
텐서플로우에서 데이터를 로드하는 세 가지 방법에 대한 자세한 설명

- 不言원래의
- 2018-04-24 14:24:093540검색
이 글에서는 주로 텐서플로우에서 데이터를 로드하는 세 가지 방법을 자세히 소개하고 있으며, 참고용으로 공유해 드립니다. 함께 살펴보겠습니다
Tensorflow 데이터를 읽는 세 가지 방법이 있습니다:
미리 로드된 데이터: 미리 로드된 데이터
피딩: Python이 데이터를 생성한 다음 백엔드에 데이터를 공급합니다.
파일에서 읽기: 파일에서 직접 읽기
이 세 가지 읽기 방법의 차이점은 무엇인가요? 먼저 TensorFlow(TF)가 어떻게 작동하는지 알아야 합니다.
TF의 핵심은 C++로 작성되었습니다. 장점은 빠르게 실행된다는 점이지만, 단점은 호출이 유연하지 않다는 것입니다. Python은 정반대이므로 두 언어의 장점을 결합합니다. 계산에 관련된 핵심 연산자와 실행 프레임워크는 C++로 작성되었으며 Python용 API도 제공됩니다. Python은 이러한 API를 호출하고 훈련 모델(Graph)을 설계한 다음 설계된 그래프를 실행을 위해 백엔드로 보냅니다. 한마디로 Python의 역할은 Design이고, C++의 역할은 Run입니다.
1. 데이터 사전 로드:
import tensorflow as tf # 设计Graph x1 = tf.constant([2, 3, 4]) x2 = tf.constant([4, 0, 1]) y = tf.add(x1, x2) # 打开一个session --> 计算y with tf.Session() as sess: print sess.run(y)
2. Python은 데이터를 생성한 다음 백엔드에 데이터를 공급합니다.
import tensorflow as tf
# 设计Graph
x1 = tf.placeholder(tf.int16)
x2 = tf.placeholder(tf.int16)
y = tf.add(x1, x2)
# 用Python产生数据
li1 = [2, 3, 4]
li2 = [4, 0, 1]
# 打开一个session --> 喂数据 --> 计算y
with tf.Session() as sess:
print sess.run(y, feed_dict={x1: li1, x2: li2}) 설명: x 여기 1, x2 단지 자리 표시자일 뿐이며 특정 값이 없습니다. 그러면 실행 시 어디에서 값을 얻습니까? 이때 Python에서 생성된 데이터를 백엔드에 공급하고 y를 계산하려면 sess.run()의 Feed_dict 매개변수를 사용해야 합니다.
이 두 솔루션의 단점:
1. 사전 로드: 데이터를 그래프에 직접 삽입한 다음 그래프를 세션에 전달하여 실행합니다. 데이터 양이 상대적으로 많으면 그래프 전송에 효율성 문제가 발생합니다.
2. 자리 표시자를 사용하여 데이터를 바꾸고 실행 시 데이터를 채웁니다.
처음 두 가지 방법은 매우 편리하지만 대용량 데이터를 접할 때는 매우 어려울 것입니다. Feeding의 경우에도 중간 링크의 증가는 데이터 유형 변환 등의 작은 오버헤드가 아닙니다. 가장 좋은 해결책은 Graph에서 파일 읽기 방법을 정의하고 TF가 파일에서 데이터를 읽고 이를 사용 가능한 샘플 세트로 디코딩하도록 하는 것입니다.
