 다음번에는 서버가 받습니다. 그래도 버퍼에서 남은 데이터를 받으면 끈적한 패킷이 생성됩니다) 클라이언트
#_*_coding:utf-8_*_ import socket BUFSIZE=1024 ip_port=('127.0.0.1',8080) s=socket.socket(socket.AF_INET,socket.SOCK_STREAM) res=s.connect_ex(ip_port) s.send('hello feng'.encode('utf-8'))
Server
#_*_coding:utf-8_*_ from socket import * ip_port=('127.0.0.1',8080) tcp_socket_server=socket(AF_INET,SOCK_STREAM) tcp_socket_server.bind(ip_port) tcp_socket_server.listen(5) conn,addr=tcp_socket_server.accept() data1=conn.recv(2) #一次没有收完整 data2=conn.recv(10)#下次收的时候,会先取旧的数据,然后取新的 print('----->',data1.decode('utf-8')) print('----->',data2.decode('utf-8')) conn.close()
세 번째, 끈적한 패킷 인스턴스:
Server
import socket import subprocess din=socket.socket(socket.AF_INET,socket.SOCK_STREAM) ip_port=('127.0.0.1',8080) din.bind(ip_port) din.listen(5) conn,deer=din.accept() data1=conn.recv(1024) data2=conn.recv(1024) print(data1) print(data2)
Client:
import socket import subprocess din=socket.socket(socket.AF_INET,socket.SOCK_STREAM) ip_port=('127.0.0.1',8080) din.connect(ip_port) din.send('helloworld'.encode('utf-8')) din.send('sb'.encode('utf-8'))
넷째, unpacking 발생
sender 버퍼의 길이가 네트워크 카드의 MTU보다 클 경우 tcp는 이번에 보낸 데이터를 다음과 같이 분할합니다.
추가 질문 1: tcp는 신뢰할 수 있는 전송이고 udp는 신뢰할 수 없는 전송인 이유
tcp가 데이터를 전송할 때 보낸 사람은 먼저 데이터를 자체 캐시로 보낸 다음 프로토콜이 제어합니다. 캐시에 있는 데이터를 반대쪽으로 보내고 반대쪽 끝은 ack= 1을 반환합니다. 보내는 쪽은 캐시의 데이터를 지우고 반대쪽 끝은 ack=0을 반환하고 데이터를 다시 보내므로 tcp는 신뢰할 수 있습니다.
그리고 udp가 데이터를 보낼 때 반대쪽 끝은 확인 정보를 반환하지 않으므로 신뢰할 수 없습니다
보충 질문 2: send(바이트 스트림), recv(1024) 및 sendall은 무엇을 의미하나요?
recv에 지정된 1024는 캐시에서 한 번에 1024바이트의 데이터를 가져간다는 의미입니다.
send의 바이트 스트림이 먼저 셀프 엔드 캐시에 들어간 다음 캐시 내용이 반대쪽 끝으로 전송됩니다. 프로토콜 제어 하에서 조절 크기가 남은 캐시 공간보다 크면 데이터가 손실됩니다. sendall을 사용하여 루프에서 보내기를 호출하면 데이터가 손실되지 않습니다.
5. 끈끈한 가방 문제를 해결하는 방법은 무엇입니까?
문제의 근본 원인은 송신측이 전송하려는 바이트 스트림의 길이를 수신측에서 알지 못하기 때문에 끈적한 패킷 문제를 해결하는 방법은 송신측에서 어떻게 해야 할지에 집중하는 것입니다. end는 데이터를 보내기 전에 바이트 스트림을 보냅니다. 전체 크기는 수신 측에 알려진 다음 수신 측에서는 모든 데이터를 수신하기 위해 무한 루프를 만듭니다.
5-1 간단한 솔루션(표면 솔루션):
패킷 고착을 방지하려면 클라이언트 전송에 절전 시간을 추가하세요. 패킷 고착을 효과적으로 방지하려면 서버가 수신할 때에도 시간 절전이 필요합니다.