3. 파일을 읽는다는 것은 간단히 말해서 데이터 읽기 모듈의 다이어그램을 설정하는 것입니다
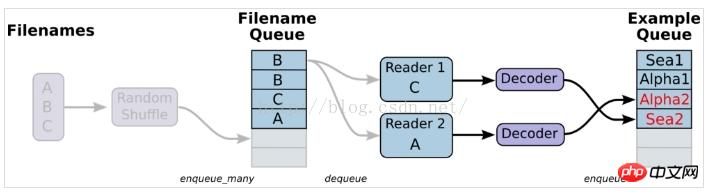
1. 데이터를 준비하고 A.csv, B.csv 세 개의 파일을 구성합니다. , C.csv
$ echo -e "Alpha1,A1\nAlpha2,A2\nAlpha3,A3" > A.csv $ echo -e "Bee1,B1\nBee2,B2\nBee3,B3" > B.csv $ echo -e "Sea1,C1\nSea2,C2\nSea3,C3" > C.csv
2. 단일 판독기, 단일 샘플
#-*- coding:utf-8 -*-
import tensorflow as tf
# 生成一个先入先出队列和一个QueueRunner,生成文件名队列
filenames = ['A.csv', 'B.csv', 'C.csv']
filename_queue = tf.train.string_input_producer(filenames, shuffle=False)
# 定义Reader
reader = tf.TextLineReader()
key, value = reader.read(filename_queue)
# 定义Decoder
example, label = tf.decode_csv(value, record_defaults=[['null'], ['null']])
#example_batch, label_batch = tf.train.shuffle_batch([example,label], batch_size=1, capacity=200, min_after_dequeue=100, num_threads=2)
# 运行Graph
with tf.Session() as sess:
coord = tf.train.Coordinator() #创建一个协调器,管理线程
threads = tf.train.start_queue_runners(coord=coord) #启动QueueRunner, 此时文件名队列已经进队。
for i in range(10):
print example.eval(),label.eval()
coord.request_stop()
coord.join(threads)
참고: 여기서는 tf.train.shuffle_batch가 사용되지 않으므로 생성된 샘플과 레이블이 각각에 해당하지 않습니다. 기타 및 고장. 생성된 결과는 다음과 같습니다.
Alpha1 A2
Alpha3 B1
Bee2 B3
Sea1 C2
Sea3 A1
Alpha2 A3
Bee1 B2
Bee3 C1
Sea2 C3
Alpha1 A2
So 해결책: tf.train을 사용하세요. shuffle_batch, 그러면 생성된 결과가 일치할 수 있습니다.
#-*- coding:utf-8 -*-
import tensorflow as tf
# 生成一个先入先出队列和一个QueueRunner,生成文件名队列
filenames = ['A.csv', 'B.csv', 'C.csv']
filename_queue = tf.train.string_input_producer(filenames, shuffle=False)
# 定义Reader
reader = tf.TextLineReader()
key, value = reader.read(filename_queue)
# 定义Decoder
example, label = tf.decode_csv(value, record_defaults=[['null'], ['null']])
example_batch, label_batch = tf.train.shuffle_batch([example,label], batch_size=1, capacity=200, min_after_dequeue=100, num_threads=2)
# 运行Graph
with tf.Session() as sess:
coord = tf.train.Coordinator() #创建一个协调器,管理线程
threads = tf.train.start_queue_runners(coord=coord) #启动QueueRunner, 此时文件名队列已经进队。
for i in range(10):
e_val,l_val = sess.run([example_batch, label_batch])
print e_val,l_val
coord.request_stop()
coord.join(threads)
3. 주로 tf.train.shuffle_batch를 통해 구현되는 단일 판독기, 다중 샘플
#-*- coding:utf-8 -*-
import tensorflow as tf
filenames = ['A.csv', 'B.csv', 'C.csv']
filename_queue = tf.train.string_input_producer(filenames, shuffle=False)
reader = tf.TextLineReader()
key, value = reader.read(filename_queue)
example, label = tf.decode_csv(value, record_defaults=[['null'], ['null']])
# 使用tf.train.batch()会多加了一个样本队列和一个QueueRunner。
#Decoder解后数据会进入这个队列,再批量出队。