클라이언트:
#客户端 import socket import time import subprocess din=socket.socket(socket.AF_INET,socket.SOCK_STREAM) ip_port=('127.0.0.1',8080) din.connect(ip_port) din.send('helloworld'.encode('utf-8')) time.sleep(3) din.send('sb'.encode('utf-8'))
서버:
#服务端 import socket import time import subprocess din=socket.socket(socket.AF_INET,socket.SOCK_STREAM) ip_port=('127.0.0.1',8080) din.bind(ip_port) din.listen(5) conn,deer=din.accept() data1=conn.recv(1024) time.sleep(4) data2=conn.recv(1024) print(data1) print(data2)
위의 해결방법은 전송이 언제 완료될지 모르기 때문에 확실히 실수가 많을 것이고, 일시정지 시간이 길면 문제가 발생할 것입니다. , 비효율적일 것이고, 짧으면 부적절할 것입니다. 따라서 이 방법은 부적절합니다.
5-2 일반적인 해결책(문제를 근본부터 살펴보기):
문제의 근본은 수신 측에서 송신 측이 전송할 바이트 스트림의 길이를 알지 못하기 때문에 끈적한 패킷의 문제를 해결하는 방법은 데이터를 전송하기 전에 송신 측에서 수신 측에 전송할 바이트 스트림의 전체 크기를 알려주고 수신 측에서 모든 데이터를 무한대로 수신하는 방식입니다. loop
바이트 스트림에 사용자 정의 고정 길이 헤더를 추가합니다. 헤더에는 바이트 스트림의 길이가 포함되어 있으며 이를 수신 시 피어가 먼저 고정 길이 헤더를 가져옵니다. 캐시를 삭제한 다음 실제 데이터를 가져옵니다.
구조 모듈을 사용하여 4바이트 또는 8바이트의 고정 길이를 압축합니다. struct.pack.format 매개변수가 "i"인 경우 길이가 10인 숫자만 압축할 수 있으며 먼저 길이를 다음으로 변환할 수 있습니다. json 문자열을 만들고 패키지합니다.
일반 클라이언트
# _*_ coding: utf-8 _*_ import socket import struct phone = socket.socket(socket.AF_INET,socket.SOCK_STREAM) phone.connect(('127.0.0.1',8880)) #连接服 while True: # 发收消息 cmd = input('请你输入命令>>:').strip() if not cmd:continue phone.send(cmd.encode('utf-8')) #发送 #先收报头 header_struct = phone.recv(4) #收四个 unpack_res = struct.unpack('i',header_struct) total_size = unpack_res[0] #总长度 #后收数据 recv_size = 0 total_data=b'' while recv_size<total_size: #循环的收 recv_data = phone.recv(1024) #1024只是一个最大的限制 recv_size+=len(recv_data) # total_data+=recv_data # print('返回的消息:%s'%total_data.decode('gbk')) phone.close()
일반 서버
# _*_ coding: utf-8 _*_
import socket
import subprocess
import struct
phone = socket.socket(socket.AF_INET,socket.SOCK_STREAM) #买手机
phone.bind(('127.0.0.1',8880)) #绑定手机卡
phone.listen(5) #阻塞的最大数
print('start runing.....')