# 虽然这里只有一个Reader,但可以设置多线程,相应增加线程数会提高读取速度,但并不是线程越多越好。
example_batch, label_batch = tf.train.batch(
[example, label], batch_size=5)
with tf.Session() as sess:
coord = tf.train.Coordinator()
threads = tf.train.start_queue_runners(coord=coord)
for i in range(10):
e_val,l_val = sess.run([example_batch,label_batch])
print e_val,l_val
coord.request_stop()
coord.join(threads)
설명: 다음 작성 방법은 배치 크기 샘플 및 기능을 추출합니다. label
#-*- coding:utf-8 -*-
import tensorflow as tf
filenames = ['A.csv', 'B.csv', 'C.csv']
filename_queue = tf.train.string_input_producer(filenames, shuffle=False)
reader = tf.TextLineReader()
key, value = reader.read(filename_queue)
example, label = tf.decode_csv(value, record_defaults=[['null'], ['null']])
# 使用tf.train.batch()会多加了一个样本队列和一个QueueRunner。
#Decoder解后数据会进入这个队列,再批量出队。
# 虽然这里只有一个Reader,但可以设置多线程,相应增加线程数会提高读取速度,但并不是线程越多越好。
example_batch, label_batch = tf.train.batch(
[example, label], batch_size=5)
with tf.Session() as sess:
coord = tf.train.Coordinator()
threads = tf.train.start_queue_runners(coord=coord)
for i in range(10):
print example_batch.eval(), label_batch.eval()
coord.request_stop()
coord.join(threads)
설명: 출력 결과는 다음과 같습니다. feature와 label
['Alpha1' 'Alpha2' 'Alpha3' 'Bee1' 'Bee2 '] ['B3' 'C1' 'C2' 'C3' 'A1']
['Alpha2' 'Alpha3' 'Bee1' 'Bee2' 'Bee3'] ['C1' 'C2' 'C3' 'A1' 'A2']
['Alpha3' 'Bee1' 'Bee2' 'Bee3' 'Sea1'] ['C2' 'C3' 'A1' 'A2' 'A3']
4. 다중 독자, 다중 샘플
#-*- coding:utf-8 -*-
import tensorflow as tf
filenames = ['A.csv', 'B.csv', 'C.csv']
filename_queue = tf.train.string_input_producer(filenames, shuffle=False)
reader = tf.TextLineReader()
key, value = reader.read(filename_queue)
record_defaults = [['null'], ['null']]
#定义了多种解码器,每个解码器跟一个reader相连
example_list = [tf.decode_csv(value, record_defaults=record_defaults)
for _ in range(2)] # Reader设置为2
# 使用tf.train.batch_join(),可以使用多个reader,并行读取数据。每个Reader使用一个线程。
example_batch, label_batch = tf.train.batch_join(
example_list, batch_size=5)
with tf.Session() as sess:
coord = tf.train.Coordinator()
threads = tf.train.start_queue_runners(coord=coord)
for i in range(10):
e_val,l_val = sess.run([example_batch,label_batch])
print e_val,l_val
coord.request_stop()
coord.join(threads)
tf.train.batch 및 tf.train.shuffle_batch 함수는 단일 리더로 읽히지만 다중 스레드일 수 있습니다. tf.train.batch_join 및 tf.train.shuffle_batch_join은 여러 판독기를 읽도록 설정할 수 있으며 각 판독기는 하나의 스레드를 사용합니다. 두 가지 방법의 효율성을 살펴보면 단일 리더를 사용하면 두 개의 스레드가 속도 제한에 도달했습니다. 리더가 여러 명인 경우 리더는 2명이 한계에 도달합니다. 따라서 더 많은 스레드가 더 빠르거나 더 많은 스레드가 효율성을 감소시키는 것은 아닙니다.