while True: #链接循环
coon,addr = phone.accept()# 等待接电话
print(coon,addr)
while True: #通信循环
# 收发消息
cmd = coon.recv(1024) #接收的最大数
print('接收的是:%s'%cmd.decode('utf-8'))
#处理过程
res = subprocess.Popen(cmd.decode('utf-8'),shell = True,
stdout=subprocess.PIPE, #标准输出
stderr=subprocess.PIPE #标准错误
)
stdout = res.stdout.read()
stderr = res.stderr.read()
#先发报头(转成固定长度的bytes类型,那么怎么转呢?就用到了struct模块)
#len(stdout) + len(stderr)#统计数据的长度
header = struct.pack('i',len(stdout)+len(stderr))#制作报头
coon.send(header)
#再发命令的结果
coon.send(stdout)
coon.send(stderr)
coon.close()
phone.close()5-3 최적화된 버전의 솔루션(문제를 루트부터 해결)
끈적거리는 문제를 해결하기 위한 최적화된 아이디어는 서버가 헤더 정보를 최적화하고 사전을 사용하여 전송할 내용을 설명합니다. 우선 사전을 네트워크를 통해 직접 전송할 수 없으며 직렬화하여 json 형식의 문자열로 변환한 후 바이트 형식으로 변환해야 합니다. 바이트 형식의 json 문자열은 문자열의 길이가 고정되어 있지 않으므로 struct 모듈을 사용하여 바이트 형식의 json 문자열 길이를 고정된 길이로 압축하여 클라이언트에 보내야 합니다. 클라이언트는 이를 수락하고 디코딩하여 완전한 데이터 패킷을 얻습니다.
클라이언트의 최종 버전
# _*_ coding: utf-8 _*_ import socket import struct import json phone = socket.socket(socket.AF_INET,socket.SOCK_STREAM) phone.connect(('127.0.0.1',8080)) #连接服务器 while True: # 发收消息 cmd = input('请你输入命令>>:').strip() if not cmd:continue phone.send(cmd.encode('utf-8')) #发送 #先收报头的长度 header_len = struct.unpack('i',phone.recv(4))[0] #吧bytes类型的反解 #在收报头 header_bytes = phone.recv(header_len) #收过来的也是bytes类型 header_json = header_bytes.decode('utf-8') #拿到json格式的字典 header_dic = json.loads(header_json) #反序列化拿到字典了 total_size = header_dic['total_size'] #就拿到数据的总长度了 #最后收数据 recv_size = 0 total_data=b'' while recv_size<total_size: #循环的收 recv_data = phone.recv(1024) #1024只是一个最大的限制 recv_size+=len(recv_data) #有可能接收的不是1024个字节,或许比1024多呢, # 那么接收的时候就接收不全,所以还要加上接收的那个长度 total_data+=recv_data #最终的结果 print('返回的消息:%s'%total_data.decode('gbk')) phone.close()
서버의 최종 버전
# _*_ coding: utf-8 _*_
import socket
import subprocess
import struct
import json
phone = socket.socket(socket.AF_INET,socket.SOCK_STREAM) #买手机
phone.setsockopt(socket.SOL_SOCKET,socket.SO_REUSEADDR,1)
phone.bind(('127.0.0.1',8080)) #绑定手机卡
phone.listen(5) #阻塞的最大数
print('start runing.....')
while True: #链接循环
coon,addr = phone.accept()# 等待接电话
print(coon,addr)
while True: #通信循环
# 收发消息
cmd = coon.recv(1024) #接收的最大数
print('接收的是:%s'%cmd.decode('utf-8'))
#处理过程
res = subprocess.Popen(cmd.decode('utf-8'),shell = True,
stdout=subprocess.PIPE, #标准输出
stderr=subprocess.PIPE #标准错误
)
stdout = res.stdout.read()
stderr = res.stderr.read()
# 制作报头
header_dic = {
'total_size': len(stdout)+len(stderr), # 总共的大小
'filename': None,
'md5': None
}
header_json = json.dumps(header_dic) #字符串类型
header_bytes = header_json.encode('utf-8') #转成bytes类型(但是长度是可变的)
#先发报头的长度
coon.send(struct.pack('i',len(header_bytes))) #发送固定长度的报头
#再发报头
coon.send(header_bytes)
#最后发命令的结果
coon.send(stdout)
coon.send(stderr)
coon.close()
phone.close()Six, struct module
了解c语言的人,一定会知道struct结构体在c语言中的作用,它定义了一种结构,里面包含不同类型的数据(int,char,bool等等),方便对某一结构对象进行处理。而在网络通信当中,大多传递的数据是以二进制流(binary data)存在的。当传递字符串时,不必担心太多的问题,而当传递诸如int、char之类的基本数据的时候,就需要有一种机制将某些特定的结构体类型打包成二进制流的字符串然后再网络传输,而接收端也应该可以通过某种机制进行解包还原出原始的结构体数据。python中的struct模块就提供了这样的机制,该模块的主要作用就是对python基本类型值与用python字符串格式表示的C struct类型间的转化(This module performs conversions between Python values and C structs represented as Python strings.)。stuct模块提供了很简单的几个函数,下面写几个例子。
1,基本的pack和unpack
struct提供用format specifier方式对数据进行打包和解包(Packing and Unpacking)。例如:
#该模块可以把一个类型,如数字,转成固定长度的bytes类型 import struct # res = struct.pack('i',12345) # print(res,len(res),type(res)) #长度是4 res2 = struct.pack('i',12345111) print(res2,len(res2),type(res2)) #长度也是4 unpack_res =struct.unpack('i',res2) print(unpack_res) #(12345111,) # print(unpack_res[0]) #12345111
代码中,首先定义了一个元组数据,包含int、string、float三种数据类型,然后定义了struct对象,并制定了format‘I3sf',I 表示int,3s表示三个字符长度的字符串,f 表示 float。最后通过struct的pack和unpack进行打包和解包。通过输出结果可以发现,value被pack之后,转化为了一段二进制字节串,而unpack可以把该字节串再转换回一个元组,但是值得注意的是对于float的精度发生了改变,这是由一些比如操作系统等客观因素所决定的。打包之后的数据所占用的字节数与C语言中的struct十分相似。
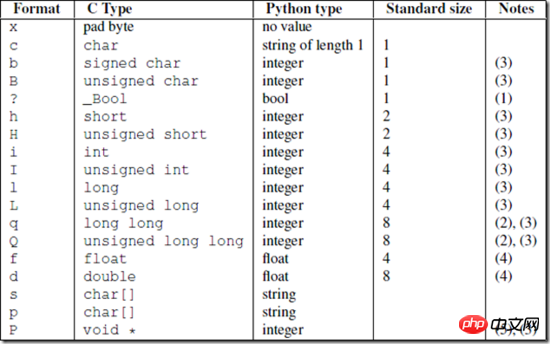
2,定义format可以参照官方api提供的对照表:
3,基本用法
import json,struct
#假设通过客户端上传1T:1073741824000的文件a.txt
#为避免粘包,必须自定制报头
header={'file_size':1073741824000,'file_name':'/a/b/c/d/e/a.txt','md5':'8f6fbf8347faa4924a76856701edb0f3'} #1T数据,文件路径和md5值
#为了该报头能传送,需要序列化并且转为bytes
head_bytes=bytes(json.dumps(header),encoding='utf-8') #序列化并转成bytes,用于传输
#为了让客户端知道报头的长度,用struck将报头长度这个数字转成固定长度:4个字节
head_len_bytes=struct.pack('i',len(head_bytes)) #这4个字节里只包含了一个数字,该数字是报头的长度
#客户端开始发送
conn.send(head_len_bytes) #先发报头的长度,4个bytes
conn.send(head_bytes) #再发报头的字节格式
conn.sendall(文件内容) #然后发真实内容的字节格式
#服务端开始接收
head_len_bytes=s.recv(4) #先收报头4个bytes,得到报头长度的字节格式
x=struct.unpack('i',head_len_bytes)[0] #提取报头的长度
head_bytes=s.recv(x) #按照报头长度x,收取报头的bytes格式
header=json.loads(json.dumps(header)) #提取报头
#最后根据报头的内容提取真实的数据,比如
real_data_len=s.recv(header['file_size'])
s.recv(real_data_len)위 내용은 Python 소켓 네트워크 프로그래밍의 고정 패킷 문제에 대한 자세한 설명의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!