5. 반복 제어, 에포크 매개변수 설정, 훈련 중에만 샘플을 사용할 수 있는 라운드 수 지정
#-*- coding:utf-8 -*-
import tensorflow as tf
filenames = ['A.csv', 'B.csv', 'C.csv']
#num_epoch: 设置迭代数
filename_queue = tf.train.string_input_producer(filenames, shuffle=False,num_epochs=3)
reader = tf.TextLineReader()
key, value = reader.read(filename_queue)
record_defaults = [['null'], ['null']]
#定义了多种解码器,每个解码器跟一个reader相连
example_list = [tf.decode_csv(value, record_defaults=record_defaults)
for _ in range(2)] # Reader设置为2
# 使用tf.train.batch_join(),可以使用多个reader,并行读取数据。每个Reader使用一个线程。
example_batch, label_batch = tf.train.batch_join(
example_list, batch_size=1)
#初始化本地变量
init_local_op = tf.initialize_local_variables()
with tf.Session() as sess:
sess.run(init_local_op)
coord = tf.train.Coordinator()
threads = tf.train.start_queue_runners(coord=coord)
try:
while not coord.should_stop():
e_val,l_val = sess.run([example_batch,label_batch])
print e_val,l_val
except tf.errors.OutOfRangeError:
print('Epochs Complete!')
finally:
coord.request_stop()
coord.join(threads)
coord.request_stop()
coord.join(threads)
반복 제어에서 tf.initialize_local_variables()를 추가하는 것을 기억하세요. 공식적인 것은 없습니다. 웹사이트 튜토리얼 설명인데, 초기화하지 않으면 실행 시 오류가 발생합니다.
분류 문제와 같은 전통적인 기계 학습의 경우 [x1 x2 x3]이 기능입니다. 2클래스 분류 문제의 경우 원-핫 인코딩 후 레이블은 [0,1] 또는 [1,0]이 됩니다. 일반적인 상황에서는 한 행이 샘플을 나타내는 csv 파일로 데이터를 구성하는 것을 고려합니다. 그런 다음 대기열을 사용하여 데이터를 읽습니다
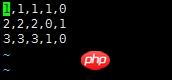
说明:对于该数据,前三列代表的是feature,因为是分类问题,后两列就是经过one-hot编码之后得到的label
使用队列读取该csv文件的代码如下:
#-*- coding:utf-8 -*-
import tensorflow as tf
# 生成一个先入先出队列和一个QueueRunner,生成文件名队列
filenames = ['A.csv']
filename_queue = tf.train.string_input_producer(filenames, shuffle=False)
# 定义Reader
reader = tf.TextLineReader()
key, value = reader.read(filename_queue)
# 定义Decoder
record_defaults = [[1], [1], [1], [1], [1]]
col1, col2, col3, col4, col5 = tf.decode_csv(value,record_defaults=record_defaults)
features = tf.pack([col1, col2, col3])
label = tf.pack([col4,col5])
example_batch, label_batch = tf.train.shuffle_batch([features,label], batch_size=2, capacity=200, min_after_dequeue=100, num_threads=2)
# 运行Graph
with tf.Session() as sess:
coord = tf.train.Coordinator() #创建一个协调器,管理线程
threads = tf.train.start_queue_runners(coord=coord) #启动QueueRunner, 此时文件名队列已经进队。
for i in range(10):
e_val,l_val = sess.run([example_batch, label_batch])
print e_val,l_val
coord.request_stop()
coord.join(threads)
输出结果如下:
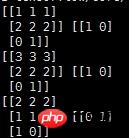
说明:
record_defaults = [[1], [1], [1], [1], [1]]
代表解析的模板,每个样本有5列,在数据中是默认用‘,'隔开的,然后解析的标准是[1],也即每一列的数值都解析为整型。[1.0]就是解析为浮点,['null']解析为string类型
相关推荐:
TensorFlow入门使用 tf.train.Saver()保存模型
关于Tensorflow中的tf.train.batch函数
위 내용은 텐서플로우에서 데이터를 로드하는 세 가지 방법에 대한 자세한 설명의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!